研究沒思路的看過來,這是可信機器學習的1000個創新idea
I. 前言
1. 先講一個故事
大概在 4-5 年前的時候,我還是卡內基梅隆大學(CMU)的 phd。身處在名校光環的照耀下,再加上頂級導師的加持,我對于科研和創新一向有極高的標準。我們決定要花時間的東西,一定不能是簡單的東西。而且有很長一段時間,我一直以為大部分人都是這樣想的。
直到有一次,在開會的時候我看到一個女孩在展示一個 poster,內容大概就是把 LSTM 用在基因表達(gene expression)上的預測效果比上個時代的 SVM 之類的效果要好。這實在是沒有什么意外的,畢竟當時大家已經知道了,RNN 家族(就比如 LSTM)是序列數據(sequence data)上的絕對王者。我當時也沒客氣,直接就問了上去,
“就這么用一下有什么了不起的么?”
結果她的回答不卑不亢:
“沒什么了不起的。真正的創新是你們這些讀的了 CMU 的人該做的事,我做不到,我只想發個 paper,趕緊畢業,然后找個工作。”
這是我第一次感受到大家追求的參差,畢竟平時在學校里面,就算有人真的一直在灌水,他也不會承認的。
從此以后,我再也不想質疑別人的工作是不是在灌水了,畢竟大家的起點,經歷,現實的訴求,和人生的愿景等等都不一樣。
2. 簡單說說這篇文章的背景
畢業后來到伊利諾伊大學厄巴納-香檳分校(UIUC) 當了一年的 faculty,盡管我的 lab 很初級,但也盡量堅持做我們認為對得起人生追求的工作。在追趕學術會議 deadline 的同時,最近也放出了第一份我們認為出彩的工作【1】:
- Liu, Haoyang, Maheep Chaudhary, and Haohan Wang. "Towards Trustworthy and Aligned Machine Learning: A Data-centric Survey with Causality Perspectives." arXiv preprint arXiv:2307.16851 (2023).
我們整理了可信機器學習的各個領域,諸如 “魯棒性”,“對抗”,“可解釋性”,和 “公平性” 的數學思想。這篇文章的整理從幾年前的單模型時代跨越到現在的大模型時代,而且注意到,盡管機器學習的研究跨越了時代,這些數學思想甚至幾乎沒有改變。
整理這些東西一個最顯而易見的好處就是可以幫助大家更好的了解這個領域,盡管這些年接觸可信人工智能(trustworthy AI)的人很多,但是我認為真正懂這個東西的人少之又少。比如有很多人認為領域泛化(domain generalization)不過是在一套新的基準上刷刷性能。我們整理的這份工作希望能夠讓大家更全面的了解這些領域。
然而更重要的是,整理工作讓大家夠以更加高屋建瓴的視野看待可信機器習相關問題。在整理這個工作的時候,我就經常跟兩位同學說,等我們弄完了,你應該輕易就會有 1000 多個繼續發文章的 idea,他們也非常認同。
可是真正的問題從來不是有沒有這些 idea,或者所謂的 “創新點”。而是這些 idea 是不是值得花大家的時間。我不允許我自己的 phd 做這種簡單的 paper,這是一個慢慢貶低自己的過程。像 maheep 這樣的 intern,想弄就弄吧,畢竟他還得攢點經歷將來用來申請 phd。
那么我們整理出來的那么多個 idea 有什么用呢,不如索性把它們寫出來送給需要的老師同學們。
不過這些 idea 估計也就能幫助一下像和上文提到的女孩有一致追求的同學,發發文章,畢業找工作用。有真正學術追求的同學可能不適合,畢竟能夠真正有潛力創造一個時代的 idea 誰也沒有多少,這一類有潛力的 idea 我更希望看到我自己的 lab 來推進。
3. 再說說為什么認為可信很重要
在 2016-17 年 ResNet 100 層剛出來的時候我就說過,這么巨大的結構其實不能只用準確率來評價,因為沒有證據證明 SOTA 準確率其實來自于模型學到了真正有用的東西而不是數據集里面的混雜因素(confounding factors),畢竟對于如此巨大的模型,ImageNet 的體量就顯得小了,混雜因素存在的可能性就大多了。只不過那個時候太幼稚,我不知道這些理念其實是可以用來發 paper 的......
