譯者 | 朱先忠
審校 | 重樓
簡介
近年來,大型語言模型的發展突飛猛進。BERT成為最受歡迎和最有效的模型之一,可以高精度地解決各種自然語言處理(NLP)任務。繼BERT模型之后,一組其他的模型也先后出現并各自展示出優秀的性能。
不難看到一個明顯趨勢是,隨著時間的推移,大型語言模型(LLM)往往會因其訓練的參數和數據數量呈指數級增加而變得更加復雜。深度學習研究表明,這種技術通常會帶來更好的運行結果。然而,遺憾的是,盡管機器學習世界已經克服了不少關于大型語言模型相關的問題;但是,可擴展性的問題已經成為有效訓練、存儲和使用大型語言模型的主要障礙。
考慮到上述問題,人們已經開發出不少的壓縮大型語言模型的特殊方法。在這篇文章中,我們將重點討論轉換器蒸餾方法,這種方法誕生了名為TinyBERT的一個迷你版本的BERT模型。此外,我們還將介紹TinyBERT模型的學習過程,以及使TinyBERT模型變得如此強大的幾個微妙原因。本文基于TinyBERT的官方論文整理而成。
主要思想
在最近的文章中,我們已經討論了DistilBERT模型中蒸餾技術的工作原理。簡而言之,蒸餾技術的主要思想是:修改損失函數目標,以便使學生模型和教師模型的預測結果相似。在DistilBERT模型中,損失函數比較學生模型和教師模型的輸出分布,并兼顧兩個模型的輸出嵌入(針對相似性損失)。
有關DistilBERT模型的更多的細節,請參考文章《Large Language Models: DistilBERT — Smaller, Faster, Cheaper and Lighter》,地址是:
“https://towardsdatascience.com/distilbert-11c8810d29fc?source=post_page-----1a928ba3082b--------------------------------”。此文的主要內容介紹了BERT模型壓縮的秘密,目標是實現師生模型框架效率的最大化。
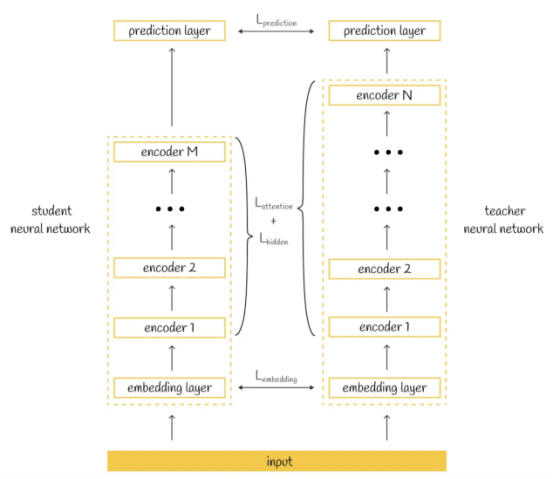
從表面上看,TinyBERT模型中的蒸餾框架與DistilBERT模型沒有太大變化:再次修改了損失函數,目標是使學生模型模仿教師模型。然而,在TinyBERT模型的情況下,它更進了一步:損失函數不僅考慮了師生兩個模型產生的結果,還考慮了如何獲得預測結果的問題。根據TinyBERT模型論文作者介紹,TinyBERT損失函數由三個部分組成,它們涵蓋了師生兩個模型的不同方面:
- 嵌入層的輸出
- 從轉換器層導出的隱藏狀態和注意力矩陣
- 預測層輸出的logits值
 轉換器蒸餾損失函數示意圖
轉換器蒸餾損失函數示意圖
那么,比較師生兩種模型的隱藏狀態有什么意義呢?通過包括隱藏狀態和注意力的輸出結果,注意力矩陣使得學生模型有可能學習教師模型的隱藏層內容,從而構建與教師模型相似的層。這樣,提取的模型不僅可以模仿原始模型的輸出,而且模仿其內部行為。
