













斯坦福公開十大主流模型透明度!Llama 2位列第一,GPT-4透明差,LeCun炮轟:盈利完全理解
GPT-4、Llama等基礎模型(FM)相繼誕生,已成為當前生成式AI的引擎。
盡管這些FM的社會影響力不斷增大,但透明度反而下降。
GPT-4官宣后,OpenAI公布的技術報告中,并未提及關鍵信息。包括谷歌PaLM,以及其他閉源模型也是如此。

每個人心中不禁有許多疑問:
模型如何訓練?如何部署?訓練數據從哪來?
構建這些AI系統背后,數據標注反饋的人是誰?他們薪水是多少?
除了以上問題等等,其透明度無論是對公司,還是對社會,都十分重要。
這不,斯坦福、MIT、普林斯頓團隊提出了一個「基礎模型透明度指數」,并對當前十個主流模型的透明度進行了評級。

地址:https://crfm.stanford.edu/fmti/
結果顯示,10個模型中最透明的是Llama 2,得分為54%。GPT-4、PaLM 2都排在后面。
研究者承認,透明度確實是一個寬泛的概念。
斯坦福對于模型評分基于100個指標,這些指標涉及模型是如何構建、如何工作以及人們如何使用它們等等。
沒想到的是,這個評分系統卻引眾多研究者炮轟,HuggingFace的聯合創始人、LeCun都在其列。
斯坦福AI模型的公開排名,可能與模型的能力相反。而要求私人公司公開商業機密的想法太幼稚。
HuggingFace聯創表示,這并非曼哈頓計劃,初創公司選擇不公開是為了盈利,完全可以理解。
并且,只要它們不以虛假的「安全理由」推動監管,限制那些想要開源的公司就行。
具體看看,這份報告是如何對模型透明度進行評估的。
生成式AI模型,急需透明度!
現在,基礎模型的社會影響不斷上升,但透明度卻在下降。
如果這種趨勢持續下去,基礎模型可能會變得像社交媒體平臺和其他以前的技術一樣不透明,從而重蹈他們的覆轍。

從具體角度來講,生成式AI是一把雙刃劍,其既可以提高生產力,也可以用來傷害他人,有些人通過創建未經同意的深度偽造圖片和視頻,用于私有目的。
開發商確實有禁止此類用途的政策。例如,OpenAI的政策禁止一長串用途,包括使用其模型為他人生成未經授權的法律、財務或醫療建議。

但這些政策如果執行不到位,就無法產生實際的影響,而且由于平臺在執行方面缺乏透明度,我們不知道它們是否有效。
老練的壞人可能會使用開源工具生成傷害他人的內容,因此政策永遠不可能是一個全面的解決方案。
基礎模型透明度指數
「2023年基礎模型的透明度指數」由斯坦福大學基礎模型研究中心(CRFM)和以人為中心的人工智能研究所(HAI)、麻省理工學院媒體實驗室、普林斯頓大學信息技術中心的8名人工智能研究人員創建。

論文地址:https://arxiv.org/pdf/2310.12941.pdf
該團隊的共同目的是提高基礎模型的透明度。
評估的指標除了技術方面(數據、計算和模型訓練過程的詳細信息)之外,還包括訓練基礎模型的社會方面(對勞動力、環境和實際使用的使用政策的影響)。
此外,還需要評估其他指標,例如,開發人員是否披露執行數據勞動的工人的工資、用于開發模型的計算資源以及他們如何執行其使用政策。

