













字節具身智能新成果:用大規模視頻數據訓練GR-1,復雜任務輕松應對
最近 GPT 模型在 NLP 領域取得了巨大成功。GPT 模型首先在大規模的數據上預訓練,然后在特定的下游任務的數據上微調。大規模的預訓練能夠幫助模型學習可泛化的特征,進而讓其輕松遷移到下游的任務上。
但相比自然語言數據,機器人數據是十分稀缺的。而且機器人數據包括了圖片、語言、機器人狀態和機器人動作等多種模態。為了突破這些困難,過去的工作嘗試用 contrastive learning [1] 和 masked modeling [2] 等方式來做預訓練以幫助機器人更好的學習。
在最新的研究中,ByteDance Research 團隊提出 GR-1,首次證明了通過大規模的視頻生成式預訓練能夠大幅提升機器人端到端多任務操作方面的性能和泛化能力。實驗證明這種預訓練方法可以大幅提升模型表現。在極具挑戰的 CALVIN 機器人操作仿真數據集上,GR-1 在 1) 多任務學習 2) 零樣本場景遷移 3) 少量數據 4) 零樣本語言指令遷移上都取得了 SOTA 的結果。在真機上,經過視頻預訓練的 GR-1 在未見過的場景和物體的表現也大幅領先現有方法。

GR-1 在 CALVIN 中連續完成多個任務

GR-1 在真機上端到端完成多種任務

- 論文地址:https://arxiv.org/abs/2312.13139
- 論文網站:https://gr1-manipulation.github.io
方法
GR-1 是一個端到端的機器人操作模型,采用了 GPT 風格的 transformer 作為模型架構。GR-1 首先在大規模視頻數據上進行視頻預測的預訓練。預訓練結束后,GR-1 在機器人數據上微調。微調的訓練任務包含未來幀的預測和機器人動作的預測。

GR-1 用來自 Ego4D [3] 數據的 8M 圖片來做視頻生成式預訓練。在預訓練階段,GR-1 的輸入包括視頻片段和描述視頻的文字。文字信息用 CLIP [4] 的文字編碼器編碼。視頻中的圖片用 MAE [5] 編碼,然后通過 perciever resampler [6] 來減少 token 的個數。輸出端 GR-1 在每一個時間戳通過學習 [OBS] token 來輸出未來幀的圖片。[OBS] 對應的輸出通過一個 transformer 來解碼成圖片。在預訓練階段,GR-1 采用了 mean squared error (MSE) 的損失函數。

在機器人數據微調階段,GR-1 的輸入包括任務語言指令,機器人狀態和觀測圖片。其中機器人狀態包括 6 維機器人位姿和夾抓的開閉狀態。機器人狀態通過 MLP 來編碼。輸出包括未來幀的圖片和機器人動作。語言和圖片的編碼方式與預訓練階段相同。輸出端 GR-1 通過學習 [ACT] token 來預測下一個時間戳機器人的動作。機械臂動作的損失函數采用 smooth L1 loss;夾抓動作的損失函數采用 binary cross entropy loss。

實驗
作者在 CALVIN 仿真平臺上做了大量實驗來驗證 GR-1 的性能。CALVIN 是一個極具挑戰性的機器人多任務操作仿真平臺。其中包括 34 個通過語言指令的操作任務和 A, B, C, D 四個不同的環境。
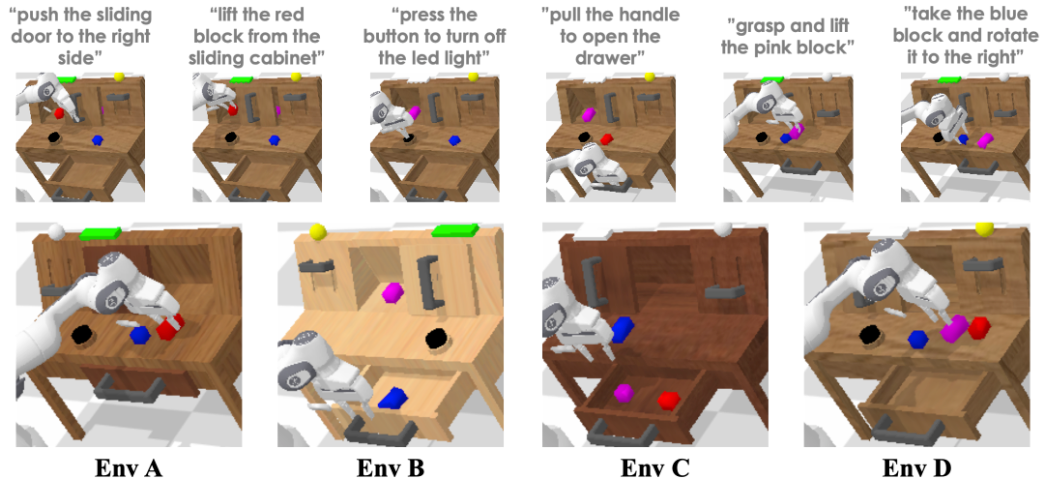
在 ABCD->D 實驗中,機器人在來自 A, B, C, D 四個環境的數據上訓練,并在 D 中測試。在 ABC->D 實驗中,機器人在來自 A, B, C 三個環境的數據上訓練,并在 D 中測試。這個實驗旨在測試 GR-1 應對零樣本場景遷移的能力。測試中,機器人需要連續完成 5 個任務。表中展示了不同方法在連續完成 1,2,3,4,5 個任務的成功率和平均完成的任務數量。GR-1 在兩個實驗中都超過了現有方法并在零樣本場景遷移上大幅領先。

