譯者 | 陳峻
審校 | 重樓
不知您是否聽說過積分神經網絡(Integral Neural Networks,INN)。作為一種靈活的架構,它經由一次性訓練,無需任何微調,便可被轉換為任意用戶指定的體積。由于聲波(例如:音樂)可以被任何所需的采樣率(也就是我們常說的:音質)進行采樣,因此INN 可以動態地改變各種數據和參數形狀(即:DNN質量)。
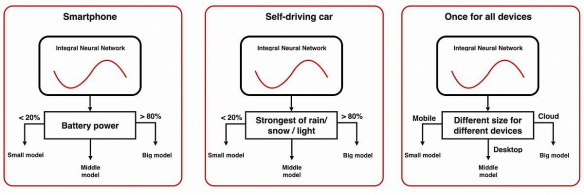
上圖展示了INN的三種應用。在推理過程中,我們可以根據不同的硬件或數據條件,來動態改變網絡的體積。這種體積的減小往往是結構化的,并且能夠自動導致神經網絡的壓縮和加速。
TheStage.ai團隊在今年的IEEE/CVF CVPR會議上展示了他們的論文《積分神經網絡(Integral Neural Networks)》。該論文被認為是此次活動中12 篇僅有的“有望獲獎”的論文之一。作為一類新型的神經網絡,INN將連續參數和積分算子相結合,來表示各個基本層。在推理階段,INN通過連續權重的離散采樣,被轉換為普通的DNN表示。由于此類網絡的參數沿著過濾器和通道維度是連續的,因此這會導致結構化的修剪(pruning),而無需僅通過維度的重新離散化,而進行微調。
在下文中,我們將首先展示如何將4倍圖像的超分辨率EDSR(Enhanced Deep Residual Networks for Single Image Super-Resolution)模型轉換為INN的過程,然后演示如何實現針對模型的結構化修剪。在完成了將INN轉換回離散的DNN后,我們通過將其部署到Nvidia GPU上,以實現高效的推理。總的說來,我們將按照如下順序展開討論:
- 簡介INN
- 概述用于超分辨率任務的EDSR網絡
- 在一行代碼中,通過TorchIntegral框架應用,獲取積分的EDSR
- 通過快速管道,實現無需INN微調的INN結構修剪
- 在Nvidia GPU上部署已修剪的模型

首先,讓我們有一個感性認識。上圖展示的是離散的EDSR特征圖。

而這張是則是INN EDSR的特征圖。很容易看出INN中的通道是被連續組織的。
無需微調的DNN修剪
雖然INN中的各個層面已被積分算子所取代,但是對于積分算子的實際評估,我們需要對輸入的信號進行離散化,以便采用數值積分的方法。同時,INN中的各個層次的設計方式是與離散化后的經典DNN層(如:全連接或卷積)保持一致的。
上圖展示了積分全連接層評估的簡要過程。
4倍圖像的超分辨率EDSR的修剪
在基于擴散模型和Transformer的高端神經網絡等架構中,我們往往需要用到圖像超分辨率任務。它是一項被廣泛使用的計算機視覺任務,往往被用在通過已知或未知的退化算子,來增強圖像。其典型應用場景莫過于使用雙立方下采樣(Bicubic Downsampling),來作為退化算子的經典超分辨率形式。由于EDSR 架構包含了 ResNet(殘差神經網絡,目前被廣泛地用于各類深度學習問題)和最終的4倍上采樣塊,非常適合我們后續的演示,因此我們將重點關注4倍EDSR架構。
