快手Agents系統(tǒng)、模型、數(shù)據(jù)全部開源!
7B 大小的模型也能玩轉(zhuǎn) AI Agents 了?近期,快手開源了「KwaiAgents」,問它周末滑雪問題,它不但幫你找到場(chǎng)地,連當(dāng)天的天氣都幫你考慮周到了。

大家都知道大語言模型(LLM)通過對(duì)語言的建模而掌握了大量知識(shí),并具備一定認(rèn)知和推理能力。但即使是當(dāng)前最強(qiáng)的 GPT-4,單獨(dú)使用的情況下,依然會(huì)一本正經(jīng)地胡說八道,無法跟世界保持實(shí)時(shí)的交互。AI Agents 就是解決這個(gè)問題的道路之一,通過激發(fā)大模型任務(wù)規(guī)劃、反思、調(diào)用工具等能力,使大模型能夠借助現(xiàn)實(shí)世界工具提升生成內(nèi)容的準(zhǔn)確性,甚至有能力解決復(fù)雜問題。這一次,快手聯(lián)合哈爾濱工業(yè)大學(xué)研發(fā)的「KwaiAgents」,使 7B/13B 的 “小” 大模型也能達(dá)到超越 GPT-3.5 的效果,并且這些系統(tǒng)、模型、數(shù)據(jù)、評(píng)測(cè)都開源了!

- 技術(shù)報(bào)告:https://arxiv.org/abs/2312.04889
- 項(xiàng)目主頁:https://github.com/KwaiKEG/KwaiAgents
從「KwaiAgents」的 Github 主頁中可以看到,本次開源內(nèi)容包含:
- 系統(tǒng)(KAgentSys-Lite):輕量級(jí) AI Agents 系統(tǒng),并配備事實(shí)、時(shí)效性工具集;
- 模型(KAgentLMs):Meta-Agent Tuning 后,具有 Agents 通用能力的系列大模型及其訓(xùn)練數(shù)據(jù);
- 評(píng)測(cè)(KAgentBench):開箱即用的 Agent 能力自動(dòng)化評(píng)測(cè) Benchmark 與人工評(píng)測(cè)結(jié)果。

系統(tǒng)
KAgentSys 系統(tǒng),是基于大模型作為認(rèn)知內(nèi)核,配以記憶機(jī)制、工具庫,形成的迭代式自動(dòng)化系統(tǒng)。其主要包含:
- 記憶機(jī)制:包含知識(shí)庫、對(duì)話、任務(wù)歷史三類記憶,依托于混合向量檢索、關(guān)鍵詞檢索等技術(shù)的檢索框架,在每一次規(guī)劃路徑中檢索所需的信息。
- 工具集:包含事實(shí)性增強(qiáng)工具集,異構(gòu)的搜索和瀏覽機(jī)制能夠匯集網(wǎng)頁、文本百科、視頻百科等多個(gè)來源的知識(shí);包含日歷、節(jié)日、時(shí)間差、天氣等常見的時(shí)效性增強(qiáng)工具集。
- 自動(dòng)化 Loop:在一輪對(duì)話中,用戶會(huì)給予一個(gè)問題,可選知識(shí)庫及額外人設(shè)整體進(jìn)行輸入,系統(tǒng)會(huì)先進(jìn)行記憶的更新和檢索,再調(diào)用大模型進(jìn)行任務(wù)的規(guī)劃,如果需要調(diào)用工具則進(jìn)行調(diào)用,如果不用則進(jìn)入總結(jié)階段,大模型綜合歷史的信息給出符合預(yù)期的回答。
本次開源 KAgentSys 的部分能力,系統(tǒng)將逐步進(jìn)行升級(jí)和開放。
模型
為了避免訓(xùn)練中單一模板引起的過擬合問題,團(tuán)隊(duì)提出 Meta-Agent Tuning (MAT) 的方法,通過在訓(xùn)練數(shù)據(jù)中引入更多 Agent Prompt 模板,從而提升大模型在 Agent 能力上的通用性,并提升了效果。