該工作還進行了小數據集的實驗以理解 GR-1 在數據比較少的時候的表現。在 10% data 實驗中,作者把 34 個任務中的每個任務的訓練軌跡控制在 66 條。總軌跡數約為 ABCD->D 實驗中的 10%。為了測試 GR-1 應對未知語言的能力,作者用 GPT-4 為每個任務生成了 50 條新的未見過的語言指令來測試。GR-1 在小數據集和未知語言指令的設置中都超越了現有方法。

GR-1 真機實驗包括了移動物體和開關抽屜,如下圖所示:
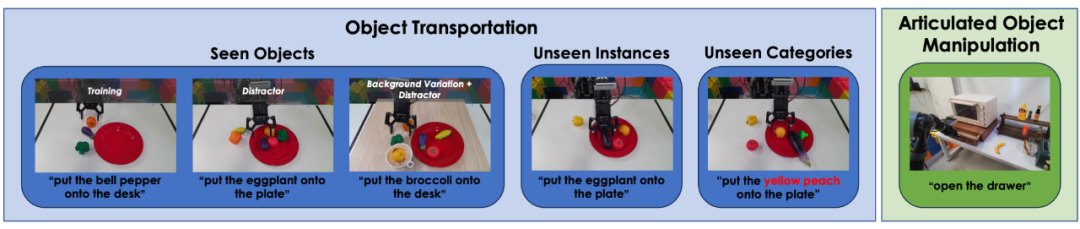
移動物體實驗指令包括將物體移動到盤子 / 桌面上。訓練數據中包括移動一個茄子、西蘭花和彩椒(如上圖最左所示)。作者首先在這些訓練數據中見過的物體上做實驗。在這個設置下,作者還測試了加入了干擾物和背景變化的實驗。



作者還在訓練數據中未見過的物體上做了實驗。未見的物體包括未見過的物體實例(一組在訓練數據中未見過的茄子、西蘭花和彩椒)和未見過的物體種類(西紅柿和黃桃)。


以下為開關抽屜的實驗:


如下表所示,GR-1 在真機實驗中大幅領先對比的現有方法。

在消融實驗中,作者對比了去掉未來幀預測和保留未來幀預測但去掉預訓練的模型的能力。結果表明預測未來幀和預訓練兩者都對 GR-1 學習魯棒的機器人操作起到了關鍵作用。在預測動作的同時加入未來幀的預測能幫助 GR-1 學習根據語言指令來預測未來場景變化的能力。這種能力正是機器人操作中需要的:根據人的語言指令來預測場景中應用的變化能夠指導機器人動作的生成。而大規模視頻數據的預訓練則能幫助 GR-1 學習魯棒可泛化的預測未來的能力。
結論
GR-1 首次證明了大規模視頻生成式預訓練能幫助機器人學習復雜的多任務操作。GR-1 首先在大規模視頻數據上預訓練然后在機器人數據上進行微調。在仿真環境和真機實驗中,GR-1 都取得了 SOTA 的結果,并在極具挑戰的零樣本遷移上表現出魯棒的性能。

























