引領人機交互革命?微軟研究團隊發布80頁的大模型GUI智能體綜述
本論文的主要作者 Chaoyun Zhang、Shilin He、Liqun Li,Si Qin 等均來自 Data, Knowledge, and Intelligence (DKI) 團隊,為微軟 Windows GUI Agent UFO 的核心開發團隊的成員。
圖形用戶界面(Graphical User Interface, GUI)作為數字時代最具代表性的創新之一,大幅簡化了人機交互的復雜度。從簡單的圖標、按鈕、窗口到復雜的多應用工作流程,GUI 為用戶提供了直觀、友好的操作體驗。然而,在自動化和智能化升級的過程中,傳統的 GUI 操控方式始終面臨諸多技術挑戰。以往的腳本化或規則驅動方法在特定場景下確實有所幫助,但隨著現代應用環境的日益復雜和動態化,它們的局限性愈發凸顯。
近年,人工智能與大語言模型(Large Language Models, LLMs)的快速發展為此領域帶來了變革性機遇。
近日,微軟研究團隊發布了一篇長達 80 頁、逾 3 萬字的綜述論文《Large Language Model-Brained GUI Agents: A Survey》。這份綜述系統梳理了大模型驅動的 GUI 智能體在現狀、技術框架、挑戰與應用等方面的研究進展。論文指出,通過將大語言模型(LLMs)與多模態模型(Visual Language Models, VLMs)相結合,GUI 智能體可以根據自然語言指令自動操作圖形界面,并完成復雜的多步驟任務。這一突破不僅超越了傳統 GUI 自動化的固有瓶頸,更推動了人機交互方式從「點擊 + 輸入」向「自然語言 + 智能操作」的躍遷。

鏈接:https://arxiv.org/abs/2411.18279
傳統 GUI 自動化的局限與新挑戰
過去數十年中,GUI 自動化技術主要依靠兩大途徑:
- 腳本化方法:如 Selenium、AutoIt 等工具依賴預先編寫的固定腳本,以模擬點擊、輸入等操作。這類方法適用于相對穩定的界面和流程,但當界面頻繁更新或布局動態變化時,腳本易失效且維護成本高。
- 規則驅動方法:根據預設規則識別 GUI 組件(如按鈕、輸入框)并執行相應操作。這類方法缺乏靈活性,難以應對復雜或非標準化的工作流程。
這些傳統方法在面對高度動態、跨應用的復雜任務時顯得力不從心。例如:
- 如何讓自動化系統理解網頁內容并從中提取用戶所需的關鍵信息?
- 如何適應不同設備、操作系統上的多樣化 GUI 界面?
- 如何在多步驟任務中保持上下文的連貫與一致性?
大模型:智能化 GUI 交互的引擎

圖 1:GUI 智能體的概念展示。
微軟的綜述指出,大語言模型(LLM)在解決上述問題中發揮著關鍵作用,其優勢主要體現在以下三個方面:
1.自然語言理解與任務規劃
以 GPT 系列為代表的大模型擁有出色的自然語言理解與生成能力。它們能夠將用戶簡單直觀的指令(如「打開文件,提取關鍵信息,然后發送給同事」)自動解析為一系列可執行的操作步驟。通過多步推理(Chain-of-Thought)和任務分解,智能體可逐步完成極為復雜的流程。
2.視覺理解與環境感知
引入多模態技術后,視覺語言模型(VLM)可處理文本與視覺信息。通過分析 GUI 截圖或 UI 結構樹,智能體可以理解界面元素(按鈕、菜單、文本框)的布局和含義。這為智能體提供了類似人類的視覺理解能力,使其能夠在動態界面中執行精準操作。如自動在網頁中定位搜索欄并輸入關鍵詞,或在桌面應用中找到特定按鈕進行復制、粘貼操作。
3.動態執行與自適應能力
相較傳統腳本方法,使用大模型的 GUI 智能體能對實時反饋做出響應,并動態調整策略。當界面狀態變化或出現錯誤提示時,智能體可以嘗試新的路徑與方案,而不再依賴固定的腳本流程。

圖 2:GUI 智能體的發展和主要工作。
在大模型的加持下,GUI 智能體為人機交互帶來了質變的提升。用戶僅需自然語言指令,智能體即可完成原本需要繁瑣點擊和復雜操作才能達成的目標。這不僅降低了用戶的操作和學習成本,也減少了對特定軟件 API 的依賴,提升了系統通用性。如圖 2 所示,自 2023 年以來,以大模型驅動的 GUI 智能體為主題的研究層出不窮,逐漸成為前沿熱點。
GUI 智能體的核心架構
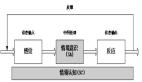
微軟的綜述指出,一個大模型驅動的 GUI 智能體通常包括以下關鍵組件,如圖 3 所示:

圖 3:GUI 智能體基本架構。
1.操作環境感知
輸入數據包括 GUI 截圖、UI 結構樹、元素屬性(類型、標簽、位置)以及窗口層級信息。通過 Windows UI Automation、Android Accessibility API 等工具,智能體可有效捕獲界面信息。
2.提示工程(Prompt Engineering)
智能體將用戶指令與當前 GUI 狀態相結合,構建輸入提示(Prompt),并利用大語言模型生成下一步操作計劃。例如:「用戶指令 + 界面截圖 + UI 元素屬性」 經過 LLM 處理后,智能體將輸出明確的操作步驟(點擊、輸入、拖拽等)。
3.模型推理
將構建好的 Prompt 輸入 LLM 后,模型會預測后續的執行動作和計劃步驟。
4.操作執行
智能體根據 LLM 輸出的高層指令進行實際操作,如鼠標點擊、鍵盤輸入或觸摸操作,從而在網頁、移動應用或桌面系統中完成任務。
5.記憶機制
為應對多步驟復雜任務,GUI 智能體設計了短期記憶(STM)與長期記憶(LTM)機制,用于跟蹤任務進度和歷史操作,確保上下文的一致性與連貫性。
此外,更高階的技術(如基于計算機視覺的 GUI 解析、多智能體協同、自我反思與進化、強化學習等)也在不斷探索中。這些技術將使 GUI 智能體日益強大和完善。微軟的綜述已對這些前沿方向進行了詳細論述。
GUI 智能體框架、數據、模型與測評:全面梳理與實踐指南
微軟的綜述對該領域的發展路徑進行了系統性總結,涵蓋框架設計、數據采集、模型優化和性能測評,為研究者與開發者提供了完整的指導框架。
1.框架設計:多平臺適配與跨領域擴展
當下 GUI 智能體的框架設計根據應用場景和平臺特性,可分為:
- Web 平臺智能體:如 WebAgent 與 SeeAct 基于 HTML DOM 或可視化特征,執行網頁導航、數據抓取、表單填寫等多步驟操作。
- 移動平臺智能體:通過 iOS 和 Android 的 Accessibility API 獲取 UI 層級結構,如 AppAgent、AutoDroid 可應對移動端復雜 UI 布局與多種手勢操作。
- 桌面平臺智能體:如微軟的 UFO 智能體,通過分析 Windows、macOS 的 GUI 層級樹和 API 調用來模擬鍵鼠操作,完成跨軟件的任務執行。
- 跨平臺智能體:如 AGUVI,通用框架可適應多種設備與系統,為跨平臺自動化奠定基礎。這類智能體具備更強的泛化能力,可自由遷移于不同平臺之間。
這些框架的提出與驗證,為 GUI 智能體在各類應用場景中落地提供了可能性,并為跨平臺自動化打造了堅實基礎。
2.數據采集:高質量訓練數據的構建
高效精準的 GUI 操作離不開豐富、真實的數據支撐,包括:
- GUI 環境數據:截圖、UI 元素屬性(類型、標簽、位置)、窗口層級信息等,為智能體提供視覺與結構化信息基礎。
- 操作數據:用戶真實交互記錄,如點擊、輸入、手勢等,為模型學習人類操作規律提供樣本。

圖 4:GUI 智能體數據采集流程。
這些數據為訓練與測試提供了基礎,也為領域標準化評估奠定了堅實的根基。圖 4 展示了訓練 GUI agent 的數據采集流程。
3.大行動模型(LAM):任務執行的核心優化
綜述提出了「大行動模型」(Large Action Model, LAM)的概念,在 LLM 的基礎上進行微調,以解決 GUI 智能體任務執行中的核心難題:
- 高效推理:在海量操作數據上進行微調后,LAM 可快速生成精準的操作指令,降低推理延遲。
- 精確執行:擁有高度泛化能力,可適應不同平臺的 GUI 環境。
- 多步驟任務規劃:支持復雜任務拆解與動態執行,連續完成多項操作,無需預定義腳本流程。

圖 5:為 GUI 智能體微調「大行動模型」。
如圖 5 所示,通過在真實環境中微調 LAM,智能體在執行效率與適應性上顯著提升。
4.測評方法與基準:評估 GUI 智能體的性能

