大視頻模型是世界模型?DeepMind/UC伯克利華人一作:預測下一幀就能改變世界
沒人懷疑,OpenAI開年推出的史詩巨作Sora,將改變視頻相關領域的內容生態。
但Google DeepMind、UC伯克利和MIT的研究人員更進一步,在他們眼里,「大視頻模型」也許能夠像世界模型一樣,真正的做到理解我們身處的這個世界。

論文地址:https://arxiv.org/abs/2402.17139
在作者看來,視頻生成將徹底改變物理世界的決策,就像語言模型如何改變數字世界一樣。

研究人員認為,與文本類似,視頻可以作為一個統一的接口,吸收互聯網知識并表征不同的任務。

例如,經典的計算機視覺任務可以被視為下一代幀生成任務(next-frame generation task)。
模型可以通過生成操作視頻(例如「如何制作壽司」)來回答人們的問題,這可能比文本響應更直觀。

視覺和算法推理也可以作為下一幀/視頻生成任務。


視頻也可以統一不同實體(embodiment)的觀察空間(observation space),因此可以使用單個視頻生成模型為不同機器人生成視覺執行計劃:

而且就像谷歌剛剛發布的世界生成模型Genie一樣,視頻生成也是復雜游戲的真實模擬器,可以與基于模型的規劃相結合,或者用于創建游戲。
生成視頻模擬器對于優化科學和工程領域的控制輸入也很有用,在這些領域可以收集大量視頻數據,但底層的物理動力學很難明確表達(例如,云運動、與軟物體的交互)。

預測下一幀,會像預測下一個字那樣改變世界
過去幾年,從互聯網文本數據集訓練大語言模型(LLMs)的工作取得了巨大進展。
LLM在各種任務上的出色表現讓人不禁想把人工智能的議程縮減為擴大這些系統的規模。
然而,大語言模型上取得的突破似乎也開始面臨了很多的局限。
首先,可公開獲取的文本數據的數量正變得越來越大。這將成為進一步擴展的瓶頸。
其次,也許更重要的是,僅靠自然語言可能不足以描述所有智能行為,也無法捕捉我們所處物理世界的所有信息(例如,想象一下僅用語言教人如何打結)。
雖然語言是描述高層次抽象概念的強大工具,但它并不總是足以捕捉物理世界的所有細節。
值得慶幸的是,互聯網上有豐富的視頻數據,僅YouTube上就有超過一萬年的連續視頻內容,其中包含了大量關于世界的知識信息。
然而,今天在互聯網文本或視頻數據上訓練出來的機器學習模型卻表現出了截然不同的能力。LLMs 已經能夠處理需要復雜推理、工具使用和決策制定的復雜任務。
相比之下,視頻生成模型的探索較少,主要集中在創建供人類消費的娛樂視頻。
鑒于語言建模領域正在發生的范式轉變,研究人員提出這樣一個問題:
我們能否將視頻生成模型提升到與語言模型類似的自主代理、模擬環境和計算引擎的水平,從而使機器人、自動駕駛和科學等需要視覺模式的應用能夠更直接地受益于互聯網視覺知識和預訓練視頻模型。
研究人員認為視頻生成對于物理世界的意義就如同語言模型對于數字世界的意義。
為了得出這一觀點,我們首先確定了使語言模型能夠解決許多現實世界任務的關鍵組成部分:(1) 能夠從互聯網吸收廣泛信息的統一表示法(即文本)、
(2) 統一的接口(即文本生成),通過它可以將不同的任務表達為生成建模,以及
(3) 語言模型能與外部環境(如人類、工具和其他模型)交互,根據外部反饋采取相應行動和優化決策,如通過人類反饋強化學習、規劃、搜索(姚等人,2023 年)和優化等技術。
從語言模型的這三個方面出發,研究人員發現:
(1) 視頻可以作為一種統一的表征,吸收物理世界的廣泛信息;
(2) 視頻生成模型可以表達或支持計算機視覺、嵌入式人工智能和科學領域的各種任務;
(3) 視頻生成作為一種預訓練目標,為大型視覺模型、行為模型和世界模型引入了互聯網規模的監督,從而可以提取動作、模擬環境交互和優化決策。
為了進一步說明視頻生成如何對現實世界的應用產生深遠影響,他們深入分析通過指令調整、上下文學習、規劃和強化學習(RL)等技術,在游戲、機器人、自動駕駛和科學等領域將視頻生成用作任務求解器、問題解答、策略/代理和環境模擬器。
視頻生成的前提設置
研究人員將視頻片段表示為一系列圖像幀 x = (x 0 , ..., x t )。圖像本身可被視為具有單幀 x = (x 0 , ) 的特殊視頻。條件視頻生成模型是條件概率 p(x|c),其中 c 是條件變量。條件概率 p(x | c) 通常由自回歸模型、擴散模型或掩蔽Transformer模型進行因子化。
根據不同的因式分解,p(x | c)的采樣要么對應于連續預測圖像(斑塊),要么對應于迭代預測所有幀(x 0 ,...,x t )。
根據條件變量 c 的內容,條件視頻生成可以達到不同的目的。
統一表征法和任務接口
在本節中,作者首先介紹了視頻是如何作為一種統一的表征,從互聯網中捕捉各種類型的信息,從而形成廣泛的知識。
然后,討論如何將計算機視覺和人工智能中的各種任務表述為條件視頻生成問題,從而為現實世界中的視頻生成決策提供基礎。
作為信息統一表征的視頻
雖然互聯網文本數據通過大型語言模型為數字/知識世界提供了很多價值,但文本更適合捕捉高級抽象概念,而不是物理世界的低級細節。
研究人員列舉幾類難以用文本表達,但可以通過視頻輕松捕捉的信息。