那么,為什么復制教師模型的行為很重要呢?研究人員聲稱,通過BERT模型學習到的注意力權重有利于捕捉語言結構。因此,它們對另一種模式的蒸餾也給了學生模型更多獲得語言知識的機會。
層映射
TinyBERT模型僅代表一種較小的BERT版本,具有較少的編碼器層。現在,不妨讓我們將BERT模型層數定義為N,將TinyBERT模型層數定義為M。鑒于層數不同,如何計算蒸餾損失值的問題尚不明確。
為此,引入了一個特殊函數n=g(m)來定義哪個BERT模型層n用于將其知識提取到TinyBERT模型中的相應層m。然后,所選擇的BERT層用于訓練期間的損失值計算。
引入的函數n=g(m)具有兩個推理約束:
- g(0)=0。這意味著,BERT模型中的嵌入層被直接映射到TinyBERT模型中的嵌入圖層,這是有意義的。
- g(M+1)=N+1。該等式指示,BERT模型中的預測層被映射到TinyBERT模型中的預測層。對于所有其他TinyBERT模型中滿足條件1≤m≤m的那些層,需要映射n=g(m)的相應函數值。現在,假設已經定義好了這樣的函數。
有關TinyBERT模型設置的問題,將在本文稍后進行研究。
轉換器蒸餾
1.嵌入層蒸餾
原始輸入在被傳遞到模型之前,首先被標記化,然后被映射到學習的嵌入層。然后,這些嵌入層被用作模型的第一層。所有可能的嵌入層都可以用矩陣的形式表示。為了比較學生模型和教師模型的嵌入層有多大的不同,可以在他們各自的嵌入矩陣E上使用標準回歸度量。例如,轉換器蒸餾使用均方誤差(MSE)作為回歸度量。
由于學生模型和教師模型的嵌入矩陣具有不同的大小,因此不可能通過使用均方誤差來明智地比較它們的元素。這就解釋了為什么學生模型嵌入矩陣乘以可學習的權重矩陣W,從而導致結果矩陣與教師模型嵌入矩陣具有相同的形狀。
 嵌入層蒸餾損失函數。
嵌入層蒸餾損失函數。
由于學生模型和教師模型的嵌入空間是不同的,矩陣W在將學生模型的嵌入空間線性轉換為教師模型嵌入空間方面也起著重要作用。
2.轉換器層蒸餾
 轉換器層蒸餾損失函數可視化展示
轉換器層蒸餾損失函數可視化展示
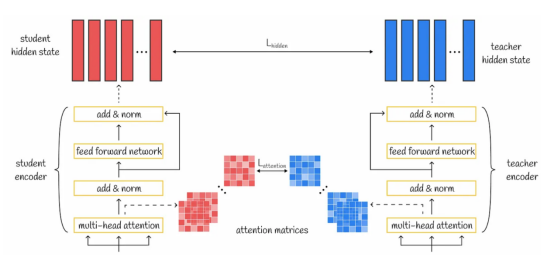
2A. 注意力層蒸餾
轉換器中的多頭注意力機制的核心是生成包含豐富語言知識的多個注意力矩陣。通過轉移教師模型的注意力權重,學生模型也可以理解重要的語言概念。為了實現這一思想,使用損失函數來計算學生模型和教師模型注意力權重之間的差異。
在TinyBERT模型中,考慮了所有的注意力層,并且每一層的最終損失值等于所有頭部的相應學生模型和教師模型注意力矩陣之間的均方誤差值之和。
 注意層蒸餾損失函數計算公式
注意層蒸餾損失函數計算公式
值得注意的是,用于注意力層提取的注意力矩陣A是未歸一化的,而不是它們的softmax輸出softmax(A)。根據研究人員的說法,這種微妙之處有助于更快地收斂并提高性能。
