













港大開源推薦系統新范式RLMRec!大模型加持,準確提煉用戶/商品文本畫像
推薦系統在深度學習和圖神經網絡的影響下已經取得了重大進步,尤其擅長于捕捉復雜的用戶-物品關系。
然而,現有基于圖神經網絡(GNNs)的推薦算法普遍僅依賴于ID數據構造的結構化拓撲信息,導致其大量存在于推薦數據集中與用戶和物品相關的原始文本數據,因此,其學習到的表示不夠信息豐富。
此外,協同過濾中運用到的隱式反饋(Implicit Feedback)數據存在有潛在的噪聲和偏差,其對深度模型在用戶偏好學習的有效性也提出了挑戰。
目前,如何將大語言模型(LLMs)與傳統的基于ID數據的推薦算法相互結合,已經受到了學界以及工業界的廣泛關注。但是,仍然存在有許多困難,例如算法的可擴展性,語言模型的輸入限制(僅文本模態以及輸入長度限制),使其大語言模型無法在實際運用的推薦系統中有效提供幫助。
為了應對這些限制,來自香港大學等機構的研究人員提出了一種利用大語言模型來促進現有推薦算法表征學習的框架RLMRec,并且在實驗中將其與現有的最先進的推薦算法相結合,在真實數據集中進一步提升了算法的推薦性能。

論文地址:https://arxiv.org/abs/2310.15950
代碼地址:https://github.com/HKUDS/RLMRec
具體而言,該范式通過利用大語言模型從文本角度挖掘用戶行為偏好以及商品語義特征,并且利用最大化互信息的方式將文本信號和來自于圖神經網絡的協同信號增強對齊,從而有效促進算法學習到的表征質量。
基于RLMRec,我們分別基于了對比式學習和生成式學習構建了RLMRec-Con和RLMRec-Gen兩套范式。這兩套范式在不同的測試場景下展現出了不同的優點,因此可以靈活的運用于不同的實際場景。
理論角度緩解協同信號中的噪聲
在基于圖神經網絡的協同過濾推薦算法中,其基于協同信號,會為每一個用戶/商品學習到一個表征。
我們稱之為基于協同信號的表征,從用戶的角度,其反應了用戶對于商品的偏好;從商品的角度,其反應了它吸引的用戶群體。然而,由于協同信號中可能存在的噪聲(例如誤點擊、流行度偏差等等),表征中不可避免的受到了噪聲(noise)的影響。
我們不妨設在推薦的視角下,對推薦存粹有益的潛在信號為,那么表征則同時由與潛在噪聲生成。考慮到協同數據中并不存在文本語義信息,因此在本文中,我們將其作為突破口,考慮利用文本語義信號(semantic information)來緩解這一現象。
我們不妨設對于每一個用戶/商品,我們都擁有一個基于文本語義而產生的表征,其基于的原始文本本身能夠準確地反應了用戶喜好的商品類別,和商品所吸引的用戶群體,因此中也包含了來自于潛在信號的信息,但是同時也包括了一些與推薦無關的信號(例如表征中可能體現的語法等語言屬性)。因此我們可以構建如下的概率圖模型。

為了能夠提高協同過濾算法所學習到的表征e的質量,我們構建的如下的學習目標

直觀上將,我們希望能夠最大化協同信號表征e與文本信號表征s以及潛在信號z直接的關聯,從而使得表征e中包含更多有益的信息以增強推薦的性能。
通過理論推導,最大化上述目標等價于最大化表征e和表征s之間的互信息I(e, s),并且最終可以轉換成優化如下目標

其中f是密度函數,體現了二者的相似程度。上述的表征學習過程可以形象化地體現為如下過程:

在優化的過程中,我們不斷增加協同信號表征e與文本信號表征s中重疊的部分,從而不斷的減少噪聲在協同信號表征中的占比,從而獲得高質量的特征學習結果,以促進推薦性能提高。
為了真正實現上述的理論推導后的優化目標,我們仍然有兩點挑戰:
1. 如何通過文本有效的用戶/商品真實的交互偏好以獲得高質量的文本語義表征;
2. 如何實現密度函數f從而高效地優化我們的學習目標。
我們將在接下來的兩節中分別闡述如何解決上述這兩點挑戰。
準確提煉用戶/商品文本畫像
為了獲得文本信號表征,我們首先需要擁有文本模態上對于用戶和商品的準確畫像描述,其需要是無偏差的,從而能夠反應出用戶和商品真實的偏好。我們希望用戶畫像能夠有效的反應出其喜好什么類別的商品,并且商品畫像能夠反應出其會吸引什么樣的用戶群體。
在真實的推薦數據集中(例如Yelp、Amazon-book)存在有許多的對于原始文本數據,例如商品描述、用戶評論等等,但是這些原始文本數據同樣存在這大量的噪音,例如在Steam數據集中,玩家對于電子游戲的評論會存在有大量的非語義符號。
噪音的存在使得我們在以往難以利用上這些文本數據。幸運的是,隨著大語言模型的發展,其高效的文本總結能力和自然語言處理能力是我們能夠達成這一目標。
在本節中,我們基于大語言模型(LLMs)和思維鏈(Chain-of-Thought)的思想,提出了一種從商品到用戶的文本畫像構建路徑。其能夠保證在現有的數據下,準確無誤無偏的反應出用戶和商品的交互偏好,以便于我們獲得高質量的文本語義表征。
簡單來說,我們先基于用戶的反饋或是商品的自身描述,基于大語言模型的知識先對商品的畫像進行總結,并且要求其提供思考的過程,基于此,我們可以首先獲得基于商品的無偏文本畫像。
其次我們將用戶對商品的反饋以及商品文本畫像相結合,輸入給大語言模型,使其總結用戶畫像,因為用戶的反饋中包含了用戶的真實喜好,因此語言模型能夠準確的把握住用戶的真實喜好,從而產生準確的文本畫像。
最后,我們利用先進的文本嵌入模型將文本畫像轉化為文本表征表征,上述過程的示意圖如下(在論文的附錄中,我們對生成過程進行了具體的案例描述)

對比式/生成式建模密度函數
密度函數的輸出是一個實數,反應了輸入的兩個表征的之間的相似程度。對于該函數的建模越有效越精確,就可以更好的實現互信息最大化,從而實現協同信號表征和文本語義信號表征之間的對齊。
在本文中我們考慮兩種不同的建模方法,從而實現了兩種不同的對齊方式。
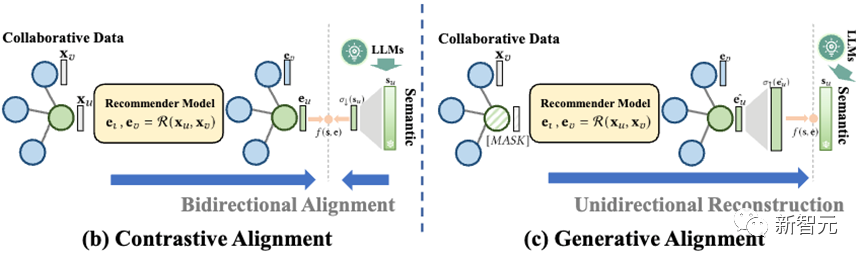
第一種是對比式對齊(Contrastive Alignment,RLMRec-Con),其具體建模形式如下

