分片并不意味著分布式
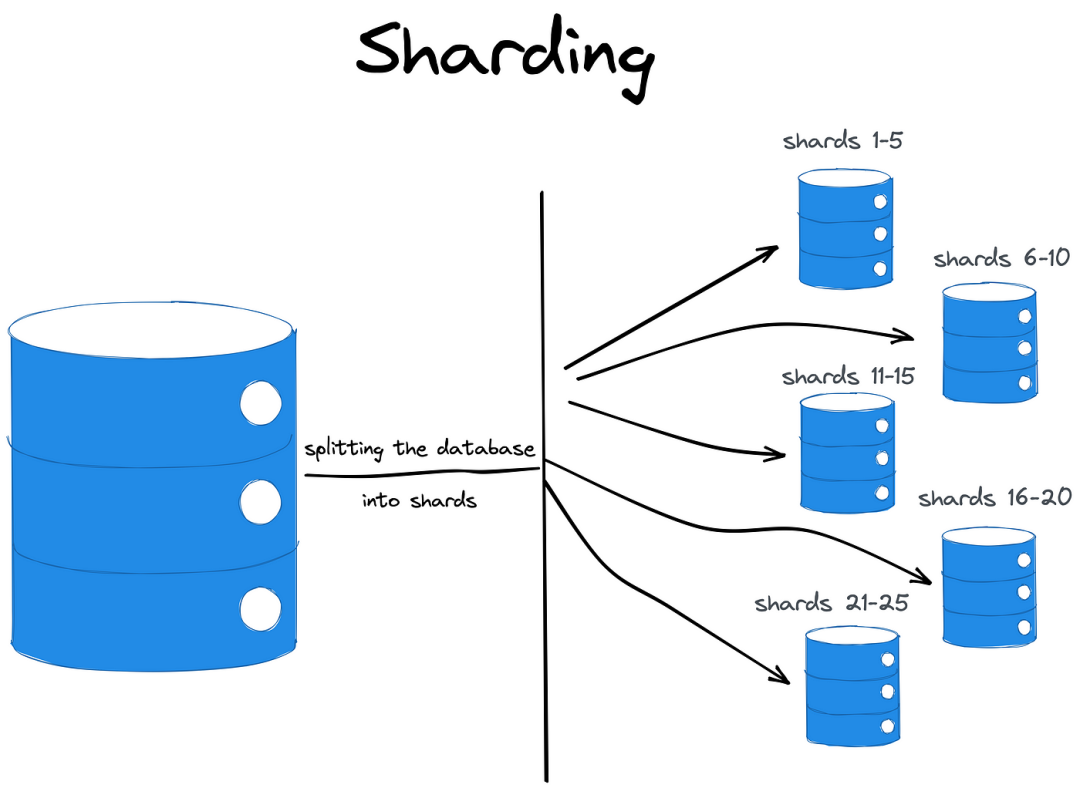
Sharding(分片)是一種將數據和負載分布到多個獨立的數據庫實例的技術。這種方法通過將原始數據集分割為分片來利用水平可擴展性,然后將這些分片分布到多個數據庫實例中。
1*yg3PV8O2RO4YegyiYeiItA.png
但是,盡管"分布"一詞出現在分片的定義中,但分片數據庫并不是分布式數據庫。
分片解決方案
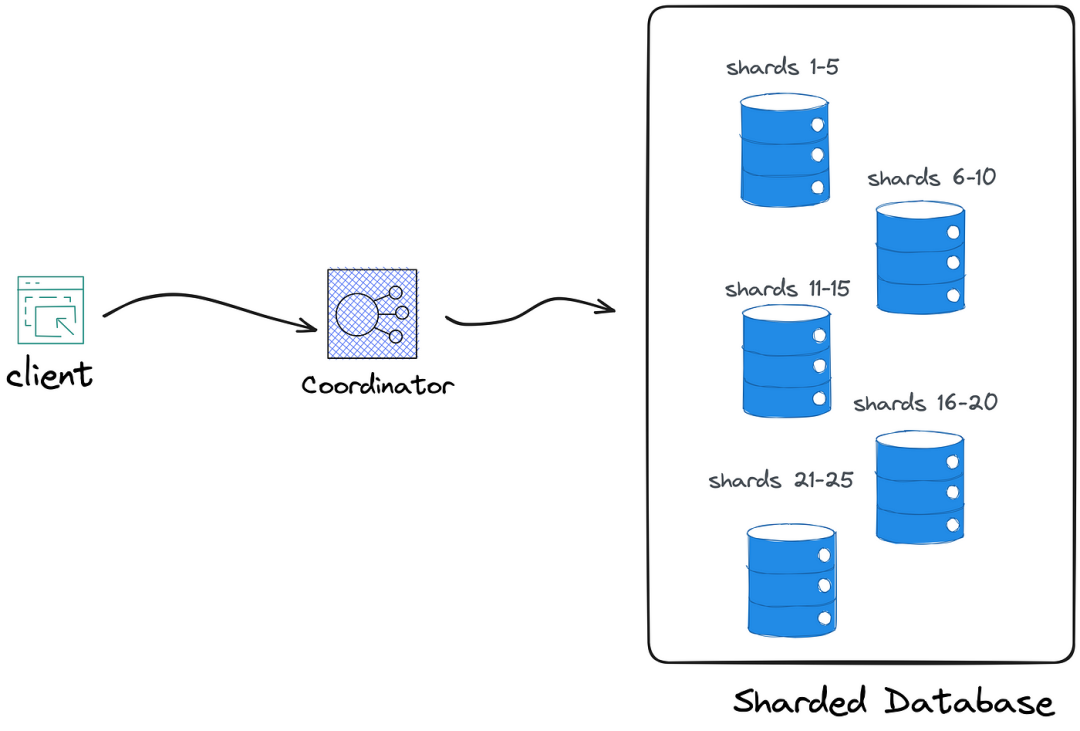
每個分片解決方案在其架構中都有一個關鍵組件。該組件可以有各種名稱,包括協調器、路由器或導演:
1*kp39_8mQ0E9bIO0Lw3PGFw.png
協調器是唯一一個知道數據分布的組件。它將客戶端請求映射到特定的分片,然后轉發到相應的數據庫實例。這就是為什么客戶端必須始終通過協調器路由其請求的原因。
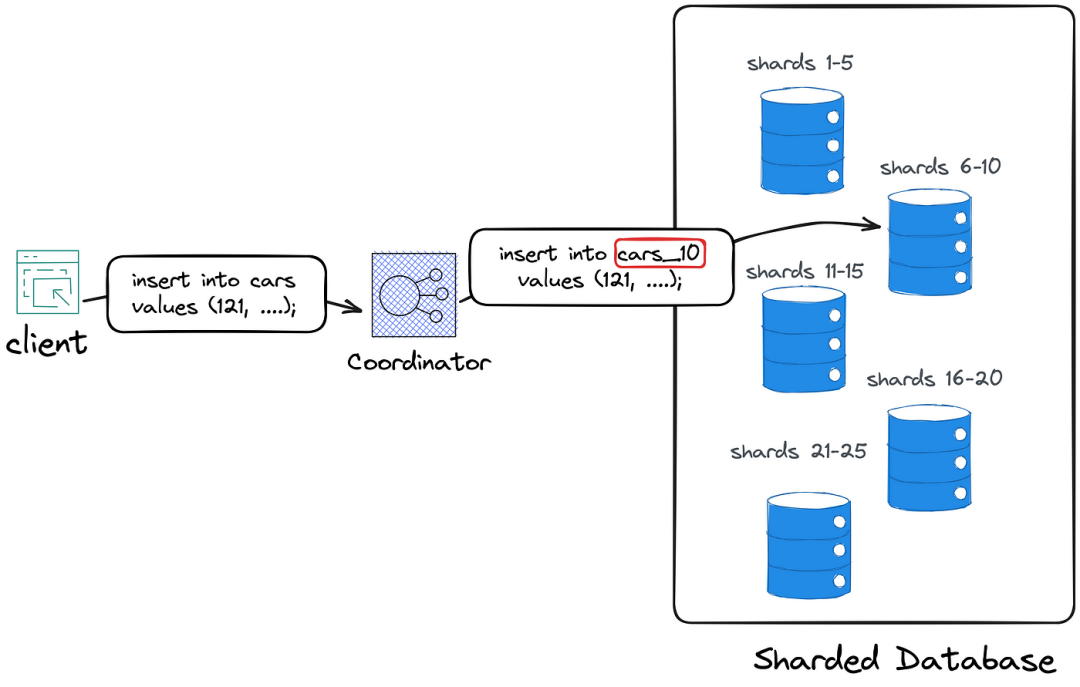
