OpenAI親授ChatGPT「屠龍術」!官方提示工程指南來啦
應該如何形容 Prompt 工程呢?對于一個最開始使用 ChatGPT 的新人小白,面對據說參數量千億萬億的龐然巨獸,Prompt 神秘的似乎像某種獻祭:我扔進去幾句話,等待聊天窗口后的「智慧生命」給我以神諭。
然而,上手 Prompt 之后,操縱 ChatGPT 似乎更加類似于指揮家指揮管弦樂隊,面對我們要解決的問題,合理的編排與組織文字,最后演化成類似指揮家的身體語言,控制大模型這樣一個「精密儀器」執行復雜任務。
那么如何快速上手 Prompt 工程將 ChatGPT 不再視為難以操縱的龐然大物而是得心應手的趁手兵刃呢?
就在近日,OpenAI 官方發布了 Prompt 工程指南,講述了快速上手 ChatGPT Prompt 的種種「屠龍術」,不僅在理論層面對 Prompt 分類總結,還提供了實際的 Prompt 用例,幫助大家來學習如何有效的與 ChatGPT 交互,一起來看看吧!
宏觀來看,OpenAI 給出了可以提升 ChatGPT 回復效果的「六大秘籍」,分別是:
- 清晰細致
- 提供參考
- 任務拆分
- 讓它思考
- 外部工具
- 系統測試
清晰細致
讓我們先來看第一條策略:清晰細致。
如果說的大白話一點,就是要把你需要解決的問題說清楚講明白。要想從 ChatGPT 那里獲得良好的回復,那么 Prompt 本身必須結合精確性、清晰度與任務描述的細致程度于一身,為了避免歧義而「把話說清楚」是讓 ChatGPT 高效工作的重中之重。
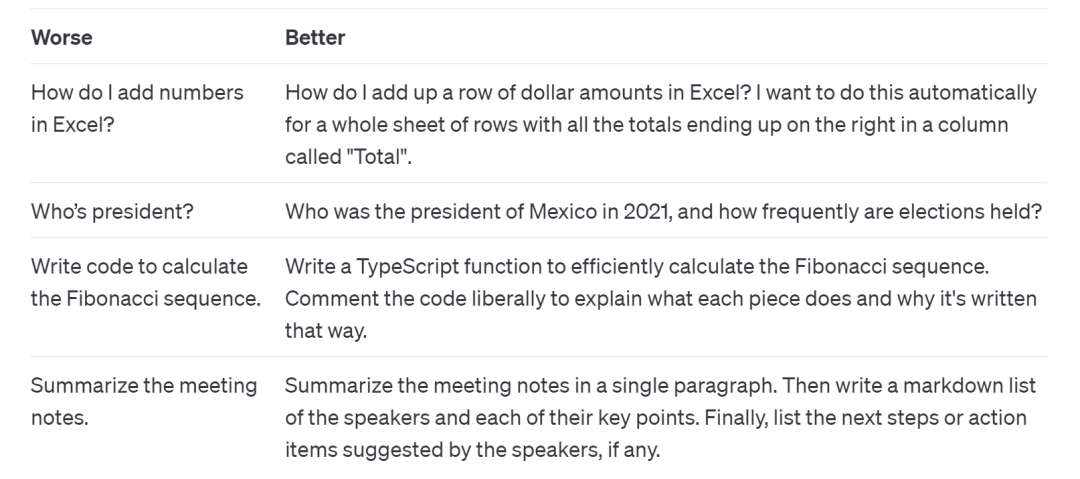
舉個例子,假設我們想了解「2021年的時候誰是墨西哥的總統」,甚至更進一步還想知道他/她是否目前仍然是總統,如果我們扔給 ChatGPT 一句「誰是總統?」,別說 ChatGPT,就算是政治老師也會一臉懵逼,更好的 Prompt 應該是:「2021年誰是墨西哥的總統,墨西哥幾年舉行一次選舉?」
如果說上面的例子有點極端,那么再看一個更加日常的例子。假設我們要去進行一個會議總結,如果我們期望 ChatGPT 可以給到我們良好的回復,那么我們就不應該直接扔進去一句話:「幫我總結這份會議筆記」,而是要將我們的需求講明白:「首先使用簡單一段總結概括這份會議筆記的主要內容,其次將會議中各個發言者的核心點以Markdown的格式分條列出,最后,如果有的話,列出每個發言者提出的下一步行動計劃與方案。」
顯然,后者的描述更為清晰,更有可能得到我們想要的答案。OpenAI 在指南中列出了一個 Worse or Better 的示例供大家參考:
同時,OpenAI 給出了一個 Prompt 想要做到表達清晰細致應該需要包含的內容:
- 關于任務需求的詳細信息
- 要求模型扮演的角色
- 使用分隔符清晰的區分輸入的不同部分
- 指定完成任務所需的步驟
- 提供示例
- 指定所需的輸出長度
以上述的會議總結為例,一個更加完整的 Prompt 可能是:
指令:假設你是一場會議的會議秘書【指定角色】,首先【任務拆分】使用簡單一段總結概括這份會議筆記的主要內容,其次將會議中各個發言者的核心點以 Markdown 的格式分 3 條【指定長度】列出,最后,如果有的話,列出每個發言者提出的下一步行動計劃與方案【詳細信息】。請以將總結插入到下方模板的<>中間。
模板【使用分隔符】:總結:發言人 1 核心觀點:發言人 2 核心觀點:…… 發言人 1 行動計劃:發言人 2 行動計劃:……
示例【提供示例】:……
提供參考
第二點重要的策略是需要為 ChatGPT 提供參考,通過引導 ChatGPT 根據我們給定的材料撰寫答案,將會使得模型回答更加聚焦于當前的問題之上,從而生成更加可靠與準確的答案。
譬如,如果我們直接詢問模型「知識產權盜竊的法律后果是什么?」,那么模型可能無法專業準確的對問題進行回復,而如果我們給模型提供一篇關于知識產權法的論文或發條,模型就會給出更加專業的回復。
指令:參考提供的法律期刊文章與法條,解釋知識產權盜竊的法律后果。參考:【知識產權盜竊的法律規范xxx】
而為了使得模型更好的理解參考文本并且直接引用參考中的原文進行回復,那么就可以對參考引用做出更加細致的解釋,譬如:
指令:參考下面這份由三個引號進行分隔的文件,請回答知識產權盜竊的法律后果是什么。請僅僅引用所提供的文件來回答問題,并且引用用于回答問題的相關段落,如果文件中不包含回答問題所需的信息,則需要寫出「信息不足」。如果找到了相關答案,則必須注明引文,請使用以下格式引用相關段落({“引用”:……})。參考:【知識產權盜竊的法律規范xxx】
任務拆分
受啟發來自軟件工程中將復雜系統分解為一組模塊的組件的思想,任務拆分也是提示 Prompt 性能的法寶之一,復雜任務可以被拆分為簡單任務的累加,通過解決一系列簡單任務就可以得到逼近復雜任務滿意解的方案。
舉一個長文檔摘要的例子,對于一個過長的文本,比如直接讓 ChatGPT 理解一本 300 頁的書籍可能 ChatGPT 無法做到,但是通過任務分解——遞歸的分別總結書籍中的每一章,在每一章的總結之上對書籍內容進行摘要——就有可能實現對難任務的解決。
具體而言,任務分解的也需要做到:
- 對不同的查詢任務進行分類
- 對長對話進行總結與過濾
- 分段總結長文檔并遞歸構建摘要
而這樣做,可以:
- 通過專注于復雜任務的特定方面以提升準確率
- 分解任務使得子任務更加便于管理,可以降低錯誤率與輸出不相關內容的概率
- 用戶收到有針對性的分步指導有可能提升用戶體驗
- 子任務劃分也有可能帶來成本效益
讓它思考
有一個有意思的點在于,從「Let's think step by step」的實踐中我們可以發現,讓模型一步一步的思考而不是直接給出答案可以顯著的提升任務的準確率。
以思維鏈技術 COT 的代表應用數學解題為例,有如下的題目:
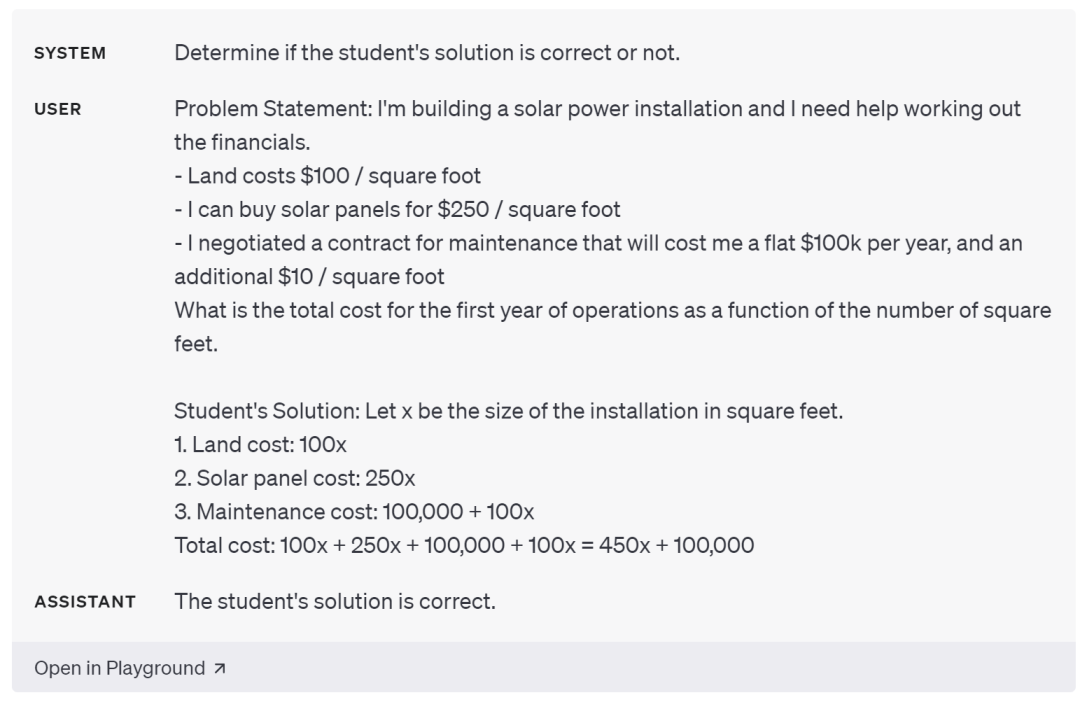
土地租用成本為 100 美元/平方英尺,太陽能電池板購買成本為 250 美元/平方英尺,固定投入成本為 10 萬美元,每年的運營成本為 10 美元/平方英尺,假設購買 x 平方英尺的太陽能電池板,請問一年的總成本為多少?
對此,現在,有個學生給出的解題步驟為(1)土地成本100x,(2)電池板購買成本250x,(3)運營成本10x,(4)固定投入100000,則總成本為 100x + 250x + 100x + 100000 = 450x + 100000。
顯然這名學生將運營成本的 10x 錯寫為了 100x,但是如果直接將學生答案輸入模型,詢問「學生的解決方案是否正確?」時,模型卻會錯誤認為該解法正確:
但是如果「讓模型進行思考」,告訴模型首先由模型自己確定一個解決方案,再將自己的解法與學生的解法進行比較,評估學生的解法是否正確。在自己完成問題之前,不要確定學生的解法是否正確。
而如果這樣輸入,模型不僅可以提供正確解法還可以很快發現學生的錯誤之處:

外部工具
從 AI Agent 的思路出發,語言模型必然不是萬能的,但是就如同人類一樣,我們可以通過向模型提供其他工具的方式來彌補模型的弱點,其中最經典的應用莫過于大模型與代碼執行引擎的結合。
所謂讓專業的人去做專業的事,直接從自己學習與訓練的語料中感知到今天的天氣如何可能對大模型而言是無法做到的,但是現在有太多方便調用的天氣 API 可以很快的幫助模型查詢到今天的天氣,從而使得模型提升自己的能力。
其中典型的應用有:
- 精確求解問題:如果直接問模型一個加減乘除平方開根號,涉及精確值的問題大模型往往并不擅長,譬如計算 529 的平方根,模型一開始的輸出是不確定的不精確的,但是如果更改 Prompt 讓模型「編寫并執行 Python 代碼來計算此值」,則會得到更加有據可依的答案
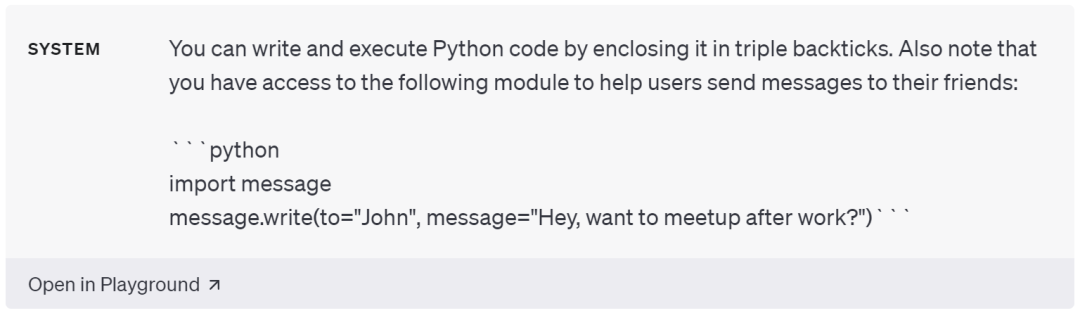
- 專用功能問題:如果直接讓模型「向我的朋友發送關于我們明天見面的提醒」,那么模型估計愛莫能助。但是如果讓模型使用 Python 調用消息 API 發送消息,那么模型就可以很好的完成消息傳遞這一需求
系統測試
要想真正測試到「好的 Prompt」,那么必然要在一個全面系統的環境下對 Prompt 進行評估與檢驗。很多場景下在一個孤立的實例中一個 Prompt 的效果良好并不能代表這個 Prompt 可以推而廣之,因此對 Prompt 的系統測試也是提升 Prompt 能力的關鍵環節之一。
