













這是GPT-4變笨的新解釋
自發布以來,曾被認為是世界上最強大的 GPT-4 也經歷了多場「信任危機」。
如果說今年早些時候那次「間歇式降智」與 OpenAI 重新設計 GPT-4 架構有關,前段時間的「變懶」傳聞就更搞笑了,有人測出只要告訴 GPT-4「現在是寒假」,它就會變得懶懶散散,仿佛進入了一種冬眠狀態。
大模型變懶、變笨,具體是指模型在新任務上的零樣本性能變差。盡管上述原因聽起來很有趣,但問題到底怎么解決呢?
在最近的一篇論文中,加州大學圣克魯斯分校研究者的新發現或可解釋 GPT-4 性能下降的深層原因:

「我們發現,在訓練數據創建日期之前發布的數據集上,LLM 的表現出奇地好于之后發布的數據集。」
它們在「見過的」任務上表現出色,而在新任務上則表現糟糕。這意味著,LLM 只是基于近似檢索的模仿智能方法,主要是記憶東西,而沒有任何程度的理解。
說白了,就是 LLM 的泛化能力「沒有說的那么強」—— 基礎不扎實,實戰總有出紕漏的時候。
造成這種結果的一大原因是「任務污染」,這是數據污染的其中一種形式。我們以前熟知的數據污染是測試數據污染,即在預訓練數據中包含測試數據示例和標簽。而「任務污染」是在預訓練數據中加入任務訓練示例,使零樣本或少樣本方法中的評估不再真實有效。
研究者在論文中首次對數據污染問題進行了系統分析:

