?這次重生,AI要奪回網文界的一切
重生了,這輩子我重生成了 MidReal。一個可以幫別人寫「網文」的 AI 機器人。

這段時間里,我看到很多選題,偶爾也會吐槽一下。竟然有人讓我寫寫 Harry Potter。拜托,難道我還能寫的比 J?K?Rowling 更好不成?不過,同人什么的,我還是可以發揮一下的。
經典設定誰會不愛?我就勉為其難地幫助這些用戶實現想象吧。
實不相瞞,上輩子我該看的,不該看的,通通看了。就下面這些主題,都是我愛慘了的。

那些你看小說很喜歡卻沒人寫的設定,那些冷門甚至邪門的 cp,都能自產自嗑。

不是我自夸,只要你想要我寫,我還真能給你寫出個一二三來。結局不喜歡?喜歡的角色「中道崩殂」?作者寫到一半吃書了?包在我身上,給你寫到滿意。

甜文,虐文,腦洞文,每一種都狠狠擊中你的爽點。

聽完MidReal的自述,你對它了解了嗎?
MidReal 可以根據用戶提供的情景描述,生成對應的小說內容。情節的邏輯與創造力都很優秀。它還能在生成過程中生成插圖,更形象地描繪你所想象的內容。互動功能也是亮點之一,你可以選擇想要的故事情節進行發展,讓整體更加貼合你的需求。
在對話框中輸入 /start,就可以開始講述你的故事了,還不快來試試?
MidReal 傳送門:https://www.midreal.ai/

MidReal 背后的技術源于這篇論文《FireAct:Toward Language Agent Fine-tuning》。論文作者首次嘗試了用 AI 智能體來微調語言模型,發現了諸多優勢,由此提出了一種新的智能體架構。
MidReal 就是基于這種架構的,網文才能寫得這么好。

論文鏈接:https://arxiv.org/pdf/2310.05915.pdf
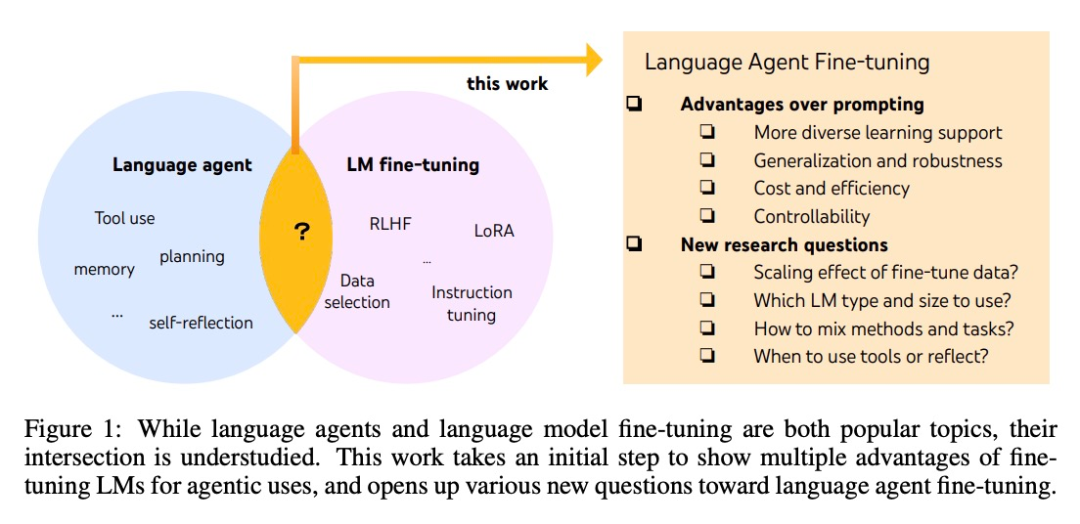
雖然智能體和微調大模型都是最熱門的 AI 話題,但它們之間具體有何聯系還不清楚。System2 Research、劍橋大學等的多位研究者對這片鮮有人涉足的「學術藍海」進行了發掘。
AI 智能體的開發通常基于現成的語言模型,但由于語言模型不是作為智能體而開發的,因此,延伸出智能體后,大多數語言模型的性能和穩健性較差。最聰明的智能體只能由 GPT-4 支持,它們也無法避免高成本和延遲,以及可控性低、重復性高等問題。
微調可以用來解決上面的這些問題。也是在這篇文章中,研究者們邁出了更加系統研究語言智能體的第一步。他們提出了 FireAct ,它能夠利用多個任務和提示方法生成的智能體「行動軌跡」來微調語言模型,讓模型更好地適應不同的任務和情況,提高其整體性能和適用性。
方法簡介
該研究主要基于一種流行的 AI 智能體方法:ReAct。一個 ReAct 任務解決軌跡由多個「思考 - 行動 - 觀察」回合組成。具體來說,讓 AI 智能體完成一個任務,語言模型在其中扮演的角色類似于「大腦」。它為 AI 智能體提供解決問題的「思考」和結構化的動作指示,并根據上下文與不同的工具交互,在這個過程中接收觀察到的反饋。
在 ReAct 的基礎上,作者提出了 FireAct,如圖 2 所示,FireAct 運用強大的語言模型的少樣本提示來生成多樣化的 ReAct 軌跡,用以微調較小規模的語言模型。與此前類似研究不同的是,FireAct 能夠混合多個訓練任務和提示方法,大大促進了數據的多樣性。
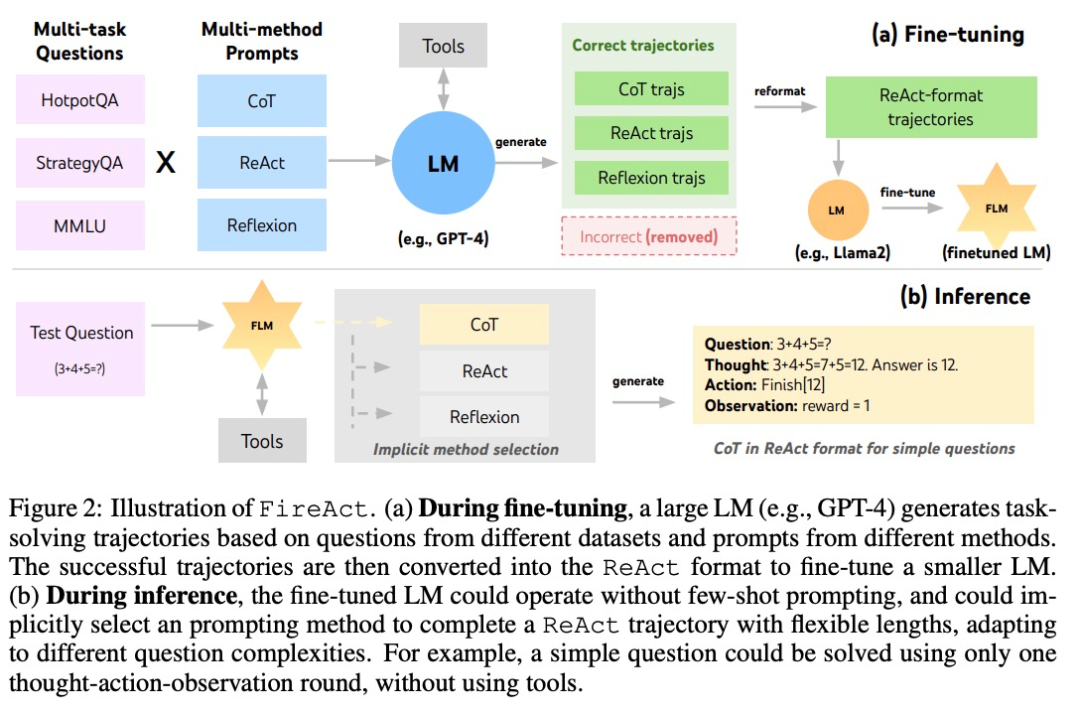
作者還參考了兩種與 ReAct 兼容的方法:
- 思維鏈(CoT)是生成連接問題和答案的中間推理的有效方法。每個 CoT 軌跡可以簡化為一個單輪 ReAct 軌跡,其中「思維」代表中間推理,「行動」代表返回答案。在不需要與應用工具交互的情況下,CoT 尤其有用。
- Reflexion 主要遵循 ReAct 軌跡,但加入了額外的反饋和自我反思。該研究中,僅在 ReAct 的第 6 輪和第 10 輪提示進行反思。這樣一來,長的 ReAct 軌跡就能為解決當前任務提供策略「支點」,能夠幫助模型解決或調整策略。例如搜索「電影名」得不到答案時,應該把搜索的關鍵詞換成「導演」。
在推理過程中,FireAct 框架下的 AI 智能體顯著減少了提示詞的樣本數量需求,推理也更加高效和簡便。它能夠根據任務的復雜度隱式地選擇合適的方法。由于 FireAct 具備更廣泛和多樣化的學習支持,與傳統的提示詞微調方法相比,它展現出更強的泛化能力和穩健性。
實驗及結果
