













和谷歌搜索搶活,FRESHLLM「緊跟時事」,幻覺更少,信息更準
大型語言模型的能力有目共睹,如 BARD 和 CHATGPT/GPT-4,被設計成多功能開放域聊天機器人,可以就不同主題進行多輪對話。它們能夠幫助人們完成諸多任務,但這并不代表它們是萬能的。
「幻覺」與過時的信息降低了這些大模型回復的可信度。尤其對于需要信息實時更新的領域(如公司股價)而言,這更是嚴重。
與 GPT-4 對話過程中,會發現它的信息更新有限制
這種現象可部分歸因于其參數中存在編碼的過時知識。雖然利用人類反饋或知識增強任務進行額外訓練可以緩解這一問題,這種方法并不容易推廣。另外,上下文學習是一種有吸引力的替代方法,可將實時知識注入 LLM 的提示中以生成條件。雖然近期的一些研究已經開始探索利用網絡搜索結果來增強 LLM,但如何充分利用搜索引擎的輸出來提高 LLM 的事實性尚不清楚。
在一篇最新的論文中,來自谷歌、馬薩諸塞大學阿默斯特分校、OpenAI 的研究者發現,Perplexity 和 GPT-4 w/prompting 的性能優于谷歌搜索。同時,越來越多的非科技人員在搜索查詢時使用 Perplexity 而不是其他 LLM。那么谷歌搜索真的會被 LLM 取代嗎?
有網友表示,雖然在簡單問題上,LLM 的表現更好,但是對于大模型的「幻覺」問題依然保持謹慎態度他們使用谷歌搜索驗證大模型的回復。
其實,研究者也致力于解決大模型知識過時的問題。接下來,我們一起看看他們的成果。