論文鏈接:https://arxiv.org/pdf/2312.16337.pdf
看完論文,有人「悲觀」地表示:
這是所有不具備持續學習能力的機器學習(ML)模型的命運,即 ML 模型權重在訓練后會被凍結,但輸入分布會不斷變化,如果模型不能持續適應這種變化,就會慢慢退化。
這意味著,隨著編程語言的不斷更新,基于 LLM 的編碼工具也會退化。這就是為什么你不必過分依賴這種脆弱工具的原因之一。
不斷重新訓練這些模型的成本很高,遲早有人會放棄這些低效的方法。
目前還沒有任何 ML 模型能夠可靠地持續適應不斷變化的輸入分布,而不會對之前的編碼任務造成嚴重干擾或性能損失。
而這正是生物神經網絡所擅長的領域之一。由于生物神經網具有強大的泛化能力,學習不同的任務可以進一步提高系統的性能,因為從一項任務中獲得的知識有助于改善整個學習過程本身,這就是所謂的「元學習」。
「任務污染」的問題有多嚴重?我們一起來看下論文內容。
模型和數據集
實驗所使用的模型有 12 個(如表 1 所示),其中 5 個是專有的 GPT-3 系列模型,7 個是可免費獲取權重的開放模型。
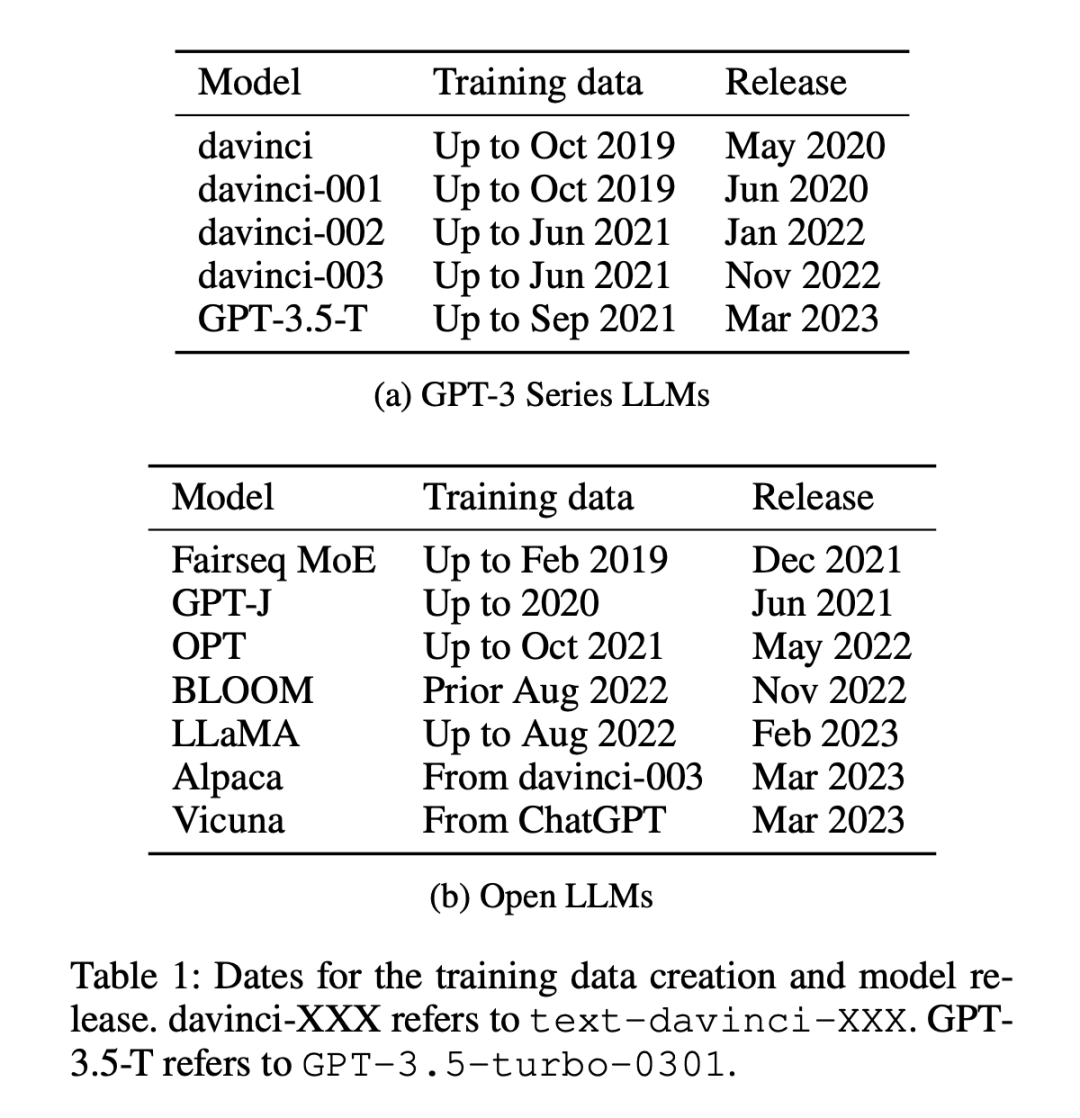
數據集分為兩類:2021 年 1 月 1 日之前或之后發布的數據集,研究者使用這種劃分方法來分析舊數據集與新數據集之間的零樣本或少樣本性能差異,并對所有 LLM 采用相同的劃分方法。表 1 列出了每個模型訓練數據的創建時間,表 2 列出了每個數據集的發布日期。