-視覺和空間信息:這包括視覺細節(如顏色、形狀、紋理、光照效果)和空間細節(如物體在空間中的排列方式、相對位置、距離、方向和三維信息)。
與文本格式相比,這些信息自然是以圖像/視頻格式存在的。
-物理和動力學:這包括物體和環境如何在物理上相互作用的細節,如碰撞、操作和其他受物理規律影響的運動。
雖然文字可以描述高層次的運動(如 "一輛汽車在街道上行駛"),但往往不足以捕捉低層次的細節,如施加在車輛上的扭矩和摩擦力。視頻可以隱含地捕捉到這些信息。
-行為和動作信息:這包括人類行為和代理動作等信息,描述了執行任務(如如何組裝一件家具)的低層次細節。
與精確的動作和運動等細節信息相比,文本大多能捕捉到如何執行任務的高級描述。
為什么是視頻?
有人可能會問,即使文本不足以捕捉上述信息,為什么還要用視頻呢?
視頻除了存在于互聯網規模之外,還可以為人類所解讀(類似于文本),因此可以方便地進行調試、交互和安全推測。
此外,視頻是一種靈活的表征方式,可以表征不同空間和時間分辨率的信息,例如以埃級(10 -10 m)運動的原子和以每秒萬億幀速度運動的光。
作為統一任務接口的視頻生成
除了能夠吸收廣泛信息的統一表征外,研究人員還從語言建模中看到,需要一個統一的任務接口,通過它可以使用單一目標(如下一個標記預測)來表達不同的任務。
同時,正是信息表征(如文本)和任務接口(如文本生成)之間的一致性,使得廣泛的知識能夠轉移到特定任務的決策中。
經典計算機視覺任務
在自然語言處理中,有許多任務(如機器翻譯、文本摘要、問題解答、情感分析、命名實體識別、語音部分標記、文本分類等)都是視覺任務。
文本分類、對話系統,傳統上被視為不同的任務,但現在都統一到了語言建模的范疇內。
這使得不同任務之間的通用性和知識共享得以加強。
同樣,計算機視覺也有一系列廣泛的任務,包括語義分割、深度估計、表面法線估計、姿態估計、邊緣檢測和物體跟蹤。

