QTNet:最新時(shí)序融合新方案!點(diǎn)云、圖像、多模態(tài)檢測器全適用(NeurIPS 2023)
本文經(jīng)自動(dòng)駕駛之心公眾號(hào)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
寫在前面 & 個(gè)人理解
時(shí)序融合能夠有效提升自動(dòng)駕駛3D目標(biāo)檢測的感知能力,然而目前的時(shí)序融合方法由于成本開銷等問題難以在實(shí)際自動(dòng)駕駛場景中應(yīng)用。NeurIPS 2023的最新研究文章 《Query-based Temporal Fusion with Explicit Motion for 3D Object Detection》將DETR中的稀疏Query作為時(shí)序融合的對(duì)象,并針對(duì)大規(guī)模點(diǎn)云的特性使用顯式運(yùn)動(dòng)信息引導(dǎo)時(shí)序注意力矩陣的生成。來自華中科技大學(xué)和百度的研究者們?cè)诒疚闹刑岢隽薗TNet:基于Query和顯式運(yùn)動(dòng)的3D目標(biāo)檢測時(shí)序融合方法。實(shí)驗(yàn)效果表明,QTNet能以可忽略不計(jì)的成本開銷為點(diǎn)云、圖像、多模態(tài)檢測器帶來一致的性能增益。

- 論文鏈接:https://openreview.net/pdf?id=gySmwdmVDF
- 代碼鏈接:https://github.com/AlmoonYsl/QTNet
問題背景
得益于現(xiàn)實(shí)世界的時(shí)間連續(xù)性,時(shí)間維度上的信息可以使得感知信息更加完備,進(jìn)而提高目標(biāo)檢測的精度和魯棒性,例如時(shí)序信息可以幫助解決目標(biāo)檢測中的遮擋問題、提供目標(biāo)的運(yùn)動(dòng)狀態(tài)和速度信息、提供目標(biāo)的持續(xù)性和一致性信息。因此如何高效地利用時(shí)序信息是自動(dòng)駕駛感知的一個(gè)重要問題。現(xiàn)有的時(shí)序融合方法主要分為兩類。一類是基于稠密的BEV特征進(jìn)行時(shí)序融合(點(diǎn)云/圖像時(shí)序融合都適用),另一類則是基于3D Proposal特征進(jìn)行時(shí)序融合 (主要針對(duì)點(diǎn)云時(shí)序融合方法)。對(duì)于基于BEV特征的時(shí)序融合,由于BEV上超過90%的點(diǎn)都是背景,而該類方法沒有更多地關(guān)注前景對(duì)象,這導(dǎo)致了大量沒有必要的計(jì)算開銷和次優(yōu)的性能。對(duì)于基于3D Proposal的時(shí)序融合算法,其通過耗時(shí)的3D RoI Pooling來生成3D Proposal特征,尤其是在目標(biāo)物較多,點(diǎn)云數(shù)量較多的情況下,3D RoI Pooling所帶來的開銷在實(shí)際應(yīng)用中往往是難以接受的。此外,3D Proposal 特征嚴(yán)重依賴于Proposal的質(zhì)量,這在復(fù)雜場景中往往是受限的。因此,目前的方法都難以以極低開銷的方式高效地引入時(shí)序融合來增強(qiáng)3D目標(biāo)檢測的性能。
如何實(shí)現(xiàn)高效的時(shí)序融合?
