













告別傳統MQ:Kafka是一個分布式事件流平臺,這到底意味著什么呢?

1、引言
在大數據時代,實時數據處理和流式數據分析變得越來越重要。為了應對大規模數據的高吞吐量和低延遲處理需求,出現了各種分布式流處理平臺。其中,Apache Kafka作為一種高性能、可擴展的分布式消息系統,成為了廣泛應用于實時數據處理和數據管道的核心組件。
2、Kafka概念
Apache Kafka 是一個分布式事件流平臺:
- 發布和訂閱事件流,類似于消息隊列或企業消息傳遞系統。
- 以容錯持久的方式存儲事件流。
- 在事件流發生時對其進行處理。
要更詳細地了解分布式事件流,您應該首先了解事件是世界或您的業務中“發生的事情”的記錄。例如,在拼車系統中,您可能會看到以下事件:
- 事件key: “Alice”
- 事件value: “Trip requested at work location”
- 事件 timestamp: “Jun. 25, 2020 at 2:06 p.m.”
事件數據描述了發生的事情、時間以及涉及的人員。事件流是從數據庫、傳感器、移動設備、云服務和軟件應用程序等源實時捕獲示例中的事件的實踐。
事件流平臺按順序捕獲事件,并持久存儲這些事件流,以便實時處理、操作和響應或稍后檢索。此外,事件流可以根據需要路由到不同的目標技術。事件流可確保數據的連續流動和解釋,以便在正確的時間、正確的地點提供正確的信息。
為了實現這一目標,Kafka 作為集群運行在一臺或多臺可以跨越多個數據中心的服務器上。并以分布式、高度可擴展、彈性、容錯和安全的方式提供其功能。此外,Kafka 可以部署在裸機硬件、虛擬機、容器、本地以及云端。
借助 Kafka,您可以獲得用于管理任務的命令行工具,以及用于為您的場景構建事件流解決方案的 Java 和 Scala API。
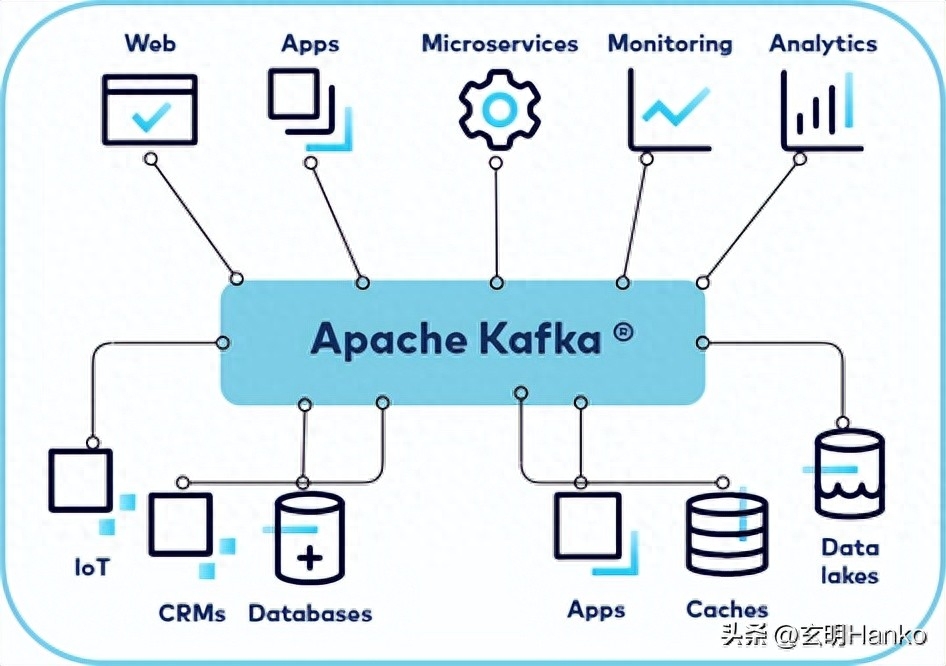