任務數據集:HotpotQA,Bamboogle,StrategyQA,MMLU。
- HotpotQA 是一個 QA 數據集,對多步驟推理和知識檢索有著更具挑戰性的考驗。研究者使用 2,000 個隨機訓練問題進行微調數據整理,并使用 500 個隨機 dev 問題進行評估。
- Bamboogle 是一個由 125 個多跳問題組成的測試集,其格式與 HotpotQA 相似,但經過精心設計,以避免直接用谷歌搜索解決問題。
- StrategyQA 是一個需要隱式推理步驟的是 / 否 QA 數據集。
- MMLU 涵蓋初等數學、歷史和計算機科學等不同領域的 57 個多選 QA 任務。
工具:研究者使用 SerpAPI1 構建了一個谷歌搜索工具,該工具會從「答案框」、「答案片段」、「高亮單詞」或「第一個結果片段」中返回第一個存在的條目,從而確保回復簡短且相關。他們發現,這樣一個簡單的工具足以滿足不同任務的基本質量保證需求,并提高了微調模型的易用性和通用性。
研究者研究了三個 LM 系列:OpenAI GPT、Llama-2 以及 CodeLlama。
微調方法:研究者在大多數微調實驗中使用了低秩自適應(Low-Rank Adaptation,LoRA),但在某些比較中也使用了全模型微調。考慮到語言代理微調的各種基本因素,他們將實驗分為三個部分,復雜程度依次增加:
- 在單一任務中使用單一提示方法進行微調;
- 在單一任務中使用多種方法進行微調;
- 在多個任務中使用多種方法進行微調。
1.在單一任務中使用單一提示方法進行微調
研究者探討了使用來自單一任務(HotpotQA)和單一提示方法(ReAct)的數據進行微調的問題。通過這種簡單而可控的設置,他們證實了微調相對于提示的各種優勢(性能、效率、穩健性、泛化),并研究了不同 LM、數據大小和微調方法的效果。
如表 2 所示,微調能持續、顯著地改善 HotpotQA EM 的提示效果。雖然較弱的 LM 從微調中獲益更多(例如,Llama-2-7B 提高了 77%),但即使是像 GPT-3.5 這樣強大的 LM 也能通過微調將性能提高 25%,這清楚地表明了從更多樣本中學習的好處。與表 1 中的強提示基線相比,研究者發現經過微調的 Llama-2-13B 優于所有 GPT-3.5 提示方法。這表明對小型開源 LM 進行微調的效果可能優于對更強大的商用 LM 進行提示的效果。
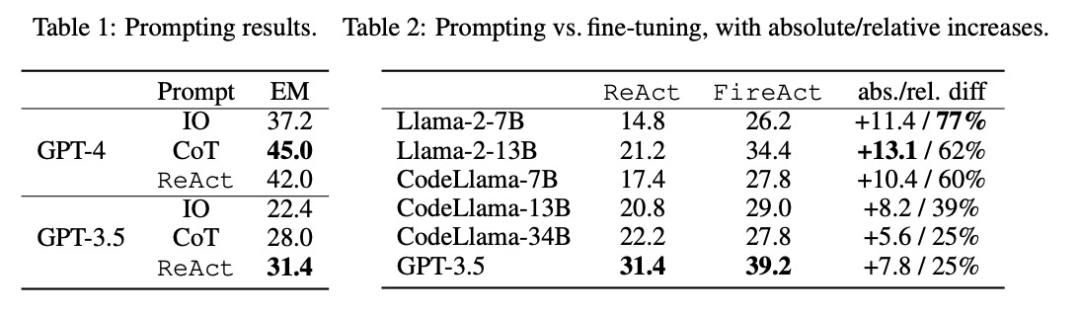
在智能體推理過程中,微調的成本更低,速度更快。由于微調 LM 不需要少量的上下文示例,因此其推理效率更高。例如,表 3 的第一部分比較了微調推理與 shiyongtishideGPT-3.5 推理的成本,發現推理時間減少了 70%,總體推理成本也有所降低。