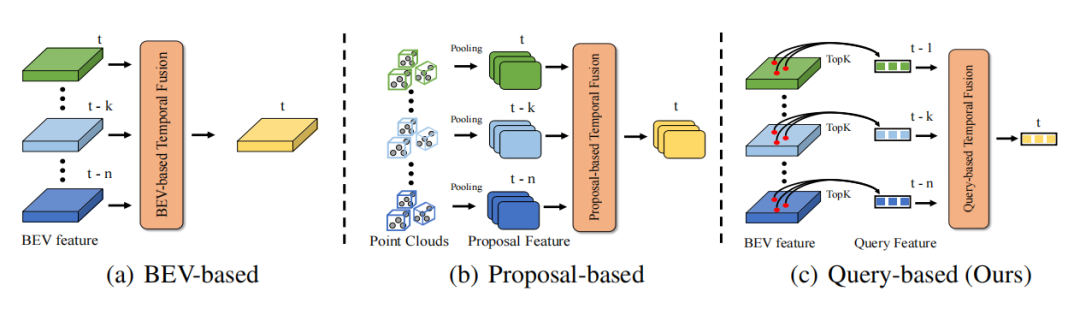
DETR是一種十分優(yōu)秀的目標(biāo)檢測范式,其提出的Query設(shè)計(jì)和Set Prediction思想有效地實(shí)現(xiàn)了無需任何后處理的優(yōu)雅檢測范式。在DETR中,每個(gè)Query代表一個(gè)物體,并且Query相對(duì)于稠密的特征來說十分稀疏(一般Query的數(shù)目會(huì)被設(shè)置為一個(gè)相對(duì)較少的固定數(shù)目)。如果以Quey作為時(shí)序融合的對(duì)象,那計(jì)算開銷的問題自然下降一個(gè)層次。因此DETR的Query范式是一種天然適合于時(shí)序融合的范式。時(shí)序融合需要構(gòu)建多幀之間的物體關(guān)聯(lián),以此實(shí)現(xiàn)時(shí)序上下文信息的綜合。那么主要問題在于如何構(gòu)建基于Query的時(shí)序融合pipeline和兩幀間的Query建立關(guān)聯(lián)。
- 由于在實(shí)際場景中自車往往存在的運(yùn)動(dòng),因此兩幀的點(diǎn)云/圖像往往是坐標(biāo)系不對(duì)齊的,并且實(shí)際應(yīng)用中不可能在當(dāng)前幀對(duì)所有歷史幀重新forward一次網(wǎng)絡(luò)來提取對(duì)齊后點(diǎn)云/圖像的特征。因此本文采用Memory Bank的方式來只存儲(chǔ)歷史幀得到的Query特征及其對(duì)應(yīng)的檢測結(jié)果,以此來避免重復(fù)計(jì)算。
- 由于點(diǎn)云和圖像在描述目標(biāo)特征上存在很大差異,通過特征層面來構(gòu)建統(tǒng)一時(shí)序融合方法是不太可行的。然而,在三維空間下,無論點(diǎn)云還是圖像模態(tài)都能通過目標(biāo)的幾何位置/運(yùn)動(dòng)信息關(guān)系來刻畫相鄰幀之間的關(guān)聯(lián)關(guān)系。因此,本文采用物體的幾何位置和對(duì)應(yīng)的運(yùn)動(dòng)信息來引導(dǎo)兩幀間物體的注意力矩陣。
方法介紹
QTNet的核心思想在于利用Memory Bank存儲(chǔ)在歷史幀已經(jīng)獲得的Query特征及其對(duì)應(yīng)的檢測結(jié)果,以此避免對(duì)于歷史幀的重復(fù)計(jì)算開銷。對(duì)于兩幀Query之間,則使用運(yùn)動(dòng)引導(dǎo)的注意力矩陣進(jìn)行關(guān)系建模。
總體框架
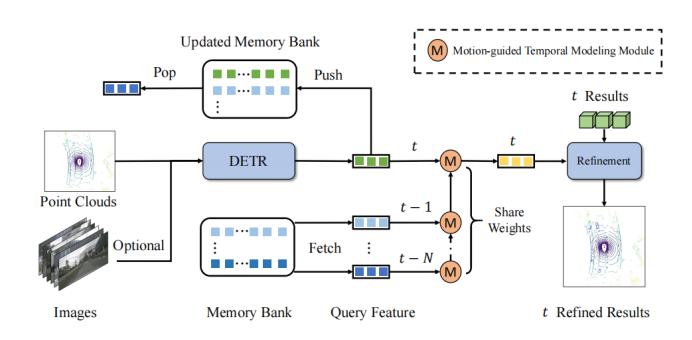