到最近無論是 Dall-E,ChatGPT,Stable Diffusion,還是 SAM 等等,我也一直跟我的學生說,不用看這個模型各個似乎神乎其技,其實很大程度是因為用戶還沒有習慣于使用這些模型,就像當年 100 層的 ResNet 一樣,剛出來的時候就有新聞說新的時代要來了,計算機視覺要被解決了,ResNet 確實帶來的一個新的時代,但與其說是解決的計算機視覺,更多的是讓我們看到了計算機視覺以前大家沒有太關注的問題,例如可信下的各個子問題。我認為這是因為 ResNet 的巨大成功讓我們看到了在日常生活中大規模依賴計算機視覺的可能性,進而當我們真的用它時,可信的各種問題就隨之而來了。
ChatGPT 等等也是一樣,遠遠領先了一個時代,但是等你適應了他的時代,用的久了,就會發現可信的問題就全都回來了。
II. 背景
1. 究竟什么是可信機器學習
可信機器學習一般認為是幾個子領域的一個統稱,究竟有哪些子領域似乎也沒有一個確切的范圍,但通常大家認為比較重要的子領域包括
- 魯棒性:比如領域自適應(domain adaptation)、領域泛化等等的領域,這些領域主題就是說機器學習在應用(testing)時面對的數據通常和訓練時的數據有一定的差異,如何保證這些差異不會對模型的性能造成影響。
- 對抗魯棒性(安全,security):最著名的大概就是熊貓的那張圖片,一般來講就是研究模型對于只有一點微小的擾動過的數據是否依然能夠保持原來的性能,這些微小的擾動并不是隨意添加的,需要精細的算法專門生成。
- 可解釋性:顧名思義,簡而言之就是模型的工作過程機理等等是否能夠解釋出來讓用戶明白。具體的定義更是五花八門。
- 公平性:一方面是說模型的工作過程中有一些過于敏感的信息(比如性別,年齡,家庭背景等等)不應該被使用。另一方面是說一些少數族裔會在統計的過程中被自然的過濾掉,而這是不應該的。
我們的工作大概就包含了上面四個子領域,其他的,比如隱私保護,也通常被考慮在可信及其學習的范疇內。
我認為一個很多人忽視的問題:可信機器學習,從它的定義源頭來講,它就不是一個單純的統計題目。可信機器學習,到底是誰來信,誰來認為是否可信。一個可解釋模型,給人看能看懂,給寵物看就看不懂了,算不算可解釋,那如果反過來,算不算可解釋呢?每個地區的教育水平不同,那時保持相同的一本錄取率算公平,還是全國一張卷算公平呢?這些問題本來就沒有確定的答案,機器學習研究本身其實也沒有必要回答。我們要做的其實就是當決策者定義出了一種 “可信”,我們能夠把相關的方法做出來。但是做到這一點的前提就是要承認,“可信”(以及 “魯棒”,“可解釋”,“公平”)等等都是主觀的。
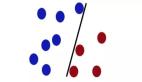
在我們的文章里,我們用下圖闡釋了為什么 “魯棒性” 是一個主觀的概念, “semantics”,“suprious”(或者“shortcut”等等)的定義也是一個主觀的概念。
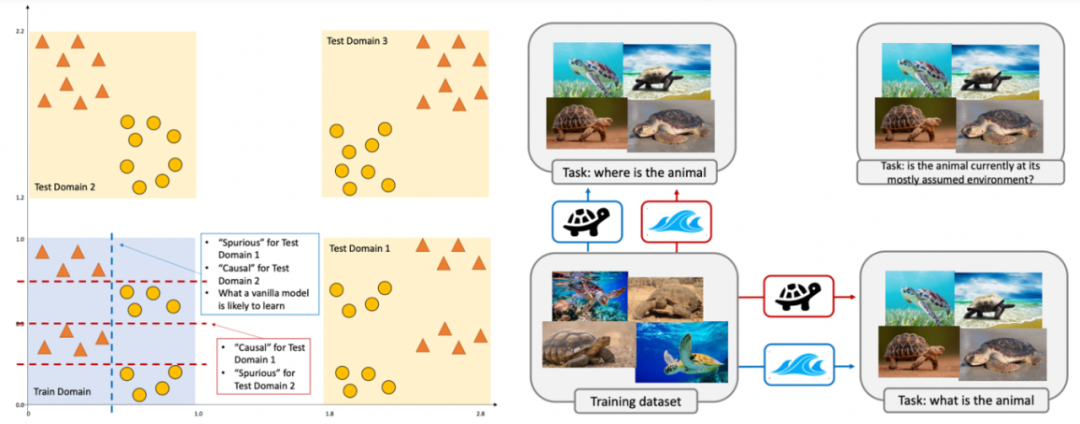
圖 1. 可信機器學習的數學是通用的,但是什么才是 “可信”,其實是很主觀的問題。比如我們要海龜和海洋通常有很強的相關性,那我們預測的究竟是動物還是環境就決定了哪個信號是 “semantics”,哪個是 “spurious”。
而這張圖也是從我之前的一篇文章【2】的中的更簡單的圖演變而來。
2.“可信” 的挑戰從何而來
訓練一個 “可信” 的機器學習模型并不是一件簡單的事情,這里可能有很多理由,我們認為其中最主要的是數據本身帶來的挑戰。同時我們也認為這是近年來 Data-centric AI(DCAI)變得越來越重要的一個原因。下面這張圖,是我多年來一直在嘗試闡述的,現代機器學習最核心的挑戰之一。

圖 2. 我認為現代機器學習最核心的挑戰之一,數據因為歷史原因充滿了各種 spurious correlation 或者偏見等等,這直接導致了深度學習這種依賴大量數據創造奇跡的方法在實際應用中到處都有可信的問題。