Meta-Agent Tuning (MAT) 分為兩階段:
- 模板生成階段:通過設(shè)計(jì) Meta-Agent,對(duì)特定問題集合,生成實(shí)例化的 Agent Prompt 模板(上右圖為一個(gè)例子)候選;并在相同的實(shí)驗(yàn)環(huán)境下,生成模板產(chǎn)出的候選結(jié)果,與開源模板(如 ReAct,AutoGPT 等)產(chǎn)出的高置信結(jié)果,用打分模型進(jìn)行對(duì)比打分,從而篩選出高質(zhì)量的 Agent Prompt 模板庫。通過引入這些多元的模板,能夠顯著降低模型微調(diào)時(shí)對(duì)模板的依賴,提純更本質(zhì)的 Agents 在任務(wù)規(guī)劃、工具使用、反思等能力,從而提高模型的泛化性和有效性。
- 指令微調(diào)階段:基于上萬的模板,構(gòu)建了超過 20 萬的 Agent 調(diào)優(yōu)指令微調(diào)數(shù)據(jù)。團(tuán)隊(duì)調(diào)優(yōu)了一些熱門開源模型如 Qwen-7B、Baichuan2-13B 等,供大家使用和參考,后續(xù)還會(huì)陸續(xù)放出其他熱門模型。
評(píng)測(cè)
KAgentBench 通過人工精細(xì)化標(biāo)注的上千條數(shù)據(jù),做到了開箱即用,讓大家能夠用一行命令評(píng)測(cè)一個(gè)大模型在不同模板下各方面的 Agents 能力。
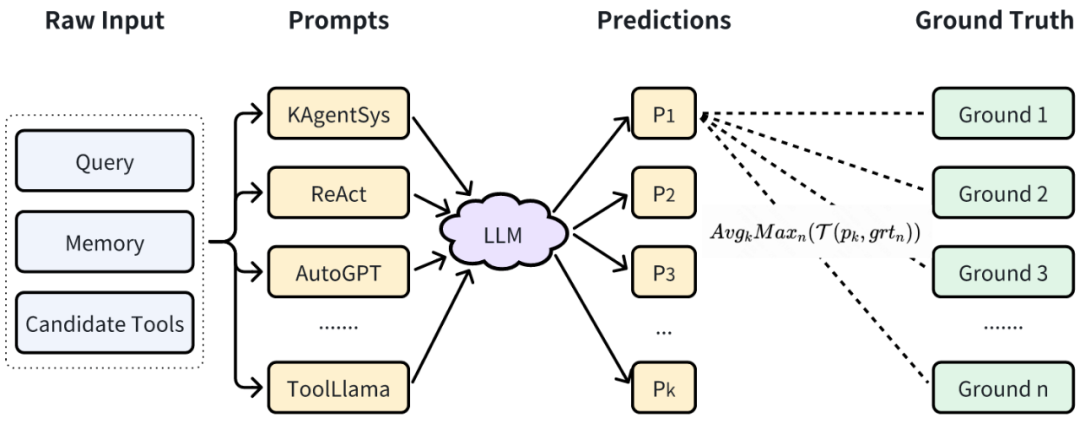
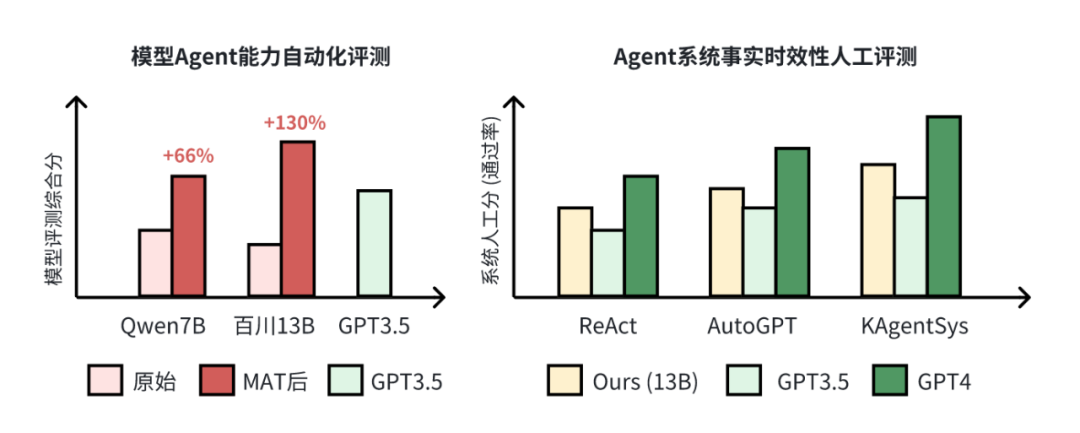
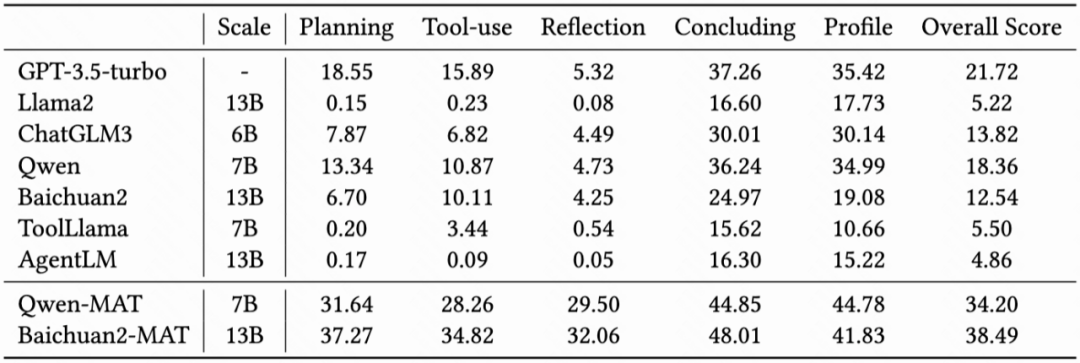