如框架圖所示,QTNet包含3D DETR結(jié)構(gòu)的3D目標(biāo)檢測器(LiDAR、Camera和多模態(tài)均可),Memory Bank和用于時(shí)序融合的Motion-guided Temporal Modeling Module (MTM)。QTNet通過DETR結(jié)構(gòu)的3D目標(biāo)檢測器獲取對(duì)應(yīng)幀的Query特征及其檢測結(jié)果,并將得到的Query特征及其檢測結(jié)果以先進(jìn)先出隊(duì)列(FIFO)的方式送入Memory Bank中。Memory Bank的數(shù)目設(shè)置為時(shí)序融合所需的幀數(shù)。對(duì)于時(shí)序融合,QTNet從Memory Bank中從最遠(yuǎn)時(shí)刻開始讀取數(shù)據(jù),通過MTM模塊以迭代的方式從 幀到 幀融合MemoryBank中的所有特征以用來增強(qiáng)當(dāng)前幀的Query特征,并根據(jù)增強(qiáng)后的Query特征來Refine對(duì)應(yīng)的當(dāng)前幀的檢測結(jié)果。
具體而言,QTNet在 幀融合 和 幀的Query特征 和 ,并得到增強(qiáng)后的 幀的Query特征 。接著,QTNet再將 與 幀的Query特征進(jìn)行融合。以此通過迭代的方式不斷融合至 幀。注意,這里從 幀到 幀所使用的MTM全部是共享參數(shù)的。
運(yùn)動(dòng)引導(dǎo)注意力模塊
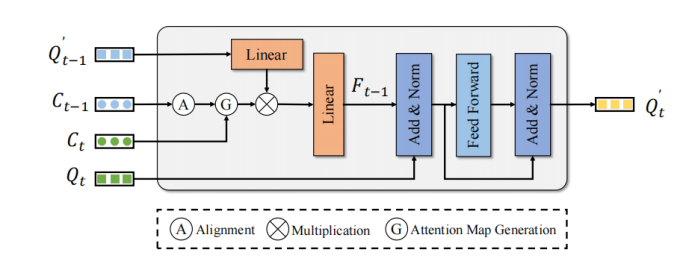
MTM使用物體的中心點(diǎn)位置來顯式生成 幀Query和 幀Query的注意力矩陣。給定ego pose矩陣 和 、物體中心點(diǎn)、速度。首先,MTM使用ego pose和物體預(yù)測的速度信息將上一幀的物體移動(dòng)到下一幀并對(duì)齊兩幀的坐標(biāo)系:
接著通過 幀物體中心點(diǎn)和 幀經(jīng)過矯正的中心點(diǎn)構(gòu)建歐式代價(jià)矩陣 。此外,為了避免可能發(fā)生的錯(cuò)誤匹配,本文使用類別 和距離閾值 構(gòu)造注意力掩碼 :
最終將代價(jià)矩陣轉(zhuǎn)換為注意力矩陣:
將注意力矩陣 作用在 幀的增強(qiáng)后的Query特征 來聚合時(shí)序特征以增強(qiáng) 幀的Query特征:
最終增強(qiáng)后的 幀的Query特征 經(jīng)過簡單的FFN來Refine對(duì)應(yīng)的檢測結(jié)果,以實(shí)現(xiàn)增強(qiáng)檢測性能的作用。
解耦時(shí)序融合結(jié)構(gòu)
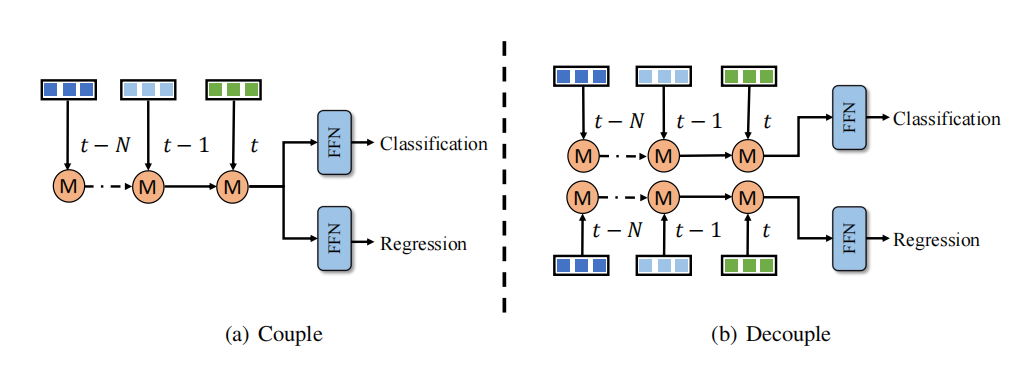