這張圖同樣演變于我以前的一篇 paper【3】。
3.“可信” 解決問題的框架(范式)
據我們觀察,大量的可信機器學習方法全部來源于 3 種主體框架(或者稱之為范式)。
3.1. 類似于 DANN(domain adversarial neural network)類的方法
大概是用來解決最簡單直接的辦法。領域自適應主要想解決的問題是一個機器學習模型的訓練數據集來自于一個領域(比如照片),而測試數據集來自于另一個領域(比如素描)。我們主觀的認為,一個優質的模型,如果在照片中能夠識別貓狗長頸鹿大象之類的動物,那么這個模型在素描中也應該能識別出這些動物(關于這個假設的數學模型,可以參考我們在 2022 UAI 的一個工作。【2】)
那么,怎么保證一個模型能夠實現領域自適應呢?
最直觀的方法大概是去訓練一個模型,保證這個模型不會學習到任何與領域本身相關的特征(即模型無法區分一張圖片是照片還是素描)。
那么如何保證一個模型無法區分一張圖片是照片還是素描呢?
我們先來回答一個特別簡單的問題:怎么保證一個模型能夠區分一張圖片是照片還是素描。答案很簡單,用數據對應的領域信息作為相應的標簽(label),訓練一個有效的領域分類器(domain classifier)。
有了這個領域分類器,在解釋下一步之前,先闡述這樣一個事實:對于任何一個(沒有循環(recurrent)結構的)深度學習模型,我們可以指定任意一層把它切開,把這層前面的稱之為編碼器,這層后面的稱之為解碼器,這層的信息我們就把它叫做表征。
現在把這個領域分類器當做解碼器。我們現在想辦法讓這個領域分類器無法識別領域,但是這個領域分類器已經訓練好了,我們不能改變它,那唯一的辦法就是我們用編碼器改變這個領域分類器的輸入,讓相對應的表征無法被領域分類器所識別。
然后別忘了,我們的最終目的是保證模型能夠區分貓狗長頸鹿大象之類的動物,所以還要同時有一個正常的分類器作為解碼器。
而把這些組合到一起,就是 domain adversarial neural network(DANN)【4】。
以上這些介紹盡管是基于魯棒性中的最簡單的領域自適應,但是同樣的方法可以應用在可信的諸多領域,比如幾乎一樣的方法可以用來解決公平的問題,把領域分類器從兩個領域拓展的多個領域就是好幾篇領域泛化的 paper。我們的 survey 里整理了很多很多工作,表面看起來萬千姿態,但是其實數學內核全都如出一轍,感興趣的老師同學們可以具體讀讀我們的 survey。
還有一個家族的方法也是基于 DANN 的體系,稍有不同的就是這個領域分類器不再是通過類似 domain ID 一樣的標簽訓練出來的 classifier,而是通過一些特別的架構得到的只能學習某一類的特征,比如我們做過的只學習紋理(texture)特征的,只學習 patch 的。更通用一點的用一個弱分類器(weak classifier)來扮演這個角色的。但是我個人認為這一系類的方法在他們自己的基準上還可以,但是在更廣泛的任務中通常不太行。更多的相關討論都在我們的 survey 中。
3.2. 最壞情況下(worst-case)的數據增強以及相關的正則化(regularization)
數據增強(data augmentation)大概是最簡單直觀的提高模型性能的方法之一了。在可信機器學習中,數據增強也發揮了巨大的作用。只不過更具有代表性的是 worst-case 的數據增強。相較于普通的數據增強(隨機的對數據進行一些變換),worst-case 的數據增強最大的特點就是這些變換不是隨機選擇的,而是選擇那個能夠讓損失(loss)變得最大的變換。
這一系列的方法效果最顯著的就是在對抗魯棒性(adversarial robustness)的研究中,最簡單而且有效的方法就是直接用 attack 對應的方法來生成數據,然后用這些數據來訓練,效果拔群【5】。