這些指標基于并綜合了過去旨在提高人工智能系統透明度的干預措施,例如模型卡、數據表、評估實踐以及基礎模型如何協調更廣泛的供應鏈。
透明度報告的統計與發現
定義指標
在透明度報告中,定義了100個指標,全面表征基礎模型開發人員的透明度。可將指標分為三大領域:
1. 上游:上游指標指定了構建基礎模型所涉及的成分和流程,例如用于構建基礎模型的計算資源、數據和勞動力。
2. 模型:模型指標指定基礎模型的屬性和功能,例如模型的架構、功能和風險。
3. 下游:下游指標指定基礎模型的分發和使用方式,例如模型對用戶的影響、模型的任何更新以及管理其使用的策略。
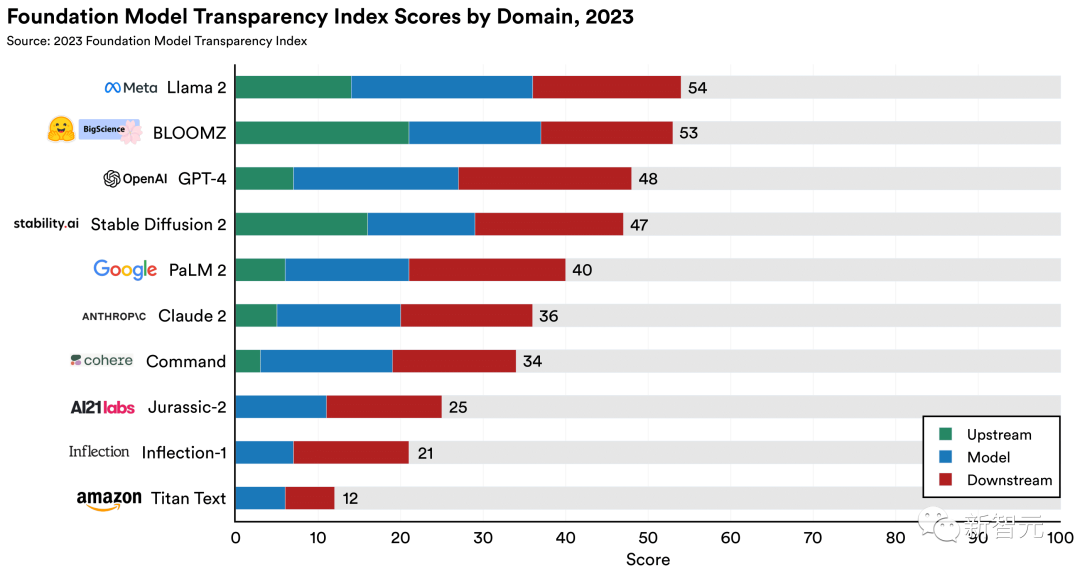
10個基礎模型提供商的分數(按領域細分)
根據該指數的100項指標評估10個主要基礎模型開發商及其旗艦模型,并全面找到需要改進的領域。
主要發現
通過計算,10個模型的平均分僅37分(滿分100分),即使是最高得分的模型也勉強超過50分。
沒有一家主要的基礎模型開發商能夠提供足夠的透明度,這揭示了人工智能行業根本上缺乏透明度。

然而,有一個模型滿足了其中82項指標,這表明如果其他開發人員能夠實施他們已經采用的實踐,那么有改進的空間。
開源基礎模型需要引領潮流,在三個開源基礎模型(Llama 2、BLOOMZ、Stable Diffusion 2)中的兩個獲得了兩個最高分,兩者都允許下載模型權重。
Stability AI是第三個開源基礎模型開發公司,排名第4,僅次于OpenAI。
其他發現
在對模型進行評分后,研究團隊主動聯系了相關公司,尋求他們的回應和反駁。
下圖顯示了在解決開發者的反駁后,每個模型的最終得分情況還,并將指標分組為子域。其中子域提供了更精細、更直觀的分析。
1. 數據、勞動力和計算是開發人員的盲點。
開發人員對于構建基礎模型所需的資源最不透明。這是由于數據、勞動力和計算子領域的低性能造成的。所有開發人員的分數總計僅占數據、勞動力和計算可用總分的 20%、17% 和 17%。
2. 開發人員對于用戶數據保護及其模型的基本功能更加透明。

開發者在與用戶數據保護(67%)、基礎模型開發方式的基本細節(63%)、模型的功能(62%)和局限性(60%)相關的指標上得分很高。
這反映了開發人員在如何處理用戶數據及其產品基本功能方面的一定程度的基線透明度。
3. 即使在開發人員最透明的子域中也存在改進的空間。
只有少數開發人員透明地展示其模型的局限性或讓第三方評估模型的功能。
雖然每個開發人員都描述了其模型的輸入和輸出模式,但只有三個開發人員公開了模型組件,并且只有兩個開發人員公開了模型大小。
開源或閉源模型
當今人工智能領域最具爭議的政策爭論之一是人工智能模型應該開源還是閉源。
雖然人工智能的發布策略不是二元的,但為了分析,將權重可廣泛下載的模型標記為開放。
下面列表中的3個開發人員(Meta、Hugging Face和Stability AI)開發了開源基礎模型(分別為Llama 2、BLOOMZ和Stable Diffusion2),其模型權重可以下載。
其他7名開發人員構建了閉源的基礎模型,模型權重不可公開下載,并且必須通過API訪問模型。

