













首個人體動捕基模型面世!SMPLer-X:橫掃七大榜單
人體全身姿態與體型估計(EHPS, Expressive Human Pose and Shape estimation)雖然目前已經取得了非常大研究進展,但當下最先進的方法仍然受限于有限的訓練數據集。
最近,來自南洋理工大學S-Lab、商湯科技、上海人工智能實驗室、東京大學和IDEA研究院的研究人員首次提出針對人體全身姿態與體型估計任務的動捕大模型SMPLer-X。該工作使用來自不同數據源的多達450萬個實例對模型進行訓練,在7個關鍵榜單上均刷新了最佳性能。
SMPLer-X除了常見的身體動作捕捉,還能輸出面部和手部動作,甚至對體型做出估計。

論文鏈接:https://arxiv.org/abs/2309.17448
項目主頁:https://caizhongang.github.io/projects/SMPLer-X/
憑借大量數據和大型模型,SMPLer-X在各種測試和榜單中表現出強大的性能,即使在沒有見過的環境中也具有出色的通用性:
1. 在數據擴展方面,研究人員對32個3D人體數據集進行了系統的評估與分析,為模型訓練提供參考;
2. 在模型縮放方面,利用視覺大模型來研究該任務中增大模型參數量帶來的性能提升;
3. 通過微調策略可以將SMPLer-X通用大模型轉變為專用大模型,使其能夠實現進一步的性能提升。

