













端到端自動駕駛系統的關鍵技術與發展趨勢
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
隨著以ChatGPT為代表的生成式人工智能的發展,端到端自動駕駛系統得到了廣泛關注,有望為通用場景的駕駛智能帶來革命性突破。以全部模塊神經網絡化為特征的端到端系統對專家規則的依賴度低,功能的集約性與實時性強,具備智能涌現能力和跨場景應用潛力,是實現數據驅動自進化駕駛能力的重要途徑。
近期,來自于清華大學的李升波等學者的論文,討論了端到端汽車自動駕駛系統的關鍵技術與發展趨勢。論文介紹了生成式人工智能的技術現狀,總結了端到端自動駕駛的關鍵技術,歸納了該類自動駕駛系統的發展現狀,并總結了生成式人工智能與自動駕駛融合發展的技術挑戰。目前,該論文已在《人工智能》期刊2023年第5期出版,原稿約14000字。此文為縮減版,約2800字,感興趣的讀者可下載原文閱讀。

論文地址:
https://aiview.cbpt.cnki.net/WKD/WebPublication/paperDigest.aspx?paperID=60ba64c1-3dee-4986-bed9-f86b98006872
下載鏈接:
https://kns.cnki.net/kcms/detail/detail.aspx?filename=DKJS202305001&dbname=cjfdtotal&dbcode=CJFD&v=MjMyODFTYkJmYkc0SE5MTXFvOUZaWVI2RGc4L3poWVU3enNPVDNpUXJSY3pGckNVUjdtZVplWnJGeXJsVjd2Skk=
1 生成式人工智能的技術現狀
數據、算力和算法是大模型發展的支柱,其中算法是大模型的核心技術體現。現有大模型多以Transformer結構為基礎,采用“預訓練(Pre-training)+微調(Fine-tune)”技術進行參數學習,使之適配不同領域的具體任務,經剪枝壓縮后完成最終部署。本節將圍繞網絡架構、預訓練、微調和剪枝壓縮四個方面對大模型關鍵技術進行介紹。
1.1 神經網絡的架構設計
大模型的出現得益于深度學習浪潮中深度神經網絡的發展。深層網絡的學習建模能力更強,有利于模型的性能提升。
在2017年,Google提出了神經網絡結構Transformer(圖1),大幅提升了網絡表達能力,在CV、NLP等多個領域大放異彩,Transformer現已成為大模型的基礎網絡結構之一。Transformer是以注意力機制為核心的編解碼器結構,其主要結構為注意力、位置編碼、殘差連接、層歸一化模塊。Transformer被廣泛應用于NLP、CV、RL等領域的大模型中。
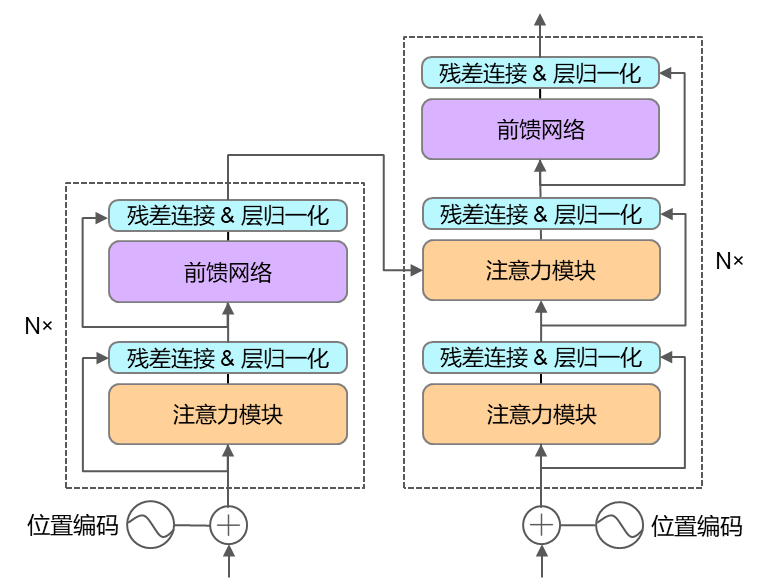
圖1 Transformer網絡結構
1.2 預訓練與微調技術
預訓練是使大模型獲得通用知識并加速模型在微調階段收斂的關鍵步驟。根據序列建模的方式,語言模型可以分為自回歸語言模型和自編碼語言模型(圖2)。自回歸語言模型使用Transformer的解碼器結構,根據前文預測下一個詞,從而對序列的聯合概率進行單向建模。自編碼語言模型則利用Transformer的編碼器結構,通過預測序列中的某個詞來雙向建模序列的聯合概率。
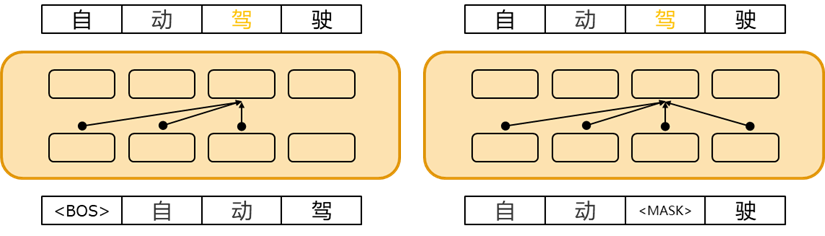
圖2兩類語言模型示意圖
微調是指將預訓練好的大模型在下游任務中進行調整,使之與具體任務更加適配。微調后的大模型與預訓練大模型相比,在下游任務中性能通常大幅提升。隨著模型規模不斷增大,微調所有參數變得十分困難,因此近年來出現了多種高效微調方法,包括Vanilla Finetune、Prompt Tuning以及Reinforcement Learning from Human Feedback(RLHF)等方法(圖3)。
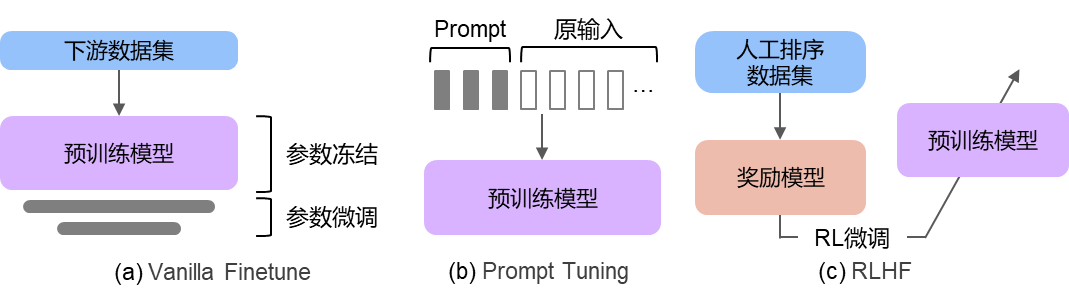
圖3 三種微調方法示意圖
1.3 模型的剪枝與壓縮
訓練好的大模型需要部署在算力和內存受限的系統上,因此需要對大模型進行剪枝和壓縮,減小模型中的冗余結構和信息,使其能在受限的計算資源上進行快速推理,同時盡量減小對模型精度的影響。大模型的壓縮方法主要包括模型剪枝、知識蒸餾和量化。
2 端到端自動駕駛的關鍵技術
