













像調雞尾酒一樣調制多技能大模型,智源等機構發布LM-Cocktail模型治理策略
隨著大模型技術的發展與落地,「模型治理」已經成為了目前受到重點關注的命題。只不過,在實踐中,研究者往往感受到多重挑戰。
一方面,為了高其在目標任務的性能表現,研究者會收集和構建目標任務數據集并對大語言模型(LLM)進行微調,但這種方式通常會導致除目標任務以外的一般任務的性能明顯下降,損害 LLM 原本具備的通用能力。
另一方面,開源社區的模型逐漸增多,大模型開發者也可能在多次訓練中累計了越來越多的模型,每個模型都具有各自的優勢,如何選擇合適的模型執行任務或進一步微調反而成為一個問題。
近日,智源研究院信息檢索與知識計算組發布 LM-Cocktail 模型治理策略,旨在為大模型開發者提供一個低成本持續提升模型性能的方式:通過少量樣例計算融合權重,借助模型融合技術融合微調模型和原模型的優勢,實現「模型資源」的高效利用。

- 技術報告:https://arxiv.org/abs/2311.13534
- 代碼:https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail
模型融合技術可以通過融合多個模型提高單模型的性能。受此啟發,LM-Cocktail 策略進一步通過對目標任務計算不同模型的重要性,賦予不同模型不同的權重,在此基礎上進行模型融合,在提升目標任務上性能的同時,保持在通用任務上的強大能力。
LM-Cocktail 策略可以幫助匯總各模型的優勢能力,就像制作雞尾酒那樣,通過加入不同的模型進行調制,得到一個具備多種特長的「多才」模型。
方法創新
具體而言,LM-Cocktail 可以通過手動選擇模型配比,或者輸入少量樣例自動計算加權權重,來融合現有模型生成一個新模型,該過程不需要對模型進行重新訓練并且具備適配多種結構的模型,如大語言模型 Llama,語義向量模型 BGE 等。
此外,如果開發者缺乏某些目標任務的標簽數據,或者缺少計算資源進行模型微調,那么采用 LM-Cocktail 策略可以省去模型微調步驟,通過構造非常少量的數據樣例,融合開源社區中已有的大語言模型來調制自己的「LM 雞尾酒」。
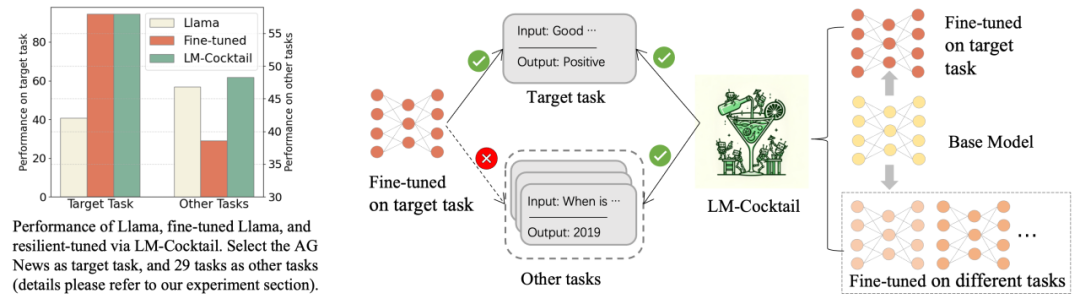
如上圖所示,在特定目標任務上微調 Llama,可以顯著提高目標任務上的準確度,但損害了在其他任務上的通用能力。采用 LM-Cocktail 可以解決這個問題。
LM-Cocktail 的核心是將微調后的模型與多個其他模型的參數進行融合,整合多個模型的優點,在提高目標任務上準確度的同時,保持在其他任務上的通用能力。具體形式為,給定目標任務、基礎模型,以及一個在該任務上微調基礎模型后得到的模型,同時收集開源社區或以往訓練過的模型組成集合。通過目標任務上少量的樣例計算每個模型的融合加權權重,對這些模型的參數進行加權求和,得到新的模型(具體的過程請參考論文或開源代碼)。如果開源社區不存在其他模型,也可以直接融合基礎模型和微調模型,在不降低通用能力的基礎上提升下游任務表現。
用戶在實際應用場景中,由于數據和資源的限制,可能無法進行下游任務的微調,即沒有在目標任務微調過后的模型。這種情況下,用戶可以通過構造非常少量的數據樣例融合社區中已有的大語言模型,生成一個面向新任務的模型,提高目標任務的準確度,而無需對模型進行訓練。
實驗結果
1. 彈性微調保持通用能力

從上圖中可以看到,在某個目標任務上進行微調之后,微調后的模型大幅提高了在該任務上的準確度,但其他通用任務上的準確度都有所下降。例如,在 AG News 到訓練集上進行微調,Llama 在 AG News 測試集上準確度從 40.80% 漲到 94.42%,但在其他任務上準確度從 46.80% 下降到了 38.58%。
然而,通過簡單的融合微調后模型和原模型的參數,在目標任務上實現了具有競爭力的性能 94.46%,與微調模型相當,同時在其他任務上準確度為 47.73%, 甚至稍強于原模型的性能。在某些任務下,如 Helleswag, 融合后的模型甚至可以在該微調任務上超過微調后的模型,并在其他任務上超過原通用模型,即在繼承微調模型和原模型的優點的同時,超過了他們。可以看出,通過 LM-Cocktail 計算融合比例,進一步融合其他微調模型,可以在保證目標任務準確度的同時,進一步提升在其他任務上的通用性能。
2. 混合已有模型處理新任務

圖:語言模型目標任務 MMLU

圖:向量模型目標任務 Rerival(信息檢索)
微調模型需要大量的數據,同時需要大量的計算資源,尤其是微調大語言模型,這些在實際情況中不一定可以實現。在無法對目標任務進行微調的情況下,LM- Cocktail 可以通過混合已有的模型(來自開源社區或者自己歷史訓練積累)來實現新的能力。
通過只給定 5 條樣例數據,LM-Cocktail 自動計算融合加權權重,從已有的模型進行篩選然后融合得到新的模型,而無需使用大量數據進行訓練。實驗發現,生成的新模型可以在新的任務上得到更高的準確度。例如,對于 Llama,通過 LM- Cocktail 融合現有 10 個模型(其訓練任務都與 MMLU 榜單無關),可以取得明顯的提升,并且要高于使用 5 條樣例數據進行上下文學習的 Llama 模型。
歡迎大家體驗 LM-Cocktail,并通過 GitHub issue 反饋建議:https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail























