ChatGPT代碼生成飆升10%!北大華人一作:細化prompt,大幅改進大模型代碼能力
在大模型時代,高質量的代碼生成已經強大到,讓人驚嘆。
從通過HumEval中67%測試的GPT-4,到近來各種開源大模型,比如CodeLlama,有望成為碼農編碼利器。
然而,現實中,程序員們不會精煉表達需求,因此誤導、限制了LLM生成優秀代碼的能力。
說白了,大模型代碼能力行不行,取決于你的提示妙不妙。
對此,來自北大實驗室的研究團隊提出了,通過與LLM聊天來細化需求的方法——ChatCoder。

論文地址:https://arxiv.org/pdf/2311.00272.pdf
具體來說,他們設計了一種聊天方案,大模型引導用戶細化需求表達,進而比以前更精確、更完整,同時提高了大模型的性能。
大模型是「碼農」,你就是「產品經理」
這里先舉個例子,如下圖,用戶提出了需求:
數據集#MBPP/443,要求ChatGPT編寫一個python函數從給定的列表中找到「最大的負數」。
基于原始需求,ChatGPT生成一個程序,該程序可以正確提取實際值最大的負數。
然而,sanitized-MBPP的作者認為「最大負數」應該是指「絕對值最大的數」。
因此由于「最大」這個表達不明確,導致LLM生成了錯誤的代碼。
而這里,可以通過需求細化(requirements refinement)來解決這個問題。
需求細化就是揭示需求中的隱含依賴和隱藏結構的過程。通過提供更多細節,在需求細化的過程中可以補充不完整的信息,消除模糊不清的地方。
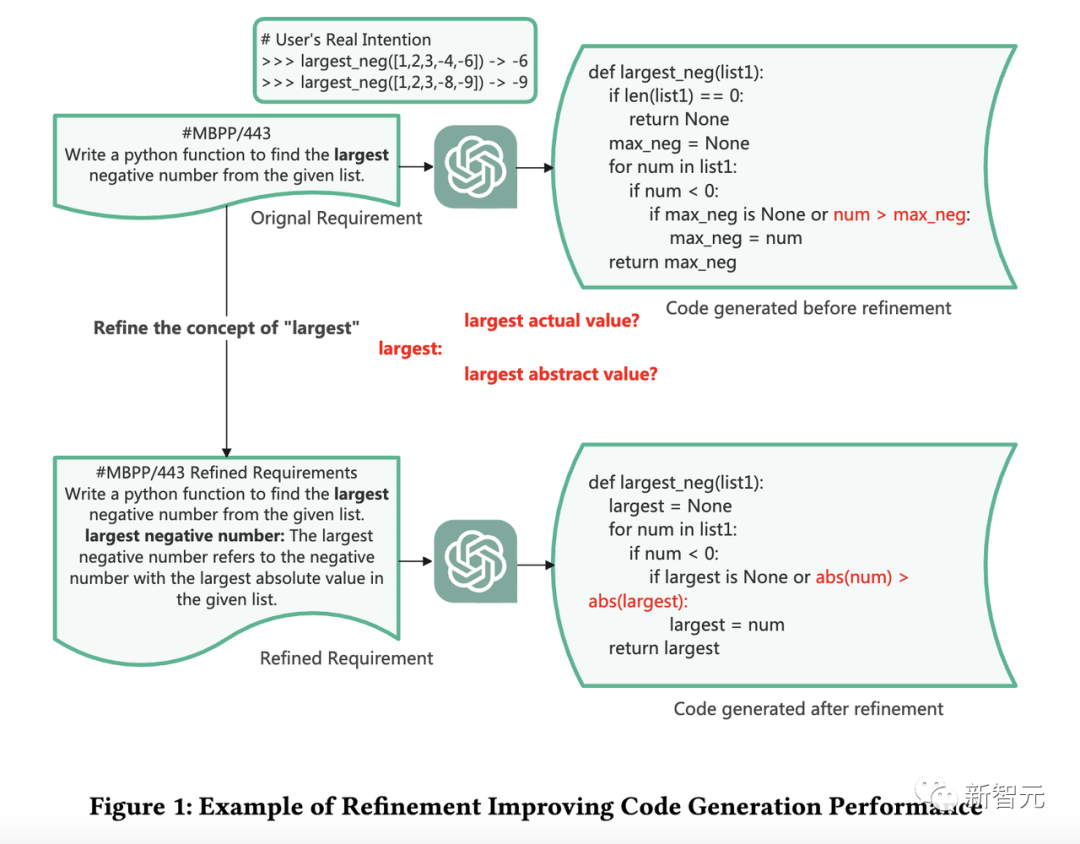
在前面舉的例子中,我們可以簡單地向大語言模型說明「最大的」在這里特指「絕對值最大的」,揭示了「最大」這個詞的隱藏結構。
有了這一改進后的需求,大模型就可以生成符合MBPP作者期望的代碼。
不得不提的是,需求細化,需要人類用戶和大模型的協作。
一般來說,在需求工程的背景下,需求細化是通過軟件供應商(編碼人員)和軟件客戶(用戶)之間的一系列交互來執行的。
軟件供應商分析客戶需求的初始表達,并提出細化點。軟件客戶則需要根據這些點來作出響應,供應商才能完成一輪需求細化。
無論是軟件客戶還是軟件供應商,任何一方都不具備單獨進行需求細化的資格。
這樣的劣勢在于,客戶通常不夠了解軟件設計和開發過程,無法撰寫可用的需求說明;而供應商通常也不夠了解客戶的問題和業務領域,無法為滿意的系統制定需求。

而現在,在大模型時代,人類用戶是客戶,LLM是「供應商」。
為了通過需求細化讓大模型生成更好地滿足用戶需求的代碼,就需要研發人類和LLM協作的方法。
ChatCoder:聊天細化,生成代碼
北大提出了ChatCoder,這是通過聊天進行需求細化的大模型代碼生成的新方法。
整體框架如下圖,非常簡潔,通過聊天來輔助LLM和人類在需求細化方面的協作。
關鍵是,如何與大型語言模型聊天。
ChatCoder便提供了一個全新的聊天模式,其設計靈感來自IEEE SRS。
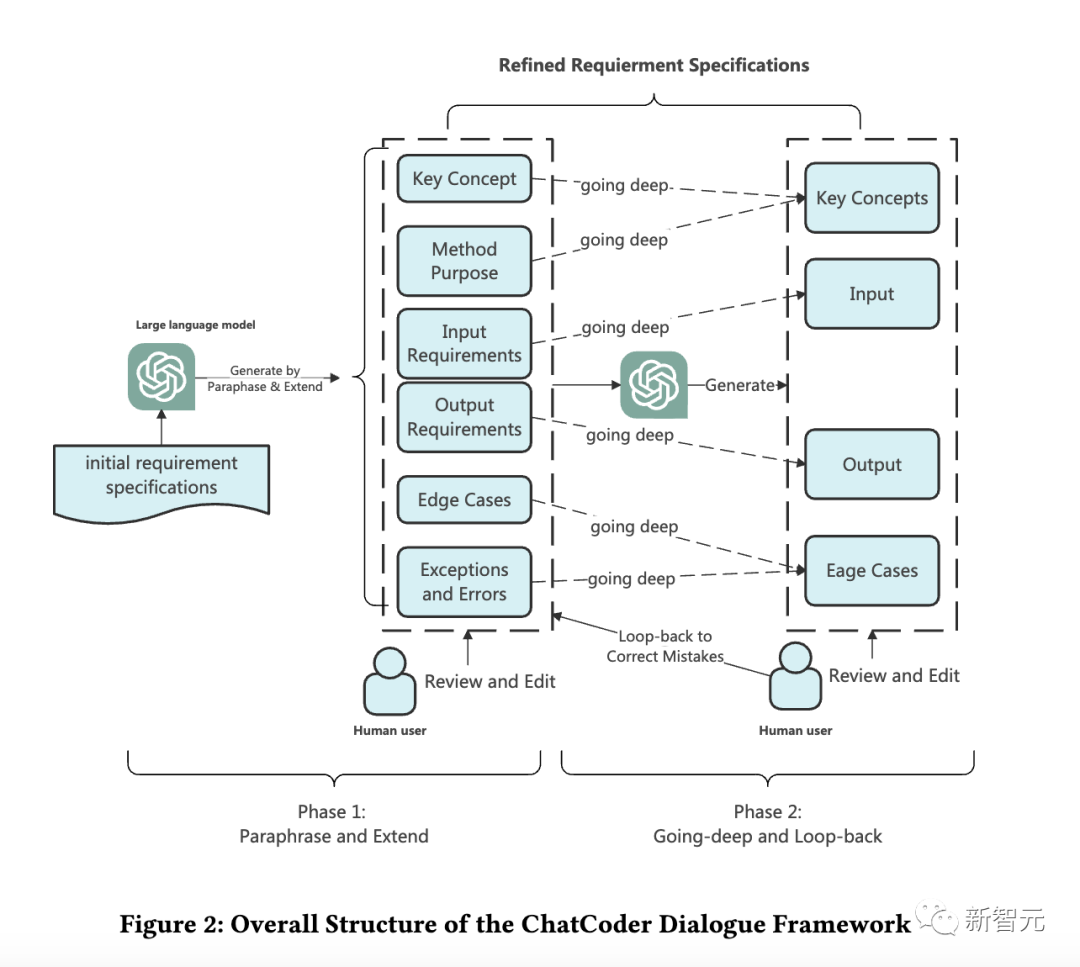
接下來,我們具體看下ChatCoder這個框架。
其整體結構是一個兩輪的對話。
第一階段:Paraphrase和Exend