開源模型(Meta的Llama-2、Hugging Face的BLOOMZ和Stability AI的 Stable Diffusion 2)處于領先地位
開源模型處于領先地位。
三個開源模型中的兩個(Meta 的 Llama 2 和 Hugging Face 的 BLOOMZ)得分大于或等于最佳閉源模型, Stability AI的Stable Diffusion 2緊隨OpenAI的GPT-4之后。
這種差異很大程度上是由于閉源的開發人員在上游問題上缺乏透明度造成的,例如用于構建模型的數據、勞動力和計算,如下圖。
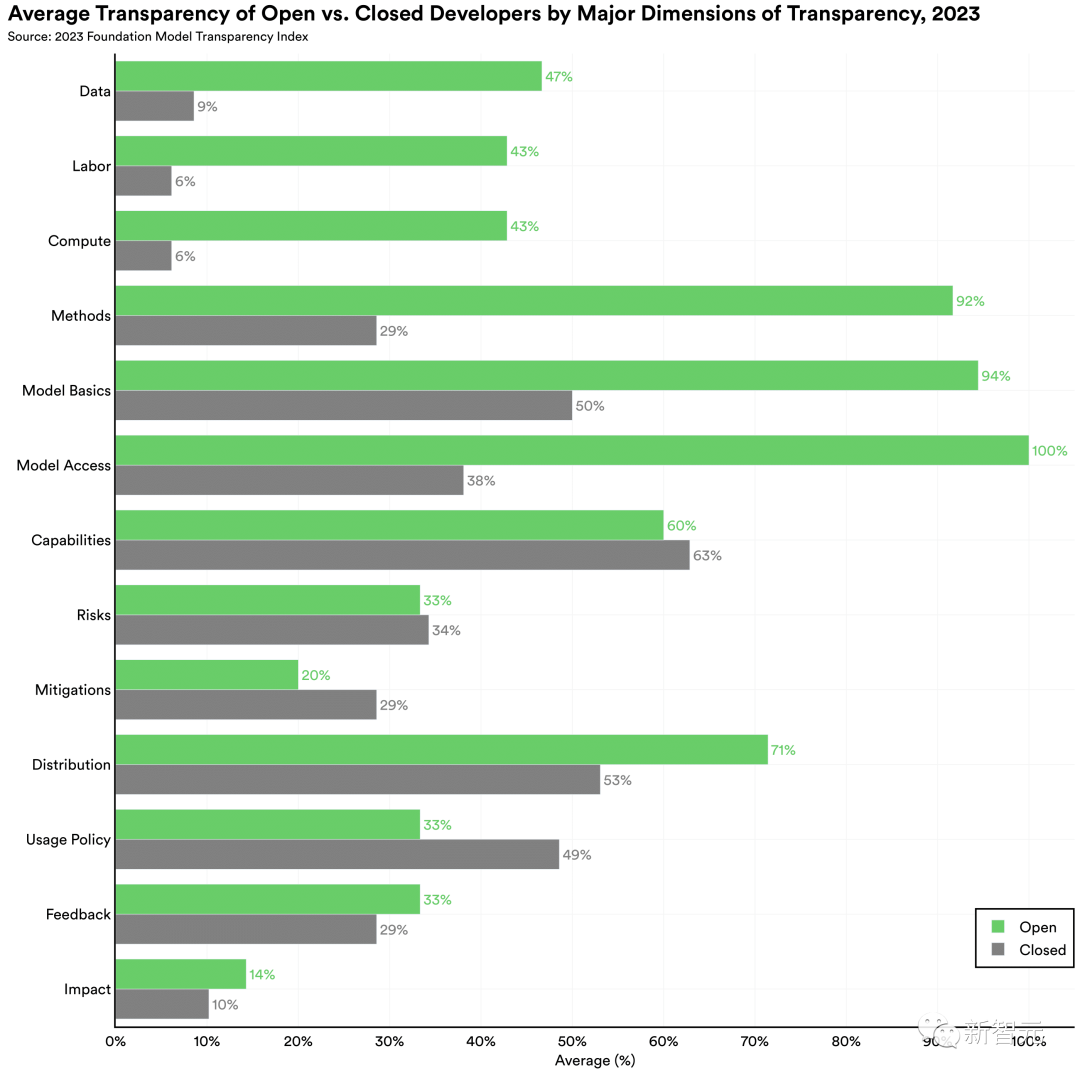
開源模型和閉源模型之間的差異是由上游指標驅動的,例如用于開發模型的數據、勞動力和計算的詳細信息
就總體得分而言,開源基礎模型開發者處于領先地位。開源模型和閉源模型開發人員之間的差異在構建模型所需資源(例如數據和計算)的指標上尤其明顯。近年來,許多閉源模型的開發人員對訓練模型的方法變得越來越保密。
如果想進一步了解方法與分析的結論,可以參考以下鏈接。
對于這些工作,有些網友還是對此表示認同。
有的人認為,推進模型透明度這項工作很有意義:這真的很酷,向前邁出了一大步!

還有網友表示這項工作太了不起了,并向作者提問如何看待最高比例只有54%的這個事實。
作者回應道,總體得分低得令人有些沮喪,但是有一個模型滿足了82/100項,這意味著當前的限制還是可行的。


