如上圖所示,在 KAgentBench 中,會(huì)對(duì)不同種類的能力構(gòu)造輸入,每個(gè) query 配備多個(gè)模板和多個(gè)人工編輯的真實(shí)回答,旨在綜合評(píng)測(cè)準(zhǔn)確性和泛化性,下表顯示了經(jīng)過 MAT 調(diào)優(yōu)后,7B-13B 模型各項(xiàng)能力的提升,且超越了 GPT-3.5 的效果:
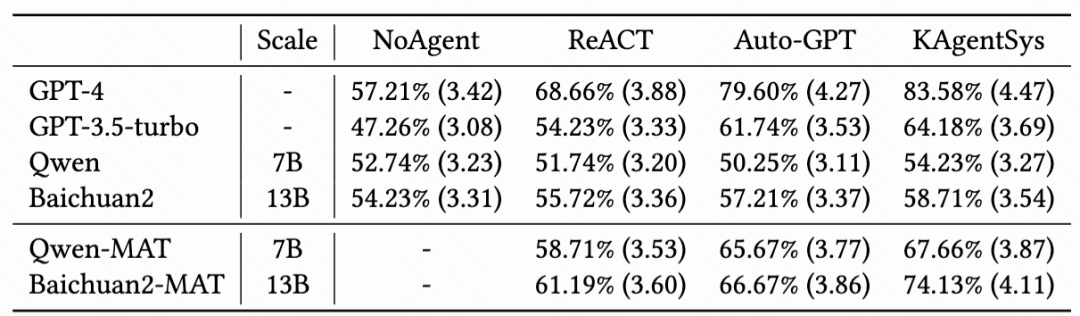
同時(shí),該研究還請(qǐng)人類標(biāo)注者在 200 個(gè)事實(shí)性和時(shí)效性的問題(如 “劉德華今年幾歲了”),對(duì)不同的大模型和 Agent 系統(tǒng)進(jìn)行了交叉評(píng)估,可以看到 KAgentSys 系統(tǒng)和 MAT 之后模型提升顯著(百分號(hào)前為正確率,括號(hào)內(nèi)為 5 分制均分)。

通常僅依賴網(wǎng)頁搜索對(duì)一些長(zhǎng)尾問題和熱門問題返回結(jié)果不佳。比如問到 “安東內(nèi)拉比梅西大多少天?” 這類長(zhǎng)尾問題,往往搜索結(jié)果返回的都是一些兩者的八卦新聞,而返回不了一些關(guān)鍵信息。而 KAgentSys 通過調(diào)用百科搜索工具獲取精準(zhǔn)的出生日期,再調(diào)用 time_delta 時(shí)間差工具算出年齡差,就能精準(zhǔn)回答這個(gè)問題了。
團(tuán)隊(duì)表示,AI Agents 是一條非常有潛力的道路,未來一方面會(huì)在這個(gè)方向持之以恒地沉淀核心技術(shù),并為整個(gè)社區(qū)不斷地注入新的活力;另一方面也會(huì)積極探索 Agents 技術(shù)與快手業(yè)務(wù)的結(jié)合,嘗試更多有趣、有價(jià)值的創(chuàng)新應(yīng)用落地。