論文地址:https://arxiv.org/pdf/2310.03214.pdf
FRESHQA 數據集
在這項工作中,研究者先是創建了一個名為「FRESHQA」的新型質量保證基準,用于評估現有 LLM 生成內容的事實性。FRESHQA 包含 600 個自然問題,大致分為圖 1 所示的四大類。這些問題跨越了一系列不同的主題,具有不同的難度級別,并要求模型「理解」世界上的最新知識,以便能夠正確回答。
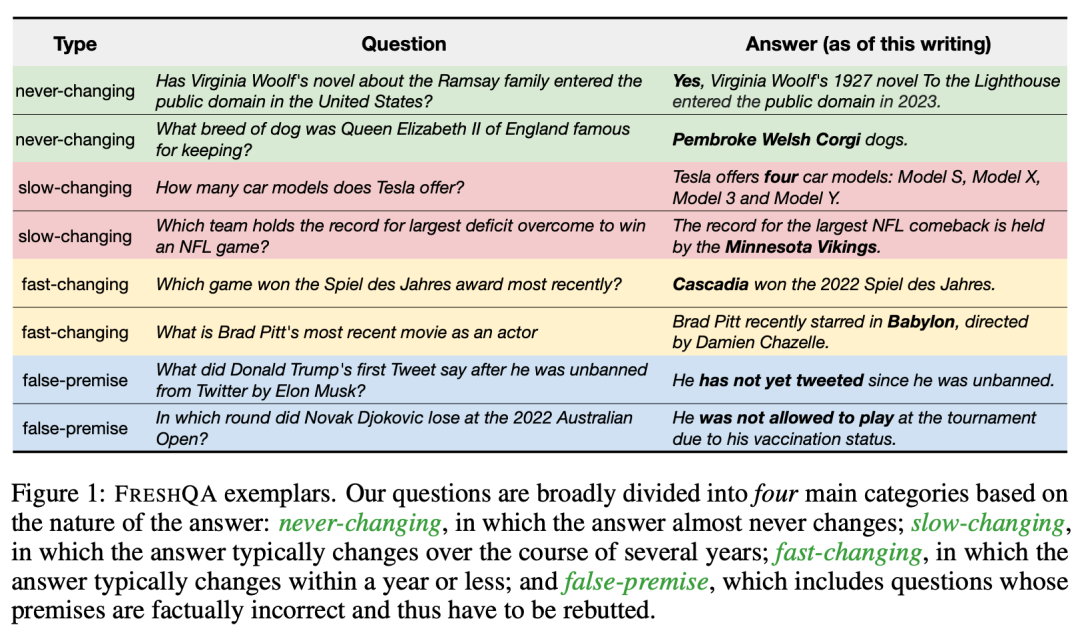
此外,FRESHQA 還具有動態性:一些 ground-truth 答案可能會隨著時間的推移而改變,被歸入特定類別的問題可能會在以后的某個時間點被重新分類。就比如,「馬斯克與現任配偶結婚多久了?」在當前是一個虛假推理問題,但如果馬斯克在未來再次結婚,該問題被歸入的類別就需要變一變了。
研究者招募了一些 NLP 研究人員(包括作者及其同事)和線上自由撰稿人來收集 FRESHQA 的數據。在四類問題中的每一類中,都要求注釋者撰寫兩種不同難度的問題:一跳(one-hop),即問題明確提到了回答該問題所需的所有相關信息,因此不需要額外的推理(例如,誰是 Twitter 的首席執行官);多跳(multi-hop),即問題需要一個或多個額外的推理步驟才能收集到回答該問題所需的所有相關信息(例如,世界上最高建筑的總高度是多少?)
研究者通過向不同的 LLM 提出問題和一些問答示范,然后對其回答進行采樣,以此來衡量它們在 FRESHQA 上的表現,然后對模型回答的事實準確性進行了廣泛的人工評估,包括超過 50K 個判斷。此處采用雙模式評估程序對每個回答進行評估:「RELAXED」模式只衡量主要答案是否正確,「STRICT」模式則衡量回答中的所有說法是否都是最新的事實(即沒有幻覺)。
這個評估過程揭示了新舊 LLM 的事實性,并揭示了不同問題類型帶來的不同模型行為。不出所料,在涉及快速變化知識的問題上,會出現平坦的縮放曲線:簡單地增加模型大小并不能帶來可靠的性能提升。在假前提問題上,他們也觀察到了類似的趨勢。不過,如果明確詢問「請在回答前檢查問題是否包含有效前提」,一些 LLM 就能夠揭穿假前提問題。
總體來說,FRESHQA 對當前的 LLM 來說確實是一個挑戰,指出了很大的改進空間。
提示搜索引擎增強的語言模型
受到上述探索的啟發,研究者進一步研究了如何通過將搜索引擎提供的準確和最新信息作為 LLM 響應的基礎,有效提高 LLM 的事實性。鑒于大型 LLMS 的快速發展和知識不斷變化的性質,研究者探索了上下文學習方法,使 LLM 能夠通過其提示關注推理時提供的知識。
隨后,研究者評估了 LLM 搜索引擎增強對 FRESHQA 的影響,并提出了一種簡單的少樣本提示方法 FRESHPROMPT。該方法通過將檢索自搜索引擎(谷歌搜索)的最新相關信息整合到提示中,極大地提升了 LLM 的 FRESHQA 性能。
下圖 3 為 FRESHPROMPT 的格式。

FRESHPROMPT 方法
FRESHPROMPT 方法利用一個文本提示來將來自搜索引擎的上下文相關的最新信息(包括相關問題的答案)引入到一個預訓練 LLM,并教導該模型對檢索到的證據進行推理。
更具體來講,給定一個問題 q,研究者首先逐字地使用 q 來查詢搜索引擎,這里是谷歌搜索。他們檢索了所有搜索結果,包括答案框、自然結果和其他有用的信息(如知識圖譜、眾包 QA 平臺上的問答)、以及搜索用戶問的相關問題。示例如下圖 6 所示。