簡單來說,我們將文本語義表征通過網絡進行縮放,使其與協同信號表征具有相同的維度,而后用余弦相似度來計算它們之間的相似程度。
結合之前的優化函數,實際上這與對比學習的過程十分相似,因此我們稱之為對比式對齊。形象化的來說,在該過程中,兩個表征雙向奔赴,不斷互相對齊彼此。
第二種是生成式對齊(Generative Alignment,RLMRec-Gen),其具體形式如下
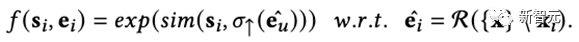
簡單來說,我們是基于生成式掩膜子編碼器(Generative Masked Auto-encoder)的思想,將部分節點的原始特征進行掩蓋,然后將推薦算法編碼出來的這些節點的特征進行縮放,使其具有和文本語義表征相同的維度,而后進行對齊。
形象化的來說,在該過程中,協同表征向文本語義表征單向逼近,生成式地重構對方,從而實現對齊。
我們在后續的實驗過程中,探尋了兩種方法(RLMRec-Con和RLMRec-Gen)在不同的場景下的優勢。
實驗驗證
我們在三個公開數據集(Yelp,Amazon-book,Steam)上,使用現有的先進協同過濾算法(GCCF、LightGCN、SGL、SimGCL、DCCF和AutoCF)作為基準模型,配合RLMRec進行了性能的驗證。通過多次隨機試驗求均值,我們發現RLMRec可以有效且顯著地進一步提升現有推薦算法的性能。
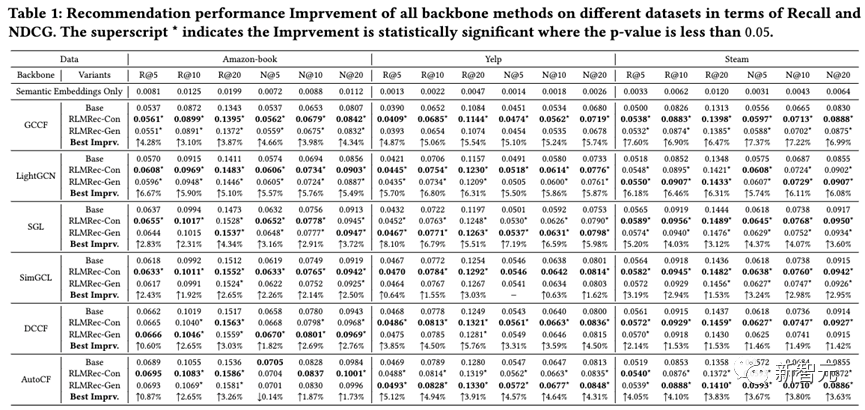
從結果中可以看出。對比式學習(RLMRec-Con)所帶來的性能提升,相較于生成式學習(RLMRec-Gen)更加顯著,但是對于自身就是生成式建模的推薦算法(AutoCF)而言,生成式學習帶來的性能提升更多,由此可見使用兩種方式需要應算法而制宜。
進一步的,為了探尋是否真的是文本信號的引入提高了推薦的性能(而非是框架的設計),我們將用戶/商品的協同信號和文本信號之間的對應關系進行了打亂(Shuffle),從而造成錯誤的信號對應關系,并進行了性能試驗如下
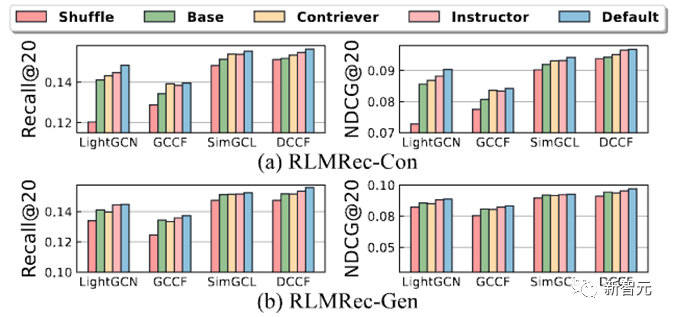
從結果中可以看出,在打亂了信號對應關系中,錯誤的文本語義的引入會導致表征學習無法正常進行,即協同信號表征無法有效的向語義表征逼近(停留在原地),因此性能相對顯著下降。
同時我們也利用了不同的語義嵌入模型(Instructor、Contriever)來生成語義表征,我們發現越好的語義嵌入模型生成的語義表征能夠更好的增益RLMRec。
其次,我們進行了噪音試驗,通過隨機加上不同程度的噪聲,來探討RLMRec對噪聲的抵抗能力,結果如下
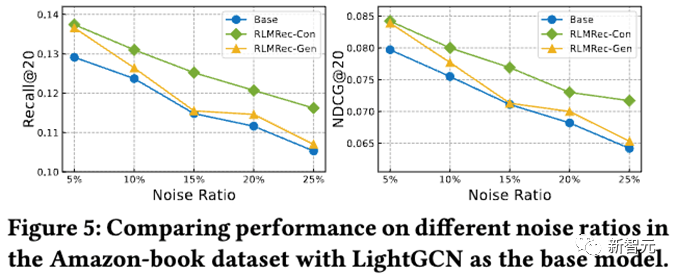
從結果中可以看出,不論在什么程度的噪聲下,在RLMRec框架下訓練獲得的表征能夠相對于基線模型有更好的性能,同時對比式對齊能夠抵御噪聲的能力更強,我們認為這是因為生產式對齊由于存在有掩膜(Mask)的操作,在特征層面上已經引入了一部分噪聲,因此應對結構化噪聲的能力有所下降,不過相對于基線模型,都是有增益的。
進一步的,我們探討了RLMRec的兩種范式能否應用于預訓練(Pre-training)。基于此,我們將Yelp數據集中從2012-2017年的數據作為預訓練數據,2018-2019年的數據作為微調(fine-tune)數據,并最終測試性能,結果如下
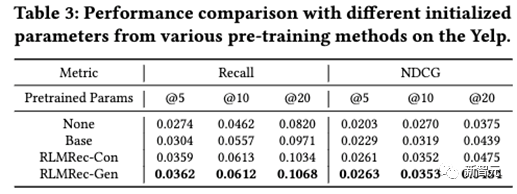
從結果中我們發現,在預訓練的場景下,生成式對齊RLMRec-Gen一致的具有更優的性能,我們認為這是因為通過生成式建模中的掩膜(Mask)操作,能夠有效防止過擬合,從而構成一種約束,因此所獲的的參數能夠有效遷移至新的數據上,這也與近年來通過生成式預訓練語言模型的范式不謀而合。
最后,我們進行了樣例研究(Case Study)