最近的研究表明,可以將不同的視覺任務轉換成上圖所示的視頻生成任務,而且這種解決視覺任務的統一方法可以隨著模型大小、數據大小和上下文長度的增加而擴展。
將視覺任務轉換為視頻生成任務一般涉及以下步驟:
(1) 將任務的輸入和輸出(如分割圖、深度圖)結構化到統一的圖像/視頻空間中;
(2) 對圖像幀重新排序,使輸入圖像后跟有特定任務的預期輸出圖像(如常規輸入圖像后跟有深度圖);
(3) 通過提供輸入-輸出對示例作為條件視頻生成模型的輸入,利用上下文學習來指定所需的任務。
視頻即答案
在傳統的視覺問題解答(VQA). 隨著視頻生成技術的發展,一種新穎的任務是將視頻作為答案,例如,在回答 「如何制作折紙飛機 」時生成視頻。
與語言模型可以對文本中的人類詢問生成定制回復類似,視頻模型也可以對具有大量低級細節的如何操作問題生成定制回復。
對于人類來說,這樣的視頻回答可能比文本回答更受歡迎。

在上圖中,研究人員展示了由文本到視頻模型生成的視頻,這些視頻是對一組 「如何做 」問題的回答。
此外,還可以考慮以初始幀為生成條件,在用戶特定場景中合成視頻答案。
盡管有如此宏大的前景,但當今文本到視頻模型合成的視頻一般都太短/太簡單,沒有足夠的信息來完全回答用戶的問題。
合成視頻幀以回答用戶問題的問題與使用語言模型進行規劃有相似之處,人們可以利用語言模型或視覺語言模型將高層次目標(如 「如何制作壽司」)分解為具體的子目標(如 「首先,將米飯放在滾動墊上」),并為每個子目標合成計劃,同時驗證合成計劃的合理性。
視覺推理和思維鏈
有了統一的信息表征和統一的任務界面,語言模型中就出現了推理,模型可以推導出相關信息,作為解決更復雜問題的中間步驟。

同樣,以視頻作為統一的表示和任務界面,視頻生成也通過預測圖像的遮蔽區域顯示出視覺推理的早期跡象,如上圖所示。
通過生成具有正確輔助線集的視頻,下一幀預測是否可用于解決更復雜的幾何問題,這將是一個有趣的課題。
在利用下一幀預測進行視覺推理和解決幾何問題的基礎上,還可以利用以下方法進一步描述推理過程和算法。
具體來說,利用視頻描述了廣度優先搜索(BFS)算法的執行狀態。

在這種情況下,學習生成視頻就相當于學習搜索,如上圖所示。
雖然圖 3 和圖 4 中的示例可能看起來有些矯揉造作,但它們作為早期指標表明,視頻生成作為一種預訓練任務,可能會引發類似于語言模型的推理行為,從而揭示了利用視頻生成解決復雜推理和算法任務的機會。
作為統一狀態-行動空間的視頻
視頻生成可以吸收廣泛的知識并描述不同的視覺任務。
研究人員將通過提供體現式人工智能中使用視頻作為統一表征和任務界面的具體實例來進一步支持這一觀點。
數據碎片化是體現式人工智能長期面臨的挑戰之一,在這種情況下,一個機器人在執行一組任務時收集的數據集很難用于不同機器人或不同任務的學習。
跨機器人和跨任務知識共享的主要困難在于,每種類型的機器人和任務都有不同的狀態-行動空間。為了解決這一難題,可以使用像素空間作為跨任務和環境的統一狀態行動空間。
在這一框架下,可將機器人規劃視為條件視頻生成問題,從而受益于互聯網預訓練視頻生成模型。
大多數現有工作都是為每個機器人訓練一個視頻生成模型,這削弱了將視頻作為統一的狀態-動作空間用于體現式學習的潛在優勢。