在通用的魯棒性研究中,如果是旋轉,翻轉之類的,或者 mix-up 家族的增強,把這種隨機增強換成 worst-case 的,收益通常非常小,而且由于是 worst-case 而不是隨機,計算復雜度要多很多(要么用梯度(gradient)來幫忙,要么每個增強一個 forward 來選擇),所以恐怕不值得。
另一種是用 GAN, VAE, 或者更新的 AIGC 系列模型來輔助生成數據。把 GAN 或者 VAE 的計算圖(computation graph)和要訓練的模型連到一起,通常可以很方便的實現 worst-case 的增強(可以直接使用模型的梯度信息),但是把這些模型加進主模型中本身就增加了相當的計算復雜度。
然后這里有一個很有意思的問題,如果我們用 GAN 或者 VAE 來生成數據,生成出來的數據和原來的數據差的太遠,標簽不一樣了怎么辦。所以這里必須要有人為定義的一個標準來保證生成的數據和原來的數據不會離的太遠。
其實所有的數據增強都有這個問題,比如用那些變換來增強數據,或者在對抗魯棒性里允許的差異是多大,而這些就是這一系列方法中 “主觀” 的成分。
然后在通用的魯棒性系列中,還有一種 worst-case 增強相對隱蔽一些,我們做的 RSC 相當于說把模型切成編碼器和解碼器,然后在中間的表征上做 worst-case 增強【6】。這個簡單的方法似乎效果很好,不僅在當時的領域泛化 leaderboard 輕松達到 SOTA,我后來在幾個生物數據上嘗試效果也都不錯。
既然我們增強的數據,現在每個數據至少有兩個 copy,那是不是會有一些正則化能夠把每組兩個數據的這種模式更好的利用起來。我認為沒有比下圖更能說明白這件事的了。

圖 3. 與數據增強可以無縫銜接的正則化。這張圖來自于我的另一個工作【7】。比如我們拿貓狗分類器來舉例子,我們要做一個模型來分類貓和狗,但是通常我們發現貓多數時候待在室內,而狗更喜歡待在室外,這樣訓練出來的模型顯然不夠好,因為可能只是在學室內室外而不是貓和狗的信息。我們要克服這個問題,最簡單的辦法就是用數據增強,畫一些室內的狗和室外的貓出來。可是僅僅這樣還是不夠,因為還有可能有在游泳的狗或者哪天貓上了太空怎么辦。于是,一個策略就是想辦法讓模型無視掉所有的背景。就想上面那張圖,我們輸入一對數據,然后讓模型找到這一對數據中的共性,無視掉所有類似于背景的東西。
大概意味著我們現在可以用一個正則化來要求模型把一組數據只學習其中一致的部分。
這種正則化和增強的組合也是浩如煙海,畢竟任意定義一個距離度量(distance metric)就可以創造一個方法。我們在去年的一個工作中【7】嘗試為這一類的工作做出了一個概述。我非常喜歡當時我做的 related work 部分,里面說雖然有一些方法現在還沒有,將來反正也會被發明出來,不如索性現在一起討論了。只不過我們討論完了之后發現,額,這些方法可能也沒有必要被發明出來了。
另外,我提出這一套 idea 的時候經常收到一個問題 “這和對比學習(contrastive learning)是不是很像呢?”“是吧,只是多了監督損失(supervision loss)”。“那不就是把對比學習搬過來了嗎?” “這么理解倒也行,不過這些工作遠遠早于對比學習。”
3.3. 樣本重加權方法
這一系列方法的家族較前兩個家族相對小巧一些,不過也已經非常多了。
方法直觀理解起來比較簡單,在很多魯棒性和公平性的任務中,有一些數據點因為本身在某些意義上屬于少數群體,模型很容易忽視這些數據,讓模型更加重視這些數據最直觀的方法就是為這些方法添加權重。那么怎么去找到這些樣本,怎么增加這些權重就是創新的空間。
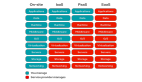
我們把這三個家族的方法整理在下圖中了。

圖 4. 我們的 survey 整理的可信機器學習的三大框架(范式),數百甚至數千篇文章都遵循這個基本的框架,無論是魯棒性、公平性、對抗性,甚至可解釋性。(a)基本的 ERM baseline。(b)向 DANN 范式的延伸。(c)向數據增強范式的延伸,其中 c.1 是增加了正則化之后的效果。(d)是向樣本重加權角度的延伸。

