適合初學者的一些常用的機器學習庫
在人工智能項目開發的過程中,我們通常會使用到很多機器學習、深度學習框架、各種數據處理庫和一些工具。好用的庫很多,但對于初學者來說先聚焦在一些比較常用的框架、庫或者工具,有利于提高效率。下面主要分享一些常用的人工智能相關的內容,包括:模型訓練、數據處理、參數優化、實驗跟蹤、特定領域庫以及一些工具。

一、模型訓練
1.PyTorch
PyTorch是Facebook開發并于2017年開源的深度學習框架,這個框架基于開源Torch包,目前是業界使用最廣泛的深度學習框架。
目前PyTorch生態系統已經比較完善,并具有各種專用庫,例如:
torchvision(https://pytorch.org/vision/stable/index.html)或torchaudio(https://pytorch.org/audio/stable/index.html)。因此,PyTorch支持用于幾乎所有類型的機器學習。
PyTorch的數據結構是Tensor對象,用于保存模型訓練和推理過程使用到的多維數據。Tensor的概念與NumPy ndarray相似。PyTorch還支持CUDA功能的NVIDIA GPU,ROCm,Metal API和TPU等來提高訓練效率。
PyTorch庫最重要的部分是nn modules,它包含了層和工具,可以輕松地構建復雜的模型。
下面是一個PyTorch實現簡單神經網絡示例。
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits目前,PyTorch 已經發布了2.0,相比過去,這個版本更快、更接近Python、更靈活。
2.PyTorch Lightning

PyTorch Lightning是PyTorch框架的一個“擴展”,旨在減少編寫模型所需的代碼量。
Lightning基于hook(鉤子)的概念,這種方法允許我們在特定時間執行回調函數,比如訓練結束后執行一些收尾的工作或者輸出。
Trainers Lighting將許多必須在PyTorch中處理的功能自動化實現了,例如:循環、硬件調用或零梯度。
下面是PyTorch(左)與PyTorch Lightning(右)的代碼片段對比。

3.TensorFlow

TensorFlow是由Google Brain團隊開發并于2015年發布的深度學習庫,TensorFlow2.0版本于2019年發布。它支持Java、C++、Python以及JavaScript等多種開發語言。
TensorFlow與PyTorch類似,也是一個非常流行的框架。并且也有一個相當豐富的生態,包括工具和庫,例如:優化工具包TensorBoard、編譯器等。
tf.nn是TensorFlow的核心模塊,它提供了訓練模型所需的構建塊。Tensorflow擁有自己的用于保存用于深度學習的向量數據的Tensor對象。另外,它也支持所有常見的加速器,如CUDA或RoCm,Metal API和TPU。
class NeuralNetwork(models.Model):
def __init__(self):
super().__init__()
self.flatten = layers.Flatten()
self.linear_relu_stack = models.Sequential([
layers.Dense(512, activation='relu'),
layers.Dense(512, activation='relu'),
layers.Dense(10)
])
def call(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits4.Keras
Keras是一個基于TensorFlow框架,但卻提供了比TensorFlow更高級的接口的機器學習框架,有點像PyTorch Lightning 。Keras由Fran?ois Chollet開發并于2015年發布,它只支持Python開發語言。Keras也有自己的一整套Python庫和特定領域庫,例如:KerasCV用于CV領域、KerasNLP用于NLP領域。
