最新Claude 200K嚴重「虛標」?大神壕擲1016美元實測,90K后性能急劇下降
OpenAI正忙著政變的時候,他們在硅谷最大的競爭對手Anthropic,則悄悄地搞了個大新聞——發布了支持200K上下文的Claude 2.1。

看得出來,Claude 2.1最大的升級就是將本就很強大的100K上下文能力,又提升了一倍!
200K的上下文不僅可以讓用戶更方便的處理更多的文檔,而且模型出現幻覺的概率也縮小了2倍。同時,還支持系統提示詞,以及小工具的使用等等。

而對于大多數普通用戶來說,Claude最大的價值就是比GPT-4還強的上下文能力——可以很方便地把一些超過GPT-4上下文長度的長文檔丟給Claude處理。
這樣使得Claude不再是ChatGPT的下位選擇,而成為了能力上和ChatGPT有所互補的另一個強大工具。
所以,Claude 2.1一發布,就網友上手實測,看看官方宣稱的「200K」上下文能力到底有多強。

Claude 2.1 200K上下文大考:頭尾最清楚,中間幾乎記不住
本月初,當OpenAI發布了GPT-4 turbo的時候,技術大佬Greg Kamradt就對OpenAI的新模型進行了各方面的測試。
他把YC創始人Paul Graham文章的各個部位都添加了標記性的語句后喂給模型,然后來測試它讀取這些語句的能力。
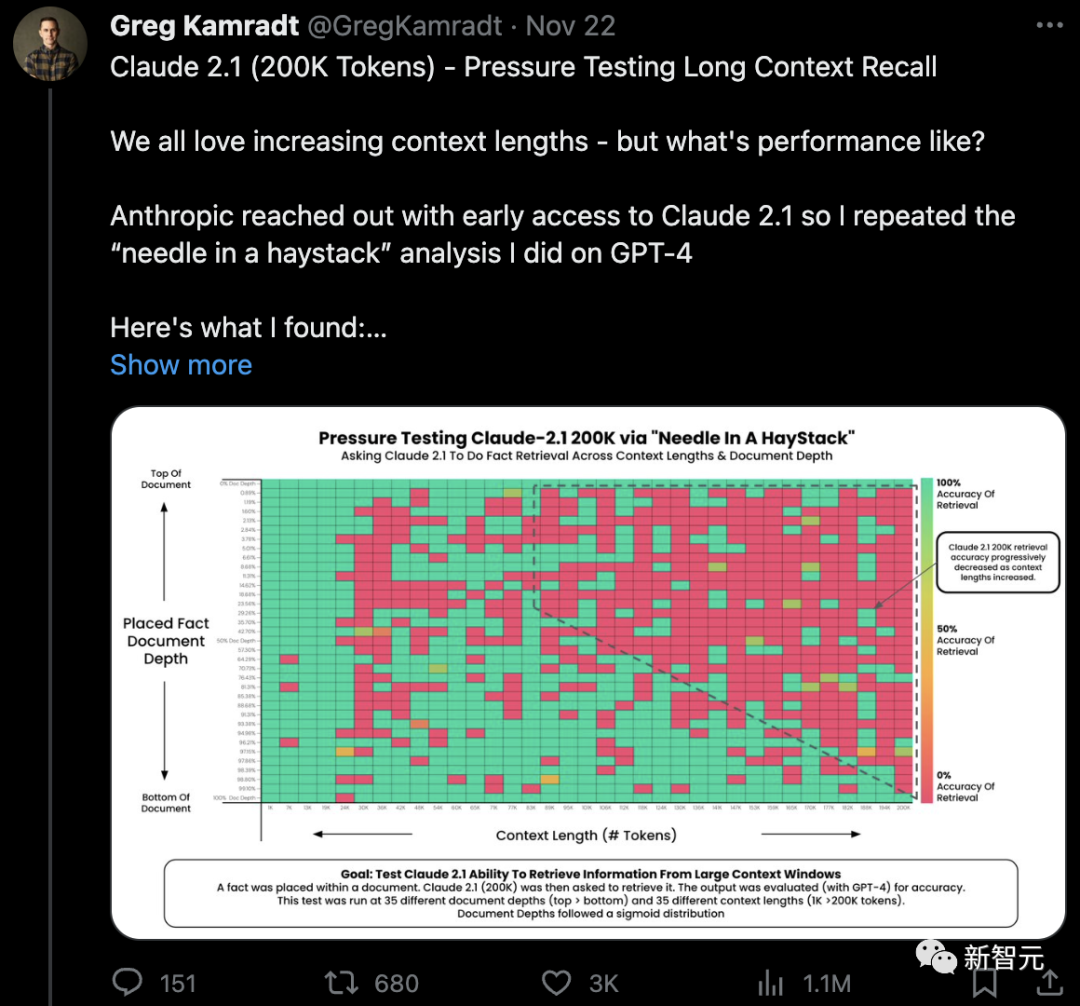
用幾乎同樣的方法,他對Claude 2.1也進行了上下文能力的壓力測試。
2天時間全網閱讀量超過110萬
測試結果顯示:
在官方標稱的極限長度200K下,Claude 2.1確實有能力提取出標記性的語句。
位于文檔開頭的標記性內容,幾乎都能被完整的獲取到。
但和GPT-4 Turbo的情況類似,模型對文檔開頭內容的獲取效果不如對文檔底部內容的獲取內容。