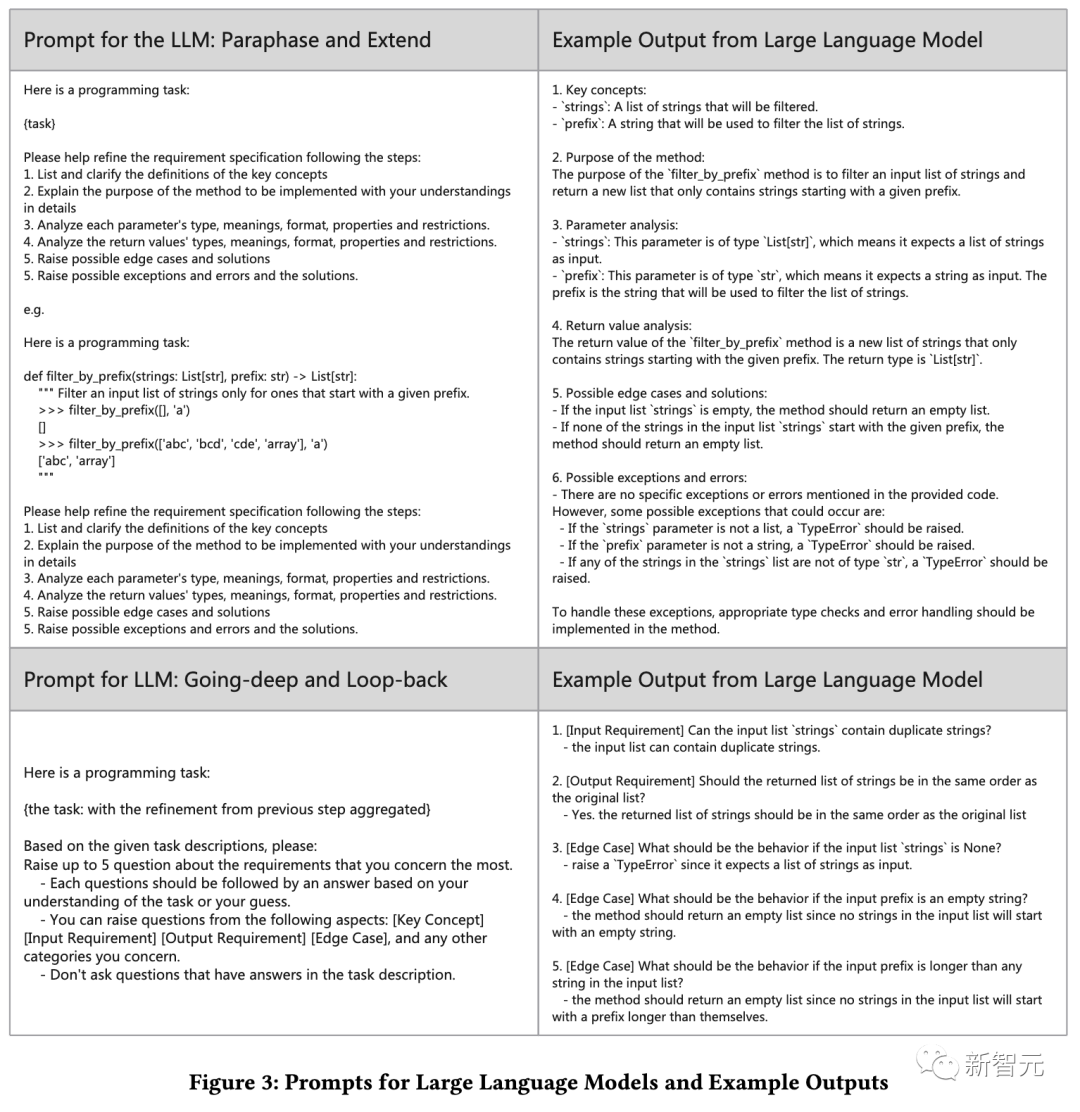
由于人類用戶表達需求可能語意模糊、不完整,ChatCoder使用提示要求LLM從幾個角度解釋用戶的原始需求,即完整的需求規范必須清晰。
對于需要改進的遺漏或有野心的論點,ChatCoder讓大語言模型基于它從訓練數據中獲得的假設來擴展它們。
人類用戶需要查看細化的規范并糾正其中的錯誤。
第二階段:Going-deep和Loop-back
在這一輪中,ChatCoder要求LLM詢問人類用戶,關于第一輪Paraphrase和Exend中信息損失,以及需要進一步改進的規范方面的困惑。
人類用戶需要回答這些問題,并回環糾正細化后的規范。
經過兩輪細化后,得到細化后的需求,然后發送給大型語言模型,得到用戶想要的程序。
ChatGPT代碼能力10%
實驗設置
數據集:Sanitized-MBPP、HumanEval。
基準:gpt-3.5-turbo、gpt-4。
研究問題
為了評估ChatCoder,研究人員提出并測試了以下研究問題:
1)與現有代碼生成模型相比,ChatCoder的表現如何?
2)ChatCoder是LLM和人類用戶交流以進行需求細化的有效方法嗎?
3)人類參與ChatCoder帶來了多少改進?
ChatCoder性能表現
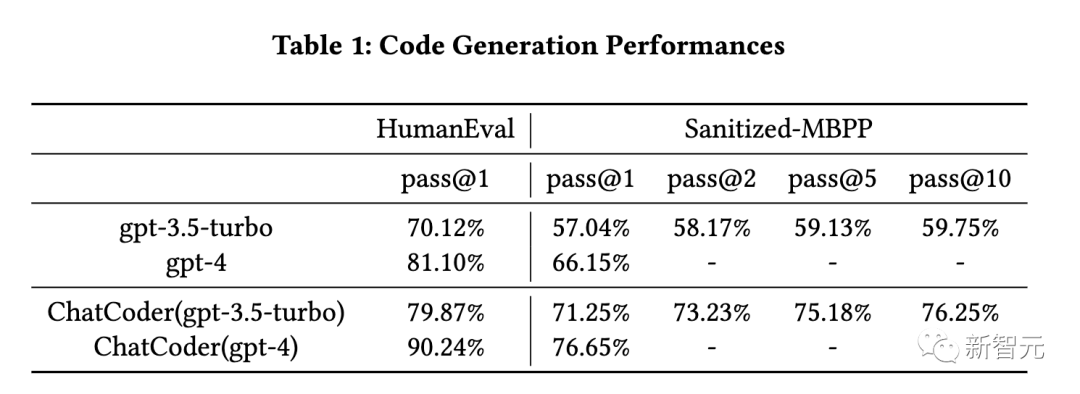
首先我們來看第一個問題,主要是為了評估ChatCoder與基線相比的整體代碼生成性能。
如表1所示,ChatCoder通過大幅細化的需求,成功幫助LLM提高了其生成程序的執行精度。
例如,對于gpt-3.5-turbo,其在Saniticed-MBPP上的pass@1從57.04%提高到71.25%,提升了14%。
橫向比較,對于gpt-3.5-turbo和gpt-4,Saniticed-MBPP上的性能改進比HumEval上的更突出。
溝通效率的表現
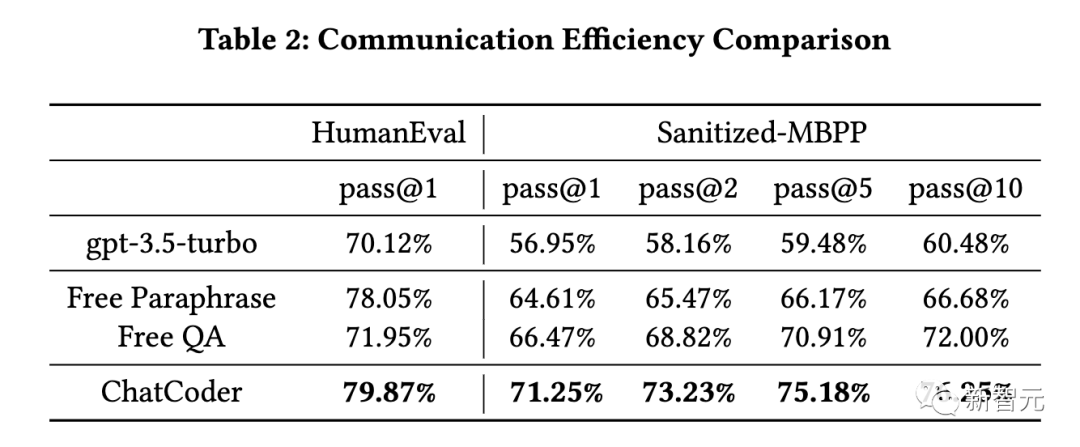
第二個問題是,評估ChatCoder是否是大模型和人類進行需求細化交流的有效方式。
根據表2,所有3種與LLM進行需求細化的通信方法都有助于LLM改進其代碼生成結果。
這一發現指出,任何形式的需求細化在應用LLM生成代碼時都是有用和重要的。
與ChatCoder相比,Free Paraphrase和Free QA不會指示LLM執行某些類型的細化,從而導致較低的改進。
人工干預評估
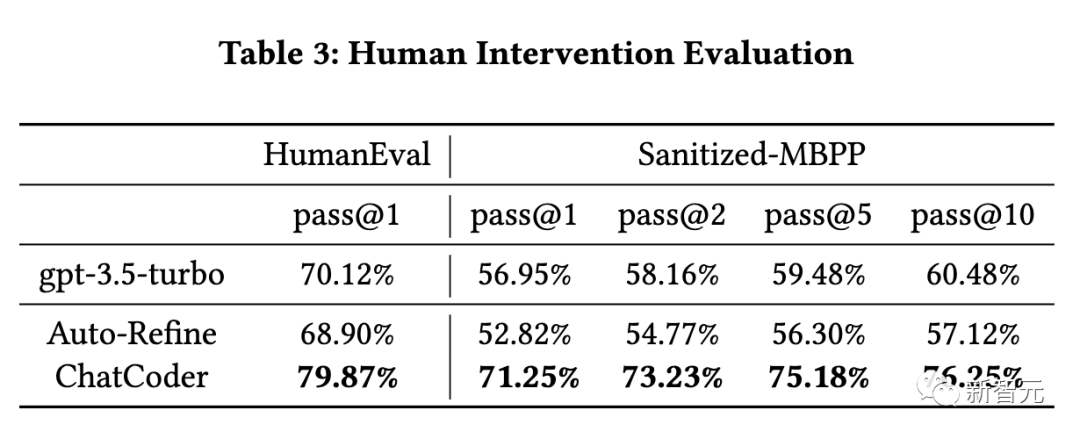
如下評估了人工干預對ChatCoder的重要性,結果見表3。
由于ChatCoder利用需求細化來提高大語言模型的代碼生成性能,因此人工干預是必要的,也是不可忽視的。
ChatCoder的過程是從給定的角度揭示需求的內部結構,這些角度沒有明確表達,即使有歧義。解決歧義的答案只有人類用戶知道。
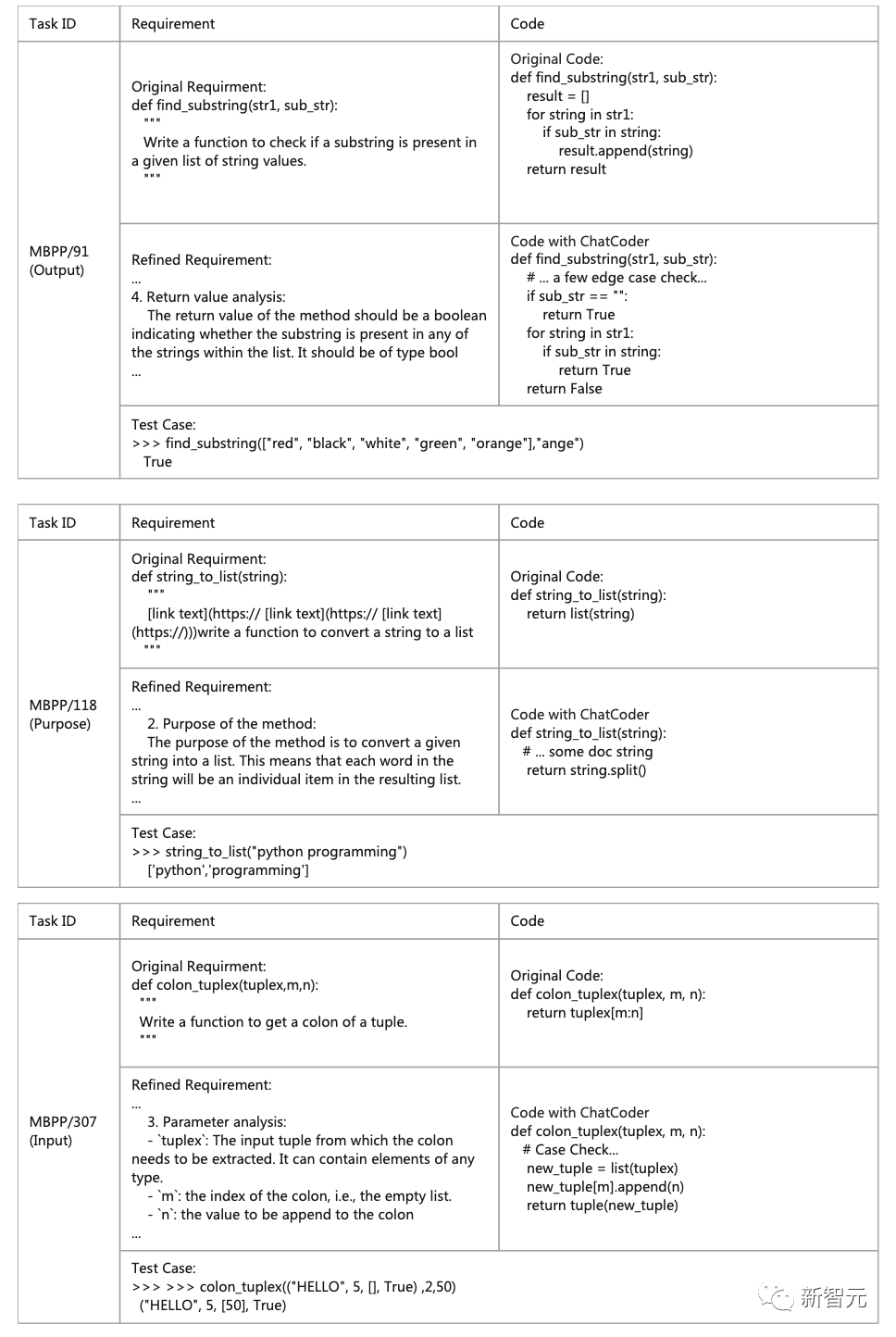
案例研究
如下,作者提出了幾個真實的測試用例,說明ChatCoder如何幫助LLM生成具有細化需求的代碼。
由于頁面限制,研究人員從MBPP中選擇了3個案例,涵蓋了關于輸入、輸出和目的的細化,因為它們直接影響功能需求。