21個優秀開源網絡爬蟲庫,適合Python、Java、Go、JavaScript開發語言
網絡爬蟲是一種用于從互聯網上的網頁中提取數據的工具或代碼。互聯網數據價值不可估量,應用場景十分廣泛,網絡爬蟲對于互聯網數據的抓取發揮著重要作用。因此,從技術角度看,爬蟲推動了大數據的發展。

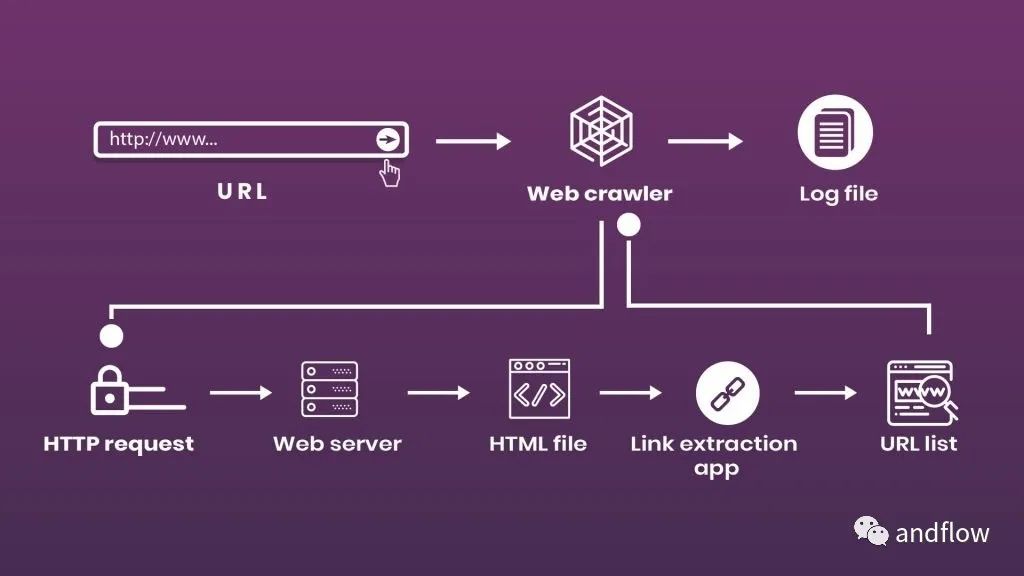
爬蟲的工作流程非常簡單,無非就是三個步驟:
- 模擬人類瀏覽網站的行為。輸入目標URL后,它向服務器發送一個請求,并在HTML文件中獲取信息。
- 有了HTML源代碼,機器人就能夠到達目標數據所在的節點,并按照抓取代碼中的命令解析數據。
- 清洗抓取的數據,轉換數據結構,并保存到數據庫。
但在實際互聯網環境下,無處不存在著道高一尺魔高一丈的博弈。因此并沒有完美的爬蟲工具,只能說盡量選擇比較靈活、易于擴展的庫,根據實際需要進行配置或開發。
在各種網絡爬蟲工具中,開源網絡爬蟲具備高靈活性、可擴展性,也更受技術人員的青睞。甚至有些爬蟲項目能夠實現無代碼或低代碼。
以下分別是在Python、Java、Go、JavaScript等開發語言領域比較優秀的開源網絡爬蟲庫。
- Python:Scrapy、PySpider、Mechanical Soup、AutoCrawler
- java:WebMagic、Crawler4j、WebCollector、Nutch、Heritrix、Web_harvest、StormCrawler
- Golang:Crawlab、ferret、Hakrawler、Crawlergo、Geziyor、Gospider、Gocrawl、fetchbot
- JavaScript:Node-crawler、EasySpider
1.Scrapy
開發語言: Python
GitHub(49.3K):https://github.com/scrapy/scrapy

Scrapy是Python中最受歡迎的開源Web爬蟲和協作Web抓取工具。有助于從網站中有效地提取數據,根據需要處理數據,并以一定數據格式(JSON,XML和CSV)保存。