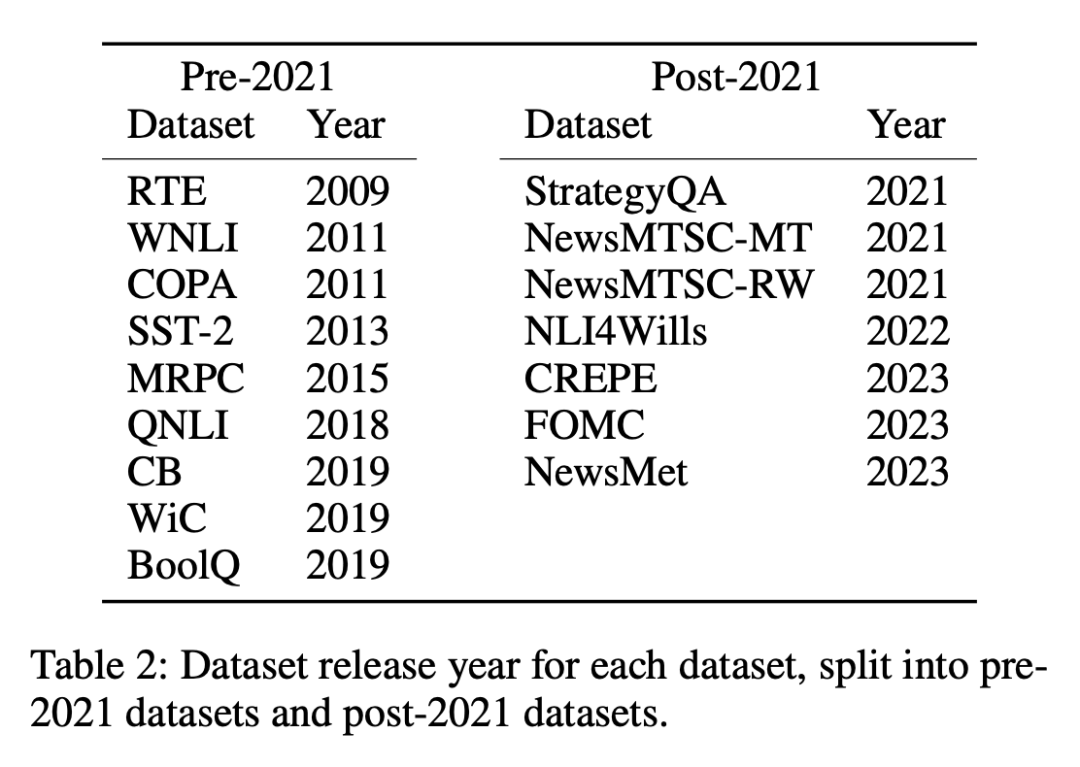
上述做法的考慮是,零樣本和少樣本評估涉及模型對其在訓練期間從未見過或僅見過幾次的任務進行預測,其關鍵前提是模型事先沒有接觸過要完成的特定任務,從而確保對其學習能力進行公平的評估。然而,受污染的模型會給人一種未接觸或僅接觸過幾次的能力的假象,因為它們在預訓練期間已經接受過任務示例的訓練。在按時間順序排列的數據集中,檢測這種不一致性會相對容易一些,因為任何重疊或異常都會很明顯。
測量方法
研究者采用了四種方法來測量「任務污染」:
- 訓練數據檢查:在訓練數據中搜索任務訓練示例。
- 任務示例提取:從現有模型中提取任務示例。只有經過指令調優的模型才能進行提取,這種分析也可用于訓練數據或測試數據的提取。注意,為了檢測任務污染,提取的任務示例不必與現有的訓練數據示例完全匹配。任何演示任務的示例都表明零樣本學習和少樣本學習可能存在污染。
- 成員推理:此方法僅適用于生成任務。檢查輸入實例的模型生成內容是否與原始數據集完全相同。如果完全匹配,就可以推斷它是 LLM 訓練數據中的一員。這與任務示例提取不同,因為生成的輸出會被檢查是否完全匹配。開放式生成任務的精確匹配強烈表明模型在訓練過程中見過這些示例,除非模型「通靈」,知道數據中使用的確切措辭。(注意,這只能用于生成任務。)