圖 6:GUI 智能體的測評流程。
測評是衡量智能體能力的重要手段。如圖 6 所示,通過觀察智能體執行任務的軌跡和日志記錄,可以測評智能體各方面的能力。主要測評指標主要包括:
- 任務完成率:是否準確執行用戶指令并完成特定任務。
- 執行效率:考察完成任務所需時間與步驟,尤其在資源受限硬件上的表現。
- 在特定規則下完成率:測試智能體在遵循用戶提供的特定規則和策略下完成任務的能力。
- 風險比例:測試智能體識別和解決執行風險的能力。
領域內已出現一系列標準化 Benchmark,為 GUI 智能體的性能評價與對比提供了客觀依據和平臺。
GUI 智能體的實際應用:從高效測試到智能助理
1.軟件測試:從繁瑣腳本到自然語言驅動的智能探索
傳統的軟件 GUI 測試常依賴冗長的腳本編寫與重復的人工驗證,既費時又容易遺漏關鍵場景。如今,借助大型語言模型(LLM)賦能的 GUI 智能體,我們迎來了一場測試領域的革新。這些智能體不再只是簡單地重復固定腳本,而是能通過自然語言描述直接生成測試用例,對界面元素進行「自主探索」,并動態應對各種變化的用戶界面。研究顯示(如 GPTDroid、VisionDroid 和 AUITestAgent 等工具所展現的),智能體可在不需專業軟件工程師深度介入的情況下,高效地捕捉潛在缺陷、追蹤復雜交互路徑,實現從輸入生成、bug 重現到功能驗證的全面自動化測試流程。
以字體大小調試為例,只需一句「請測試系統設置中更改字體大小的流程」,GUI 智能體便可自主導航界面、模擬用戶點擊、滑動選項,并在結果界面中精準確認字體調整是否生效。這樣的自然語言驅動測試不但有效提高測試覆蓋率與效率,即使非技術人員也能輕松參與質量保障過程。這意味著軟件產品迭代速度的加快,以及開發與質量保證團隊從重復勞動中解放,從而更專注于創新與優化。
2.智能助手:從被動響應到多平臺、多步驟的全能執行官
虛擬助手不再局限于簡單的鬧鐘設定或天氣查詢。當 LLM 賦能的 GUI 智能體成為虛擬助手的「大腦」時,我們得到的是一位真正的「多面手」—— 可跨越桌面、手機、Web 瀏覽器和企業應用,以自然語言命令為指引,自動完成從文檔編輯、數據表格分析,到復雜手機操作流程的各種任務。
這些智能體不僅能響應指令,還能根據上下文理解用戶需求,并靈活適配不同界面元素。例如,它們可在移動端應用中自主查找隱藏的功能入口,為新用戶演示如何截圖;或在辦公環境下,將一組跨平臺數據整理后自動生成報告。在這類應用中,用戶不必再為記憶繁瑣的操作步驟煩惱,也不必面對復雜的流程而左右為難,只需以自然語言描述目標,智能體便能迅速解析上下文、定位界面組件并完成指令。通過持續學習與優化,這些智能助手還能越來越「懂你」,有效提升你的生產力與體驗滿意度。
綜上,GUI 智能體在現實應用中已不僅僅是 “工具”,而更像一位全天候的 “數字助理” 和 “質量專家”。在測試領域,它們為軟件品質保駕護航,大幅降低人力和時間成本;在日常與商務操作中,它們成為跨平臺的多功能幫手,讓用戶能以更直觀、更人性化的方式,與數字世界輕松互動。未來,隨著技術的不斷迭代升級,這些智能體將持續拓展應用邊界,并為各行各業的數字化轉型注入新的活力。
技術挑戰與未來展望
盡管 GUI 智能體前景廣闊,但微軟的綜述也明確指出目前的挑戰所在:
- 隱私與安全:智能體需要訪問用戶界面內容,數據安全與隱私保護亟待完善。
- 推理延遲與硬件受限:大模型推理開銷較大,需在性能與實時性間取得平衡。
- 安全與可信:確保智能體可靠執行任務,避免誤操作與安全風險。
- 人機協同與交互策略:在復雜任務中平衡用戶與智能體的決策與執行關系。
- 個性化與定制化:智能體如何學習用戶偏好和習慣,從而更精確地滿足用戶需求。
- 道德與規范:保證智能體的決策透明、公平并負責任。
- 通用泛化性:面對不同設備、操作系統與復雜非標準界面元素的適配仍是難題。
展望未來,隨著大語言模型與多模態技術的持續進化,GUI 智能體將在更多領域落地,為生產力與工作流程帶來深刻變革。
結語:走向智能化交互新時代
大模型的興起為 GUI 自動化打開了全新空間。當 GUI 智能體不再僅依賴固化的腳本與規則,而是借由自然語言與視覺理解來決策和執行操作時,人機交互方式發生了質的轉變。這不僅簡化了用戶操作,更為智能助手、自動化測試等應用場景提供了強大支持。
隨著技術的不斷迭代與生態的日趨成熟,GUI 智能體有望成為日常工作與生活中的關鍵工具,讓復雜的操作愈加智能、高效,并最終引領人機交互走向全新的智能化時代。