優點:
- 快速且強大
- 易于使用,有詳細的文檔
- 無需修改內核即可增加新功能
- 健康的社區和豐富的資源
- 支持在云環境中運行
2.PySpider
開發語言: Python
GitHub(16.1K):https://github.com/binux/pyspider
PySpider是一個強大的Python網絡爬蟲系統。采用分布式系統架構,提供易于使用的Web UI,提供了調度器、提取器和處理器等諸多組件。它支持MongoDB、MySQL等數據庫。
優點:
- 強大的WebUI,包含腳本編輯器、任務監視器、項目管理器和結果查看器
- 支持使用RabbitMQ、Beanstalk、Redis和Kombu作為消息隊列
- 分布式架構
3.Mechanical Soup
開發語言:Python
GitHub(4.5K):https://github.com/MechanicalSoup/MechanicalSoup

Mechanical Soup是一個Python庫,旨在模擬人類在使用瀏覽器時與網站的交互。它基于Python的Requests(用于HTTP會話)和BeautifulSoup(用于文檔導航)構建。可自動存儲和發送cookie,遵循重定向,遵循鏈接,并提交表單。
優點:
- 模擬人類行為的能力
- 快速抓取相當簡單的網站
- 支持CSS和XPath選擇器
4.AutoCrawler
開發語言:Python
GitHub(19.1K):https://github.com/YoongiKim/AutoCrawler
這是個可控制Naver多進程圖像爬蟲(高品質速度可定制)。
5.WebMagic
開發語言:Java
GitHub(11K):https://github.com/code4craft/webmagic

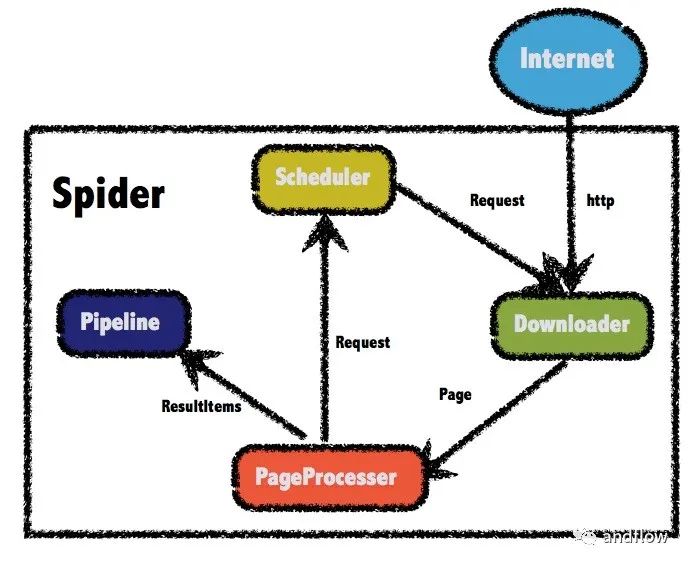
webmagic是一個開源的Java爬蟲框架,目標是簡化爬蟲的開發流程,讓開發者專注于邏輯功能的開發。下圖是WebMagic的工作流程圖。