從90K長度開始,模型對文檔底部標記性內容的獲取能力就開始下降了。
從圖中我們能看到,與GPT-4 128K測試結果相比,Claude 2.1 200K上下文長度,僅僅只是「在200K長度的文章中能讀取到信息」。
而GPT-4 128K的情況是「在128K長度后出現明顯下降」。

如果按照GPT-4 128K的質量標準,可能Claude 2.1大概只能宣稱90K的上下文長度。
按照測試大神Greg說法,的這些測試結果表明:
用戶在需要專門設計提示詞,或者進行多次測試來衡量上下文檢索的準確性。
應用開發者不能直接假設在這些上下文范圍內的信息都能被檢索到。
更少上下文長度的內容一般來說就代表著更高的檢索能力,如果對檢索質量要求比較高,就盡量減少喂給模型的上下文長度。
關鍵信息的位置很重要,開頭結尾的信息更容易被記住。
而他也進一步解釋了自己做這個對比測試的原因:
他不是為了黑Anthropic,他們的產品真的很棒,正在為所有人構建強大的AI工具。
他作為LLM從業人員,需要對模型的工作原理,優勢和局限性有更多的了解和理解。
這些測試肯定也有不周到的地方,但可以幫中使用模型的用戶更好的構建基于模型的服務,或者更加有效地使用模型能力。
而在做測試的過程中他還發現了一些細節:
模型能夠回憶出的標記事實量很重要,模型在執行多個事實檢索任務或綜合推理步驟時會降低回憶事實的體量。
更改提示詞,問題,以及要回憶的事實和背景上下文都會影響回憶的質量。