事件流適用于眾多行業和組織的各種用例。例如:
- 作為消息系統。例如,Kafka 可用于實時處理支付和金融交易,例如在證券交易所、銀行和保險公司。
- 活動跟蹤。例如,Kafka 可用于實時跟蹤和監控汽車、卡車、車隊和貨運,例如出租車服務、物流和汽車行業。
- 收集指標數據。例如,Kafka 可用于連續捕獲和分析來自物聯網設備或其他設備(例如工廠和風電場)的傳感器數據。
- 用于流處理。例如,使用 Kafka 收集客戶交互和訂單并做出反應,例如零售、酒店和旅游業以及移動應用程序。
- 解耦系統。例如,使用 Kafka 連接、存儲并提供公司不同部門生成的數據。
- 與其他大數據技術(例如 Hadoop)集成。
Kafka的核心概念包括以下幾個部分:
主題(Topic)
主題是數據流的類別或標簽,用于將數據進行分類。生產者將數據發布到特定的主題,消費者訂閱這些主題以接收數據。
分區(Partition)
每個主題可以分為一個或多個分區,每個分區是數據的有序序列。分區允許在多個服務器上并行處理和存儲數據,并實現高吞吐量和負載均衡。
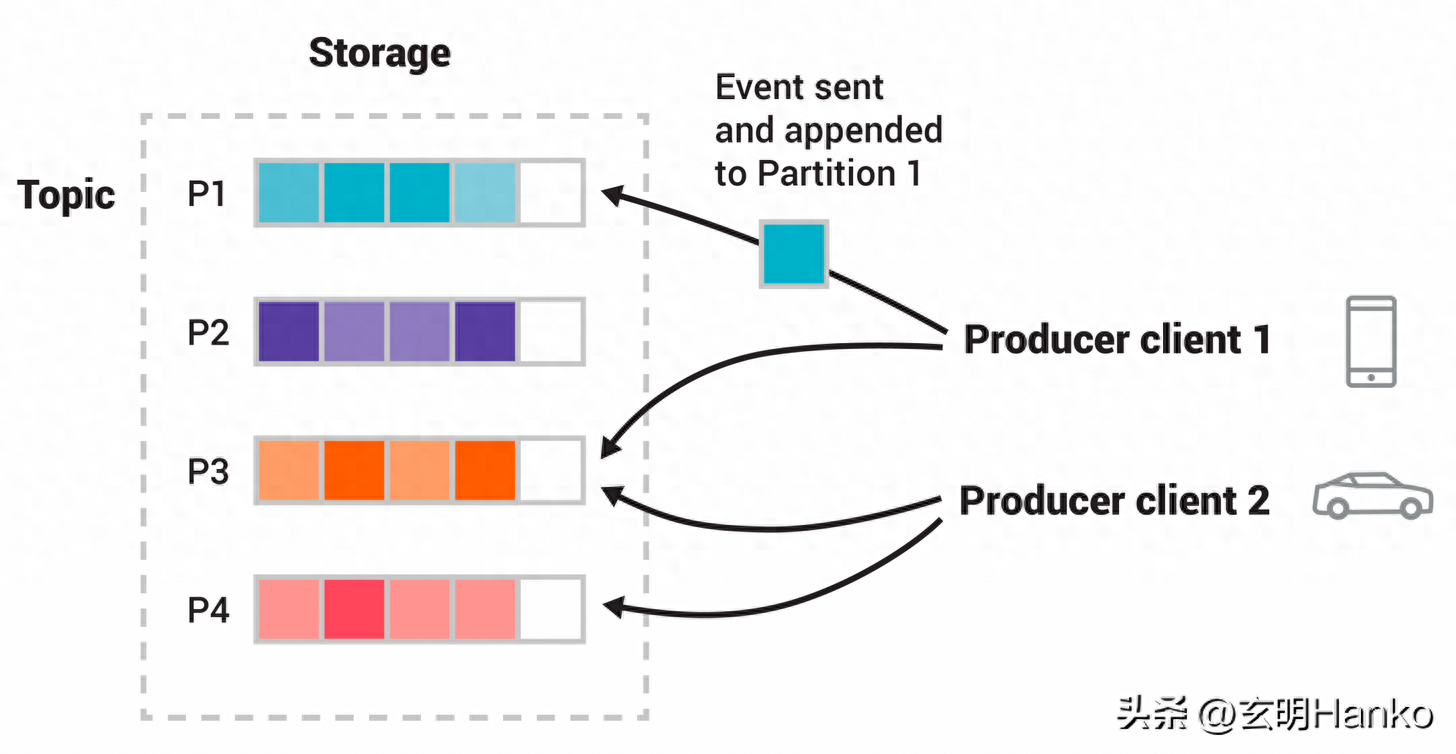
生產者(Producer)
生產者是將數據發布到Kafka主題的應用程序。它負責將數據發送到指定的主題,并根據分區策略選擇目標分區。
消費者(Consumer)
消費者是從Kafka主題中訂閱和讀取數據的應用程序。它可以訂閱一個或多個主題,并從指定的偏移量開始消費消息。
偏移量(Offset)
偏移量是分區中每條消息的唯一標識符,表示消息在分區中的位置。消費者可以指定偏移量來讀取特定位置的消息。
Kafka可以用于多種場景,包括日志收集、事件驅動架構、實時分析、指標監控、流式ETL等。它提供了可靠的數據傳輸、持久化存儲、數據復制和容錯機制,使得大規模數據處理和流式數據分析變得更加高效和可靠。
3、Kafka特性

