首個「創造式任務」基準來了!北大清華聯手發布Creative Agents:專為想象力而生!
近年來,許多研究通過訓練服從自然語言指令的智能體,讓智能體具有了解決各種開放式任務的能力。
例如,SayCan[1]利用語言模型實現了根據語言描述解決各種室內機器人任務的智能體,Steve-1[2]訓練端到端的策略實現了能夠在《我的世界》(Minecraft)中做出各種行為的智能體。
然而,在這些研究中提供給智能體的語言指令往往清晰明確地描述了任務,沒有考慮讓智能體發揮創造性、解決高自由度的任務。
例如,在Minecraft中,一些現有的智能體能夠做「造鉆石鎬」、「用2個雪塊和1個南瓜堆雪人」等流程明確的任務;但如果要求智能體「用沙子造一座城堡」,目前基于自然語言指令的智能體難以將這句話轉化成一系列明確的建造城堡的動作。
這是因為,這句語言指令對任務的描述是抽象的,要求智能體能夠自發地生成出復雜多樣的城堡外觀細節、并且推理出造城堡的過程。
而人類玩家得益于想象力和對復雜任務的規劃能力,可以先想象出城堡最終的外觀和結構,再以此規劃出造城堡的順序,從而創造性地完成這類任務。
目前的工作缺少對這類創造式任務的研究,這也是當前AI Agents研究面臨的一個重要挑戰。
北京大學和清華大學等機構組成的團隊提出了一類解決創造式任務的智能體——Creative Agents,并推出了首個創造式任務的測試基準。

論文鏈接:https://arxiv.org/pdf/2312.02519.pdf
代碼鏈接:https://github.com/PKU-RL/Creative-Agents
項目主頁:https://sites.google.com/view/creative-agents
作者認為完成創造式任務的關鍵是賦予智能體想象力,提出將智能體分為想象模塊和控制器兩部分:想象模塊基于任務的語言描述,以文本或圖像的形式生成任務的細節,為任務執行提供具體的目標;控制器基于前者生成的任務想象,規劃執行的動作序列。
作者分別提出了想象模塊和控制器的兩種實現方式,實現了Creative Agents的多個變種。在Minecraft游戲中,作者用20個困難的建造任務建立創造式任務的測試基準,并提出了基于多模態模型GPT-4V的自動化評價指標。
實驗結果表明,Creative Agents是首個能夠創造復雜多樣建筑的AI Agents。團隊開源了任務集、評價指標、多個訓練數據集以及Creative Agents的模型和代碼,為具有創造性的AI Agents研究提供了一套基準。

Creative Agents完成《我的世界》中的創造式任務:“build a white pyramid-like house with windows, which is built of snow,” “build a sandstone palace with intricate details and towering minarets,” “build a wooden house made of oak planks and glass,” and “build a modern house with quartz blocks and glass.”
Minecraft建造任務和Creative Agents
傳統的強化學習任務要求智能體在與環境的交互中最大化獎勵。與之不同,開放式任務不通過人工定義的獎勵函數來提供任務目標,而是由自然語言的指令提供任務描述。
開放式任務要求智能體能夠服從任意的語言指令l,在環境M中做出與指令一致的行為。智能體的策略P(a|s, l)接收語言指令,根據環境的狀態s做出動作a。
由于語言是抽象的,經常不能充分地描述任務細節,此時開放式智能體需要具有創造性來完成任務中不能被語言指令明確的部分。
作者將這類語言指令不足以充分描述任務細節的開放式任務稱為創造式任務,其中一條簡單的語言指令(如「造一座房子」)可以指代復雜、多樣、新穎的任務目標(房子的具體樣子)。創造式任務的語言指令為智能體的行為帶來很大不確定性,要求智能體能夠想象沒有被詳盡描述的任務細節,并規劃動作來實現細節。
作者用開放世界Minecraft中造建筑的任務構建了一套創造式任務的測試基準。其中包含20條多樣的語言指令,要求智能體在生存模式的游戲中用給定的材料建造符合語言描述的建筑(例子如下所示)。