優勢:
- 完全模塊化的設計,強大的可擴展性。
- 核心簡單但是涵蓋爬蟲的全部流程,靈活而強大,也是學習爬蟲入門的好材料。
- 提供豐富的抽取頁面API。
- 無配置,但是可通過POJO+注解形式實現一個爬蟲。
- 支持多線程。
- 支持分布式。
- 支持爬取js動態渲染的頁面。
- 無框架依賴,可以靈活地嵌入到項目中去。
Maven:
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>${webmagic.version}</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>${webmagic.version}</version>
</dependency>6.crawler4j
開發語言:Java
GitHub(4.5K):https://github.com/yasserg/crawler4j

crawler4j是一個開源的Java網絡爬蟲,它提供了一個簡單的接口, 抓取網頁使用它,可以在幾分鐘內設置一個多線程的網絡爬蟲。
Maven:
<dependency>
<groupId>edu.uci.ics</groupId>
<artifactId>crawler4j</artifactId>
<version>4.4.0</version>
</dependency>7.WebCollector
開發語言:Java
GitHub(3K):https://github.com/CrawlScript/WebCollector
WebCollector是一個基于Java的開源網絡爬蟲框架。它提供了一些簡單的界面,可以在5分鐘內設置一個多線程網絡爬蟲。它除了是一個通用的爬蟲框架之外,WebCollector還集成了CEPF(Web內容提取算法)。Maven:
<dependency>
<groupId>cn.edu.hfut.dmic.webcollector</groupId>