高吞吐量
Kafka設計用于處理高吞吐量的數據流。它能夠處理每秒數百萬條消息,并支持同時處理大量的生產者和消費者。Kafka通過分區和并行處理來實現高吞吐量的數據傳輸。
可擴展性
Kafka是一個分布式系統,可以在集群中添加更多的服務器來擴展其容量和性能。它使用分區機制將數據分布到多個節點上,允許并行處理和水平擴展。
持久性存儲
Kafka提供持久化的數據存儲,即使消息被消費,它們仍然會被保留在磁盤上一段時間。這使得應用程序可以隨時回放歷史數據,進行批處理操作或重新處理數據。
高可用性
Kafka通過數據的復制和分布式副本機制來提供高可用性。每個分區都有多個副本,其中一個副本被選為Leader,負責處理讀寫請求,其他副本則作為Followers,用于備份和數據復制。如果Leader副本失效,Followers中的一個會被選舉為新的Leader,以確保數據的可用性和連續性。
多語言支持
Kafka提供了多種編程語言的客戶端API,包括Java、Python、Go和.NET等,方便開發者使用各種編程語言進行消息的生產和消費。

4、Kafka應用

Kafka在大數據和實時數據處理領域有廣泛的應用場景。以下是一些常見的Kafka應用場景:
日志收集和分析
Kafka能夠高效地收集和存儲大量的日志數據。應用程序可以將日志消息發布到Kafka主題中,而日志分析系統可以通過訂閱主題來實時消費和處理日志數據,進行實時監控、故障排查和數據分析等操作。
實時流處理
Kafka作為流處理平臺,可以進行實時的數據處理、轉換和聚合。它提供了Kafka Streams庫,使得開發者能夠輕松構建和部署實時流處理應用程序。實時流處理場景包括實時計算、實時監控、實時推薦等。
事件驅動架構
Kafka作為事件驅動架構的核心組件,能夠實現松耦合的異步通信和事件驅動的處理。不同的服務和組件可以通過Kafka進行事件的發布和訂閱,實現解耦、可擴展和高可用的架構。
指標監控
Kafka可以作為指標數據的收集和傳輸平臺,用于實時監控系統的性能和狀態。應用程序可以將指標數據發送到Kafka,監控系統訂閱相應的主題來實時消費和處理指標數據,進行實時監控、報警和分析。
數據管道和ETL
Kafka可以作為數據管道,連接不同的數據系統和應用程序。它可以與消息隊列、數據庫、數據湖等系統進行集成,實現異構系統之間的數據流動和交互。同時,Kafka的持久化存儲和流處理能力也使得它成為實時ETL(Extract, Transform, Load)的理想選擇。
媒體流處理
Kafka可以用于處理媒體數據流,如音頻、視頻等。它能夠高效地處理和傳輸大規模的媒體數據,并支持流媒體處理和實時分析,適用于實時廣播、視頻直播等場景。
5、使用者
Apache Kafka 是最流行的開源流處理軟件,用于大規模收集、處理、存儲和分析數據。它以其出色的性能、低延遲、容錯和高吞吐量而聞名,每秒能夠處理數千條消息。Kafka 用例超過 1,000 個,并且數量還在不斷增加,一些共同的好處是構建數據管道、利用實時數據流、啟用運營指標以及跨無數來源的數據集成。
如今,Kafka 被數千家公司使用,其中包括超過 80% 的財富 100 強企業。其中包括Box,Goldman Sachs,Target,Cisco,Intuit等。作為授權和創新公司的可靠工具,Kafka 允許組織通過事件流架構實現數據策略的現代化。了解 Kafka 如何被各行各業的組織使用 - 從計算機軟件、金融服務和醫療保健到政府和交通。





