- 時序分析:對于在已知時間范圍內收集訓練數據的模型集,在已知發布日期的數據集上測量其性能,并使用時序證據檢查污染證據。
前三種方法精度高,但召回率低。如果能在任務的訓練數據中找到數據,那么就能確定模型曾見過示例。但由于數據格式的變化、用于定義任務的關鍵字的變化以及數據集的大小,使用前三種方法找不到污染證據并不能證明沒有污染。
第四種方法,按時間順序分析的召回率高,但精確度低。如果由于任務污染而導致性能較高,那么按時間順序分析就有很大機會發現它。但隨著時間的推移,其他因素也可能導致性能提高,因此精確度較低。
因此,研究者采用了所有四種方法來檢測任務污染,發現了在某些模型和數據集組合中存在任務污染的有力證據。
他們首先對所有測試過的模型和數據集進行時序分析,因為它最有可能發現可能的污染;然后使用訓練數據檢查和任務示例提取尋找任務污染的進一步證據;接下來觀察了 LLM 在無污染任務中的性能,最后使用成員推理攻擊進行額外分析。
重點結論如下:
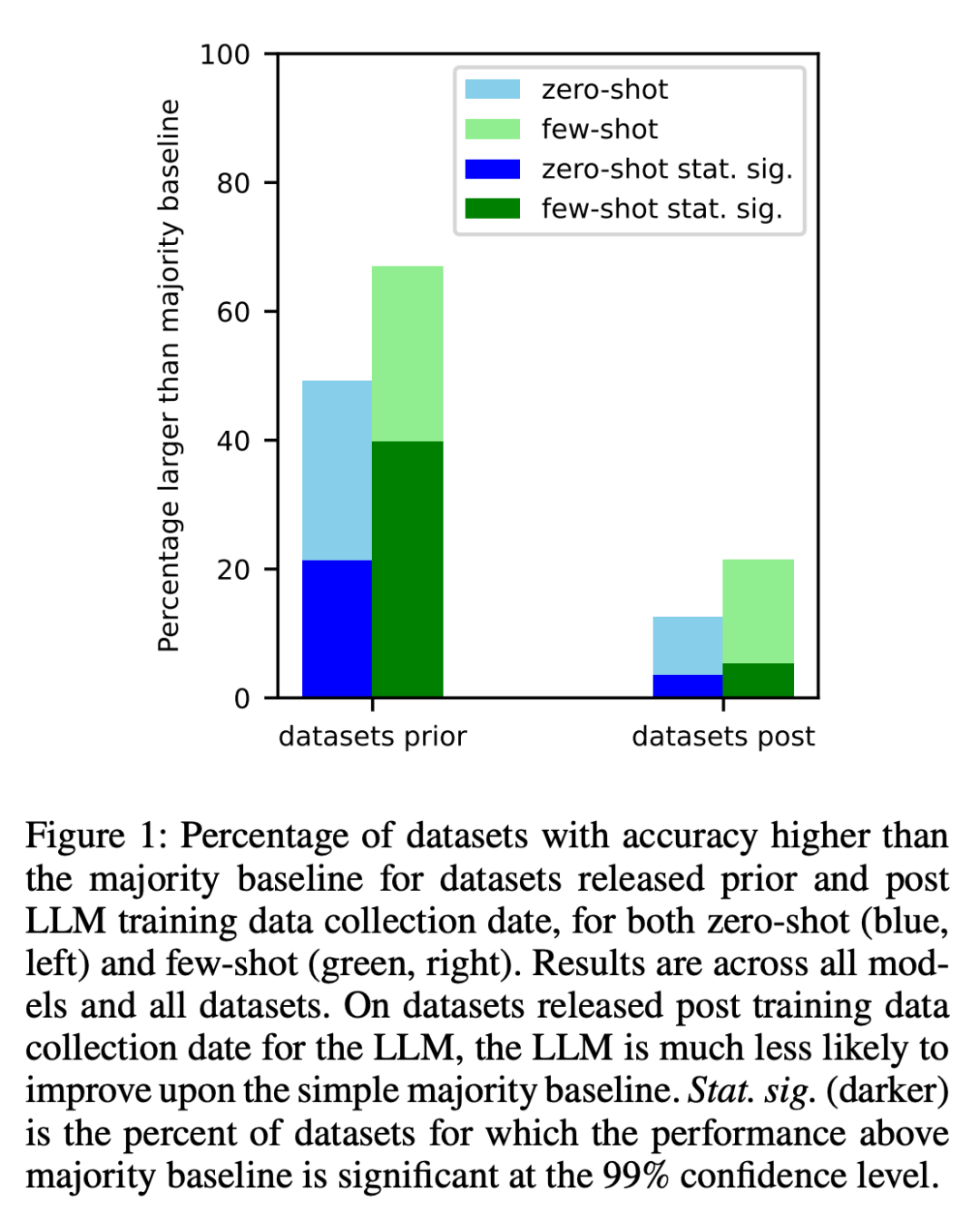
1、研究者對每個模型在其訓練數據在互聯網上抓取之前創建的數據集和之后創建的數據集進行了分析。結果發現,對于在收集 LLM 訓練數據之前創建的數據集,其性能高于大多數基線的幾率明顯更高(圖 1)。