在上圖中提供了在 Open X-Embodiment 數據集 之前和新生成的視頻計劃看起來都非常逼真,并成功完成了指定任務。
視頻生成即模擬
視頻生成技術不僅能解決前文提到的眾多任務,還能夠在另一個重要領域發揮作用——模擬各種系統和過程的視覺效果,進而根據模擬結果優化系統的控制策略。
這一能力對于那些能夠收集到大量視頻數據,但難以精確描述底層物理動態的應用場景尤為重要,如云層的流動、與柔軟物體的交互等。
游戲環境的生成
多年來,游戲已成為測試AI算法的理想平臺。舉個例子,街機學習環境(Arcade Learning Environment)推動了深度Q學習技術的發展,這一技術成功讓AI智能體首次在Atari游戲中達到了人類的水平。
同樣的,我們可以通過與游戲引擎中的真實模擬結果進行對比,來驗證生成式模擬器的質量。
- 模擬復雜游戲環境
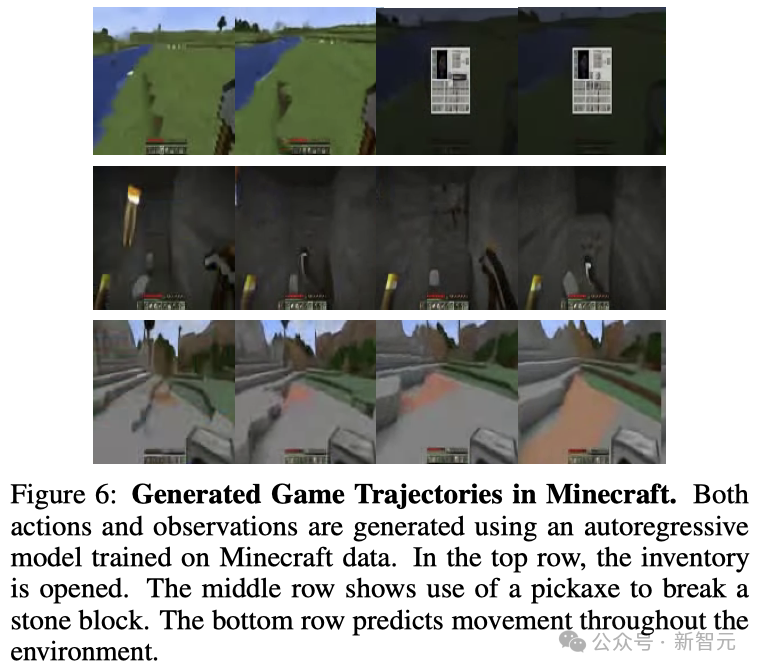
通過動作條件下的視頻生成技術,可以模擬出像Minecraft這類復雜電腦游戲的環境動態。
基于此,研究人員提出了一個能夠根據以往的游戲進程預測未來的動作和游戲狀態的Transformer模型。
游戲中的觀察結果和玩家動作都被轉化為了Token,這樣就把預測下一步動作簡化為了預測下一個Token。
值得注意的是,在這種情況下,模型既可以作為世界模型,也可以作為行動策略。
如圖6所示,給定一個以行動結束的觀察和行動交替序列,模型就能推斷出下一個觀察結果(世界模型);給定一個以觀察結束的類似序列,模型就能推斷出下一個要采取的行動(策略)。
借助這種策略和動態分析骨干,還可以應用基于模型的強化學習算法,如Dyna、Dreamer和MuZero,來進一步優化策略。
- 創造新型游戲環境
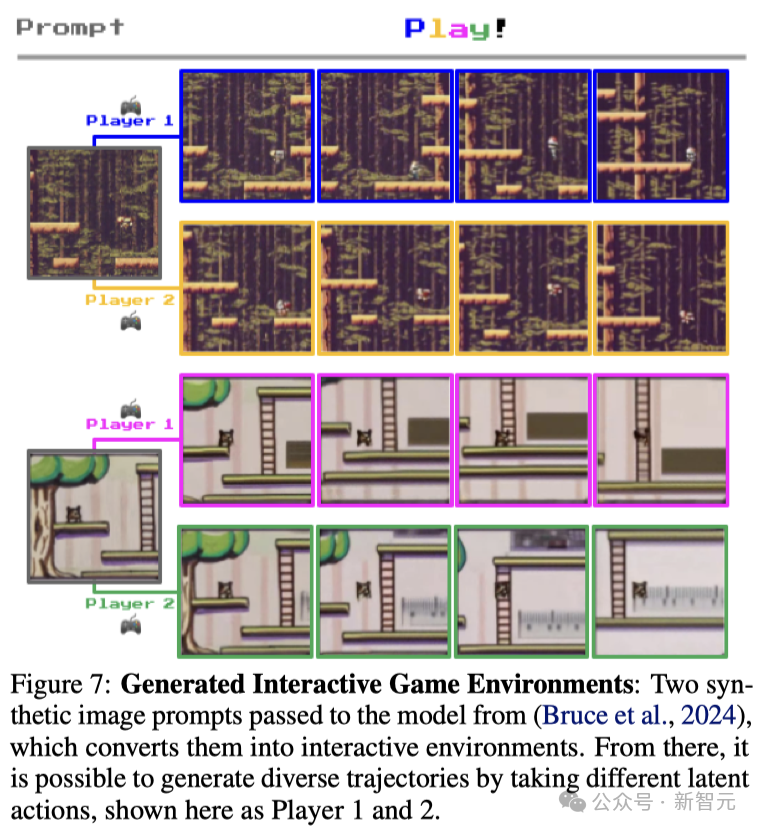
在游戲AI領域,程序化創造新型游戲內容和關卡是一個熱門研究方向,而這也已被證實對訓練和評價強化學習(RL)智能體非常有用。
如圖7所示,通過學習大規模互聯網上未經標注的游戲數據中的潛動作,然后訓練一個可控制動作的視頻模型,可以實現從一張提示圖像生成無限可能的多樣化互動環境。
雖然這項工作還處于探索階段,但在未來,我們或許可以通過集成學習到的獎勵模型,讓RL智能體在完全由生成模型創造的游戲環境中進行訓練。
機器人與自動駕駛
模擬SE(3)動作空間是機器人學習領域的一大挑戰,尤其體現在如何將在虛擬模擬器中訓練的策略成功應用到真實機器人上的問題。
此前的研究成功地在真實機器人的視頻數據上,針對Language Table環境,學習了一個基于動作的下一幀預測模型,并采用了一個簡單的笛卡爾(Cartesian)動作空間。
如圖8所示,可以看到,下一幀預測能夠預測出SE(3)空間中更為通用的末端執行器動作所產生的視覺效果。
生成式SE(3)模擬器的一個直接應用是評估機器人策略,這在涉及真實機器人評估的安全考慮時特別重要。
除了評估,此前的研究還在Language Table環境中使用來自生成式模擬器的rollouts訓練了強化學習(RL)策略。
下一個步驟可能是,使用Dyna式算法并結合模擬的演示和真實環境的數據來學習策略。
在這種情況下,當策略在執行時,真實世界的視頻會被收集起來,為生成式模擬器提供額外的示范和反饋。
最后,通過在多樣化環境中進行視頻演示,生成式模擬器能夠有效地訓練多任務和多環境策略,這在之前是無法實現的,因為通常一個策略一次只能接觸到一個真實世界環境。