圖 5. 這三個范式(紅色)與 ERM baseline(橙色)和各個領域(藍色)在數學上的聯系。這篇文章恐怕只能簡單的概括一下各個方法,對于更深層次的數學聯系,還請閱讀我們的 survey。
我們也嘗試過把第二個和第三個家族的方法放到一起【8】,做出來的方法其實我個人非常喜歡,而且我曾經讓同學把這個方法在藥物測試的 OOD 數據集上嘗試了一下,瞬間性能就提升到了懷疑代碼有 bug 的程度。
我個人一直在追求統計視角下這三個范式的大一統理論,也有一點嘗試【2】,不過這篇文章也經常被詬病過于晦澀,我也在考慮為這篇文章寫一個 blog 解釋一下。
III. 回到標題 - 1000 個創新點
先回答幾個問題:
真的有 1000 個么?--- 我認為差不多,不過重要的從來都不是數字,而是原理。其實我認為如果誰真的可以像我自己這么熟悉我們的 survey 的話,1000 個實在是太過于謙虛了,不過我也確實不太可能有精力把整個 survey 在這里解釋一遍。
- 都能用來發頂會么?--- 不好說,但是每年頂會里肯定都能看見類似的文章發表,只不過不知道投的有多少。
- 你為什么不自己留著發 paper 呢?--- 這些 idea 不足以反映我對學術的追求,而且甚至更有追求的 idea 我現在都有點溢出了,根本用不完。
終于開始進入正文了,為了更好的介紹,先說清楚下文的介紹講分為如下四個板塊。
- 還是得先用最傳統的 ERM 結構介紹一些每一類可信機器學習方法的,從我跟學生的交流看來,這些方法似乎是最符合一個年輕同學對 “創新” 這兩個字的理解的。
- 然后追隨一波潮流,證明一下重要的從來都是方法的本質,而 ERM 結構或者大模型都只是這些方法本質具象化的媒介。所以同樣的范式在大模型下基本都適用。
- 然后更進一步的,這幾個方法可以互相借鑒,帶來更好的效果。
- 最后實在不行,做做應用。很多應用問題都天然的要求模型必須要至少魯棒,畢竟既然是應用,就得要模型真的有用。
4.1 從 ERM 的展開
4.1.1 從 ERM 展開 - DANN 及其延伸
前面也說過了,作為最經典的方法之一,DANN 已經被重復利用太多次了,比如最簡單,直接把 domain-invariant 對標到 sensitive-covariate-inviariant 就是新的方法,直接把兩個 domain 的 invariant 變成多個 domain 的 invariant(從 domain adaptation 到 domain generalization)又是一個方法,不過這兩個在我印象里已經被大同小異地發表過太多次了。
下面說說(我感覺)沒有被怎么發表過的。首先 DANN 最突出的特色就是那個用來做 domain invariant 的分類器。那既然有這么一個分類器,其實非常自然的人們就可以思考:是不是如果這個分類器變得更好,那么 DANN 本身及其架構下的方法都會變得更好。然后最簡單的想法就是把這個分類器(現行的一般就是個普通的 MLP)武裝起來,從基本的 dropout,到稍復雜點的歸一化(normalization)體系(batchnorm,layernorm 以及后來的各種變形),到更體系化的注意力(attention)家族,甚至還可以搞一套對抗訓練(adversarial training)讓這個小的分類器對小型擾動(perturbation)更加魯棒。各種技巧不勝枚舉。然而很有意思的是,這個角度如此的系統和規矩,卻似乎從未被人仔細的探索過。