總而言之,SMPLer-X探索了數據縮放與模型縮放(圖1),對32個學術數據集進行排名,并在其450萬個實例上完成了訓練,在7個關鍵榜單(如AGORA、UBody、EgoBody和EHF)上均刷新了最佳性能。
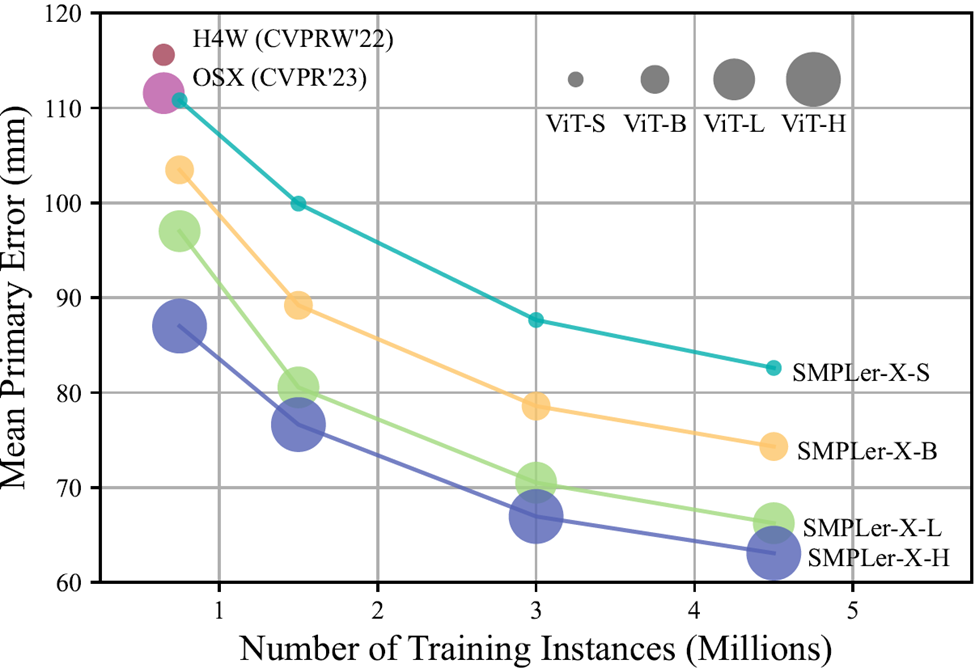
Figure 1 增大數據量和模型參數量在降低關鍵榜單(AGORA、UBody、EgoBody、3DPW 和 EHF)的平均主要誤差(MPE)方面都是有效的
現有3D人體數據集的泛化性研究
研究人員對32個學術數據集進行了排名:為了衡量每個數據集的性能,需要使用該數據集訓練一個模型,并在五個評估數據集上評估模型:AGORA、UBody、EgoBody、3DPW和EHF。
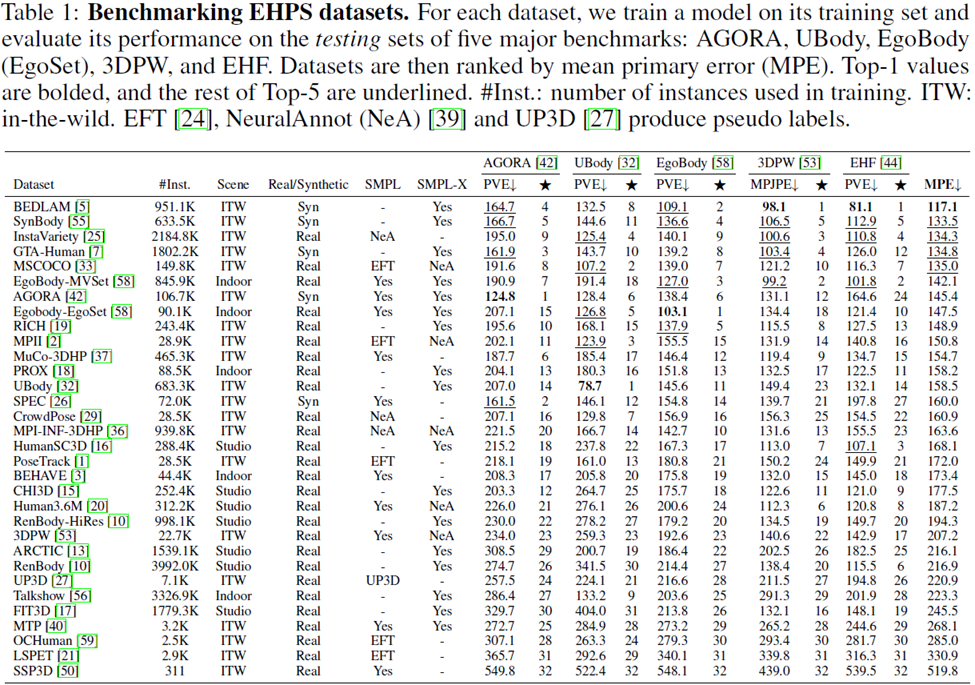
表中還計算了平均主要誤差(Mean Primary Error, MPE),以便于在各個數據集之間進行簡單比較。
從數據集泛化性研究中得到的啟示
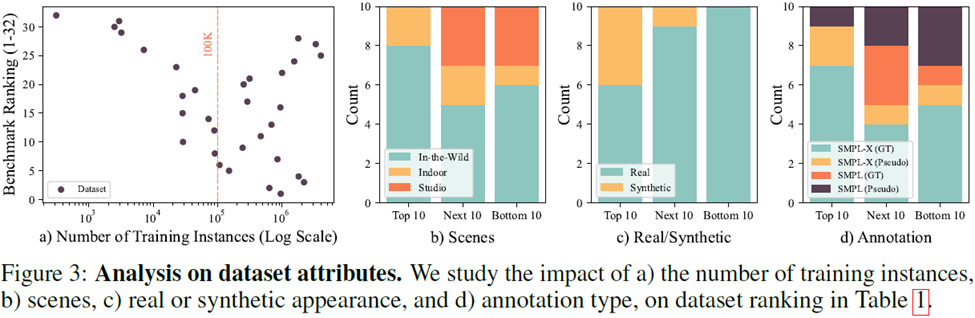
從大量數據集的分析(圖3)中,可以得出以下四點結論:
1. 關于單一數據集的數據量,10萬個實例數量級的數據集用于模型訓練可以得到較高的性價比;
2. 關于數據集的采集場景,In-the-wild數據集效果最好,如果只能室內采集,需要避免單一場景以提升訓練效果;
3. 關于數據集的采集,數據集排名前三中有兩個是生成數據集,生成數據近年來展現出了強大的性能。
4. 關于數據集的標注,偽標簽的數據集在訓練中也發揮了至關重要的作用。
動捕大模型的訓練與微調
當前最先進的方法通常只使用少數幾個數據集(例如,MSCOCO、MPII和Human3.6M)進行訓練,而這篇文章中探討使用了更多數據集。
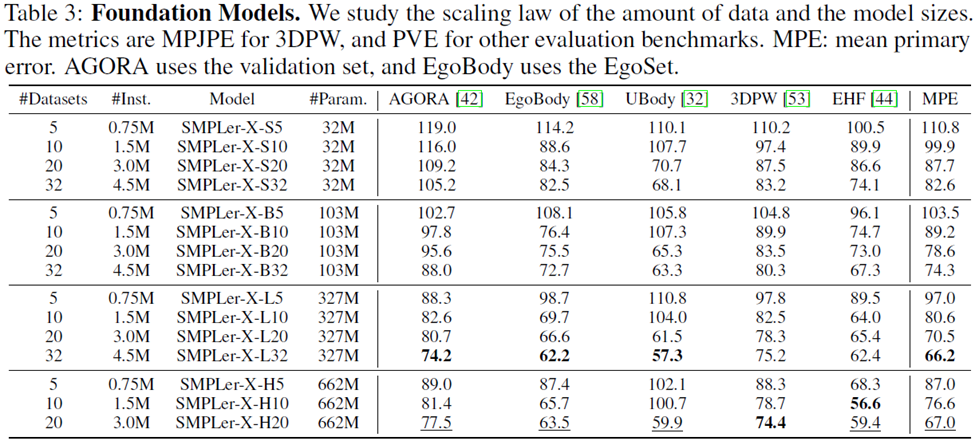
在始終優先考慮排名較高的數據集的前提下使用了四種數據量:作為訓練集的5、10、20和32個數據集,總大小為75萬、150萬、300萬和450萬實例。
除此之外,研究人員也展示了低成本的微調策略來將通用大模型適應到特定場景。
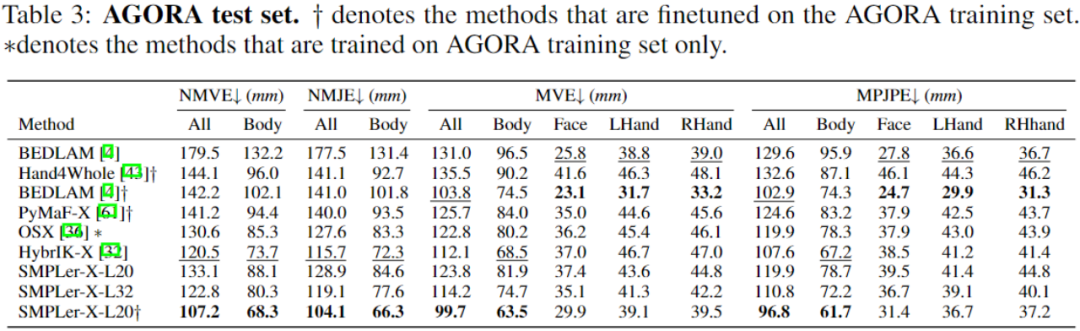
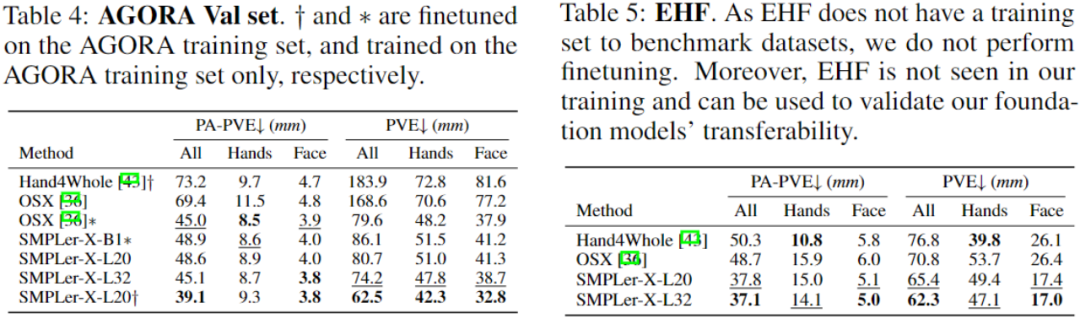
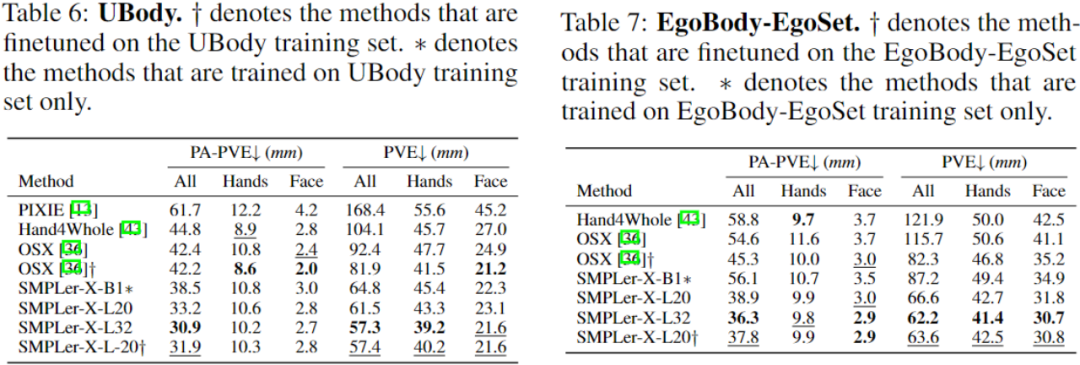
上表中展示了部分主要測試,如AGORA測試集(表3)、AGORA驗證集(表4)、EHF(表5)、UBody(表6)、EgoBody-EgoSet(表7)。
此外,研究人員還在ARCTIC和DNA-Rendering兩個測試集上評估了動捕大模型的泛化性。
研究人員希望SMPLer-X能帶來超出算法設計的啟發,并為學術社區提供強大的全身人體動捕大模型。
代碼和預訓練模型都已開源,更多詳情請訪問項目主頁:https://caizhongang.github.io/projects/SMPLer-X/
結果展示






