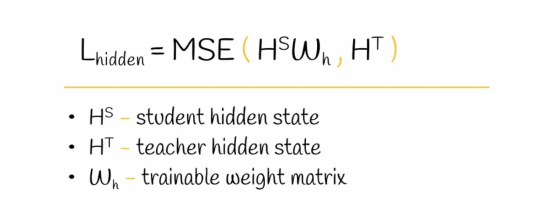
2B. 隱藏層蒸餾
為了實現獲取豐富語言知識的想法,蒸餾操作也被應用到轉換器層的輸出上。
 隱藏層蒸餾損失函數計算公式。
隱藏層蒸餾損失函數計算公式。
這里,權重矩陣W起到與上述用于嵌入層蒸餾的權重矩陣相同的作用。
3.預測層蒸餾
最后,為了使學生模型再現教師模型的輸出結果,使用了預測層損失函數。它包括計算兩個模型預測的logit向量之間的交叉熵。
 預測層蒸餾損失函數計算公式
預測層蒸餾損失函數計算公式
值得注意的是,有些情況下,logits要除以控制輸出分布的平滑度的溫度參數T。在TinyBERT模型中,溫度參數T設置為1。
損失方程
在TinyBERT模型中,根據其類型特征,每一層都有自己的損失函數。考慮到某些層或多或少的重要性作用,將相應的損失值乘以常數a。最終的損失函數等于所有TinyBERT模型層的損失值的加權和。
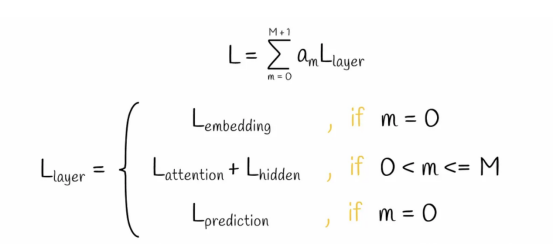 TinyBERT模型中的損失函數計算公式
TinyBERT模型中的損失函數計算公式
大量實驗表明,在三種損失分量中,轉換器層蒸餾損失對模型性能的影響最大。
模型訓練
需要注意的是,大多數自然語言處理模型(包括BERT)開發過程可大致劃分為兩個階段:
- 在一個大型數據語料庫上對模型進行預訓練,以獲得語言結構的一般知識。
- 在另一個數據集上對模型進行微調,以解決特定的下游任務。
遵循與此同樣的思想,研究人員研發了一個新的框架TinyBERT,它的學習過程也是由類似上面的兩個階段組成的。在這兩個訓練階段中,使用轉換器蒸餾算法將BERT模型知識轉換成TinyBERT模型。
階段一:普通蒸餾。TinyBERT作為一個教師模型,通過預先訓練(無需微調)的BERT模型獲得了豐富的語言結構常識。通過使用更少的層和參數,在這個階段之后,TinyBERT模型的性能通常比BERT模型差一些。
階段二:特定任務的蒸餾。這一次,微調版的BERT模型扮演了教師模型的角色。為了進一步提高性能,正如研究人員所提出的,在訓練數據集上應用了數據增強方法。實驗結果表明,經過特定任務的蒸餾操作后,TinyBERT模型在BERT模型方面取得了相當的性能。
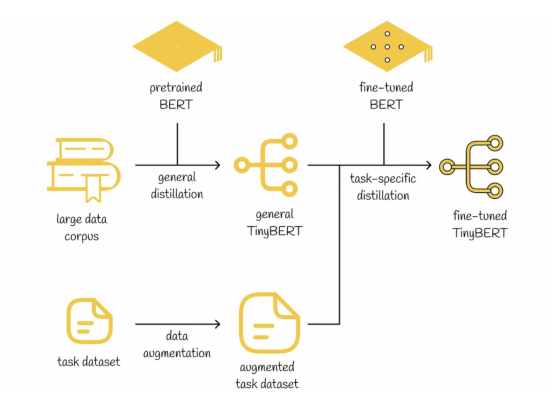 TinyBERT模型訓練流程示意圖
TinyBERT模型訓練流程示意圖
數據增強
針對特定任務的蒸餾,引入了一種特殊的數據增強技術。在這種數據增強技術中,首先從給定的數據集中提取序列,然后以下列兩種方式之一替換一定百分比的單詞:
- 如果某單詞被標記為同一個單詞,則該單詞由BERT模型預測,并且用預測后的結果單詞替換序列中的原始單詞。
