OpenAI官方的Prompt工程指南:你可以這么玩ChatGPT
隨著 ChatGPT、GPT-4 等大型語言模型(LLM)的出現,提示工程(Prompt Engineering)變得越來越重要。很多人將 prompt 視為 LLM 的咒語,其好壞直接影響模型輸出的結果。
如何寫好 prompt,已經成為 LLM 研究的一項必修課。
引領大模型發展潮流的 OpenAI,近日官方發布了一份提示工程指南,該指南分享了如何借助一些策略讓 GPT-4 等 LLM 輸出更好的結果。OpenAI 表示這些方法有時可以組合使用以獲得更好的效果。

指南地址:https://platform.openai.com/docs/guides/prompt-engineering
六個策略,獲得更好的結果
策略一:寫清楚指令
首先用戶要寫清楚指令,因為模型無法讀懂你的大腦在想什么。舉例來說,如果你希望模型的輸出不要太簡單,那就把指令寫成「要求專家級別的寫作」;又比如你不喜歡現在的文本風格,就換個指令明確一下。模型猜測你想要什么的次數越少,你得到滿意結果的可能性就越大。
只要你做到下面幾點,問題不會太大:
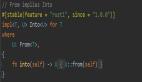
首先是提示中盡量包含更詳細的查詢信息,從而獲得更相關的答案,就像下面所展示的,同樣是總結會議記錄,采用這樣的提示「用一個段落總結會議記錄。然后寫下演講者的 Markdown 列表以及每個要點。最后,列出發言人建議的后續步驟或行動項目(如果有)。」結果會比較好。

其次是用戶可以提供示例。例如,當你想讓模型模仿一種難以明確描述的回答風格時,用戶可以提供少數示例。

第三點是指定模型完成任務時所需的步驟。對于有些任務,最好指定步驟如步驟 1、2,顯式地寫出這些步驟可以使模型更容易地遵循用戶意愿。

第四點是指定模型輸出的長度。用戶可以要求模型生成給定目標長度的輸出,目標輸出長度可以根據單詞、句子、段落等來指定。

第五點是使用分隔符來明確劃分提示的不同部分。"""、XML 標簽、小節標題等分隔符可以幫助劃分要區別對待的文本部分。

第六點是讓模型扮演不同的角色,以控制其生成的內容。

策略 2 提供參考文本
語言模型會時不時的產生幻覺,自己發明答案,為這些模型提供參考文本可以幫助減少錯誤輸出。需要做到兩點:
首先是指示模型使用參考文本回答問題。如果我們可以為模型提供與當前查詢相關的可信信息,那么我們可以指示模型使用提供的信息來組成其答案。比如:使用由三重引號引起來的文本來回答問題。如果在文章中找不到答案,就寫「我找不到答案」。

其次是指示模型從參考文本中引用答案。

策略 3:將復雜的任務拆分為更簡單的子任務
正如軟件工程中將復雜系統分解為一組模塊化組件一樣,提交給語言模型的任務也是如此。復雜的任務往往比簡單的任務具有更高的錯誤率,此外,復雜的任務通常可以被重新定義為更簡單任務的工作流程。包括三點:
- 使用意圖分類來識別與用戶查詢最相關的指令;
- 對于需要很長對話的對話應用,總結或過濾以前的對話;
- 分段總結長文檔并遞歸的構建完整摘要。
由于模型具有固定的上下文長度,因此要總結一個很長的文檔(例如一本書),我們可以使用一系列查詢來總結文檔的每個部分。章節摘要可以連接起來并進行總結,生成摘要的摘要。這個過程可以遞歸地進行,直到總結整個文檔。如果有必要使用前面部分的信息來理解后面的部分,那么另一個有用的技巧是在文本(如書)中任何給定點之前包含文本的運行摘要,同時在該點總結內容。OpenAI 在之前的研究中已經使用 GPT-3 的變體研究了這種過程的有效性。
策略 4:給模型時間去思考
對于人類來說,要求給出 17 X 28 的結果,你不會立馬給出答案,但隨著時間的推移仍然可以算出來。同樣,如果模型立即回答而不是花時間找出答案,可能會犯更多的推理錯誤。在給出答案之前采用思維鏈可以幫助模型更可靠地推理出正確答案。需要做到三點:
首先是指示模型在急于得出結論之前找出自己的解決方案。
其次是使用 inner monologue 或一系列查詢來隱藏模型的推理過程。前面的策略表明,模型有時在回答特定問題之前詳細推理問題很重要。對于某些應用程序,模型用于得出最終答案的推理過程不適合與用戶共享。例如,在輔導應用程序中,我們可能希望鼓勵學生得出自己的答案,但模型關于學生解決方案的推理過程可能會向學生揭示答案。
inner monologue 是一種可以用來緩解這種情況的策略。inner monologue 的思路是指示模型將原本對用戶隱藏的部分輸出放入結構化格式中,以便于解析它們。然后,在向用戶呈現輸出之前,將解析輸出并且僅使部分輸出可見。
最后是詢問模型在之前的過程中是否遺漏了任何內容。
策略 5:使用外部工具
通過向模型提供其他工具的輸出來彌補模型的弱點。例如,文本檢索系統(有時稱為 RAG 或檢索增強生成)可以告訴模型相關文檔。OpenAI 的 Code Interpreter 可以幫助模型進行數學運算并運行代碼。如果一項任務可以通過工具而不是語言模型更可靠或更有效地完成,或許可以考慮利用兩者。
- 首先使用基于嵌入的搜索實現高效的知識檢索;
- 調用外部 API;
- 賦予模型訪問特定功能的權限。
策略 6:系統的測試變化
在某些情況下,對提示的修改會實現更好的性能,但會導致在一組更具代表性的示例上整體性能變差。因此,為了確保更改對最終性能產生積極影響,可能有必要定義一個全面的測試套件(也稱為評估),例如使用系統消息。
更多內容,請參考原博客。