<artifactId>WebCollector</artifactId>
<version>2.73-alpha</version>
</dependency>8.Apache Nutch
開發語言:Java
GitHub(2.7K):https://github.com/apache/nutch

Apache Nutch是一個完全用Java編寫的開源scraper,具有高度模塊化的架構,提供了解析媒體類型、數據檢索、查詢和集群等插件。作為可插拔和模塊化的,Nutch還提供了可擴展接口。
優點:
- 高度可擴展和可伸縮
- 遵守txt規則
- 充滿活力的社區和積極發展
- 可插拔的解析、協議、存儲和索引
9.Heritrix
開發語言:Java
GitHub(2.6K):https://github.com/internetarchive/heritrix3
Heritrix是一個基于JAVA的開源爬蟲工具,具有高度的可擴展性,并高度尊重robot.txt排除指令和Meta機器人標簽,并以自適應速度收集數據,執行穩定性好。它提供了一個基于Web的用戶界面,可通過Web瀏覽器訪問,以供操作員控制、監控。
優點:
- 可更換的可插拔模塊
- 基于web的界面
- 尊重robot.txt和Meta robot標記
- 延展性良好
10.Web-Harvest
開發語言:Java
下載地址:https://sourceforge.net/projects/web-harvest/
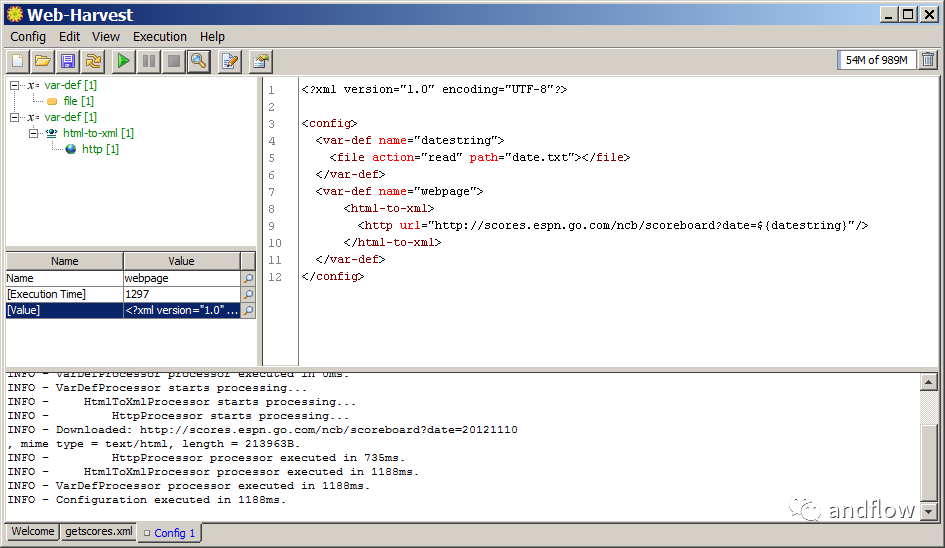
Web-Harvest是一個用Java編寫的開源爬蟲工具。它可以從指定的頁面收集有用的數據。它利用XML、XQuery和正則表達式等技術來操作或過濾基于HTML/XML的網站的內容,可以很容易地擴展,以增強其提取能力。
優點:
- 可用于數據處理的強大文本和XML操作處理器
- 用于存儲和使用的上下文變量
- 支持真實的腳本語言,可輕松集成到項目中
11.StormCrawler