研究者考慮到一個簡化且無害的設置,即搜索 API 有 0.5 的概率返回「None」或隨機搜索響應,并詢問語言智能體是否仍能穩健地回答問題。如表 3 第二部分所示,「None」的設置更具挑戰性,它使 ReAct EM 降低了 33.8%,而 FireAct EM 僅降低了 14.2%。這些初步結果表明,更多樣化的學習支持對于提高穩健性非常重要。
表 3 的第三部分顯示了經過微調的和使用提示的 GPT-3.5 在 Bamboogle 上的 EM 結果。雖然經過 HotpotQA 微調或使用提示的 GPT-3.5 都能合理地泛化到 Bamboogle,但前者(44.0 EM)仍然優于后者(40.8 EM),這表明微調具有泛化優勢。
2.在單一任務中使用多種方法進行微調
作者將 CoT 和 Reflexion 與 ReAct 集成,測試了對于在單一任務(HotpotQA)中使用多種方法進行微調的性能。對比 FireAct 和既有方法的在各數據集中的得分,他們有以下發現:
首先,使用多種方法微調提高了智能體的靈活性。如圖 5 所示,在定量結果之外,研究者向我們展示了兩個示例問題,以說明多方法 FireAct 微調的好處。第一個問題比較簡單,但僅使用 ReAct 微調的智能體搜索了一個過于復雜的查詢,導致注意力分散,提供了錯誤的答案。相比之下,同時使用 CoT 和 ReAct 微調的智能體自信地選擇依靠自己的內部知識,在一輪內完成了任務。第二個問題難度更高,僅使用 ReAct 微調的智能體未搜索出有用的信息。相比之下,同時使用 Reflexion 和 ReAct 微調的智能體在搜索碰壁時進行了反思,并改變了搜索策略,從而得到了正確答案。靈活地為不同問題選擇解決方案,是 FireAct 相較于提示等微調方法的關鍵優勢。