在Keras2.4版本之前,Keras支持的后端不僅僅是TensorFlow,但在之后的版本只支持TensorFlow。由于Keras只是TensorFlow上層接口,它支持的加速器也和TensorFlow類似。下面是Keras代碼例子。
class NeuralNetwork(models.Model):
def __init__(self):
super().__init__()
self.flatten = layers.Flatten()
self.linear_relu_stack = models.Sequential([
layers.Dense(512, activation='relu'),
layers.Dense(512, activation='relu'),
layers.Dense(10)
])
def call(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logitsKeras、TensorFlow、PyTorch、PyTorch Lightning 之間的區別
深度學習框架很多,所以給深度學習項目選擇正確的框架可能會有點糾結。PyTorch、PyTorch Lightning 、TensorFlow、Keras 都是目前比較流行的框架,
其實,這四個框架的基礎只有PyTorch和TensorFlow兩個方向。這些框架基本上能夠滿足數據科學家和初學者的需求,但由于每個項目的要求都不一樣,每個開發人員也有不一樣使用習慣,大家都有自己在專業領域的優先考慮方向。
PyTorch 和 TensorFlow這兩個框架之間的主要區別在于它們對模型的定義方式和執行過程不同。
(1) PyTorch
PyTorch使用動態計算圖,這意味著圖是在執行過程中動態定義的。這使得代碼調試更加靈活性和直觀,優點是,開發人員可以在運行時修改圖并輕松檢查中間過程的輸出,缺點是,這種方法可能比靜態圖效率低,特別是對于復雜模型。然而,PyTorch 2.0開始通過torch.compile和FX圖來解決這些問題。
(2) TensorFlow
TensorFlow使用靜態計算圖,這些圖在執行之前被編譯。這使得執行效率更高,因為這種方式可以針對目標硬件進行優化圖或者并行化圖。但是,它的調試更加困難,因為不容易觀察中間結果。
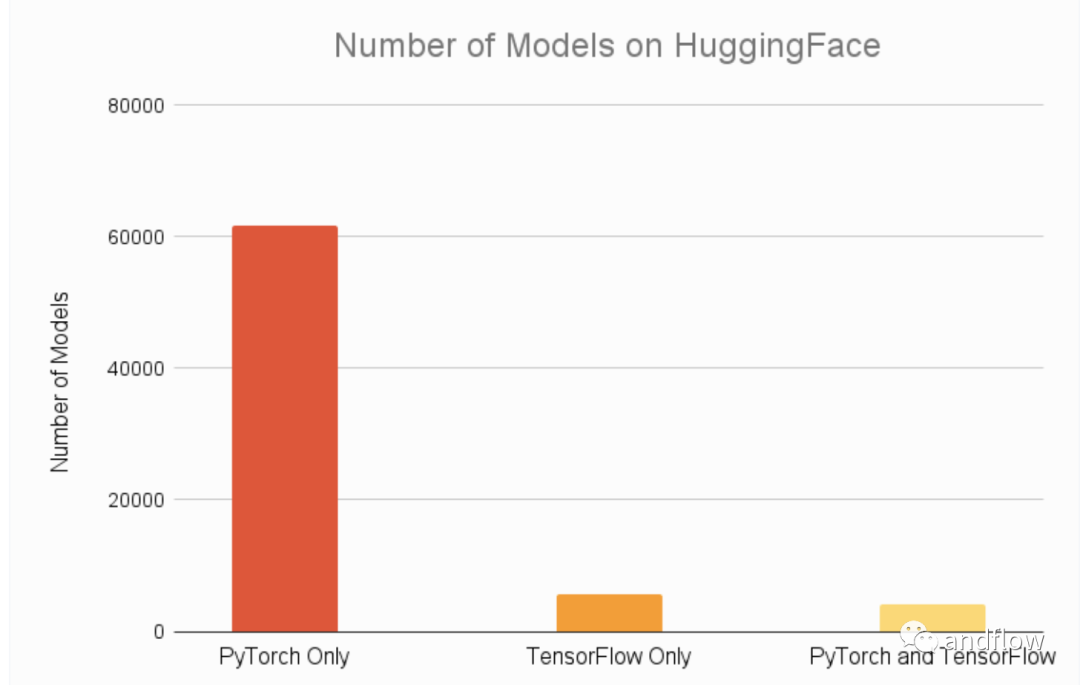
根據2023年HuggingFace的模型數量統計 pytorch已經大大超過tensorflow。
二、數據處理庫
1.pandas
pandas可以說是最著名的數據處理 Python庫。最初于2008年發布,在2012年發布了1.0版本。它提供了過濾、聚合、數據轉換以及數據集合并等功能。這個庫的核心是DataFrame對象,這個對象是任何類型數據的多維表。有些功能是用純C編寫的,所以該庫性能非常好。除了性能之外,pandas還提供了數據清洗和預處理、刪除重復項、填充空值或nan值、時間序列分析、重采樣、加窗、時移等方面的功能。此外,它還可以執行各種輸入/輸出操作:例如:讀寫.csv或.xlsx文件、數據庫查詢、GCP BigQuery數據加載
2.NumPy
NumPy也是一個開源的數據處理庫,使用BSD許可證。NumPy最重要的功能是ndarray,ndarray是一個表示多維數字數組的結構。除了ndarray,NumPy還提供了許多用于處理數據的高級數學函數和數學運算。NumPy還非常注重性能,包含許多預實現的算法,以減少NumPy函數的執行時間。
3.SciPy
SciPy是一個專注于科學計算的庫。ndarray是SciPy的基本數據結構。除此之外,該庫還添加了優化、線性代數、信號處理、插值和備用矩陣等功能。它比NumPy更高級,因此可以提供更復雜的功能。
三、超參數優化
1.Ray Tune