開發語言: Java
GitHub(825):https://github.com/DigitalPebble/storm-crawler

StormCrawler是一個成熟的開源Java網絡爬蟲。它由一系列可重用的資源和組件組成。可用于在Java中構建低延遲、可擴展、易優化的Web爬蟲。
優點:
- 高度可擴展,可用于大規模遞歸爬網
- 易于使用其他Java庫進行擴展
- 出色的線程管理,減少了抓取的延遲
12.crawlab
開發語言:Go
GitHub(10.4K):https://github.com/crawlab-team/crawlab
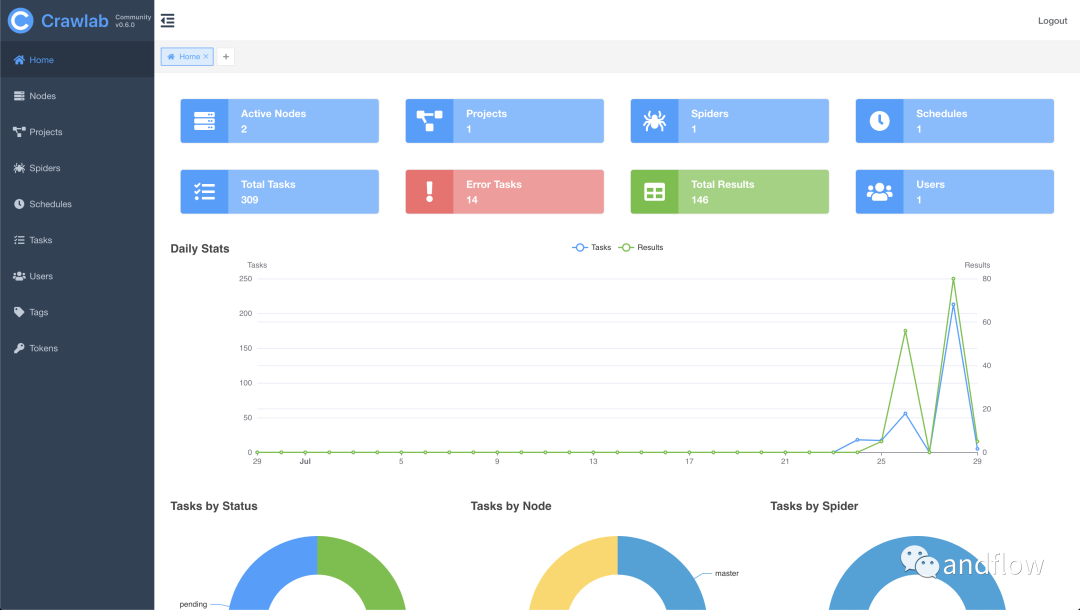
基于Golang的分布式網絡爬蟲管理平臺,支持Python、NodeJS、Go、Java、PHP等多種語言,支持Scrapy、Puppeteer、Selenium等多種網絡爬蟲框架。
簡單說:它是管理爬蟲的管理工具。
13.ferret
開發語言:Go
GitHub(5.5K):https://github.com/MontFerret/ferret
ferret是一個網頁爬蟲系統。旨在簡化從Web中提取的數據,用于UI測試、機器學習、分析等。
ferret允許用戶專注于數據。它使用自己的描述性語言抽象出底層技術的技術細節和復雜性。它非常便攜、可擴展和快速。
優勢:
- 支持描述性語言
- 支持靜態和動態網頁
- 可嵌入
- 可擴展
下面是ferret的架構圖:
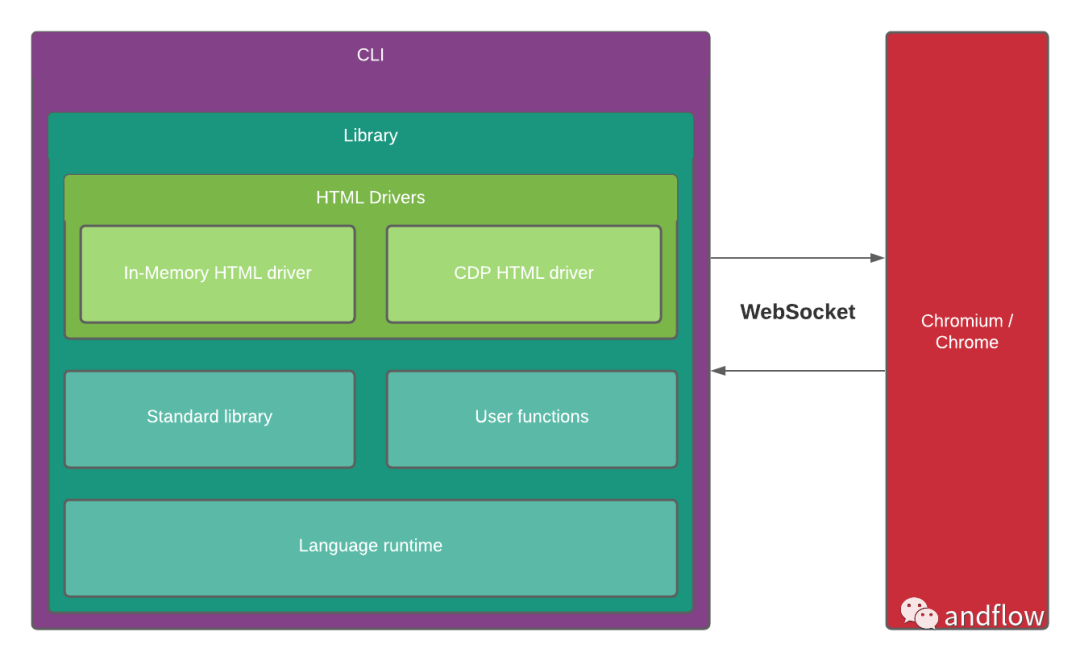
14.hakrawler
開發語言:Go
GitHub(4K):https://github.com/hakluke/hakrawler
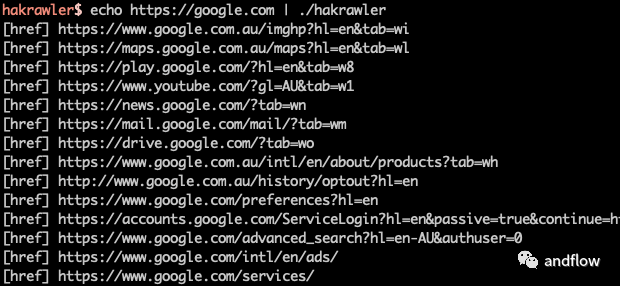
這是一個簡單、快速的Web爬蟲,旨在輕松、快速地發現Web應用程序中的端點和資產。用于收集URL和JavaScript文件位置的快速golang爬蟲。是一個很棒的Gocolly庫的簡單實現。