本文觀察到時(shí)序融合的分類和回歸學(xué)習(xí)存在不平衡問題,一種解決辦法是對(duì)于分類和回歸單獨(dú)設(shè)計(jì)時(shí)序融合分支。然而,這種解耦方式會(huì)帶來更多的計(jì)算成本和延遲,這對(duì)于大多數(shù)方法來說是不可接受的。相比之下,得益于高效的時(shí)序融合設(shè)計(jì),與整個(gè)3D檢測網(wǎng)絡(luò)相比QTNet的計(jì)算成本和延遲可以忽略不計(jì)。因此,如圖所示,本文將分類和回歸分支在時(shí)序融合上進(jìn)行解耦,以在可忽略不計(jì)的成本的情況下取得更好的檢測性能。
實(shí)驗(yàn)效果
QTNet在點(diǎn)云/圖像/多模態(tài)上實(shí)現(xiàn)一致漲點(diǎn)
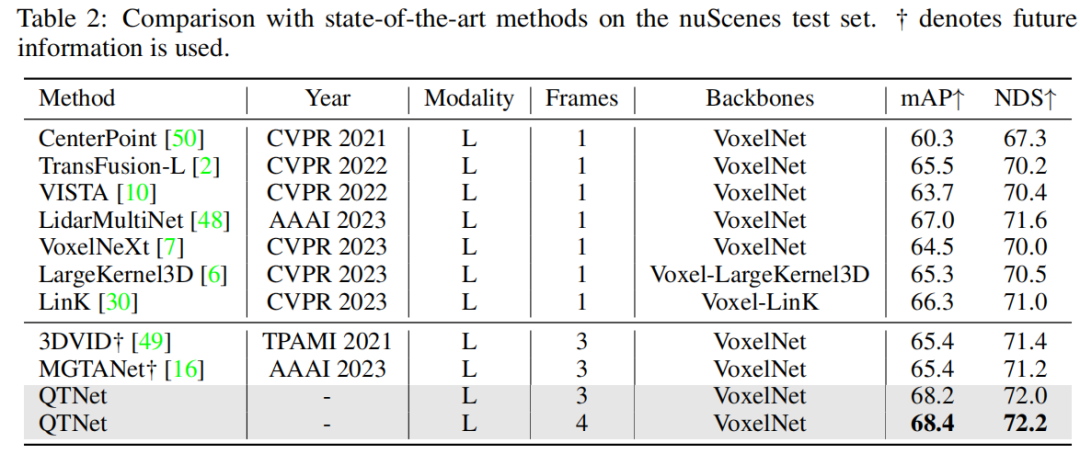
本文在nuScenes數(shù)據(jù)集上進(jìn)行驗(yàn)證,在不使用未來信息、TTA、模型集成的情況下QTNet在nuScenes benchmark上取得了68.4 mAP 和 72.2 NDS的SOTA性能。相較于使用了未來信息的MGTANet,QTNet在3幀時(shí)序融合的情況下優(yōu)于MGTANet 3.0 mAP 和 1.0NDS。
此外,本文也在多模態(tài)和基于環(huán)視圖的方法上進(jìn)行了驗(yàn)證,在nuScenes驗(yàn)證集上的實(shí)驗(yàn)結(jié)果證明了QTNet在不同模態(tài)上的有效性。


時(shí)序融合的成本開銷對(duì)于實(shí)際應(yīng)用來說十分重要,本文針對(duì)QTNet在計(jì)算量、時(shí)延、參數(shù)量三個(gè)方面進(jìn)行了分析實(shí)驗(yàn)。可以發(fā)現(xiàn)QTNet對(duì)于不同baseline所帶來的計(jì)算開銷、時(shí)間延、參數(shù)量相對(duì)于整個(gè)網(wǎng)絡(luò)來說均可忽略不計(jì),尤其是計(jì)算量僅僅使用0.1G FLOPs(LiDAR baseline)。

不同時(shí)序融合范式比較
為了驗(yàn)證本文所提出的基于Query的時(shí)序融合范式的優(yōu)越性,本文選取了具有代表性的不同前沿時(shí)序融合方法進(jìn)行比較。通過實(shí)驗(yàn)結(jié)果可以發(fā)現(xiàn),基于Query范式的時(shí)序融合算法相較于其他基于BEV和基于Proposal范式更加高效。QTNet以0.1G FLOPs和4.5ms的開銷的情況下取得了更加優(yōu)秀的性能,此外整體參數(shù)量僅僅只有0.3M。

消融實(shí)驗(yàn)