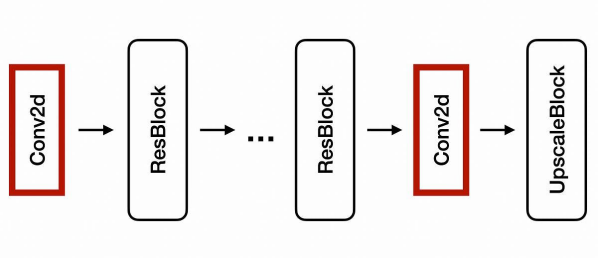
上圖展示了EDSR的邏輯架構。該架構由一系列緊接著上采樣塊的殘差塊(Residual Blocks)所組成。此處的上采樣塊則是由多個卷積和上采樣(Upsample)層組成。
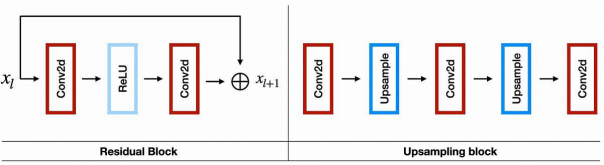
在上圖中,左側是:殘差塊的架構;而右側是:4倍超分辨率的上采樣塊。其中,每個上采樣層都有2倍的規模。
EDSR架構的修剪細節
結構化的修剪往往涉及刪除整個過濾器或通道,進而對作為EDSR中主要構建塊的殘差塊,產生獨特的影響。而在該架構中,由于每個狀態都是通過向輸入添加Conv -> ReLU -> Conv塊來更新的,因此輸入和輸出信號必須具有相同數量的參數。那么通過創建修剪依賴關系圖,我們便可以在TorchIntegral框架中有效地管理這些。下圖展示了每個殘差塊的第二卷積,是如何形成單個組的。
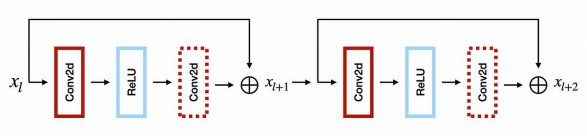
也就是說,為了修剪殘差塊中的第二卷積,我們有必要修剪每個殘差塊中的所有第二卷積。當然,為了更靈活的設置,我們實際上應該在所有殘差塊中,修剪第一卷積的過濾器,從而實現對第二卷積通道的修剪。
將EDSR模型轉換為INN EDSR
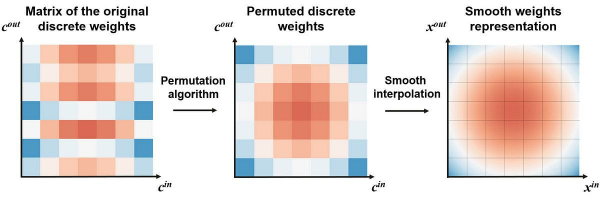
接著,為了實現針對預訓練的DNN轉換,我們需要利用特殊的過濾器通道排列算法,進一步平滑插值(interpolation)。此類排列算法不但能夠保留模型的質量,而且會使得DNN的權重,看起來像是從連續函數中采樣出來的一樣。
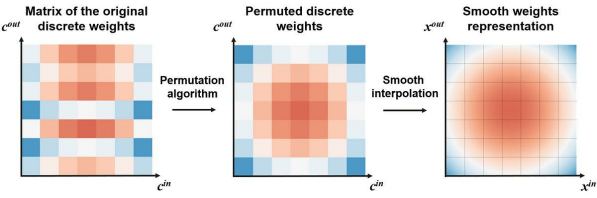
上圖展示了從DNN到INN 的轉換。我們使用著名的“旅行推銷員問題(Travelling Salesman Problem,即:給定一系列城市和每對城市之間的距離,求解訪問每一座城市一次并回到起始城市的最短回路。)”公式,來排列各個離散的權重。在完成排列后,我們將獲得更平滑的權重,同時它也保證了預訓練DNN的質量不會下降。具體請參見如下代碼段:
import torch
import torchintegral as inn
from super_image import EdsrModel
# creating 4x EDSR model
model = EdsrModel.from_pretrained("eugenesiow/edsr", scale=4).cuda()