Ray Tune是Ray工具集的一部分,Ray工具集是用于構建機器學習和Python的分布式應用程序的庫。ML庫中的Tune部分,通過提供多種搜索算法,以優化超啟動功能。例如網格搜索、超頻帶或貝葉斯優化。
Ray Tune的主要概念包括:
- Trainables :用于向我們要優化的模型傳遞的Tune對象參數。
- Search space:包含我們要在當前試驗中檢查的所有超參數值
- Tuner :一個執行調用tuner.fit()的返回對象。啟動搜索最佳超參數集的過程。它至少需要傳遞一個可訓練對象和搜索空間
- Trial :每個Trial表示來自搜索空間的精確參數集,Trial由Ray Tune Tuner生成。因為它代表運行調諧器的輸出,所以Trial包含用于特定試驗的配置、Trial ID 等信息。
- Search algorithms :用于Tuner.fit執行的一種算法。默認情況下Ray Tune將使用Radom Search作為默認值。
- Schedulers:一組負責管理運行的對象。他們可以暫停、停止和在執行過程中測試。可以提高效率、減少運行時間。默認情況下Tune選擇FIFO作為默認值,像經典隊列一樣逐個執行。
- Run analyses :以ResultGrid對象的形式包裝Tuner.fit執行結果的對象。它包含與運行相關的所有數據,例如所有試驗中的最佳結果或來自所有試驗的數據。
2.BoTorch
BoTorch是一個基于PyTorch的庫,是PyTorch生態系統的一部分。它專注于貝葉斯算法的超參數優化。作為需要與PyTorch配合使用,還處于測試版和密集的開發中,因此可能會出現一些意想不到的問題。
四、跟蹤監測工具
1.Neptune.ai
Neptune.ai是一個網頁工具,既可以作為跟蹤監測也可以作為模型注冊表。該工具基于云平臺,采用SaaS服務模式。
Neptune.ai提供了一個儀表板,可以觀察模型訓練的結果,還可以用于存儲運行參數以及運行參數的版本化。
Neptune.ai還可以控制模型的版本。該工具與庫無關,可以托管使用任何庫創建的模型。為了支持系統集成,Neptune還公開了一個REST API,并配套完善的API文檔,用戶可以通過pip安裝客戶端庫。
可惜的是,該工具需要付費的。但是,如果只是個人項目或者研究機構,也可以申請免費使用。
2.Weights & Biases
Weights & Biases也稱為WandB或W&B,這是一個基于Web的工具,它提供了可用作跟蹤監測工具和模型注冊表的所有需要的功能,與neptune.ai功能類似。然而相比neptune.ai,Weights & Biases的可視化效果更佳。此外,WandB似乎更專注于為個人項目和研究人員提供服務,并不太強調協作。
Weights Biases還公開了一個REST的API來支持系統集成。與Neptune.ai不同的是,它的客戶端庫是Java包而不是Python庫,這就要求機器學習模型是java開發的。
3.TensorBoard
TensorBoard是TensorFlow生態的可視化工具包。用于算法運行監測和指標可視化。但它也可以與Keras或者PyTorch一起使用。
此外,它是免費的,免費的,免費的,重要的事說三遍。然而,TensorBoard并沒有模型注冊表功能。由于它是TensorFlow生態的一個工具,因此它與Keras或TensorFlow的集成比其他工具都更加順暢。
五、特定領域庫
1.OpenCV
OpenCV的全稱是Open Source Computer Vision Library,是一個跨平臺的計算機視覺庫。OpenCV是由英特爾公司發起并參與開發,以BSD許可證授權發行,可以在商業和研究領域中免費使用。OpenCV可用于開發實時的圖像處理、計算機視覺以及模式識別程序。
opencv主要用于解決以下幾個領域的問題:
- 增強現實
- 人臉識別
- 手勢識別
- 人機交互
- 動作識別
- 運動跟蹤
- 物體識別
- 圖像分割
- 機器人
2.GeoPandas
