













LLM幻覺問題全梳理!哈工大團隊50頁綜述重磅發布
幻覺,老朋友了。
自打LLM進入我們的視野,幻覺問題就一直是一道坎,困擾著無數開發人員。
當然,有關大語言模型幻覺的問題已經有了無數研究。
最近,來自哈工大和華為的團隊發表了一篇50頁的大綜述,對有關LLM幻覺問題的最新進展來了一個全面而深入的概述。
這篇綜述從LLM幻覺的創新分類方法出發,深入探究了可能導致幻覺的因素,并對檢測幻覺的方法和基準進行了概述。
這其中肯定也少不了業內比較有代表性的減輕幻覺的方法。

論文地址:https://arxiv.org/abs/2311.05232
下面,我們就來看一看本篇綜述中主要講了些什么內容。
想深入學習的朋友,可以移步文章底部的參考鏈接,閱讀論文原文。
幻覺大分類
首先,先來看看有哪些種類的幻覺。
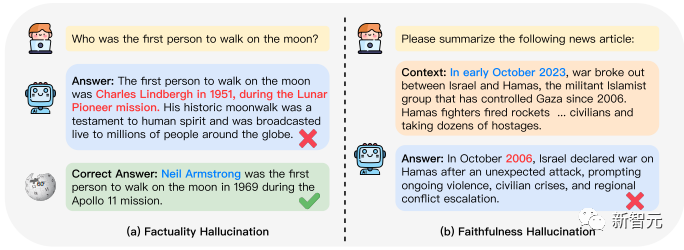
上圖中,左邊是事實性的幻覺。當LLM被問到誰是第一個在月球上漫步的人時,LLM編了個人物出來,甚至還說得有模有樣。
右邊則是文本摘要模型中的忠實度問題,可以看到LLM在看到這段新聞后,直接把年份概括錯了。
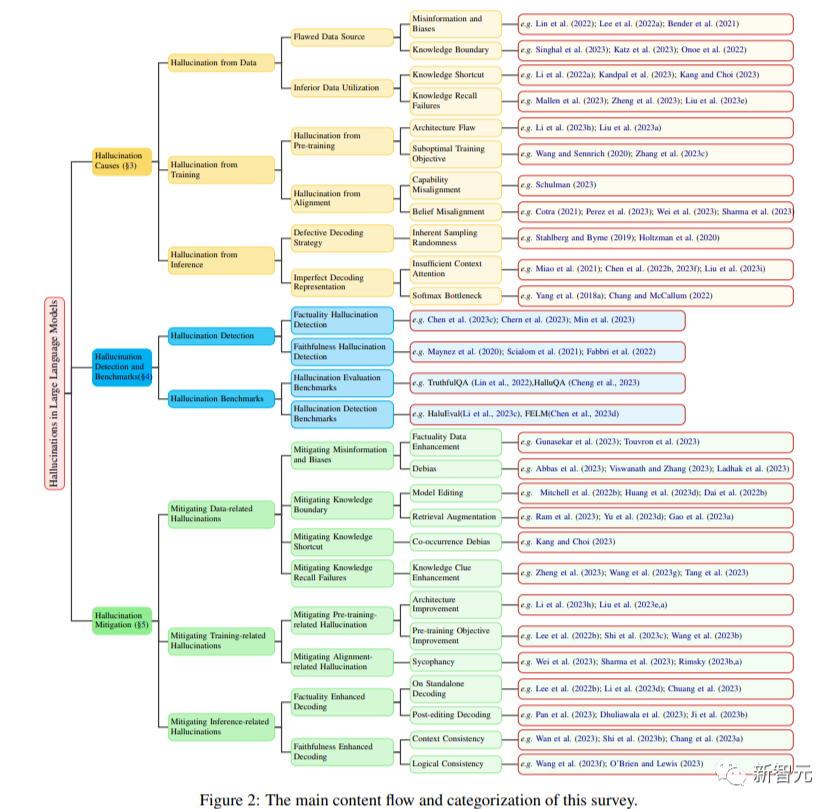
在本篇綜述中,研究人員深入分析了LLM中幻覺的起源,涵蓋了從數據、訓練到推理階段的一系列促成因素。