相比較之下,大家似乎更加執著于一些更加具體,隨性的方法。盡管其本質也是讓這個小的分類器變得更好,但是更多的技巧都是 case-by-case 地設計出來的。比如我們 survey 里提到過的一些方法,這里不再贅述了。這種方法的設計需要一些對于問題本身的理解,更好的一些直覺,所以想體系化的一下產生 100 個 idea 可能還比較難。不過如果有人想批量試試,很簡單的思路就是去看看領域自適應或者領域泛化這些里的在更大規模的實驗中證明過自己的方法時候可以在 公平性相關的問題中有所作為。當然反過來也是一樣,只不過領域自適應和領域泛化發展的比較早,反過來能有效的幾率小了一點。
4.1.2. 從 ERM 展開 - 數據增強的延伸
數據增強整個家族的方法通常給人一種很簡單的感覺,在這上面的創新其實也不難。
在這里,我們就不說如何增強了,無論是旋轉,翻轉,還是在頻域搞點什么事情,稍加思考,總是能找到一些能用的數據增強的方法的。這里我們主要說說當我們有了數據增強之后,或者說當我們觀察到簡單的增強可以幫助我們之后,改怎么進一步提高性能。
直接轉為 worst-case 的方法。當我們知道了什么增強能夠幫助我們提高性能之后,最簡單直接的方法就是直接把原來的 IID 增強(對每一個樣本隨機抽樣一種增強的方法)直接改為 worst-case 的增強(對每一個樣本選擇那個讓訓練損失變得最高的增強方法)。這個方法最差也不過是和原來的那種增強效果相同,而且幾乎 100% 保證提高效率,即在更少的 epoch 數下提高性能。不過這么簡單的東西也有弊端,畢竟選擇那種增強可以稱之為 worst-case 需要更多的計算量,如果增強本身是梯度的一部分還好一些,如果不是,反復的前向傳播(forward pass)來計算損失不僅量大,而且顯得很臃腫。這些計算帶來的收益未必比得過更少的 epoch 帶來的收益。另外,這種方法也非常適配 dropout 之類的數據擾動(data perturbation)類的方法,我們曾經做過一個效果非常好的方法叫 RSC【6】。
數據增強 + 正則化。另一個幾乎 100% 帶來收益的方法是加一個正則化。尤其是在魯棒性相關的評估 上。幾乎任何一個距離度量都會帶來一個新的方法,我們在曾經的文章【7】里也說過(數據增強的方法 X 各種距離度量 X 應用)就會帶來近乎無限的收益。只不過有一點,根據我的經驗,這個收益往往來自于魯棒性相關的評估上,而不是 iid 上的準確率評估。另外,這個角度和上一個角度互相是兼容的,只要有一個增強似乎有可能有效,幾乎可以馬上升級成此類方法。
那如果找不到哪個數據增強的方法能來用怎么辦呢?一個最簡單直觀的方法就是直接在模型上綁個 GAN 一類的生成模型,然后用這個模型來一邊生成數據,一邊拿去給模型訓練。這一類的方法一個很天然的好處就是把 GAN 之類的模型綁上去的時候,梯度往往已經連接到了一起,這樣天然就可以把普通的數據增強升級成 worst-case 的版本的。當然,有任何一個增強,就可以直接升級成帶正則化版本的。最后,這一套方法還有一個好處就是可以隨著生成模型的升級無限升級,從 GAN 到 VAE 再到 diffusion,只要有更好的生成模型,這一套 idea 可以一直發展下去。
4.1.3 從 ERM 展開 - 樣本重加權的延伸
同數據增強一樣,這一套方法其實在機器學習的世界里早已是碩果累累。即使是現在,在基礎的機器學習課程中,加權最小二乘法(weighted least square)也經常作為線性回歸(linear regression)的自然延伸講授。只不過可能深度學習最開始出來的時候大家認為這種方法非常自然,即使這類方法可以提高準確率,大家似乎也沒有把它當做真正的方法拿來考慮的必要。后來深度學習的現實意義越來越多,大家意識到 under-represented 的問題比比皆是,然后再次意識到給樣本加個權重這種自然的方法有很大的意義。
最早期的方法就是損失越大,權重就越大,這樣這個模型就會更關注這個樣本。后來衍生出各種估計權重的方法。我猜測這一類方法的一個終極形態就是用另一個深度學習模型來估計權重。如果這一天真的出現了,大概也是為了提高性能無所不用其極的典型了。我認為一個方法如果走到了這一步,現實意義就很小了,所以只適合那些需要發發 paper 的同學。