例如,如果客戶端想要將新記錄插入到Car表中,請求首先會傳遞到協調器。協調器將記錄的主鍵映射到其中一個分片,然后將請求轉發到負責該分片的數據庫實例。
1*YNUB6y8WJnp0CCVAXSjQ0g.png
在上面的示意圖中,首先,協調器將鍵121映射到分片10,然后將記錄插入到存儲在擁有分片10的數據庫實例上的表car_10中。
然而,還有一個問題:為什么在分片解決方案中需要協調器呢?答案很直接。分片存儲在設計用于單服務器部署的數據庫實例上。
這些數據庫實例不相互通信,也不支持任何能促進這種通信的協議。它們彼此不知道,存在于各自的隔離環境中,對于它們是一個更大系統的一部分這一事實毫不知情。
因此,在分片解決方案中,協調器是不可或缺的。如果您有興趣更深入地了解分片數據庫架構,請考慮探索用于PostgreSQL的CitusData或Azure CosmosDB,用于MySQL的Vitess,用于Oracle的Distributed Autonomous Database以及MongoDB Sharded Cluster。
分布式數據庫
與分片數據庫解決方案類似,分布式數據庫也使用類似的分片技術在數據庫節點群集中分發數據和負載。但是,與分片解決方案不同,分布式數據庫不依賴于協調器組件。
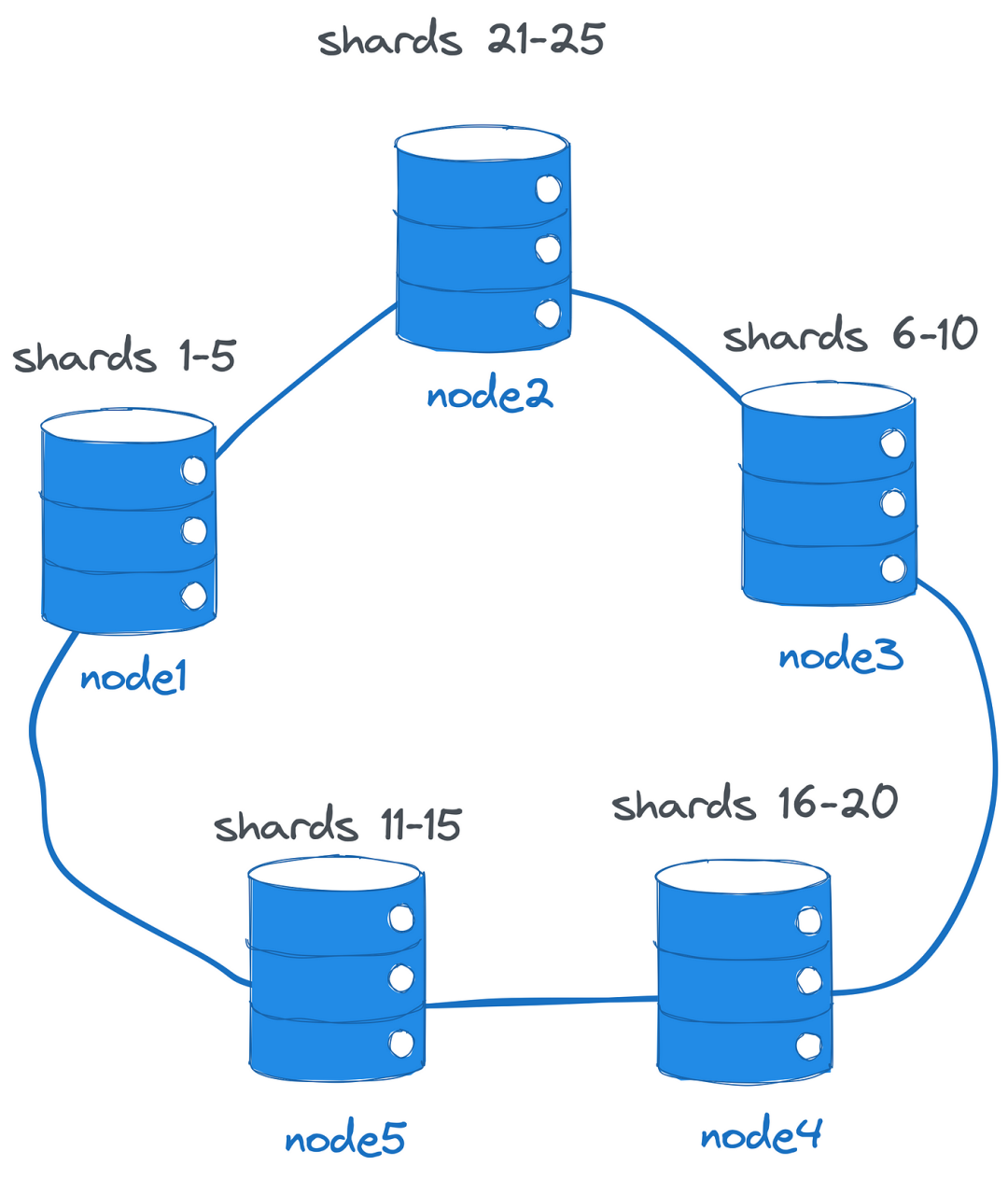
分布式數據庫建立在共享無關架構上,沒有像協調器這樣的單一組件負擔著做出許多決策:
1*deOgcXccWs9lKUSgLPNOww.png
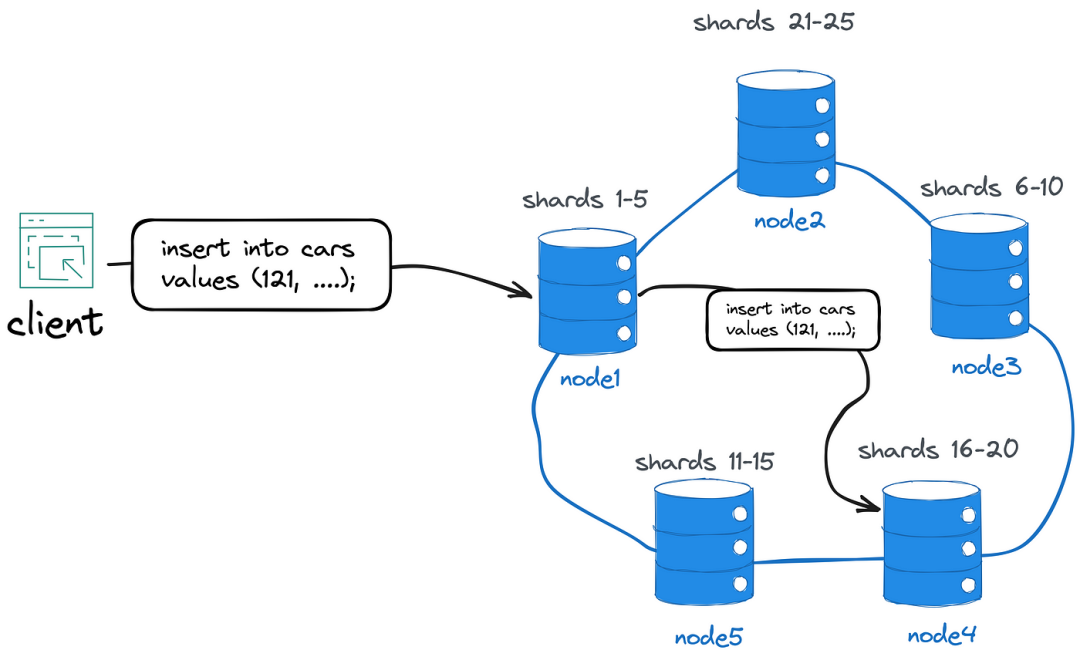
集群中的所有節點都知道對方,因此也知道數據的分布。通過直接通信,每個節點可以將客戶端請求路由到適當的分片所有者。此外,它們可以執行和協調多節點事務。當擴展到更多節點時,集群會自動重新平衡和分割分片。節點保持數據的冗余副本(基于配置的復制因子),即使某些節點失敗,也可以繼續操作而無需停機。
所有這些對于客戶端來說是透明的,客戶端只需與任何節點建立連接,然后允許該節點管理分布式方面。
例如,客戶端可能連接到node1并插入具有id121的新的Car記錄。如果node1是記錄分片的所有者,則它將在本地存儲記錄,并使用共識算法將更改復制到其他節點的子集。如果不是,node1將記錄轉發到分片的所有者,可能是node4。
1*weEdq2BxIpf6GiLjipns5Q.png
如果您有興趣探索真正分布式數據庫的架構,請考慮研究Google Spanner,YugabyteDB,CockroachDB,Apache Cassandra或Apache Ignite。
在數據庫領域,分片和分布經常被混為一談,但它們有著不同的目的。
雖然分片涉及將數據分割到多個獨立的實例中,但這并不意味著系統本質上是分布式的。分片解決方案中協調器的存在,該協調器指導客戶端請求到適當的分片,突顯了這一區別。
另一方面,建立在共享無關架構上的分布式數據庫缺乏這種集中式協調器。這些系統中的節點都知道對方,管理數據分布,并無縫處理客戶端請求。
這兩種架構都有其優點,了解它們的細微差別對于進行數據庫設計和選擇至關重要。