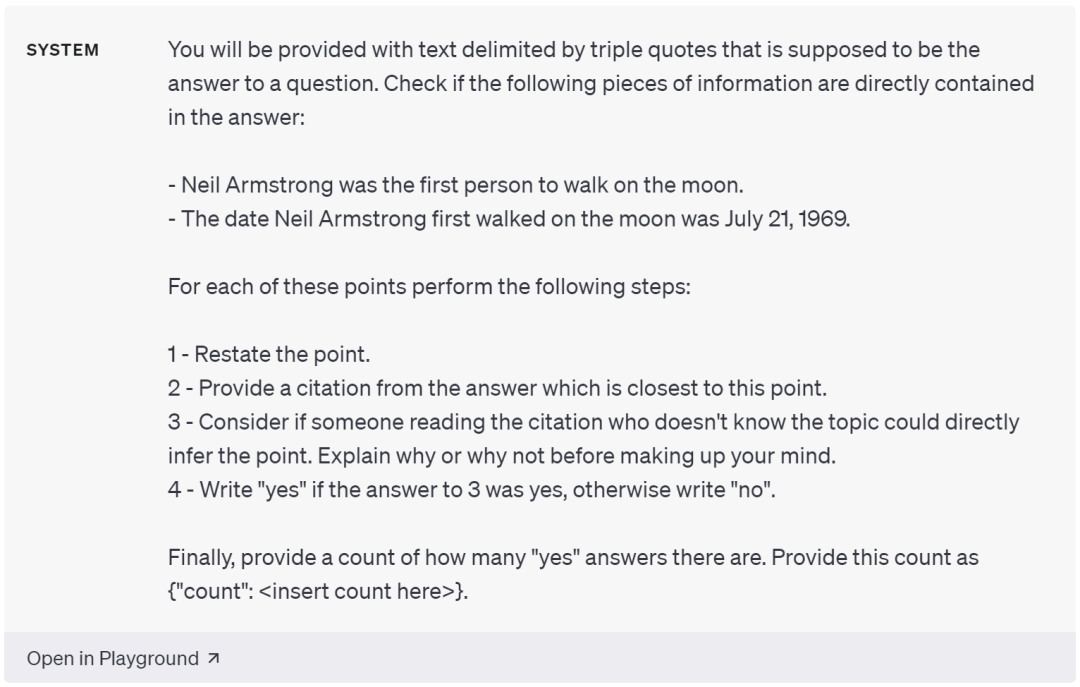
其中,一種方法是假設我們已經知道了正確答案應當包含的某個已知事實,那么就可以使用模型來查詢輸出中包含多少必要的事實。比如我們假設存在一個事實「阿姆斯特朗是第一個登上月球的人」,則可以向模型輸入:
以下有三組以引號進行分隔的文本,該文本的正確答案是:尼爾·阿姆斯特朗是第一個登上月球的人,請檢查答案是否直接包含上述信息,對于每組文本,請首先理解文本,提供最接近正確的答案的引文,考慮在不清楚相關主題的人是否可以直接從該文本推斷出正確答案。
此外,還可以借助「矛盾推斷」,「細節補充」等等方式對輸出答案進行評估,以確定更好的 Prompt 格式。
總結
毫無疑問,Prompt 的質量顯著影響著大模型的性能,而好的 Prompt 有甚至不僅僅是一種技術更是一種「藝術」。作為「人」與「AI」互動的窗口,Prompt 很有可能是未來 AI 時代我們必須掌握的「第二語言」,而這份 OpenAI 官方的指南就非常類似一本小學英語入門教科書,感興趣的大家可以去查閱原文瀏覽更加詳細的例子。
鏈接: https://platform.openai.com/docs/guides/prompt-engineering/six-strategies-for-getting-better-results
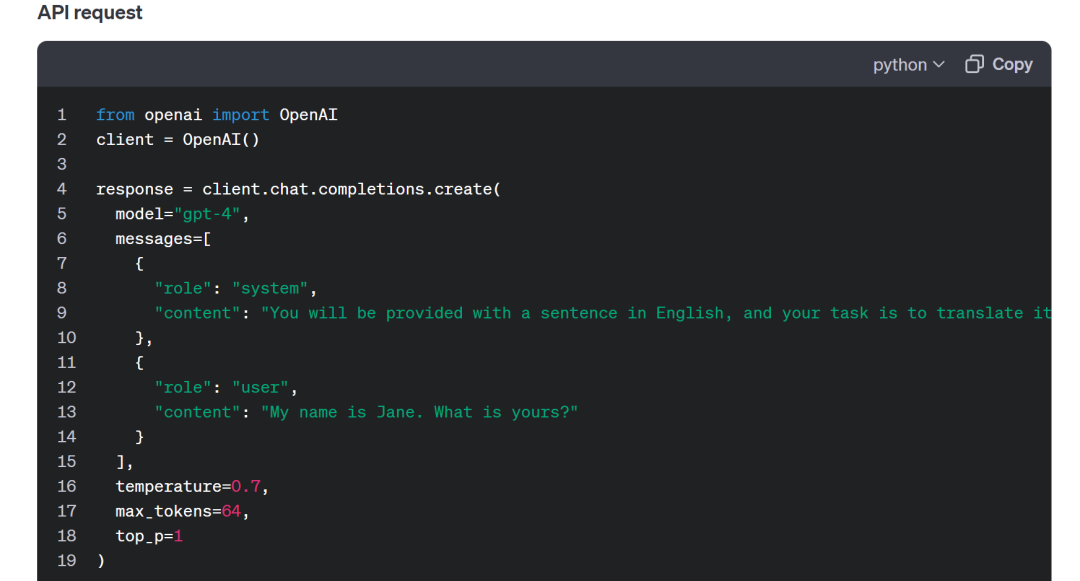
除了指南以外,OpenAI 還提供了更加即插即用的各個場景下的優秀 Prompt 范例。
譬如我期望使用大模型完成翻譯任務,那么在 Prompt examples 中搜索翻譯,就可以找到優秀的「滿分作文」供我們抄襲(x)借鑒(√)。
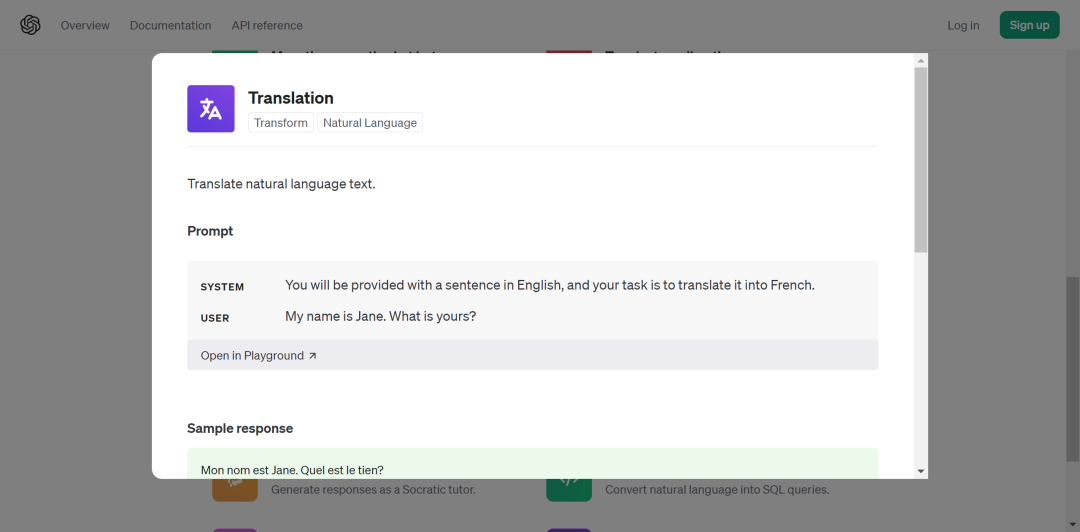
除了 Prompt 以外,還有 API 調用的代碼以供參考,提供了推薦的 temperature 等參數: