【深度學習】生成對抗網絡(GANs)詳解!
一、概述
生成對抗網絡(Generative Adversarial Networks)是一種無監督深度學習模型,用來通過計算機生成數據,由Ian J. Goodfellow等人于2014年提出。模型通過框架中(至少)兩個模塊:生成模型(Generative Model)和判別模型(Discriminative Model)的互相博弈學習產生相當好的輸出。生成對抗網絡被認為是當前最具前景、最具活躍度的模型之一,目前主要應用于樣本數據生成、圖像生成、圖像修復、圖像轉換、文本生成等方向。
GAN這種全新的技術在生成方向上帶給了人工智能領域全新的突破。在之后的幾年中生GAN成為深度學習領域中的研究熱點,近幾年與GAN有關的論文數量也急速上升,目前數量仍然在持續增加中。
 GAN論文數量增長示意圖
GAN論文數量增長示意圖
2018年,對抗式神經網絡的思想被《麻省理工科技評論》評選為2018年“全球十大突破性技術”(10 Breakthrough Technologies)之一。 Yann LeCun(“深度學習三巨頭”之一,紐約大學教授,前Facebook首席人工智能科學家)稱贊生成對抗網絡是“過去20年中深度學習領域最酷的思想”,而在國內被大家熟知的前百度首席科學家Andrew Ng也把生成對抗網絡看作“深度學習領域中一項非常重大的進步”。
二、GAN基本原理
1. 構成
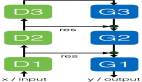
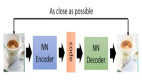
GAN由兩個重要的部分構成:生成器(Generator,簡寫作G)和判別器(Discriminator,簡寫作D)。
生成器:通過機器生成數據,目的是盡可能“騙過”判別器,生成的數據記做G(z);
判別器:判斷數據是真實數據還是「生成器」生成的數據,目的是盡可能找出「生成器」造的“假數據”。它的輸入參數是x,x代表數據,輸出D(x)代表x為真實數據的概率,如果為1,就代表100%是真實的數據,而輸出為0,就代表不可能是真實的數據。
這樣,G和D構成了一個動態對抗(或博弈過程),隨著訓練(對抗)的進行,G生成的數據越來越接近真實數據,D鑒別數據的水平越來越高。在理想的狀態下,G可以生成足以“以假亂真”的數據;而對于D來說,它難以判定生成器生成的數據究竟是不是真實的,因此D(G(z)) = 0.5。訓練完成后,我們得到了一個生成模型G,它可以用來生成以假亂真的數據。
 GAN示意圖
GAN示意圖
2. 訓練過程
第一階段:固定「判別器D」,訓練「生成器G」。使用一個性能不錯的判別器,G不斷生成“假數據”,然后給這個D去判斷。開始時候,G還很弱,所以很容易被判別出來。但隨著訓練不斷進行,G技能不斷提升,最終騙過了D。這個時候,D基本屬于“瞎猜”的狀態,判斷是否為假數據的概率為50%。
第二階段:固定「生成器G」,訓練「判別器D」。當通過了第一階段,繼續訓練G就沒有意義了。這時候我們固定G,然后開始訓練D。通過不斷訓練,D提高了自己的鑒別能力,最終他可以準確判斷出假數據。
重復第一階段、第二階段。通過不斷的循環,「生成器G」和「判別器D」的能力都越來越強。最終我們得到了一個效果非常好的「生成器G」,就可以用它來生成數據。
3. GAN的優缺點
1)優點
能更好建模數據分布(圖像更銳利、清晰);
理論上,GANs 能訓練任何一種生成器網絡。其他的框架需要生成器網絡有一些特定的函數形式,比如輸出層是高斯的;
無需利用馬爾科夫鏈反復采樣,無需在學習過程中進行推斷,沒有復雜的變分下界,避開近似計算棘手的概率的難題。
2)缺點
模型難以收斂,不穩定。生成器和判別器之間需要很好的同步,但是在實際訓練中很容易D收斂,G發散。D/G 的訓練需要精心的設計。
模式缺失(Mode Collapse)問題。GANs的學習過程可能出現模式缺失,生成器開始退化,總是生成同樣的樣本點,無法繼續學習。
4. GAN的應用
1)生成數據集
人工智能的訓練是需要大量的數據集,可以通過GAN自動生成低成本的數據集。
2)人臉生成

3)物品生成

4)圖像轉換
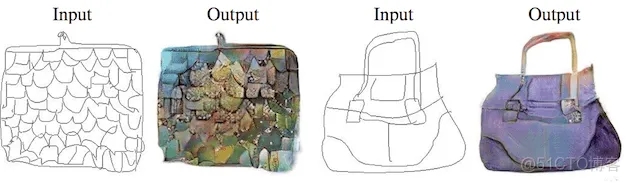
5)圖像修復

三、GAN的數學原理
1.GAN的數學推導
生成模型會從一個輸入空間將數據映射到生成空間(即通過輸入數據,在函數作用下生成輸出數據),寫成公式的形式是x=G(z)。通常,輸入z會滿足一個簡單形式的隨機分布(比如高斯分布或者均勻分布等),為了使得生成的數據分布能夠盡可能地逼近真實數據分布,生成函數G會是一個神經網絡的形式,通過神經網絡可以模擬出各種完全不同的分布類型。
以下是生成對抗網絡中的代價函數,以判別器D為例,代價函數寫作J(D)J^{(D)}J(D),形式如下所示:
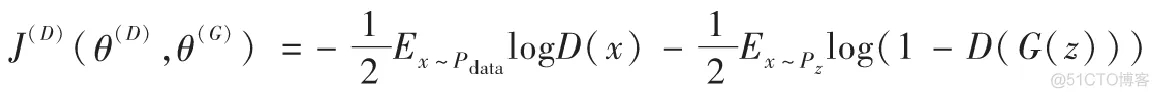
其中,E表示期望概率,x~Pdatax \sim P_{data}x~Pdata表示x滿足PdataP_{data}Pdata分布。
對于生成器來說它與判別器是緊密相關的,我們可以把兩者看作一個零和博弈,它們的代價綜合應該是零,所以生成器的代價函數應滿足如下等式:
J(G)=?J(D)J^{(G)} = -J^{(D)} J(G)=?J(D)
這樣一來,我們可以設置一個價值函數V來表示J(G)J^{(G)}J(G)和J(D)J^{(D)}J(D):
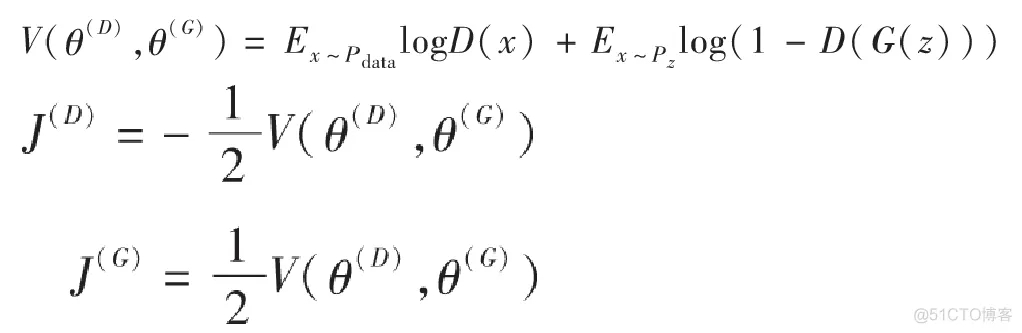
我們現在把問題變成了需要尋找一個合適的V(θ(D),θ(G))V(θ^{(D)},θ^{(G)})V(θ(D),θ(G))使得J(G)J^{(G)}J(G)和J(D)J^{(D)}J(D)都盡可能小,也就是說對于判別器而言越大越V(θ(D),θ(G))V(θ^{(D)},θ^{(G)})V(θ(D),θ(G))好,而對于生成器來說則是越小越好V(θ(D),θ(G))V(θ^{(D)},θ^{(G)})V(θ(D),θ(G)),從而形成了兩者之間的博弈關系。
在博弈論中,博弈雙方的決策組合會形成一個納什平衡點(Nash equilibrium),在這個博弈平衡點下博弈中的任何一方將無法通過自身的行為而增加自己的收益。在生成對抗網絡中,我們要計算的納什平衡點正是要尋找一個生成器G與判別器D使得各自的代價函數最小,從上面的推導中也可以得出我們希望找到一個V(θ(D),θ(G))V(θ^{(D)},θ^{(G)})V(θ(D),θ(G))對于生成器來說最小而對判別器來說最大,我們可以把它定義成一個尋找極大極小值的問題,公式如下所示:
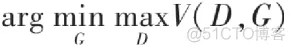
我們可以用圖形化的方法理解一下這個極大極小值的概念,一個很好的例子就是鞍點(saddle point),如下圖所示,即在一個方向是函數的極大值點,而在另一個方向是函數的極小值點。

在上面公式的基礎上,我們可以分別求出理想的判別器D*和生成器G*:
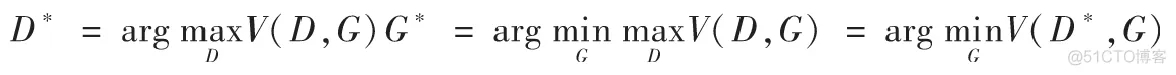
下面我們先來看一下如何求出理想的判別器,對于上述的D*,我們假定生成器G是固定的,令式子中的G(z)=x。推導如下:
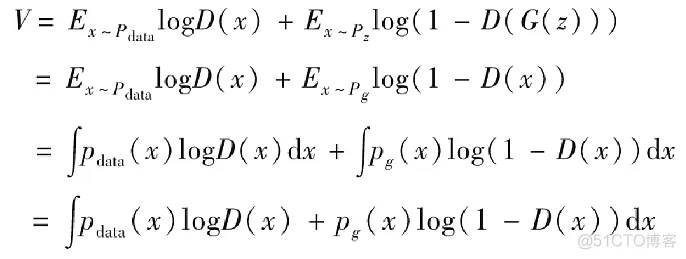
我們現在的目標是希望尋找一個D使得V最大,我們希望對于積分中的項f(x)=pdata(x)logD(x)+pg(x)log(1?D(x))f(x)=p_{data}(x)logD(x)+p_g(x)log(1-D(x))f(x)=pdata(x)logD(x)+pg(x)log(1?D(x)),無論x取何值都能最大。其中,我們已知pdatap_datapdata是固定的,之前我們也假定生成器G固定,所以pgp_gpg也是固定的,所以我們可以很容易地求出D以使得f(x)最大。我們假設x固定,f(x)對D(x)求導等于零,下面是求解D(x)的推導。

可以看出它是一個范圍在0到1的值,這也符合我們判別器的模式,理想的判別器在接收到真實數據時應該判斷為1,而對于生成數據則應該判斷為0,當生成數據分布與真實數據分布非常接近的時候,應該輸出的結果為1/2.
找到了D*之后,我們再來推導一下生成器G*。現在先把D*(x)代入前面的積分式子中重新表示:
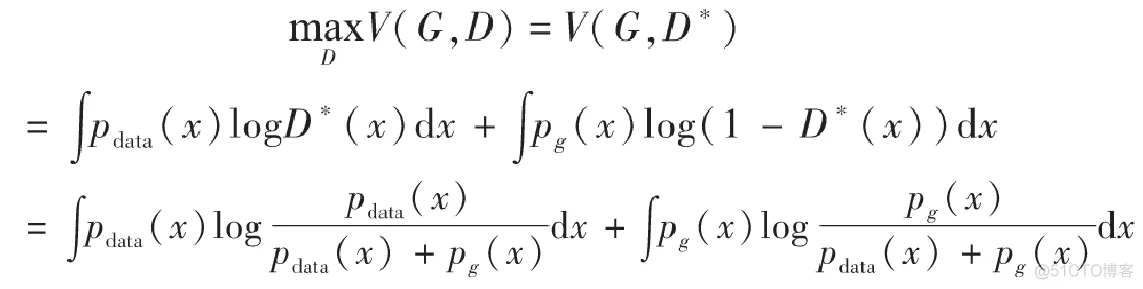
到了這一步,我們需要先介紹一個定義——Jensen–Shannon散度,我們這里簡稱JS散度。在概率統計中,JS散度也與前面提到的KL散度一樣具備了測量兩個概率分布相似程度的能力,它的計算方法基于KL散度,繼承了KL散度的非負性等,但有一點重要的不同,JS散度具備了對稱性。JS散度的公式如下,我們還是以P和Q作為例子,另外我們設定M=12(P+Q)M=\frac{1}{2}(P+Q)M=21(P+Q),KL為KL散度公式。
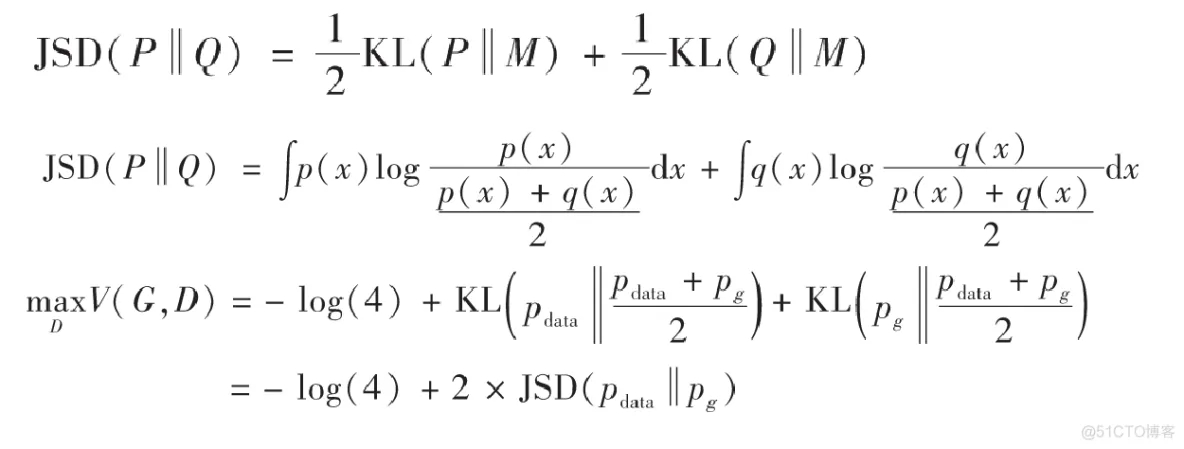
對于上面的MaxV(G,D)MaxV(G,D)MaxV(G,D),由于JS散度是非負的,當且僅當pdata=pgp_{data}=p_gpdata=pg的時候,上式可以取得全局最小值?log(4)-log(4)?log(4)。所以我們要求的最優生成器G*,正是要使得G*的分布pg=pdatap_g=p_{data}pg=pdata.
2. GAN的可視化理解
下面我們用一個可視化概率分布的例子來更深入地認識一下生成對抗網絡。Ian Goodfellow的論中給出了這樣一個GAN的可視化實現的例子:下圖中的點線為真實數據分布,曲線為生成數據樣本,生成對抗網絡在這個例子中的目標在于,讓曲線(也就是生成數據的分布)逐漸逼近點線(代表的真實數據分布)。
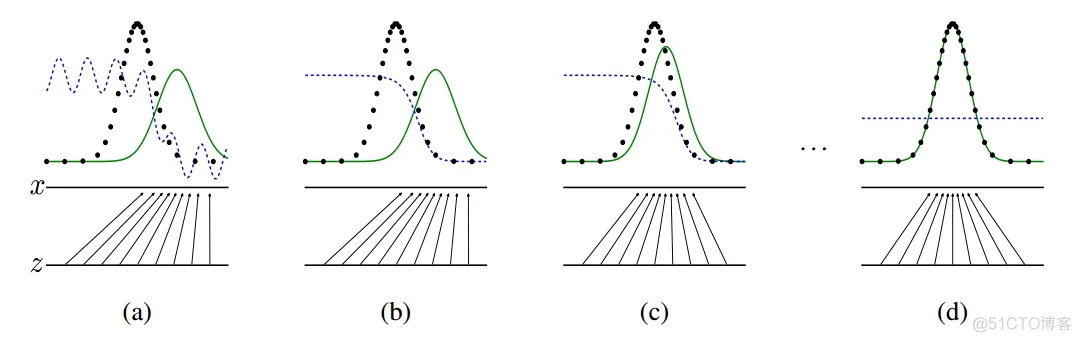
虛線為生成對抗網絡中的判別器,它被賦予了初步區分真實數據與生成數據的能力,并對于它的劃分性能加上一定的白噪聲,使得模擬環境更為真實。輸入域為z(圖中下方的直線)在這個例子里默認為一個均勻分布的數據,生成域為x(圖中上方的直線)為不均勻分布數據,通過生成函數x=G(z)形成一個映射關系,如圖中的那些箭頭所示,將均勻分布的數據映射成非均勻數據。
從a到d的四張圖可以展現整個生成對抗網絡的運作過程。在a圖中,可以說是一種初始的狀態,生成數據與真實數據還有比較大的差距,判別器具備初步劃分是否為真實數據的能力,但是由于存在噪聲,效果仍有缺陷。b圖中,通過使用兩類標簽數據對于判別器的訓練,判別器D開始逐漸向一個比較完善的方向收斂,最終呈現出圖中的結果。當判別器逐漸完美后,我們開始迭代生成器G,如圖c所示。通過判別器D的倒數梯度方向作為指導,我們讓生成數據向真實數據的分布方向移動,讓生成數據更容易被判別器判斷為真實數據。在反復的一系列上述訓練過程后,生成器與判別器會進入圖d的最終狀態,此時pgp_gpg會非常逼近甚至完全等于pdatap_{data}pdata,當達到理想的pg=pdatap_g=p_{data}pg=pdata的時候,D與G都已經無法再更進一步優化了,此時G生成的數據已經達到了我們期望的目的,能夠完全模擬出真實數據的分布,而D在這個狀態下已經無法分辨兩種數據分布(因為它們完全相同),此時D(x)=12D(x)=\frac{1}{2}D(x)=21.
四、DCGAN
1. 概述
DCGAN的創始論文《Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks》(基于深層卷積生成對抗網絡的無監督表示學習)發表于2015年,文章在GAN的基礎之上提出了全新的DCGAN架構,該網絡在訓練過程中狀態穩定,并可以有效實現高質量的圖片生成及相關的生成模型應用。由于其具有非常強的實用性,在它之后的大量GAN模型都是基于DCGAN進行的改良版本。為了使得GAN能夠很好地適應于卷積神經網絡架構,DCGAN提出了四點架構設計規則,分別是:
使用卷積層替代池化層。首先第一點是把傳統卷積網絡中的池化層全部去除,使用卷積層代替。對于判別器,我們使用步長卷積(strided convolution)來代替池化層;對于生成器,我們使用分數步長卷積(fractional-strided convolutions)來代替池化層。
去除全連接層。目前的研究趨勢中我們會發現非常多的研究都在試圖去除全連接層,常規的卷積神經網絡往往會在卷積層后添加全連接層用以輸出最終向量,但我們知道全連接層的缺點在于參數過多,當神經網絡層數深了以后運算速度會變得非常慢,此外全連接層也會使得網絡容易過度擬合。有研究使用了全局平均池化(global average pooling)來替代全連接層,可以使得模型更穩定,但也影響了收斂速度。論文中說的一種折中方案是將生成器的隨機輸入直接與卷積層特征輸入進行連接,同樣地對于判別器的輸出層也是與卷積層的輸出特征連接,具體的操作會在后面的框架結構介紹中說明。
使用批歸一化(batch normalization)。由于深度學習的神經網絡層數很多,每一層都會使得輸出數據的分布發生變化,隨著層數的增加網絡的整體偏差會越來越大。批歸一化的目標則是為了解決這一問題,通過對每一層的輸入進行歸一化處理,能夠有效使得數據服從某個固定的數據分布。
使用恰當的激活函數。在DCGAN網絡框架中,生成器和判別器使用了不同的激活函數來設計。生成器中使用ReLU函數,但對于輸出層使用了Tanh激活函數,因為研究者們在實驗中觀察到使用有邊界的激活函數可以讓模型更快地進行學習,并能快速覆蓋色彩空間。而在判別器中對所有層均使用LeakyReLU,在實際使用中尤其適用于高分辨率的圖像判別模型。這些激活函數的選擇是研究者在多次實驗測試中得出的結論,可以有效使得DCGAN得到最優的結果。
2. 網絡結構
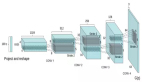
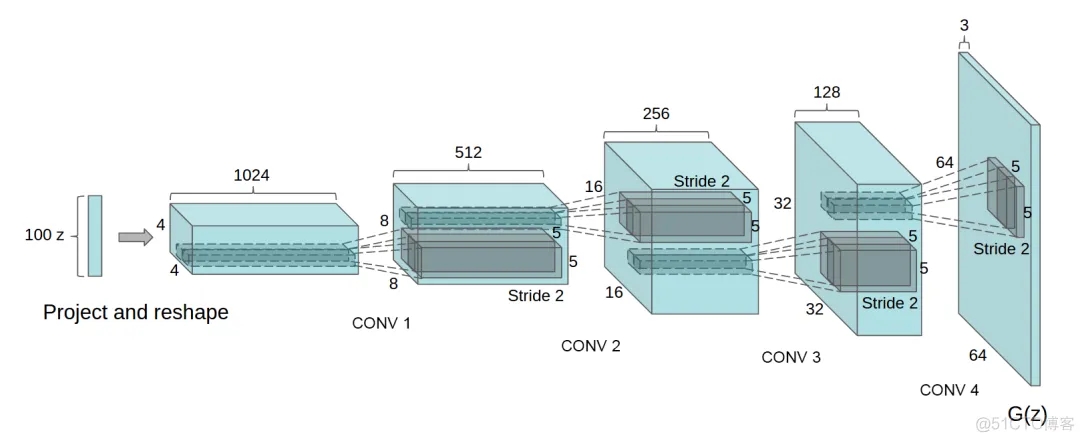