本文基于LiDAR baseline在nuScenes驗(yàn)證集上以3幀時(shí)序融合進(jìn)行了消融實(shí)驗(yàn)。通過消融實(shí)驗(yàn)可以發(fā)現(xiàn),如果簡單地使用Cross Attention去建模時(shí)序關(guān)系是沒有明顯的效果的。然而在使用MTM后,可以明顯觀測到檢測性能的漲幅,這表明了顯式運(yùn)動(dòng)引導(dǎo)在大規(guī)模點(diǎn)云下的重要性。此外,通過幀數(shù)的消融實(shí)驗(yàn)可以發(fā)現(xiàn),QTNet的整體設(shè)計(jì)是十分輕量且有效的。在使用4幀數(shù)據(jù)進(jìn)行時(shí)序融合后,QTNet所帶來的計(jì)算量僅僅只有0.24G FLOPs,延遲也只有6.5ms。

MTM的可視化
為了探究MTM優(yōu)于Cross Attention的原因,本文將兩幀間物體的注意力矩陣進(jìn)行可視化,其中相同的ID代表兩幀間同一個(gè)物體。可以發(fā)現(xiàn)由MTM生成的注意力矩陣(b)比Cross Attention生成的注意力矩陣(a)更加具有區(qū)分度,尤其是小物體之間的注意力矩陣。這表明由顯式運(yùn)動(dòng)引導(dǎo)的注意力矩陣通過物理建模的方式使得模型更加容易地建立起兩幀間物體的關(guān)聯(lián)。本文僅僅只是初步探索了在時(shí)序融合中以物理方式建立時(shí)序關(guān)聯(lián)問題,對(duì)于如何更好構(gòu)建時(shí)序關(guān)聯(lián)仍然是值得探索的。

檢測結(jié)果的可視化
本文以場景序列為對(duì)象進(jìn)行了檢測結(jié)果的可視化分析。可以發(fā)現(xiàn)左下角的小物體從 幀開始快速遠(yuǎn)離自車,這導(dǎo)致baseline在 幀漏檢了該物體,然而QTNet在 幀仍然可以檢測到該物體,這證明了QTNet在時(shí)序融合上的有效性。

本文總結(jié)
本文針對(duì)目前3D目標(biāo)檢測任務(wù)提出了更加高效的基于Query的時(shí)序融合方法QTNet。其主要核心有兩點(diǎn):一是使用稀疏Query作為時(shí)序融合的對(duì)象并通過Memory Bank存儲(chǔ)歷史信息以避免重復(fù)的計(jì)算,二是使用顯式的運(yùn)動(dòng)建模來引導(dǎo)時(shí)序Query間的注意力矩陣的生成,以此實(shí)現(xiàn)時(shí)序關(guān)系建模。通過這兩個(gè)關(guān)鍵思路,QTNet能夠高效地實(shí)現(xiàn)可應(yīng)用于LiDAR、Camera、多模態(tài)的時(shí)序融合,并以可忽略不計(jì)的成本開銷一致性地增強(qiáng)3D目標(biāo)檢測的性能。

原文鏈接:https://mp.weixin.qq.com/s/s9tkF_rAP2yUEkn6tp9eUQ