我們針對一個用戶計算了與其距離較遠(在Graph上大于3跳)的所有用戶的特征相似度,并且基于此從高到低排序。
我們發現即使是兩個用戶擁有相同的偏好,但是傳統的推薦算法獲得的表征,無法有效的體現出他們之間的相似性,這是因為他們的距離大于圖網絡的層數,因此無法互相監督。
通過在RLMRec中引入了文本信號信息,具有相同偏好的用戶表征被有效的拉近,從而他們的表征相似度也得到了提高,這從一定程度上說明通過引入文本信號來優化用戶/商品表征學習,能夠從全局的視角對具有相似偏好的用戶/商品進行有益的對齊,從而提高表征學習的質量最終提高推薦性能。
結語
在本文中我們提出了一種模型無關的基于大語言模型的推薦系統表征學習范式,通過合理的設計,利用大語言模型從海量原始文本數據中挖掘的純凈的文本語義信號,從而對協同信號表征進行優化,最終促進的最先進推薦算法性能的提升。
我們在GitHub上對數據集和代碼進行了開源,希望我們清洗后的具有文本標注的推薦數據集以及所提出的范式RLMRec能夠促進大語言模型和推薦系統的進一步融合。
最后,其實RLMRec的思想不單單能運用在推薦算法中,我們也在別的場景下進行了實踐,在百度的搜索算法框架下,我們將RLMRec中的對比式對齊的思想進行了測試,在搜索推薦的精度上也獲得了有益的提升,實現了算法的有效落地。


