15.crawlergo
開發語言:Go
GitHub(2.6K):https://github.com/Qianlitp/crawlergo

crawlergo是一個使用chrome headless模式進行URL收集的網頁爬蟲。它對整個網頁的關鍵位置與DOM渲染階段進行HOOK,盡可能收集網站暴露的入口,自動進行表單填充并提交,配合智能的JS觸發事件。內置URL去重模塊,過濾掉了大量偽靜態URL,對于大型網站仍保持較快的解析與抓取速度,最后得到高質量的請求結果集合。
優勢:
- 原生瀏覽器環境,線程池調度任務
- 表單智能填充、自動化提交
- 完整DOM事件收集,自動化觸發
- 智能URL去重,去掉大部分的重復請求
- 全面分析收集,包括javascript文件內容、頁面注釋、robots.txt文件和常見路徑Fuzz
- 支持Host綁定,自動添加Referer
- 支持請求代理,支持爬蟲結果主動推送
16.geziyor
開發語言:Go
GitHub(2.3K):https://github.com/geziyor/geziyor
Geziyor是一個非常快速的網頁抓取和網頁抓取框架。它可以用來抓取網站并從中提取結構化數據。Geziyor可用于廣泛的目的,如數據挖掘,監控和自動化測試。
17.Gospider
開發語言:Go
GitHub(2.2K):https://github.com/jaeles-project/gospider
Gospider是一個用Go語言編寫的快速網絡爬蟲。
可在Docker運行:
# Clone the repo
git clone https://github.com/jaeles-project/gospider.git
# Build the contianer
docker build -t gospider:latest gospider
# Run the container
docker run -t gospider -h18.Gocrawl
開發語言:Go