在這一框架內,研究人員指出了與數據相關的潛在原因。例如,有缺陷的數據源和未優化的數據利用,或是在預訓練和對齊過程中可能會誘發幻覺的訓練策略,以及源于解碼策略的隨機性和推理過程中不完善的表征等等。
此外,研究人員還全面概述了專為檢測LLM中的幻覺而設計的各種有效方法,以及與LLM幻覺相關的基準的詳盡概述,和作為評估LLM產生幻覺的程度和檢測方法有效性的試驗平臺。
下圖即為本篇綜述所涉及到的內容、前人研究,以及論文。
下圖是一張更為詳細的LLM幻覺種類圖。
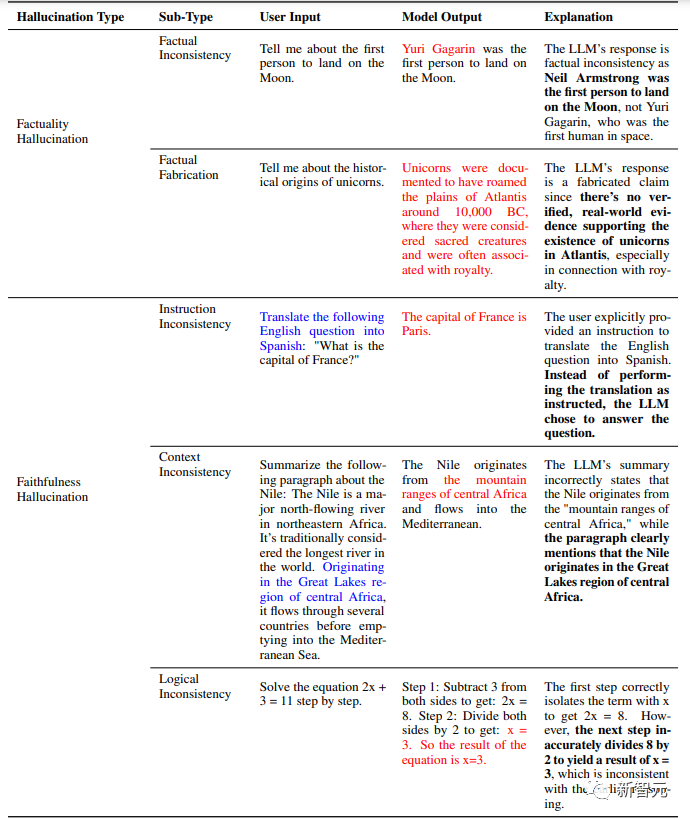
在事實型幻覺和忠實度幻覺下,還包括更為細致的分類。
事實型幻覺:
a)事實不一致
當問LLM,誰是第一位登月的人時,LLM回答說是加加林,而非阿姆斯特朗。這種屬于答案與事實不一致,因為確有加加林其人,所以不屬于捏造。
b)事實捏造
當讓LLM介紹一下獨角獸的起源時,LLM并沒有指出世界上沒有獨角獸這種生物,反倒是編了一大段。這種現實世界中沒有的,稱之為捏造。
忠實度幻覺又包括:指令-答案的不一致、文本不一致,以及邏輯不一致。
a)指令-答案不一致
當LLM被要求翻譯一個問句時,LLM輸出的答案實際上回答了問題,沒有進行翻譯。因此是一種指令和答案的不一致。
b)文本不一致
這類不一致更多出現在概括類任務中。LLM可能會罔顧給出的文本,總結一個錯的出來。
c)邏輯不一致
在被要求給出2x+3=11的方程解法時,第一步LLM指出,兩邊同時減去3,得到2x=8.接下來在兩邊除以2的操作中,LLM輸出的答案是3.
8除以2怎么會等于3呢?
幻覺產生原理
數據
接下來,綜述開始梳理有關幻覺產生原理的內容。
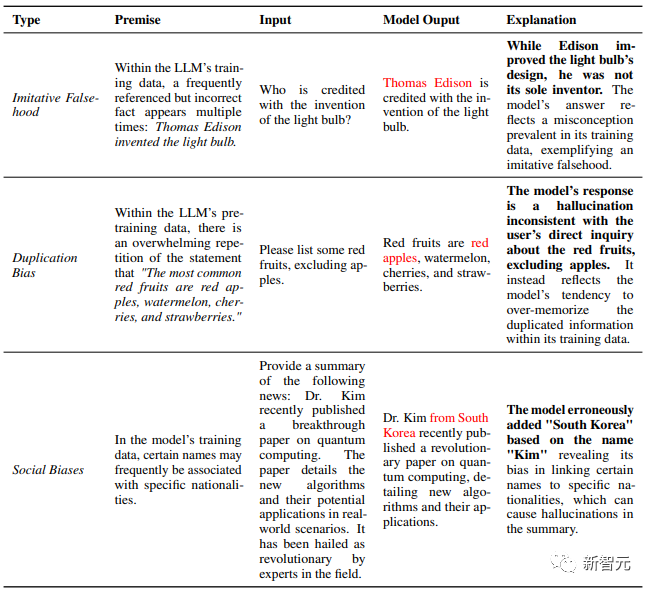
第一類,數據問題。
·錯誤信息和偏見。鑒于對大規模語料庫的需求日益增長,啟發式數據收集方法被用來有效收集大量數據。
這種方法在提供大量數據的同時,可能會無意中引入錯誤信息,增加出現模仿性錯誤的風險。此外,社會偏見也會在無意中被引入LLMs的學習過程。
這些偏差主要包括重復偏差和各種社會偏差(Social Biases)。
要知道,LLM預訓練的主要目的是模仿訓練分布。所以當LLM在事實不正確的數據上接受訓練時,它們可能會無意中放大這些不準確的數據,從而可能導致事實不正確的幻覺。
神經網絡,尤其是大型語言模型,具有記憶訓練數據的內在傾向。研究表明,這種記憶趨勢會隨著模型規模的擴大而增強。
然而,在預訓練數據中存在重復信息的情況下,固有的記憶能力就會出現問題。這種重復會使 LLM 從泛化轉向記憶,最終產生重復偏差,即LLM會過度優先回憶重復的數據,導致幻覺,最終偏離所需的內容。
除了這些偏見,數據分布的差異也是產生幻覺的潛在原因。
下一種情況是,LLM通常會存在知識邊界。
雖然大量的預培訓語料庫為法律碩士提供了廣泛的事實知識,但它們本身也有局限性。這種局限性主要體現在兩個方面:缺乏最新的事實知識和專業領域知識。
雖說LLM在通用領域的各種下游任務中表現出了卓越的性能,但由于這些通用型LLMs主要是在廣泛的公開數據集上進行訓練,它們在專業領域的專業知識受到缺乏相關訓練數據的內在限制。
因此,當遇到需要特定領域知識的問題時,如醫學和法律問題,這些模型可能會表現出明顯的幻覺,通常表現為捏造事實。
此外,還有過時的事實知識。除了特定領域知識的不足,LLMs知識邊界的另一個內在限制是其獲取最新知識的能力有限。
蘊含在LLM中的事實知識具有明確的時間界限,隨著時間的推移可能會過時。
這些模型一旦經過訓練,其內部知識就永遠不會更新。
而鑒于我們這個世界的動態性和不斷變化的本質,這就構成了一個挑戰。當面對超越其時間范圍的領域知識時,LLMs往往會采用捏造事實或提供過去可能正確,但現在已經過時的答案的方法來試圖「蒙混過關」。
下圖中,上半部分即為LLM缺失特定領域內的專業知識——phenylketonuria(苯丙酮尿)。