# Transform model layers to integral.
# continous_dims and discrete dims define which dimensions
# of parameters tensors should be parametrized continuously
# or stay fixed size as in discrete networks.
# In our case we make all filter and channel dimensions
# to be continuous excluding convolutions of the upsample block.
model = inn.IntegralWrapper(init_from_discrete=True)(
model, example_input, continuous_dims, discrete_dims
).cuda()積分網格調整:DNN結構化訓練的后期修剪
所謂積分網格調整(Integration grid tuning),是指在SGD(隨機梯度下降)的優化過程中,平滑地選擇參數張量(parameter tensors)的操作。其過濾器應針對由用戶定義的數字,來進行采樣。與上述過濾器和通道刪除方法不同,由INN生成的過濾器,可以通過插值操作,來組合多個離散過濾器。注意,INN在過濾器和通道維度的參數張量上,引入了軟按索引選擇(soft select-by-index)的操作。具體請參見如下代碼段:
# Set trainable gird for each integral layer
# Each group should have the same grid
# During the sum of continuous signals
# We need to sample it using the same set of points
for group in model.groups:
new_size = 224 if 'operator' in group.operations else 128
group.reset_grid(inn.TrainableGrid1D(new_size))
# Prepare model for tuning of integration grid
model.grid_tuning()
# Start training
train(model, train_data, test_data)由于積分網格調整是一種快速的優化過程,可以在小型校準集上進行,因此其優化結果便是已在結構上壓縮了的DNN。我們在單顆 Nvidia A4000 上的測試表明:對完整的Div2k數據集的積分網格進行調整,通常需要4分鐘。 那么,在四倍A4000上的分布式設置,就能夠幾乎實現4倍的加速,其優化時間將僅為1分鐘。
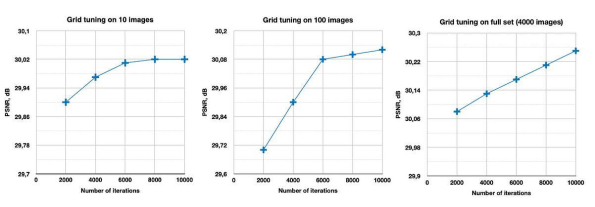
如上圖所示,在實驗中,我們發現:500張圖片與包含4000張圖片的完整訓練集 Div2k,所給出的結果是相同的。
性能
如果我們需要將修剪后的INN模型轉換為離散模型,則可以使用以下代碼行:
model = model.transform_to_discrete()
# then model can be compiled, for instance
# compilation can add an additional 1.4x speedup for inference
model = torch.compile(model, backend='cudagraphs')當輸入的分辨率為64x64時,我們便可以在RTX A4000上提供每秒幀數(FPS)了。可見,上文生成的INN模型可以被輕松轉換為離散模型,并被部署在任何NVIDIA GPU上。至此,已壓縮的模型幾乎實現了2倍的加速度。

如上圖所示,左側是4倍雙立方放大圖像;右側則是使用INN的經50%壓縮的EDSR模型。下表展示了更詳細的對比:
模型 | 體積 FP16 | FPS RTX A4000 | PSNR(峰值信噪比) |
EDSRorig. | 75MB | 170 | 30.65 |
INN EDSR 30% | 52MB | 230 | 30.43 |
INN EDSR 40% | 45MB | 270 | 30.34 |
INN EDSR 50% | 37MB | 320 | 30.25 |
小結
在上文中,我們簡述了《積分神經網絡》一文的基本成果:憑借著4倍EDSR模型的訓練后修建,我們僅通過單行代碼和1分鐘的積分網格微調,便實現了近2倍的加速度。針對上述話題,您可以通過查看如下資源,以獲取更多有關高效模型部署的信息與更新。
- INN項目站點--https://inn.thestage.ai/?ref=hackernoon.com
- INN 項目的Github資源--https://github.com/TheStageAI/TorchIntegral?ref=hackernoon.com
- 與本文相關的支持代碼--https://github.com/TheStageAI/TechBlog/tree/main/inn_edsr_grid_tuning_medium?ref=hackernoon.com
譯者介紹
陳峻(Julian Chen),51CTO社區編輯,具有十多年的IT項目實施經驗,善于對內外部資源與風險實施管控,專注傳播網絡與信息安全知識與經驗。
原文標題:Unleashing 2x Acceleration for DNNs: Transforming Models with Integral Neural Networks in Just 1 Min,作者:thestage