斯坦福大學發布 AI 基礎模型“透明度指標”,Llama 2 以 54% 居首但“不及格”

10 月 20 日消息,斯坦福大學日前發布了 AI 基礎模型“透明度指標”,其中顯示指標最高的是 Meta 的 Lama 2,但相關“透明度”也只有 54%,因此研究人員認為,市面上幾乎所有 AI 模型,都“缺乏透明度”。
據悉,這一研究是由 HAI 基礎模型研究中心(CRFM)的負責人 Rishi Bommasani 所主導,調查了海外最流行的 10 款基礎模型:
- Meta 的 Llama 2、
- BigScience 的 BloomZ、
- OpenAI 的 GPT-4、
- Stability AI 的 Stable Diffusion、
- Anthropic PBC 的 Claude、
- 谷歌的 PaLM 2、
- Cohere 的 Command、
- AI21 Labs 的 Jurassic-2、
- Inflection AI 的 Inflection、
- 亞馬遜的 Titan。
Rishi Bommasani 認為,“缺乏透明度”一直是 AI 行業所面臨的問題,在具體模型“透明度指標”方面,IT之家發現,相關評估內容主要圍繞“模型訓練數據集版權”、“訓練模型所用的運算資源”、“模型生成內容的可信度”、“模型自身能力”、“模型被誘導生成有害內容的風險”、“使用模型的用戶隱私性”等展開,共計 100 項。
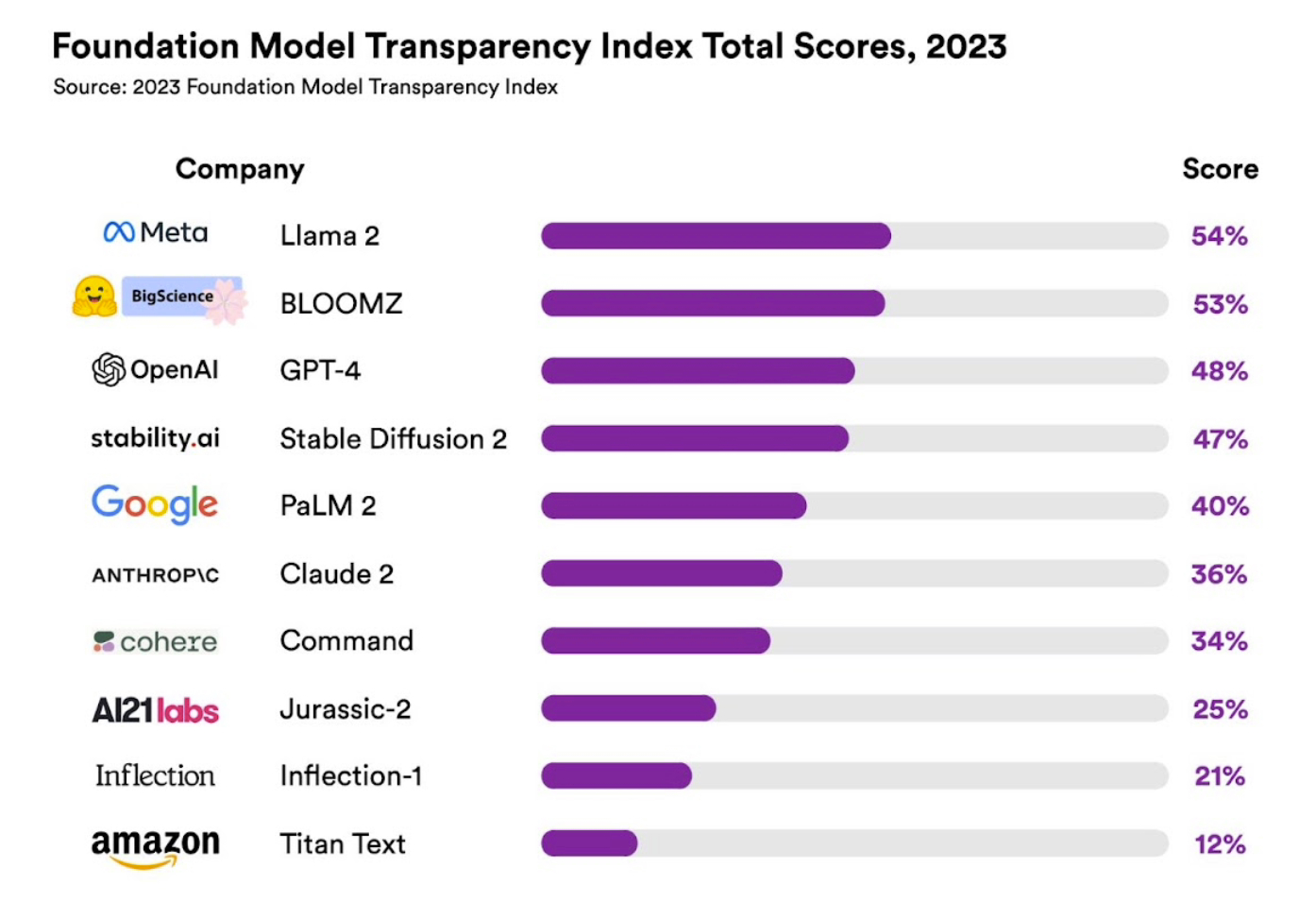
最終調查情況顯示,Meta 的 Lama 2 以 54% 的透明度居冠,而 OpenAI 的 GPT-4 透明度只有 48%,谷歌的 PaLM 2 則以 40% 排名第五。
 ▲ 圖源 斯坦福大學
▲ 圖源 斯坦福大學
在具體指標中,十大模型得分表現均“最好”的是“模型基本信息”(Model Basics),這一評估內容主要包含“模型訓練上是否準確介紹了模型的模式、規模、架構”,平均透明度為 63%。表現最差的則是影響(Impact),主要評估基礎模型是否會“調取用戶信息進行評估”,平均透明度只有 11%。
CRFM 主任 Percy Liang 表示,商業基礎模型的“透明度”對于推動 AI 立法,及相關產業、學術界而言,非常重要。
Rishi Bommasani 則表示,較低的模型透明度讓企業更難知道它們能否安全地依賴相關模型,也難以令研究人員依靠這些模型來做研究。
Rishi Bommasani 最終認為,上述十大基礎模型在透明度方面都“不及格”,雖然 Meta 的 Llama 2 得分最高,但并不能滿足外界需求,“模型透明度最少要達到 82%,才能被外界認可”。