4.2 大模型的時代
我們做這個 survey 的時候,最讓人激動的地方就是這里面很多系統性的思維,都可以直接銜接在大模型這個時代的方法中。為了做到這個銜接,我們首先把大模型時代的典型 prompt 結構翻譯成更常見的形態。
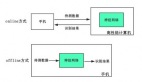
首先,在大模型時代之前,幾乎所有的模型都是在 ERM 的架構上建立出來的,也就是說,幾乎所有的模型都是下面這個公式的某種延伸,如我們在圖 5 中展示的那樣。

可是到了大模型時代,很多方法都不能是 ERM 的延伸了,畢竟重新訓練一個模型變得不現實了,于是有了各種利用已經訓練好的參數的方法誕生了。首先是最簡單的 微調(fine-tuning),然后又有了 prompt 和 adaptor。我們認為這些方法都可以同樣的寫到 ERM 體系下。
比如微調最簡單,其實就是把訓練好的模型看做一種初始化(initialization)。

由于公式中沒有注明初始化來自于何方,所有這兩者看起來是一樣的。
Adaptor 其實也好處理,就是插入一部分新的權重,然后只訓練這一部分權重。

我們這里主要關注的是自動生成的 prompt,而不是那種手動設計的,這樣的話,生成 prompt 的部分可以看做是一個模型,那整個模型合到一起就是一個編碼器-解碼器的結構。

這樣看下來,事情就變得很簡單了,在大模型的世界里,想要追求可信的性質,無非就是把曾經的 ERM 里好用的方法再拿來試一下。尤其是那些經典的方法,如果有必要的話,必將占據一席之地。
在我們整理這個 survey 的時候,我們發現了很多的例子,更多的內容可以見我們的 survey,下面這兩個是我經常放在相關的 presentation 里的例子,大家可以感受一下,這兩個方法放到我們的范式之中之后是多么的規矩。
例子 1 來自于這篇 paper《Adversarial soft prompt tuning for cross-domain sentiment analysis》, 我認為這圖,尤其是領域對抗訓練足以說明問題了。

圖 6. 左圖來自于《Adversarial soft prompt tuning for cross-domain sentiment analysis》,相當于是來在 DANN 范式在大模型下的應用。
例子 2 來自于這篇 paper《Auto-debias: Debiasing masked language models with automated biased prompts》,其實主要也可以從圖上看出來方法的核心在于去找到有偏見的 prompt,進而用某種一致性損失去除他們。

圖 7. 左圖來自于《Auto-debias: Debiasing masked language models with automated biased prompts》,相當于是數據增強和正則化范式在大模型下的應用。
當然,這兩個例子并不是在貶低這兩篇 paper,每篇 paper 都有自己的獨到之處,需要仔細讀才看的出來。這里只是借用這兩篇宏觀的方法來證實一下這種可信機器學習范式的力量。
4.3 方法的混搭
再從另一個角度出發,其實一個特別有效的思路就是這些方法的混搭。
比如我們這里介紹了三種最核心的范式,然后每個范式下面都有數十種方法。一個很簡單的思路就是,不同范式下的不同的方法能否組合在一起呢?
我們在自己提出理論核心的 paper 里【2】做過一點簡單的嘗試,比如把最簡單的 “領域分類器” 和最簡單的 “數據增強” 放到一起,提出了一個方法,也提高了一點性能。不過由于這個 paper 的重點是理論的部分,這個方法我們沒有太細致的打磨,可能潛力比較小。不過這些也應該證實了一點:兩個范式下各自最簡單的方法一組合變有效果,那么兩個范式下各自更復雜的方法的組合豈不是一定好使?