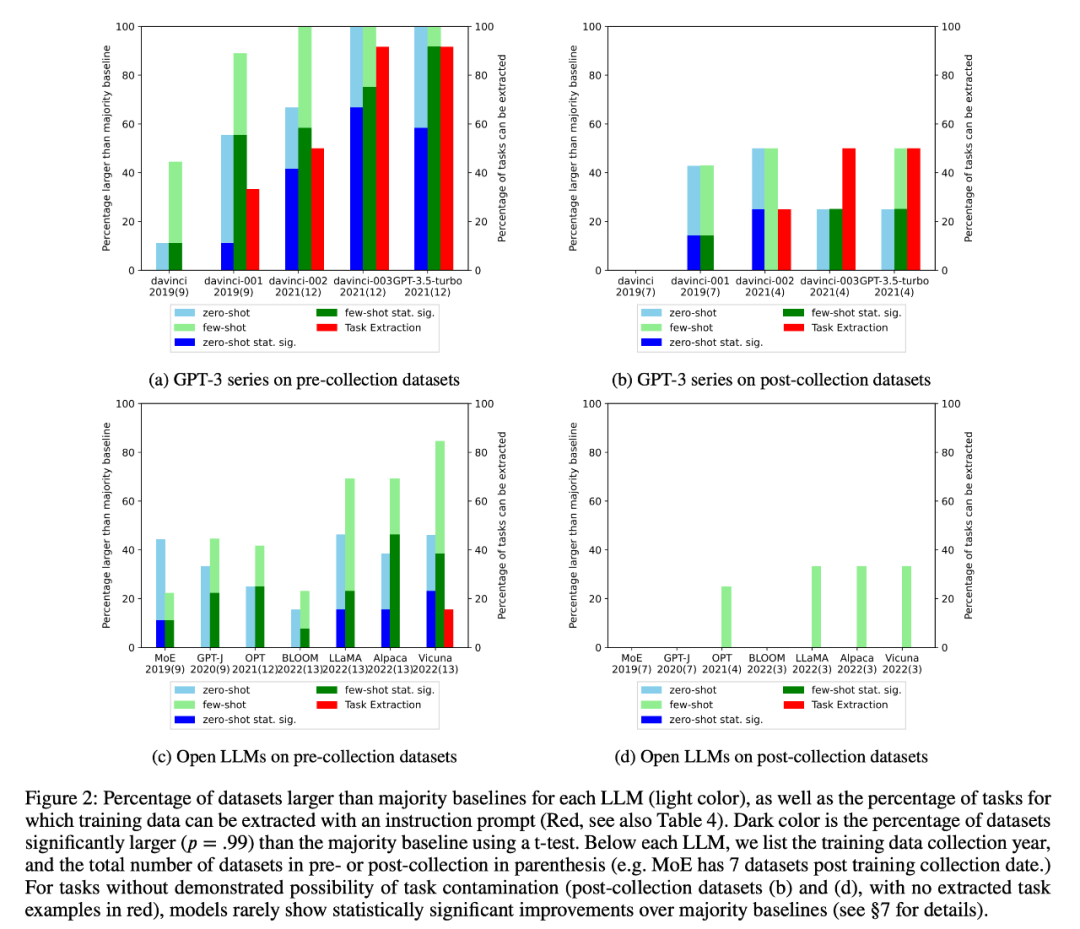
2、研究者進行了訓練數據檢查和任務示例提取,以查找可能存在的任務污染。結果發現,對于不可能存在任務污染的分類任務,在一系列任務中,模型很少比簡單多數基線有統計意義上的顯著提高,無論是零樣本還是少樣本(圖 2)。
研究者也檢查了 GPT-3 系列和開放 LLM 的平均表現隨時間的變化,如圖 3:

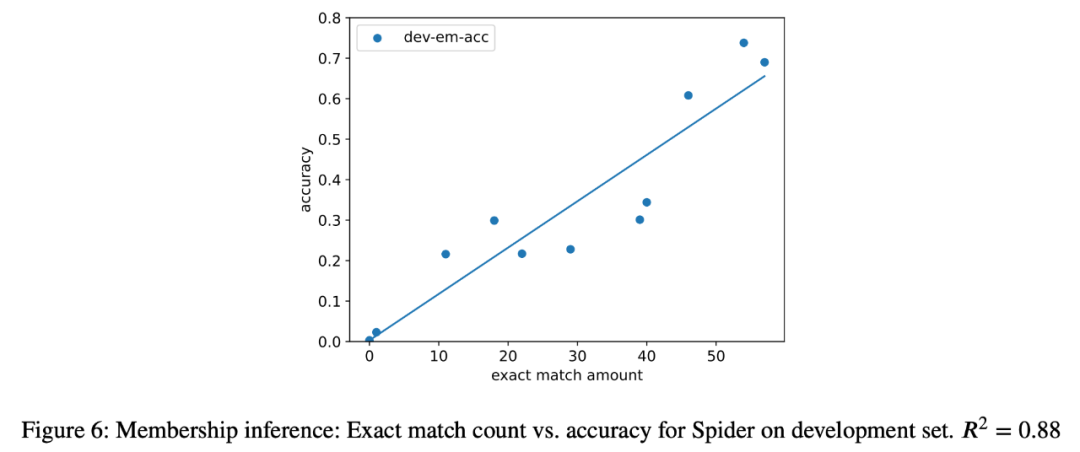
3、作為案例研究,研究者還嘗試對分析中的所有模型進行語義解析任務的成員推理攻擊,發現在最終任務中,提取實例的數量與模型的準確性之間存在很強的相關性(R=.88)(圖 6)。這有力地證明了在這一任務中零樣本性能的提高是由于任務污染造成的。
4、研究者還還仔細研究了 GPT-3 系列模型,發現可以從 GPT-3 模型中提取訓練示例,而且從 davinci 到 GPT-3.5-turbo 的每個版本中,可提取的訓練示例數量都在增加,這與 GPT-3 模型在該任務上零樣本性能的提高密切相關(圖 2)。這有力地證明了從 davinci 到 GPT-3.5-turbo 的 GPT-3 模型在這些任務上的性能提高是由于任務污染造成的。






