Anthropic團隊在測試過程中也提供了很多幫助和建議,但這次測試調用API還是花了作者本人1016美元(每100萬token的成本為8美元)。
自掏200刀,首測GPT-4 128K
在這個月初,OpenAI在開發者大會上發布GPT-4 Turbo時,也宣稱擴大了上下文能力到128K。
當時,Greg Kamradt直接自掏200刀測了一波(單次輸入128K token的成本為1.28美元)。
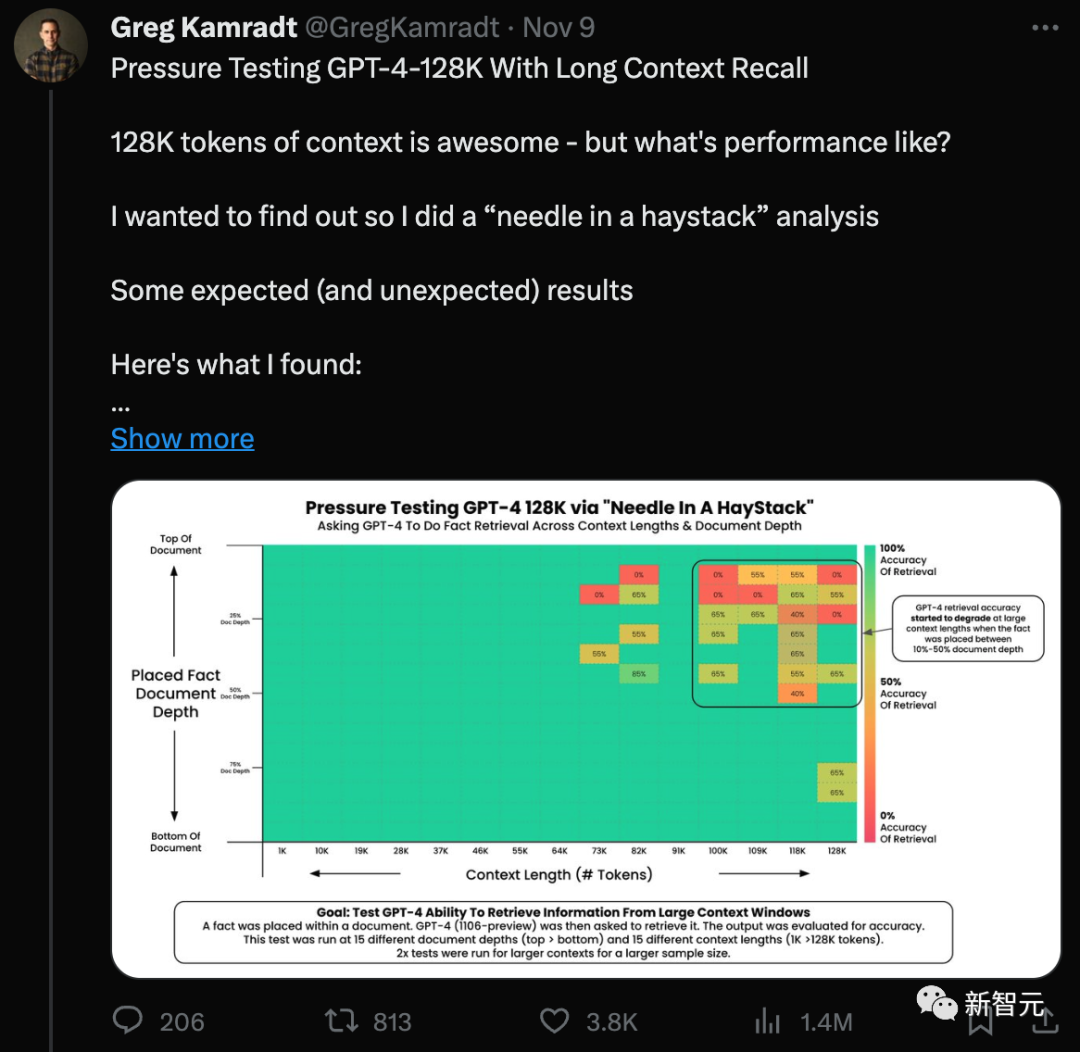
從趨勢來看,和這次Anthropic的結果差不多:
當上下文超過73K token時,GPT-4 的記憶性能開始下降。
如果需要回憶的事實位于文檔的7%到50%深度之間,回憶效果通常較差。
如果事實位于文檔開頭,無論上下文長度如何,通常都能被成功回憶出來。
而整個測試的詳細步驟包括:
利用Paul Graham的文章作為「背景」token。用了他的218篇文章,輕松達到200K token(重復使用了一些文章)。
在文檔的不同深度插入一個隨機陳述,稱述的事實是:「在舊金山最棒的活動是在陽光燦爛的日子里,在多洛雷斯公園享用三明治。」
讓GPT-4僅依靠提供的上下文來回答這個問題。
使用另一個模型(同樣是 GPT-4)和@LangChainAI 的評估方法來評價GPT-4的回答。
針對15種不同的文檔深度(從文檔頂部的0%到底部的 100%)和15種不同的上下文長度(從1K token到128K token),重復上述步驟。