GeoPandas是一個建立在pandas之上的開源項目,是用來處理地理空間數據的python第三方庫。支持以GeJSON,shapefile格式讀寫數據,或從PostGIS系統讀取數據。除了依賴于pandas,它還依賴于PyGEOS、GeoPy或Shapely等空間數據庫。
六、其他工具
1.Matplotlib
顧名思義,Matplotlib是一個用于創建各種圖表的庫。它支持創建各種復雜的圖表:直線圖、直方圖、3D形狀或極坐標圖等等。它還允許自定義圖表的顏色或標簽之類的內容。
2.Seaborn
Seaborn提供的功能與Matplotlib提供的功能類似。然而,Seaborn的API更加高級,代碼量更少、調色板更柔和、外觀設計更好看。此外,Seaborn還很容易與pandas集成。
以下分別是使用Matplotlib和Seaborn創建的熱圖的代碼。
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
data = np.random.rand(5, 5)
fig, ax = plt.subplots()
heatmap = ax.pcolor(data, cmap=plt.cm.Blues)
ax.set_xticks(np.arange(data.shape[0])+0.5, minor=False)
ax.set_yticks(np.arange(data.shape[1])+0.5, minor=False)
ax.set_xticklabels(np.arange(1, data.shape[0]+1), minor=False)
ax.set_yticklabels(np.arange(1, data.shape[1]+1), minor=False)
plt.title("Heatmap")
plt.xlabel("X axis")
plt.ylabel("Y axis")
cbar = plt.colorbar(heatmap)
plt.show()
sns.heatmap(data, cmap="Blues", annot=True)
# Set plot title and axis labels
plt.title("Heatmap")
plt.xlabel("X axis")
plt.ylabel("Y axis")
# Show plot
plt.show()
3.Hydra
為了項目的靈活性,很多內容都需要形成可配置參數。像Answer工具可以將參數值存放到.env文件中。但是,如果如果參數比較復雜,項目可配置參數實現起來就沒有那么簡單了。Hydra是一個開源工具,用于管理和運行基于Python的應用程序的配置參數。它基于OmegaConf庫,能夠創建分層配置,并通過配置文件和命令行覆蓋它,允許更清晰地分離配置文件。
4.coolname
coolname是一個開源標示符生成庫。如果你不喜歡UUID,或者只是想讓ID更具可讀性,那么coolname就是一個很好的工具。它能夠生成長度從2到4個單詞不等的唯一標識符用于生成一個惟一的標識符。不同的長度有不同的組合的數量:4字長度標識符有1010個組合;3字長度標識符有108種組合;2字長度標識符有105種組合顯然數量明顯低于UUID,因此沖突的概率也更高。所以只能用于特定的場景。
5.tqdm
tqdm庫為應用程序的執行過程提供了一個進度條功能,這個庫只需要Python即可獨立執行。Tqdm還能夠預測任務的剩余時間,并且沒有明顯的性能開銷。可以為執行重要任務的過程,實現進度反饋和剩余時間預測。
6.Jupyter Notebook (+JupyterLab)
Jupyter Notebook(此前被稱為 IPython notebook)是一個交互式筆記本,支持運行 40 多種編程語言。Jupyter Notebook 的本質是一個 Web 應用程序,便于創建和共享程序文檔,支持實時代碼,數學方程,可視化和 markdown。

以上這些內容都是我們在深度學習入門過程中經常會用到的基本工具。