人工智能技術與自動駕駛技術的融合,關鍵在于打通以車云協同為核心的邊緣場景數據采集和自動駕駛模型訓練的在線循環迭代路徑。圖4展示了車云協同的自動駕駛大模型開發方案:由一定規模具有網聯功能的車輛進行眾包數據采集,數據清洗和篩選之后上傳至云控計算平臺;利用云控平臺的充足算力,生成海量仿真駕駛數據;融合虛實數據進行場景構建,利用自監督學習、強化學習、對抗學習等方法對自動駕駛大模型進行在線迭代優化;所學大模型經剪枝壓縮后得到車規級實時模型,并通過OTA方式下載到車載芯片,完成車端駕駛策略的自進化學習。
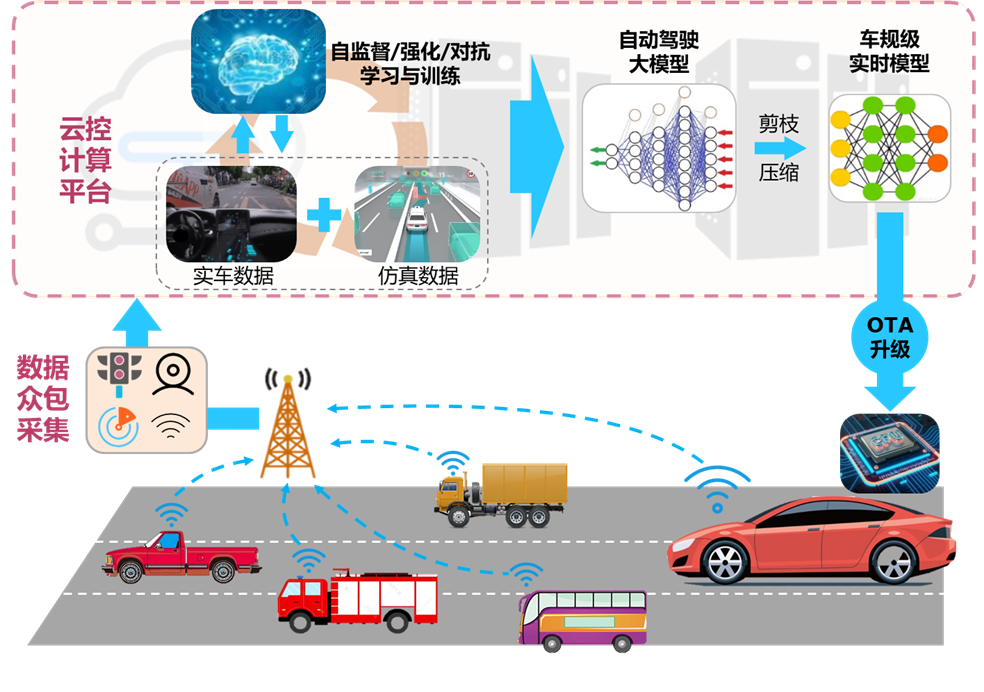
圖4 車云協同的自動駕駛大模型開發方案
具體研究內容包括:(1)面向自動駕駛的大模型基礎理論;(2)自動駕駛感知認知通用基礎大模型;(3)自動駕駛決策控制通用基礎大模型;(4)自動駕駛大數據采集生成與自動標注;(5)車云協同的基礎大模型持續進化;(6)自主可控的車用集成部署工具鏈與平臺。
3 端到端自動駕駛的技術發展趨勢
隨著大模型技術的不斷發展,以ChatGPT為代表的大模型技術展現出令人驚嘆的效果。大模型已在多項工業實踐中得到初步應用中,有望成為實體經濟新的增長引擎。
3.1 感知大模型
自動駕駛的感知模塊利用傳感器采集的數據,實時動態地生成駕駛環境的感知結果。感知大模型是提升車輛自動駕駛能力的核心驅動力之一,這些模型能識別和理解道路、交通標志、行人、車輛等信息,為自動駕駛車輛提供環境感知,繼而用于車輛自主決策。
目前在自動駕駛感知方面已有相關應用,例如百度文心UFO 2.0視覺大模型、華為盤古CV以及商湯的INTERN大模型等。
鳥瞰圖感知(Bird's Eye View,BEV)是當前主流感知方案之一,它將攝像頭、雷達等多源傳感器的感知信息轉換至鳥瞰視角,并行地完成目標檢測、圖像分割、跟蹤和預測等多項感知任務,如圖5所示。典型工作如特斯拉的BEV感知,百度的UniBEV和商湯的FastBEV。
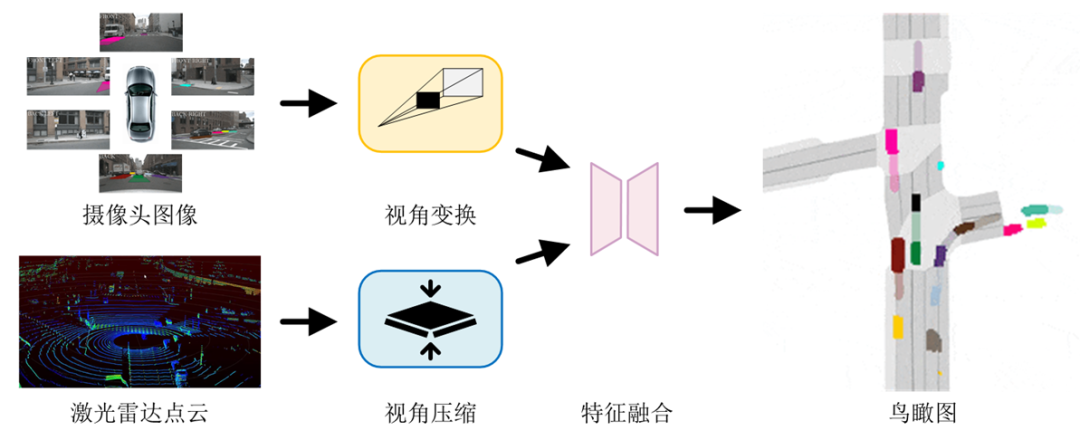
圖5 鳥瞰圖感知流程
3.2 預測大模型
預測是自動駕駛的關鍵組成部分,它主要涉及對周邊交通參與者未來運動狀態的預測,也稱為軌跡預測。軌跡預測綜合考慮道路結構、歷史軌跡以及與其他交通參與者的交互關系等信息,輸出一條或多條未來可能行駛的軌跡,供下游決策控制任務參考。數據驅動型的軌跡預測方法通常采用編碼-解碼架構,包括信息表示、場景編碼和多模態解碼等主要環節。代表工作包括谷歌Wayformer、清華SEPT和毫末智行DriveGPT等。