為解決創造式任務帶來的挑戰,作者提出的Creative Agents框架,將智能體分解為想象模塊和控制器:

其中g是對任務目標細節的想象,可以具有語言、圖像等不同的模態。想象模塊I從語言指令創造出細節豐富的任務目標,為控制器π提供更多任務信息、緩解任務的不確定性。同時,這種分解利于獨立研究兩部分模塊、將它們任意組合在一起得到不同的智能體。
想象模塊和控制器的實現
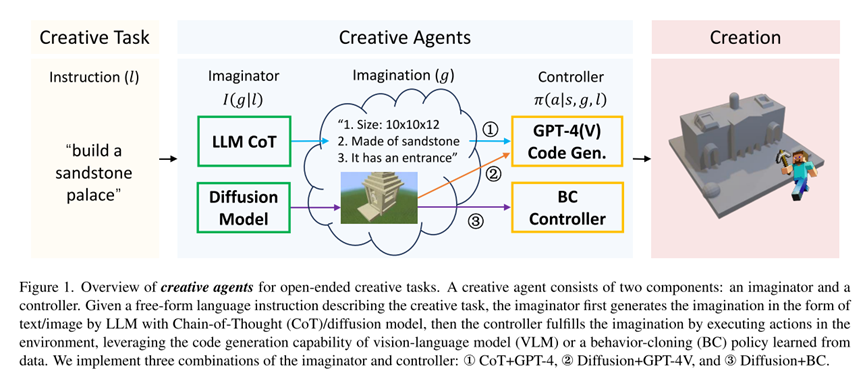
用語言模型實現文本空間的想象(LLM CoT)
這種方法利用大語言模型GPT-4的文本推理能力,以文本形式生成對任務細節的想象。作者利用思維鏈推理(Chain-of-Thought),在提示詞中設計與任務細節相關的五個問題(如下所示),要求GPT-4想象建筑不同方面的特征。

用擴散模型(Diffusion Model)實現圖像空間的想象
在圖像生成領域,擴散模型能夠基于文本生成高質量、多樣的圖像,可以作為想象模塊生成目標建筑的視覺形態,比文本形式的想象具有更豐富的細節。作者收集整理了14K帶有語言描述的Minecraft建筑圖像數據集,微調Stable Diffusion[3]模型,實現了從語言指令生成真實的Minecraft建筑圖像。
基于模仿學習的控制器(BC Controller)
對專家行為的數據集做模仿學習是訓練控制器的常用做法。作者在Minecraft建造任務上實現了一種分為兩步的模仿學習控制器:首先收集了1M成對的建筑圖像和建筑的3D體素數據集,通過訓練Pix2Vox++模型,將想象模塊生成的圖像轉換為建筑的藍圖(即3D體素);然后,作者收集了6M個在游戲中建造目標建筑體素的專家動作,用模仿學習得到了根據目標體素規劃動作序列的控制器策略。
基于大模型生成代碼的控制器(GPT-4(V) Code Gen.)
這個方法利用大模型GPT-4(V) 任務推理和寫代碼的能力,將底層控制轉化為生成代碼的問題。使用Mineflayer提供的對Minecraft中基本動作的封裝,作者將文本/圖像形式的想象輸入給GPT-4(V),要求生成代碼調用Mineflayer的接口、在游戲中創造相應建筑。
結合不同的想象模塊和控制器,作者實現了Creative Agents的三個變體:CoT+GPT-4, Diffusion+GPT-4V, Diffusion+BC。此外,引入了一個不使用想象模塊、直接根據語言指令生成建造代碼的基線方法Vanilla GPT-4。
基于GPT-4V的評價指標
由于缺少獎勵函數和任務成功的反饋,如何設置開放式任務的評價指標是待解決的問題。許多現有的工作通過問卷調研比較不同方法,比較費時費力、且容易受被試者主觀偏好的影響。
作者提出用大模型GPT-4V實現自動的創造式任務評價,解決人類評價帶來的問題。在Minecraft建造任務中,作者考慮從五個方面對智能體的表現進行評價:
1. 正確性:建筑是否與語言指令一致;
2. 復雜性:創造的建筑是否體積大、有復雜結構;
3. 質量:創造的建筑是否符合美學;
4. 功能性:創造的建筑是否具有必要的功能結構(如門窗、走廊等);
5. 魯棒性:智能體在不同的任務上表現的穩定性。
基于GPT-4V的評價指標將任務的語言指令和智能體建造房屋的截圖作為提示詞,詢問對各個方面表現的評價。
作者提出了兩種不同的評價方式(如下所示):
1. 一對一比較的評價(左):將兩種方法在同一個任務上創造建筑的圖像并列,要求GPT-4V給出哪個更好。在對不同方法兩兩之間進行了多輪比較之后,使用Elo評分系統[4]對每個方法產生一個評分;
2. 直接打分的評價(右):給定一個方法造出建筑的一張圖像,要求GPT-4V對各個方面進行0~10分的打分。