科學與工程
視頻已經成為了跨越眾多科學和工程領域的一個統一的表現形式,對醫學成像、計算機圖像處理、計算流體動力學等領域的研究產生了影響。
在一些情況下,雖然我們可以通過攝像頭輕松捕捉到視覺信息,但是很難識別背后的動態系統(比如云的運動,或者電子顯微鏡下原子的運動)。
而基于控制輸入的視頻生成模型可以成為一個有效的視覺模擬工具,進而幫助我們得到更優的控制方案。
下圖展示了硅原子在碳原子單層上,在電子束的刺激下的動態變化。可以看到,這種生成式模擬器能夠準確地在像素層面捕捉硅原子的移動。
除了幫助縮小模擬與現實之間的差距,生成式模擬器還有一個優點是它們的計算成本是固定的,這在傳統計算方法無法應對的情況下尤為重要。

總結
總結而言,研究人員認為,視頻生成技術在物理世界的作用,就像語言模型在數字世界中的角色一樣重要。
團隊通過展示視頻如何能夠像語言模型一樣,廣泛地表達信息和執行任務來支持這個觀點。
并且,從新的角度探討了視頻生成技術的應用,這些應用通過結合推理、場景中的學習、搜索、規劃和強化學習等方法,來解決現實世界中的問題。
雖然視頻生成模型面臨著如虛假生成(幻覺)和泛化能力等挑戰,但它們有潛力成為自主的AI智能體、規劃者、環境模擬器和計算平臺,并最終可能作為一種人工智能大腦,在物理世界中進行思考和行動。