- 如果單詞被標記為幾個子單詞,那么這些子單詞將被最相似的GloVe嵌入(全局向量的詞嵌入:Global Vectors for Word Representation)所取代。
盡管模型大小顯著減小,但是所描述的數據增強機制通過允許TinyBERT學習更多不同的示例,對其性能產生了很大影響。
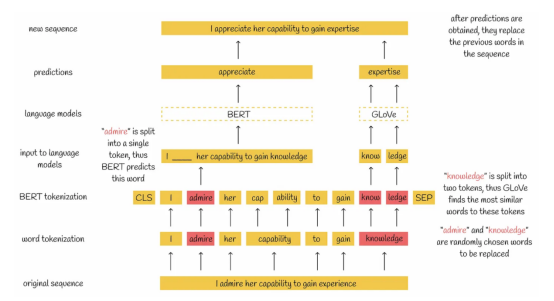 數據增強技術示意圖
數據增強技術示意圖
模型設置
由于只有14.5M個參數,TinyBERT模型比基礎型BERT模型小約7.5倍。它們的詳細比較如下圖所示:
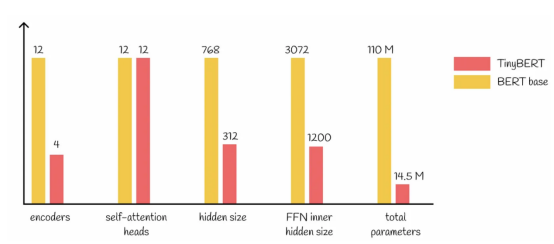 基礎BERT模型與TinyBERT模型比較
基礎BERT模型與TinyBERT模型比較
對于層映射,論文作者提出了一種統一的策略。根據該策略,層映射函數將每個TinyBERT層映射到按序排序的每三個為一組的BERT層中的第一個:g(m)=3*m。論文作者還研究了其他的策略(如采用所有底部或頂部BERT層),但僅有統一策略顯示出最佳實驗結果。這個結論似乎是比較合乎邏輯的,因為它允許從不同的抽象層轉移知識,使轉移的信息更加多樣化。
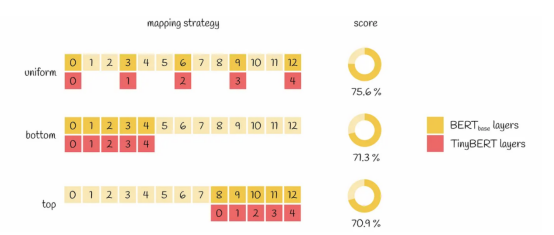 基于不同的層映射策略情況:圖中展示了基于GLUE數據集的性能比較結果
基于不同的層映射策略情況:圖中展示了基于GLUE數據集的性能比較結果
就訓練實現過程方面,TinyBERT模型是在英語維基百科(2500M個單詞)上訓練的,其大多數超參數與BERT模型庫中使用的相同。
結論
轉換器蒸餾是自然語言處理中的一項重要措施。考慮到基于轉換器的模型是目前機器學習中最強大的模型之一,我們可以通過應用轉換器蒸餾來有效地壓縮它們來進一步開發利用它們。這方面最偉大的例子之一是TinyBERT模型,它在BERT模型基礎上壓縮了7.5倍。
盡管參數大幅減少,但實驗表明,TinyBERT模型的性能與BERT基礎模型基本相當:在GLUE基準數據集上的測試結果表明,TinyBERT模型獲得77.0%的得分,與得分為79.5%的BERT模型相距并不遠。顯然,這是一個驚人的成就!最后,其他的一些流行的壓縮技術,如量化或修剪等,都可以應用于TinyBERT模型壓縮算法,從而使此模型體積變得更小。
除非另有說明,否則本文中所有圖片均由作者本人提供。
參考資料
- TinyBERT: Distilling BERT for Natural Language Understanding:https://arxiv.org/pdf/1909.10351.pdf。
譯者介紹
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。
原文標題:Large Language Models: TinyBERT — Distilling BERT for NLP,作者:Vyacheslav Efimov