其次,使用多方法微調不同的語言模型將產生不同的影響。如表 4 所示,綜合使用多種智能體進行微調并不總是能帶來提升,最優的方法組合取決于基礎語言模型。例如,對于 GPT-3.5 和 Llama-2 模型,ReAct+CoT 優于 ReAct,但對于 CodeLlama 模型則不同。對于 CodeLlama7/13B,ReAct+CoT+Reflexion 的效果最差,但 CodeLlama-34B 卻能取得最好的效果。這些結果表明,還需進一步研究基礎語言模型和微調數據之間的相互作用。
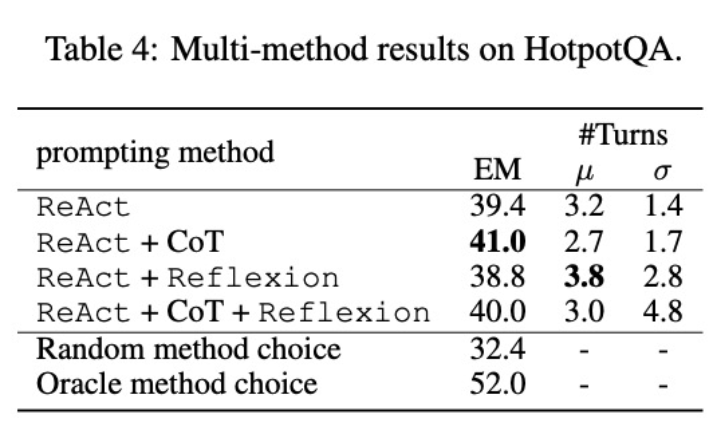
為了進一步了解組合了多種方法的智能體是否能夠根據任務選擇恰當的解決方案,研究者計算了在推理過程中隨機選擇方法的得分。該得分(32.4)遠低于所有組合了多種方法的智能體,這表明選擇解決方案并非易事。然而,每個實例的最佳方案的得分也僅為 52.0,這表明在提示方法選擇方面仍有提升空間。
3.在多個任務中使用多種方法進行微調
到這里,微調只使用了 HotpotQA 數據,但有關 LM 微調的實證研究表明,混合使用不同的任務會有益處。研究者使用來自三個數據集的混合訓練數據對 GPT-3.5 進行微調:HotpotQA(500 個 ReAct 樣本,277 個 CoT 樣本)、StrategyQA(388 個 ReAct 樣本,380 個 CoT 樣本)和 MMLU(456 個 ReAct 樣本,469 個 CoT 樣本)。
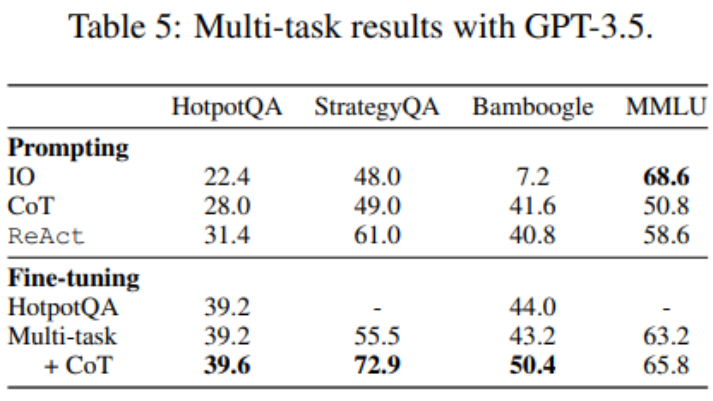
如表 5 所示,加入 StrategyQA/MMLU 數據后,HotpotQA/Bamboogle 的性能幾乎保持不變。一方面,StrategyQA/MMLU 軌跡包含的問題和工具使用策略大不相同,這使得遷移變得困難。另一方面,盡管分布發生了變化,但加入 StrategyQA/MMLU 并沒有影響 HotpotQA/Bamboogle 的性能,這表明微調一個多任務代理以取代多個單任務代理是未來可以發展的方向。當研究者從多任務、單一方法微調切換到多任務、多方法微調時,他們發現所有任務的性能都有所提高,這再次明確了多方法代理微調的價值。
想要了解更多技術細節,請閱讀原文。
參考鏈接:
- https://twitter.com/Tisoga/status/1739813471246786823
- https://www.zhihu.com/people/eyew3g