全抖音都在說家鄉話,兩項關鍵技術助你“聽懂”各地方言
國慶期間,抖音上“一句方言證明你是地道家鄉人”的活動在吸引了全國各地的網友熱情參與,話題最高登上抖音挑戰榜第一位,播放量已超過5000萬。
這場“各地方言大賞”之所以能火出圈,抖音新上線的地方方言自動翻譯功能功不可沒。創作者們在用家鄉話錄制短視頻時,使用“自動字幕”功能,選擇“轉為普通話字幕”,即可完成對視頻內容方言語音的自動識別,并將視頻里的方言內容轉化為普通話字幕,讓其他地區的網友也能無痛聽懂各種“加密型國語”。有來自福建網友親測表示,連“十里不同音”的閩南語也能翻譯得分毫不差,大呼“閩南語在抖音上為所欲為的日子一去不復返了”。

眾所周知,語音識別和機器翻譯的模型訓練需要大量的訓練數據,但方言作為口語流傳,可用于模型訓練的方言語料數據很少,那么,為這項功能提供技術支持的火山引擎技術團隊是如何突破的呢?
方言識別階段
一直以來,火山語音團隊都為時下風靡的視頻平臺提供基于語音識別技術的智能視頻字幕解決方案,簡單來說就是可以自動將視頻中的語音和歌詞轉化成文字,來輔助視頻創作的功能。
在這個過程中,技術團隊發現,傳統的有監督學習會對人工標注的有監督數據產生嚴重依賴,尤其在大語種的持續優化以及小語種的冷啟動方面。以中文普通話和英語這樣的大語種為例,盡管視頻平臺提供了充足的業務場景語音數據,但有監督數據達到一定規模之后,繼續標注的ROI將非常低,必然需要技術人員考慮如何有效利用百萬小時級別的無標注數據,來進一步改善大語種語音識別的效果。
相對小眾的語言或者方言,由于資源、人力等原因,數據的標注成本高昂。在標注數據極少的情況下(10小時量級),有監督訓練的效果非常差,甚至可能無法正常收斂;而采購的數據往往和目標場景不匹配,無法滿足業務的需要。
對此,團隊采用了以下方案:
- 低資源方言自監督
基于Wav2vec 2.0自監督學習技術,團隊提出了Efficient Wav2vec,實現了極少量標注數據條件下的方言ASR能力。為解決Wav2vec2.0訓練慢、效果不穩定的問題,一方面,用filterbank特征取代waveform降低計算量、縮短序列長度,同時降低幀率,實現訓練效率翻倍;另一方面,通過等長數據流和自適應連續mask,大幅改善了訓練的穩定性和效果。
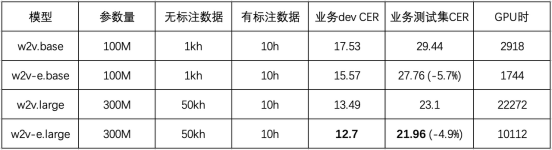
該實驗在粵語上進行,使用了5萬小時無標注語音和10小時標注語音。結果如下表所示,Efficient Wav2vec (w2v-e)在100M和300M參數量的模型下,相比Wav2vec 2.0,CER相對下降5%,訓練開銷減半。
進一步,團隊以自監督預訓練模型微調得到的CTC模型作為種子模型,對無標注數據打偽標簽,然后提供給一個參數量較小的端到端LAS模型做訓練,同步實現了模型結構的遷移和推理計算量的壓縮,可以直接基于成熟的端到端推理引擎部署上線。該技術已成功應用于兩個低資源方言,用10小時量級的標注數據實現了低于20%的字錯誤率。
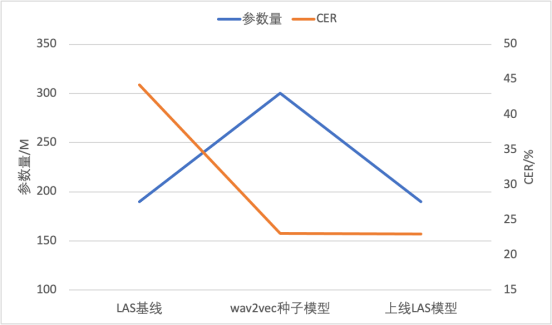
圖說:模型參數量和CER對比
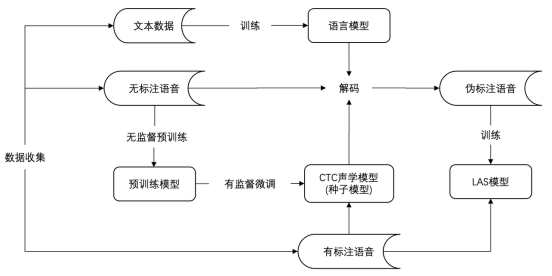
圖說:基于無監督訓練ASR的落地流程
- 方言大規模pretrain+finetune訓練模式
當有監督數據標注結束后,ASR模型的持續優化是一個很重要的研究方向。過去很長一段時間,半/無監督學習一直很火熱,無監督pretrain主要思想是,充分利用用未標記的數據集來擴充已標記的數據集,能夠實現小數據量的平行語料取得比較好的識別效果。算法流程如下:
(1)首先,利用人工標注的有監督數據訓練出種子模型,然后利用該模型對未標注的數據進行偽標簽標記。
(2)在偽標簽生成過程中,由于種子模型對未標記數據的所有預測都不可能都是準確的,因此需要利用一些策略過率訓練價值低的數據。
(3)其次,將生成的偽標簽與原始的標記數據相結合,并在合并后數據上進行聯合訓練。
(4)由于在訓練過程加入了大量的無監督數據,即使無監督數據偽標簽質量不及有監督數據,但是,往往能夠得到比較通用的表征。我們基于大數據訓練出的pretrain模型,用人工精標的方言數據進行finetune。這樣可以保留pretrain帶來的優秀的泛化性,同時提升模型對方言的識別效果。
5個方言的平均CER(字錯誤率)從35.3%優化到17.21%。
平均字錯誤率 | 粵語 | 閩南 | 上海 | 中原官話 | 西南官話 | |
單方言 | 35.3 | |||||
100wh pretrain+方言混合finetune | 17.21 | 13.14 | 22.84 | 19.60 | 19.50 | 10.95 |
方言翻譯階段
通常情況下,機器翻譯模型的訓練離不開大量語料的支持,然而方言常以口語形式流傳,現今方言使用者的數量也逐年減少,這些現象都提升了方言語料數據收集的難度,方言的機器翻譯效果也難以提升。
為了解決方言語料不足的問題,火山翻譯團隊提出多語言翻譯模型 mRASP (multilingual Random Aligned Substitution Pre-training)和 mRASP2,通過引入對比學習,輔以對齊增強方法,將單語語料和雙語語料囊括在統一的訓練框架之下,充分利用語料,來學習更好的語言無關表示,由此提升多語言翻譯性能。

論文地址:https://arxiv.org/abs/2105.09501
加入對比學習任務的設計是基于一個經典的假設:不同語言中同義句的編碼后的表示應當在高維空間的相鄰位置。因為不同語言中的同義句對應的句意是相同的,也就是“編碼”過程的輸出是相同的。比如“早上好”和“Good morning”這兩句話對于懂中文和英文的人來說,理解到的意思是一樣的,這也就對應了“編碼后的表示在高維空間的相鄰位置”。
訓練目標設計
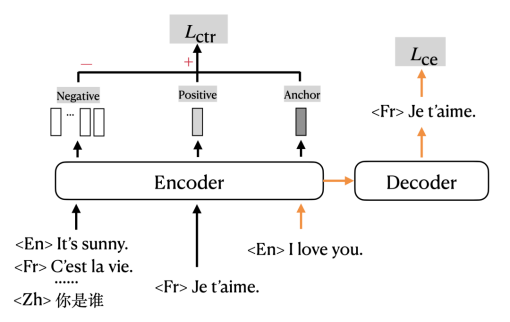
mRASP2在傳統的交叉熵損失 (cross entropy loss) 的基礎上,加入了對比損失 (contrastive loss) ,以多任務形式進行訓練。圖中橙色的箭頭指示的是傳統使用交叉熵損失 (Cross Entropy Loss, CE loss) 訓練機器翻譯的部分;黑色的部分指示的是對比損失 (Contrastive Loss, CTR loss) 對應的部分。
詞對齊數據增強方法又稱對齊增強(Aligned Augmentation, AA),是從mRASP的隨機對齊變換(Random Aligned Substitution, RAS)方法發展而來的。
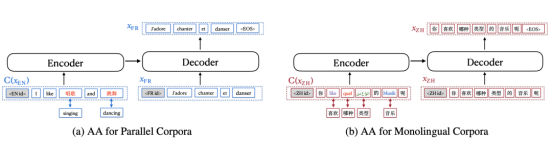
如圖所示,圖(a)表示了對平行語料的增強過程,圖(b)表示了對單語語料的增強過程。其中,圖(a)中原本的英語單詞被替換成中文對應的單詞;而圖(b)中原本的中文單詞被分別替換成英文、法語、阿拉伯語、德語。mRASP的RAS等價于第一種替換方式,它只要求提供雙語的同義詞詞典;而第二種替換方式需要提供包含多種語言的同義詞詞典。值得提一句,最終使用對齊增強方法的時候,可以只采用(a)的做法或者只采用(b)的做法。
實驗結果表明mRASP2在有監督、無監督、零資源的場景下均取得翻譯效果的提升。其中有監督場景平均提升 1.98 BLEU,無監督場景平均提升 14.13 BLEU,零資源場景平均提升 10.26 BLEU。該方法在廣泛場景下取得了明顯的性能提升,可以大大緩解低資源語種訓練數據不足的問題。
寫在最后
方言與普通話相輔相成,都是中華傳統文化的重要載體,以方言為載體的“鄉音”更是中國人故鄉的情感符號和情感紐帶,借助短視頻和方言翻譯,有助于廣大用戶無障礙欣賞天南海北不同區域的文化。
當前,抖音「方言翻譯」功能現已支持粵語、閩語、吳語(上海)、西南官話(四川)、中原官話(陜西、河南)等,據說未來還將支持更多方言,一起拭目以待吧。