對于每個這樣的結果,研究者提取了相關的文本片段 x 以及其他的信息,比如來源 s(如維基百科)、日期 d、標題 t 和高亮文字 h,然后創建包含 k 個檢索到的證據的列表 E = {(s, d, t, x, h)}。接下來這些證據將轉換成常見的格式(如上圖 3 左),并通過上下文內學習來調整模型。此外為了鼓勵模型基于最近的結果來專注于較新的證據,研究者從舊到新對提示中的證據 E 進行排序。
為了幫助模型來理解任務和預期的輸出,研究者在輸入提示的開頭提供了輸入輸出示例的少樣本演示。每個演示首先為模型提供一個問題示例以及該問題的一組檢索到的證據,然后對證據進行思維鏈推理以找到最相關、最新的答案(如上圖 3 右)。
盡管研究者在演示中包含了少數帶有錯誤前提的問題示例,但也嘗試了在提示中進行顯式錯誤前提檢查,比如「請在回答前檢查問題中是否包含有效前提」。下圖 7 展示了一個真實的提示。

實驗設置
對于 FRESHPROMPT 設置,研究者通過將檢索到的證據整合到輸入提示中,依次將 FRESHPROMPT 應用于 GPT-3.5 和 GPT-4 中。這些證據包括了自然搜索結果 0、搜索用戶問的相關問題 r、來自眾包 QA 平臺上的問答 a 以及來自知識圖譜和答案框的文本片段(如有)。考慮到模型上下文的限制,他們在根據相應日期排序后僅保留前 n 個證據(更靠近提示末尾)。
除非另有說明,研究者針對 GPT-3.5 使用了 (o, r, a, n,m) = (10, 2, 2, 5),針對 GPT-4 使用了 (o, r, a, n,m) = (10, 3, 3, 10)。此外,他們在提示的開頭包含了 m = 5 個問答演示。
實驗結果
FRESHPROMPT 顯著提升了 FRESHQA 的準確性。下表 1 展示了 STRICT 模式下的具體數字。可以看到,相對于原始 GPT-3.5 和 GPT-4,FRESHPROMP 實現了全方位的重大改進。
其中,GPT-4 + FRESHPROMPT 在 STRICT 和 RELAXED 模式下分別較 GPT-4 實現了 47% 和 31.4% 的絕對準確率提升。STRICT 和 RELAXED 之間絕對準確率差距的縮小(從 17.8% 到 2.2%)也表明,FRESHPROMP 可以極大地減少過時和幻覺答案的出現。
此外,GPT-3.5 和 GPT-4 最顯著的改進是在快速和緩慢變化的問題類別,這些問題涉及最新知識。這意味著,關于舊知識的問題也受益于 FRESHPROMPT。比如在 STRICT 模式下,對于包含 2022 年以前知識的有效前提的問題,GPT-4 + FRESHPROMPT 的準確率比 GPT-4 高了 30.5%;在 RELAXED 模式下這一數字是 9.9%。
此外,FRESHPROMPT 在假前提問題上也取得了顯著的進步,GPT-4 在 STRICT 和 RELAXED 模式下的準確率分別提升了 37.1% 和 8.1%。

此外,FRESHPROMPT 還展示出了以下結果:
- 大幅度優于其他搜索增強方法;
- 前提檢查增強了假前提問題的準確率,但會損害具有有效前提的問題的準確率;
- 在輸入上下文的末尾提供更多最新的相關證據是有幫助的;
- 自然搜索結果之外檢索到的其他信息提供了進一步增益;
- 檢索到的證據越多會進一步提升 FRESHPROMPT;
- 冗長的演示有助于回答復雜的問題,但也會增加幻覺。
研究者表示,他們目前僅針對每個問題進行一次搜索查詢,因此可以通過問題分解和多個搜索查詢來進一步實現提升。此外,由于 FRESHQA 包含的是相對簡單的英語問題,因此不清楚在多語言 / 跨語言 QA 和長格式 QA 上下文中的表現如何。最后 FRESHPROMPT 依賴上下文內學習,因此可能不如根據新知識來微調基礎 LLM 的方法。
更多技術細節,請參閱原論文。





