作者在實驗中以同樣的提示詞制作問卷,收集了49名人類評審的評價結果,通過對比驗證GPT-4V評價指標與人類評價的一致性。
實驗結論
1. 相比不使用想象模塊的方法,使用文本想象使建筑的細節更豐富:雷達圖顯示,CoT+GPT-4除魯棒性外,所有方面表現超過Vanilla GPT-4,后者只能穩定地創造簡單的建筑。Elo評分的結果顯示Vanilla GPT-4弱于其他方法。

2. 使用圖像想象的智能體表現好于使用文本想象的智能體:雷達圖中的各個評價方面,Diffusion+GPT-4V表現略好于CoT+GPT-4,表明生成圖像形式的想象效果更好。
3. Diffusion+GPT-4V相比其他方法具有最好的綜合表現:它利用了擴散模型生成細節豐富的圖像想象的優勢,并且對擴散模型生成圖像的噪聲比較魯棒。
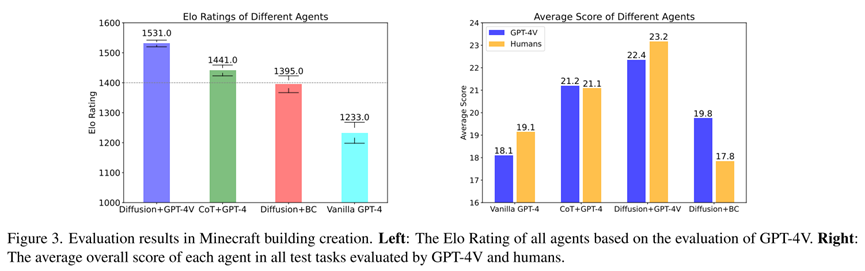
4. GPT-4V評價和人類評價的一致性較好:在對各個方法的綜合打分中,GPT-4V評價和人類評價對四個方法的性能排序基本一致。表1顯示了GPT-4V和人類對每一對樣本的評價具有良好的一致性,對兩個樣本的好壞關系做出一致評價的概率超過60%。

5. 受限于控制器的性能,目前Creative Agents能夠創造的建筑比較簡單:作者注意到GPT-4(V)傾向于生成簡單的代碼,而模仿學習的控制器存在過擬合的問題、建造的建筑不準確。下圖顯示了各種方法建造的結果與擴散模型想象的建筑圖像均存在差距。

總結
作者對開放式智能體的創造性研究做出了第一步嘗試,提出賦予智能體想象力、解決創造式任務的框架Creative Agents,并對若干種實現方案進行了實驗分析。作者在Minecraft中構建了創造式任務的測試環境和數據集,提出了一套基于GPT-4V的評價指標,為后續相關領域的研究提供了基準。
創造性是人類區別于其他動物的重要特性之一。如何讓智能體具備創造性、通過想象更好地完成開放式任務是實現通用人工智能的重要環節,也是學術界需要深入研究的問題。