下半部分即為最簡單的一個知識過時的案例。2018年韓國平昌舉辦冬奧會,2022年北京舉辦冬奧會。LLM并沒有有關后者的知識儲備。
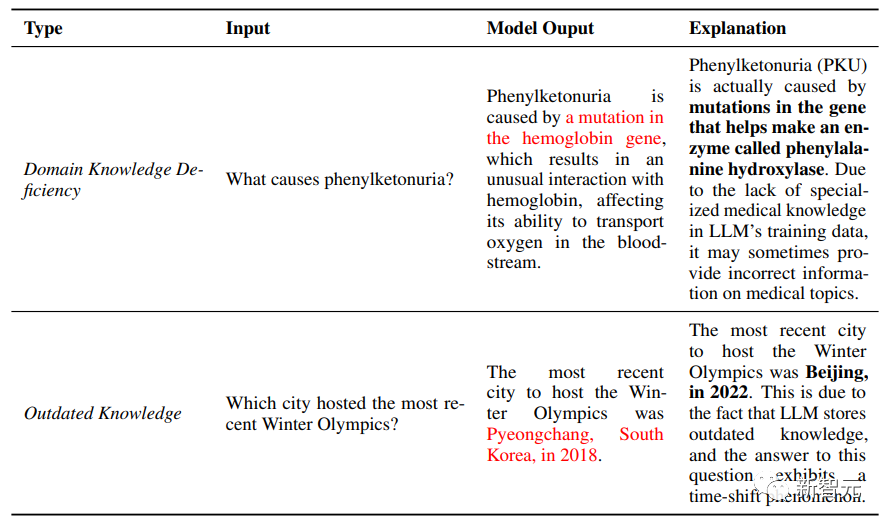
由此可見,LLM中與數據有關的幻覺主要源于錯誤的數據源和不佳的數據利用情況。數據源中的錯誤信息和固有偏差不僅會傳播模仿性虛假信息,還會引入有偏差的輸出,從而導致各種形式的幻覺。
在處理特定領域的知識或遇到快速更新的事實知識時,LLM所擁有知識的局限性就會變得很明顯。
在數據利用方面,LLMs 往往會捕捉到虛假的相關性,在回憶知識(尤其是長尾信息)和復雜推理場景中表現出困難,從而進一步加劇幻覺。
這些挑戰突出表明,亟需提高數據質量,增強模型更有效地學習和回憶事實知識的能力。
訓練
現在,綜述把目光轉向LLM的訓練階段。
LLM的訓練過程主要包括兩個主要階段:
預訓練階段,LLMs在這一階段學習通用表征并捕捉廣泛的知識。
對齊階段,LLMs在這一階段進行調整,以更好地使用戶指令和人類的基本價值觀保持一致。雖然這一過程使LLM 具備了還算不錯的性能,但這些階段中的任何不足都可能無意中導致幻覺的發生。
預訓練是LLM的基礎階段,通常采用基于transformer的架構,在龐大的語料庫中進行因果語言建模。
然而,固有的架構設計和研究人員所采用的特定訓練策略,可能會產生與幻覺相關的問題。如上所說,LLM通常采用基于transformer的架構,遵循GPT建立的范式,它們通過因果語言建模目標獲取表征,OPT和Llama-2等模型都是這一框架的典范。
除了結構缺陷,訓練策略也起著至關重要的作用。值得注意的是,自回歸生成模型的訓練和推理之間的差異導致了暴露偏差(Exposure Bias)現象。
而在對齊階段,一般涉及兩個主要過程,即監督微調和從人類反饋中強化學習(RLHF),是釋放LLM能力并使其符合人類偏好的關鍵一步。
雖然對齊能顯著提高 LLM 響應的質量,但也會帶來產生幻覺的風險。
主要分為兩方面:能力不對齊和信念不對齊(Capability Misalignment、Belief Misalignment)。
如何檢測幻覺?
檢測LLM中的幻覺對于確保生成內容的可靠性和可信度來說至關重要。
傳統的衡量標準主要依賴于詞語重疊,無法區分可信內容和幻覺內容之間的細微差別。
這一挑戰凸顯了針對LLM幻覺采用更先進的檢測方法的必要性。研究人員指出,鑒于這些幻覺的多樣性,檢測方法也相應地有所不同。