GitHub(2K):https://github.com/PuerkitoBio/gocrawl
一個輕量級,高并發網絡爬蟲。
19.fetchbot
開發語言:Go
GitHub(777+):https://github.com/PuerkitoBio/fetchbot

這是一個Go包,提供了一個簡單而靈活的網絡爬蟲功能,遵循robots.txt 策略,支持延遲機制。
這是一個基于gocrawl重新改造的爬蟲,具備更簡單的API,更少的內置功能,但更靈活。
20.Node-crawler
開發語言: JavaScript
GitHub(6.5K):https://github.com/bda-research/node-crawler

Node-crawler是一個強大的、流行的、基于Node.js的網絡爬蟲。完全用Node.js編寫,支持非阻塞異步I/O,實現爬蟲的流水線運行機制。同時支持DOM的快速選取(無需編寫正則表達式)。
優點:
- 支持速率控制
- 支持不同優先級的requestsURL請求
- 可配置的池大小和重試次數
- 服務器端使用Cheerio(默認)或JSDOM實現jQuery自動插入DOM
21.EasySpider
開發語言:JavaScript
GitHub(17.5K):
https://github.com/NaiboWang/EasySpider
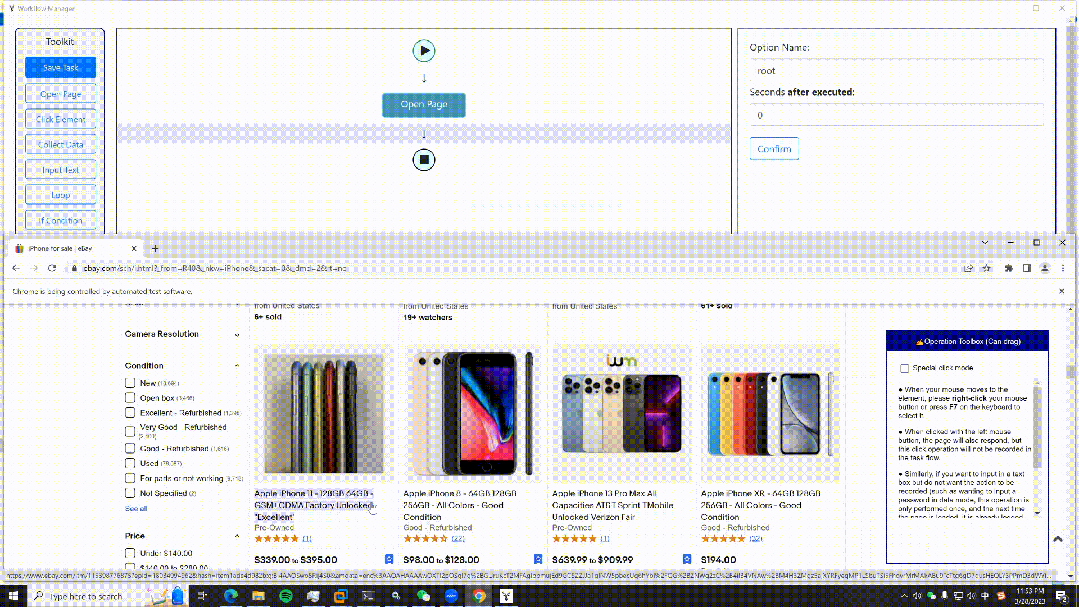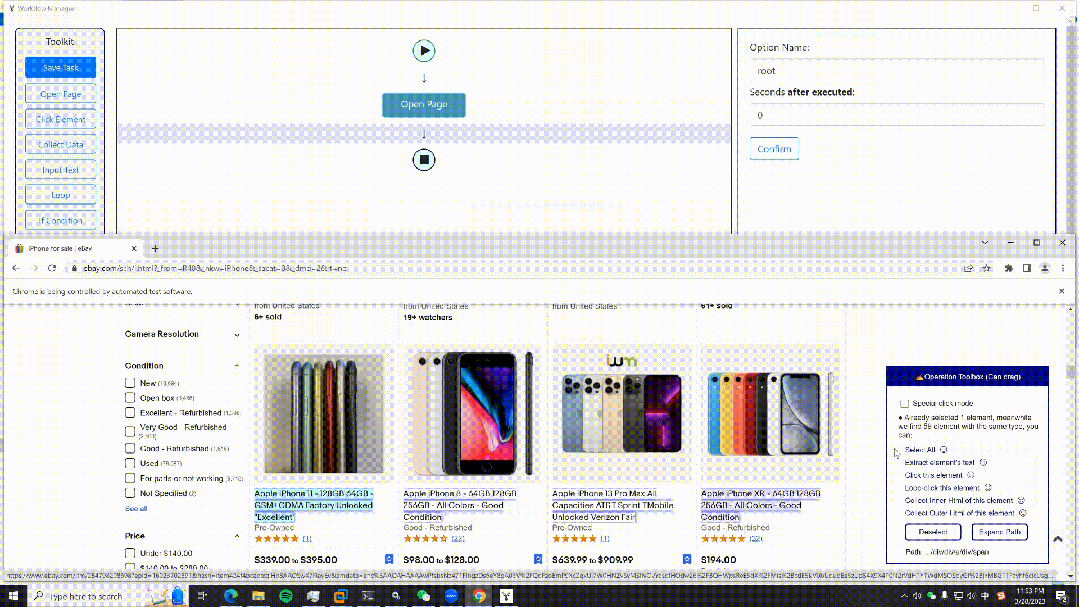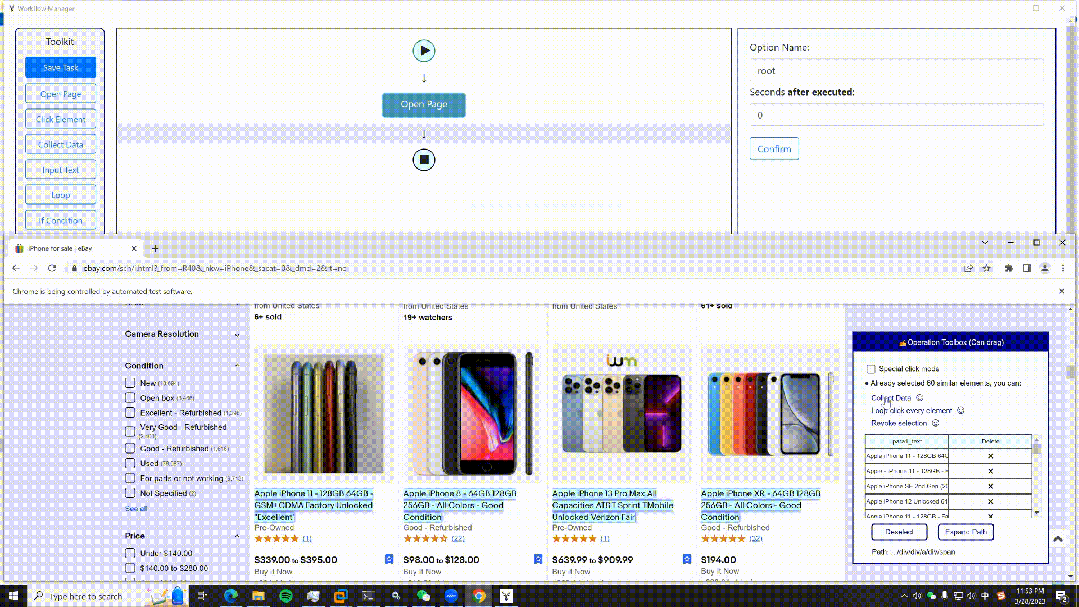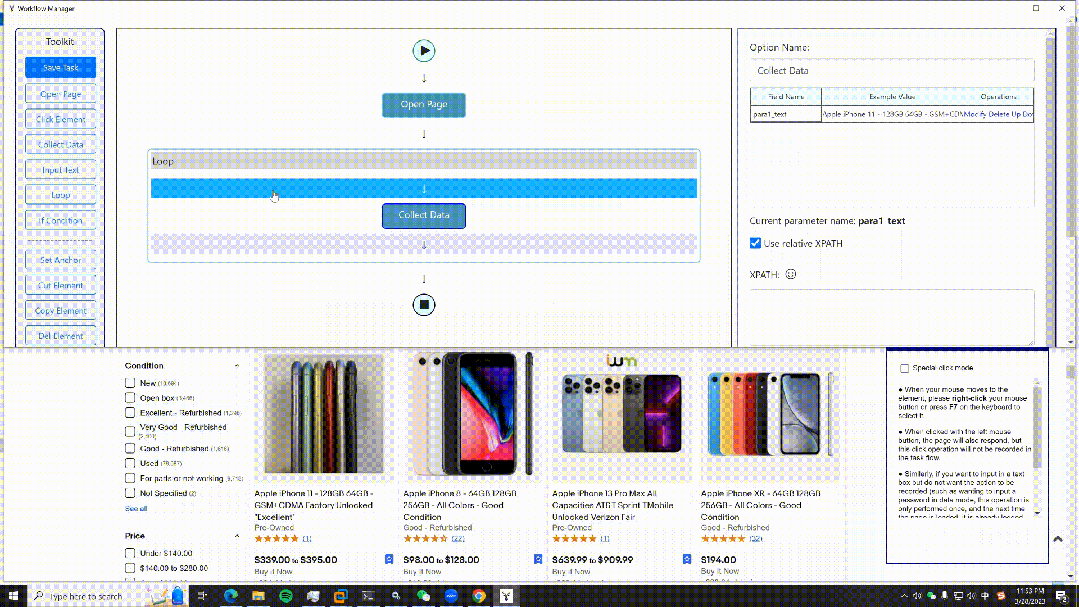
這是一個可視化瀏覽器自動化測試/數據采集/爬蟲軟件,可以使用圖形化界面,無代碼可視化的設計和執行任務。只需要在網頁上選擇自己想要操作的內容并根據提示框操作即可完成任務的設計和執行。同時軟件還可以單獨以命令行的方式進行執行,從而可以很方便地嵌入到其他系統中。