下圖是DCGAN生成器G的架構圖,輸入數據為100維的隨機數據z,服從范圍在[-1,1]的均勻分布,經過一系列分數步長卷積后,最后形成一幅64×64×3的RGB圖片,與訓練圖片大小一致。
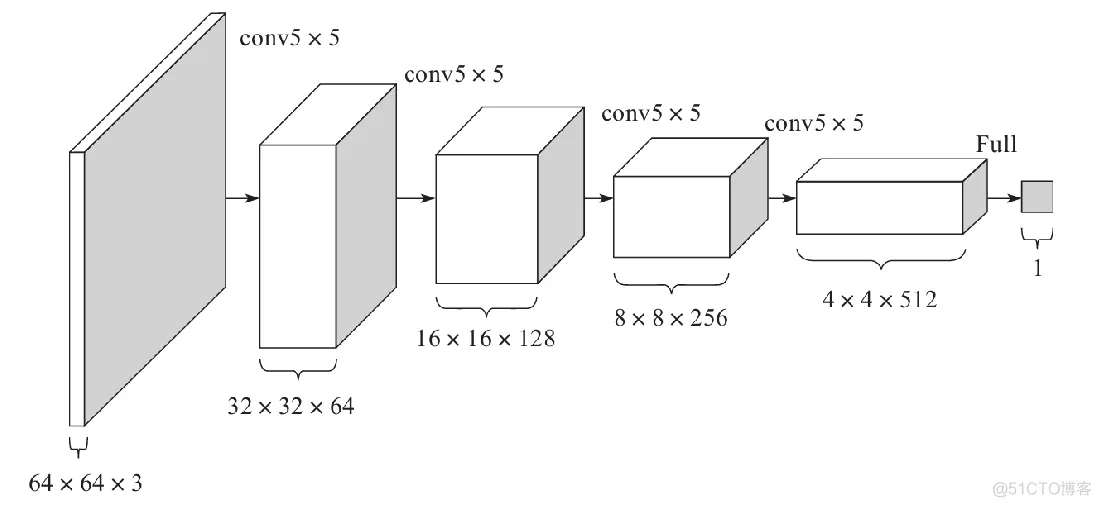
對于判別器D的架構,基本是生成器G的反向操作,如下圖所示。輸入層為64×64×3的圖像數據,經過一系列卷積層降低數據的維度,最終輸出的是一個二分類數據。
3. 訓練細節
1)對于用于訓練的圖像數據樣本,僅將數據縮放到[-1,1]的范圍內,這個也是tanh的取值范圍,并不做任何其他處理。
2)模型均采用Mini-Batch大小為128的批量隨機梯度下降方法進行訓練。權重的初始化使用滿足均值為0、方差為0.02的高斯分布的隨機變量。
3)對于激活函數LeakyReLU,其中Leak的部分設置斜率為0.2。
4)訓練過程中使用Adam優化器進行超參數調優。學習率使用0.0002,動量β1取0.5,使得訓練更加穩定。
五、實現DCGAN
1. 任務目標
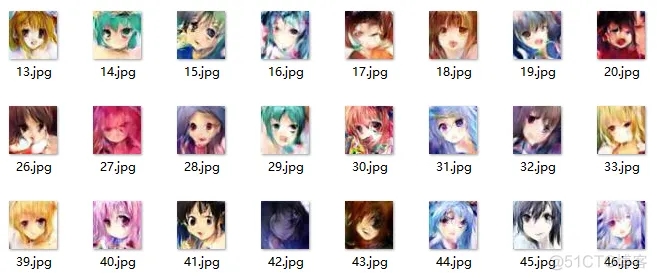
實現DCGAN,并利用其合成卡通人物頭像。
2. 數據集
樣本內容:卡通人物頭像
樣本數量:51223個
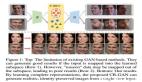
3. 實驗結果
為了加快訓練速度,實際只采用了8903個樣本進行訓練,執行每20輪一次增量訓練。實驗結果如下:
1輪訓練

5輪訓練

10輪訓練
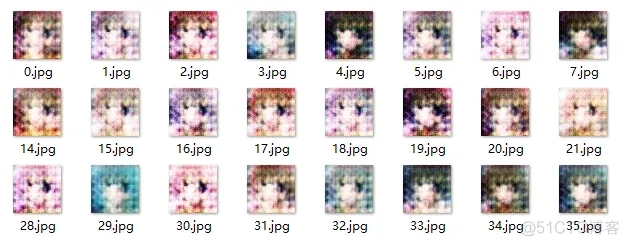
20輪訓練
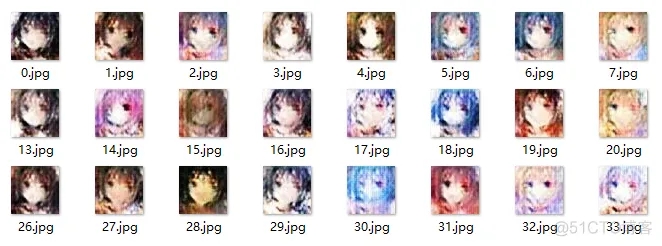
40輪訓練
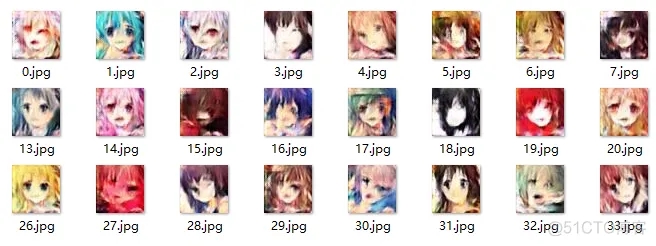
60輪訓練
六、其它GAN模型
1)文本生成圖像:GAWWN
2)匹配數據圖像轉換:Pix2Pix
3)非匹配數據圖像轉換:CycleGAN,用于實現兩個領域圖片互轉
4)多領域圖像轉換:StarGAN
七、參考資源
1. 在線視頻
1)李宏毅GAN教程: https://www.ixigua.com/pseries/6783110584444387843/?logTag=cZwYY0OhI8vRiNppza2UW
2. 書籍
1)《生成對抗網絡入門指南》,史丹青編著,機械工業出版社