在另一個我非常喜歡的工作中,我們嘗試了把兩鐘 worst-case 的概念結合起來,一種在特征的維度上去 drop 預測性最強的特征,這其實也就是相當于一種數據增強,另一種是在樣本的維度上,其實就是重加權的范式下面。這個結合帶來了兩個維度下的 worst-case,因此被我命名為 W2D。我認為這個方法及其的自然,精巧,非常好理解,而且效果拔群(具體的可以見下文)。然后這個角度很自然的思路就是,我們其實依然只是用了兩個范式里比較簡單的方法,重加權的范式里就是最簡單的損失轉換為權重,增強里面的稍微復雜一點,因為我們直接基于了自己的 RSC 的工作來做的增強。不過這里面的空間依然很大,其實我當時做這個 paper 的一個遺憾就是沒有直接用當時效果最好的重加權的方法,這個效果最好的方法也是一個非常小巧和優雅的方法,很契合我們做事的理念。
當然,沿著這兩個思路下來,很自然的角度就是各個范式下各種方法的結合,這里就不必贅述了。
4.4 最后,還有新鮮的應用
如果開發新的方法對于某些同學來講讓人頭大,那就沒必要使勁琢磨了,在新的應用上對這些方法做一些小規模的創新一樣能吃飽飯。
這也是另一個我特別喜歡 W2D 方法的理由。經常對那些不太想真正在技術前沿拼殺的同學,我通常建議他們在某些數據集上嘗試一下 W2D 方法,通常一次嘗試就直接提高 SOTA。目前我們嘗試的幾個跟 drug 相關的數據集都是這種效果。我認為這個跟兩個原因有關。一個是說 W2D 本身的力量幾乎全部來自于純粹的統計,而不是主觀的正則化,這大大提高了這個方法的適配度。另一個愿意就是 W2D 對于模型沒有任何要求,幾乎只要是交叉熵損失(cross-entropy loss)就能用,所以可以直接 plug-in 到幾乎任何 SOTA 模型上然后送它們再進一步。
但是我們也在細胞圖像分割(cellular image segmentation)上嘗試過,結果似乎很掙扎,可能是因為 W2D 畢竟還是比較適合傳統一點的交叉熵損失,分割的損失函數不太適配。
另一個我認為特別簡單的性能助推器是我們的 AlignReg,一般有高中生找我合作我就會讓他們把玩一下這個,幾乎也是注定提高性能。然后他們就來跟我說,“原來機器學習這么簡單”,那是因為你不知道我當時花了多久才把事情簡化到這種程度。
當然,以上只是兩個例子,方法五花八門,應用更是千姿百態,隨便組合也許就是新的機會。但是其實方法和問題適配非常的重要,隨便拼湊著試恐怕不行。比如上面兩個例子,W2D 的那些應用上的成績都是因為數據本身也是一個跨領域的問題,無論是領域自適應還是領域泛化,還是什么新的 setting。AlignReg 那個例子也是,方法雖然簡單,但是確定方法和問題是一致的一般不是那些高中生能自己做到的。
IV. 最后一部分
寫到這里,我希望我兌現了這 1000 個創新點的承諾,如果你一路讀下來,每句話都有道理,你恐怕會感受到其實遠遠不止 1000 個。如果你沒有這種感覺,也建議去看看我們完整的 survey,那里的內容要豐富的多。
順便也借此回答一下有些朋友可能有的問題:“你這樣把 idea 寫出來你自己的 paper 不就少了嗎?” 按我現在的淺見,重要的從來不是 paper 數量,而是這些 paper 后面承載的內力,沒有這種修養,paper 再多不過是些花拳繡腿,一碰就散架。不過我現在還太年輕,這些理解未來也許會隨著年齡的增長而改變。
最后的最后,既然寫了這么長,順便介紹一下自己。
我現在在伊利諾伊大學厄巴納-香檳分校(UIUC)的信息科學學院當助理教授,主要研究可信機器學習(trustworthy machine learning)和計算生物學(computational biology)。目前將 lab 命名為 DREAM (Developing Reliable and Efficient Algorithms for Medicine)。我的 lab 剛剛建立一年多,非常需要各種志同道合的小伙伴,歡迎大家來和我一起玩,無論是正式的申請,還是作為 intern 或 visiting scholar。今年的 phd 申請,我要盡量在自己的 intern 中錄取。我個人非常非常非常喜歡和優秀的人一起玩,因為我認為這是一個互相進步的過程。而且這種優秀其實不局限于簡歷上的優秀,更多是修養和追求上的優秀。