3.3 決控大模型
自主決策與運動控制是自動駕駛的核心功能,決策與控制水平的高低決定了自動駕駛汽車的智能程度。自動駕駛決控系統的技術方案主要經過了三個發展階段:專家規則型、模仿學習型以及類腦學習型。自動駕駛決策控制大模型的目標是構建以深度學習與強化學習為代表、數據驅動與知識引導相結合的決策控制通用基礎模型訓練算法,為自動駕駛智能性突破提供解決方案。
目前工業界尚缺乏用于自動駕駛的決策與控制一體化大模型。由清華大學提出的集成式架構(IDC)將決策與控制整合為統一的約束型最優控制問題,利用數據驅動算法求解評價模型與策略模型,它以環境感知結果為輸入,直接輸出油門、制動、轉向等控制指令。IDC 具有在線計算效率高、可解釋性強、無需人工標注數據、可自回歸地預測下一個動作等優點,為大模型應用于自動駕駛決控奠定了基礎。圖6為傳統專家分層式和集成式決控架構示意圖。

圖6 兩種決控架構示意圖
3.4 端到端訓練的自動駕駛模型
端到端的自動駕駛方案將輸入的原始傳感器數據直接映射輸出為軌跡點或低級控制命令,與分層式架構相比,其具有簡潔的方案結構與巨大的性能潛力。端到端方案的工業應用面臨著數據短缺、學習效率低下和魯棒性差等問題,尤其無法保障任何極端情況下模型輸出的安全性,這將成為其應用于自動駕駛領域的最大挑戰。代表工作有上海人工智能實驗室的UniAD和特斯拉FSD Beta V12。
隨著算力發展與大模型技術的興起,端到端的自動駕駛將為行業帶來新的突破。針對端到端方案,不斷降低其技術門檻、進行可解釋性研究、以及提出更多保障端到端自動駕駛安全的算法,將是未來熱門的研究方向。
4 總結
以大模型為代表的生成式人工智能是智能網聯汽車發展的戰略前瞻方向。這需要進一步突破:適用于駕駛大數據的大模型預訓練方法和學習理論;泛場景、泛對象、跨模態適用的感知認知和決策控制通用基礎模型;仿真環境數據與真實場景數據結合的大規模數據采集與標注系統;車云協同的基礎大模型持續進化技術與車用集成部署工具鏈與平臺等。以上技術的攻關將打通以車云協同為核心的駕駛大數據和自動駕駛大模型算法在線循環迭代路徑,推動端到端自動駕駛技術在全場景的落地應用。

原文鏈接:https://mp.weixin.qq.com/s/ka0k31i5ZuXcx_C6damNLw




