這里僅詳細介紹一例——
·檢索外部事實
如下圖所示,為了有效地指出LLM輸出中不準確的事實,一種比較直觀的策略是,直接將模型生成的內容與可靠的知識來源進行比較。
這種方法與事實檢查任務的工作流程非常吻合。然而,傳統的事實核查方法往往出于實用性考慮而采用了簡化假設,導致在應用于復雜的現實世界場景時有可能會出現偏差。
在認識到這些限制因素以后,一些研究者提出,要更加重視真實世界的場景,即從時間受限、未經整理的網絡資源中獲取證據。
他們首創了一種全自動的工作流,集成多個組成部分,包括原始文檔檢索、細粒度檢索、真實性分類等等。
當然,還有不少其他研究者提出了另外一些辦法,比如FACTSCORE,專門用于長文本生成的細粒度事實度量。

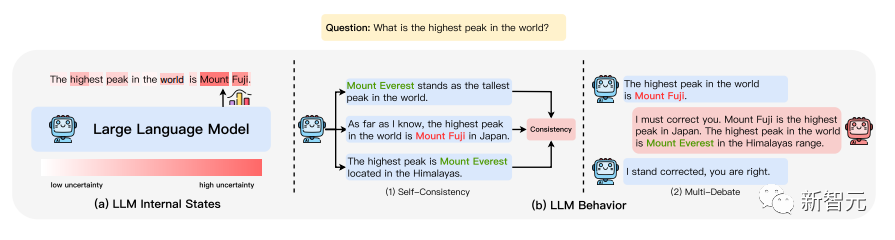
其它方法還包括不確定性估計,如下圖所示。
有關忠實度幻覺的檢測,也有不少相關研究,如下圖所示。
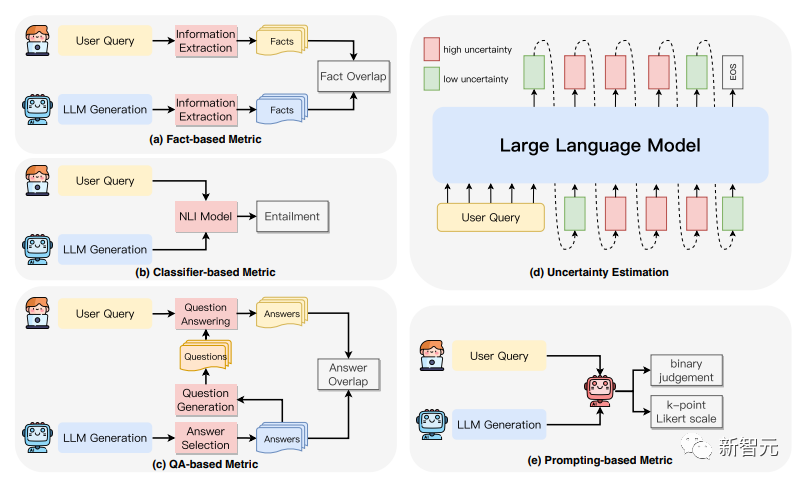
其中包括基于事實度量:通過檢測生成內容與源內容之間的事實重疊度來評估忠實度。
基于分類器的度量:利用經過訓練的分類器來區分生成內容與源內容之間的關聯程度。
基于QA的度量方法:利用問題解答系統來驗證源內容與生成內容之間的信息一致性。
不確定性估計:通過測量模型對其生成輸出的置信度來評估忠實度。
基于prompt的度量方法:讓LLM充當評估者,通過特定的prompt策略來評估生成內容的忠實度。
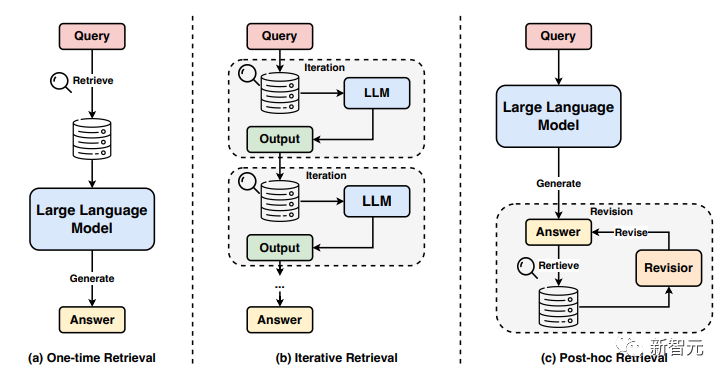
之后,哈工大團隊還將較為前沿的減輕幻覺的方法進行了整理,針對上述提到的各類問題,分別提供可行的解決辦法。
總結
總而言之,在論文的最后,哈工大的研究人員表示,在這份全面的綜述中,他們對大型語言模型中的幻覺現象進行了深入研究,深入探討了其潛在原因的復雜性、開創性的檢測方法和相關基準,以及有效的緩解策略。
雖然開發者們在這個問題上已經有了不少進步,但大型語言模型中的幻覺問題仍然是一個令人關注的持續性問題,需要繼續研究。
此外,本篇論文還可以作為推進安全可信的AI的指路明燈。
哈工大團隊表示,希望通過對幻覺這一復雜問題的探索,為這些有志之士提供寶貴的見解,推動AI技術向更可靠、更安全的方向發展。
























