詳解數(shù)據(jù)庫分片,大幅提升Spring Boot查詢MySQL性能
背景
微服務(wù)項(xiàng)目中通常包含各種服務(wù)。其中一項(xiàng)服務(wù)與存儲(chǔ)用戶相關(guān)的數(shù)據(jù)有關(guān)。我們使用Spring Boot作為后端,使用MySQL數(shù)據(jù)庫。
目標(biāo)
隨著用戶基數(shù)的增長,服務(wù)性能受到了影響,延遲也上升了。由于只有一個(gè)數(shù)據(jù)庫和一張表,許多查詢和更新由于鎖異常返回錯(cuò)誤。此外,隨著數(shù)據(jù)庫的規(guī)模不斷擴(kuò)大,性能進(jìn)一步下降。因此,需要一種解決方案來處理不斷增長的用戶基數(shù)。
解決方案
表格分片
 圖片
圖片
第一種方法是在單個(gè)數(shù)據(jù)庫中創(chuàng)建多個(gè)類似的表,并使用user_id作為分片鍵。
我們?cè)趗ser_id列出現(xiàn)的任何地方創(chuàng)建了每個(gè)表的10個(gè)副本。因此,代碼中需要進(jìn)行兩個(gè)更改。第一個(gè)更改是獲取用戶請(qǐng)求中的user_id。第二個(gè)更改是替換由Hibernate生成的查詢中的表名。
關(guān)于第一個(gè)更改,獲取user_id很容易,因?yàn)槲覀円呀?jīng)在請(qǐng)求標(biāo)頭中獲取了user_id。
對(duì)于第二個(gè)更改,我們擴(kuò)展了Hibernate的EmptyInterceptor類,并覆蓋了onPrepareStatement方法,該方法在準(zhǔn)備SQL字符串時(shí)調(diào)用。該方法有一個(gè)字符串參數(shù),即SQL語句。該SQL語句中也包含表名。因此,這里根據(jù)請(qǐng)求頭中存在的user_id用所需的表名替換表名。例如,如果user_id為77。我們?nèi)∷?0的模得到7,并將表名user_profile替換為user_profile_7,因?yàn)槲覀円呀?jīng)在數(shù)據(jù)庫中創(chuàng)建了10個(gè)副本。以下是擴(kuò)展EmptyInterceptor類的代碼。如果您使用的是spring boot 3,則EmptyInterceptor已經(jīng)棄用,你可以使用StatementInspector接口,并覆蓋inspect方法,并將邏輯從onPrepareStatement方法移動(dòng)到inspect方法中。
public class DynamicTableNameSharding extends EmptyInterceptor {
@Override
public String onPrepareStatement(String sql) {
// 替換表名
if (Boolean.parseBoolean(DatabaseEnvironment.TABLE_SHARDING_ENABLED.label)) {
for (String tableName : SHARDED_TABLES) {
if(sql.contains(tableName)) {
ServletRequestAttributes attr = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
String shardingNumber = getSharding(attr);
sql = sql.replace(tableName, tableName + shardingNumber);
// 這里不要使用break,因?yàn)橐粭l查詢可以包含多個(gè)表,因此需要更改所有已啟用分片的表的名稱
}
}
}
return super.onPrepareStatement(sql);
}
}在上述函數(shù)中,SHARDED_TABLES是已啟用分片的表的列表。getSharding方法根據(jù)請(qǐng)求頭中傳遞的用戶ID返回分片號(hào)。由于在單個(gè)查詢中存在多個(gè)表(例如連接或復(fù)雜邏輯),因此我們使用for循環(huán)來正確替換查詢中出現(xiàn)的所有表。
我們還通過擴(kuò)展DefaultVisitListener類,在某些操作中使用了JOOQ。
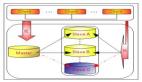
數(shù)據(jù)庫分片
 圖片
圖片
雖然通過表格分片提升了一定性能,但還有進(jìn)一步改進(jìn)的空間,我們進(jìn)一步對(duì)數(shù)據(jù)庫進(jìn)行分片。與創(chuàng)建表副本類似,我們創(chuàng)建10個(gè)數(shù)據(jù)庫服務(wù)器/實(shí)例的副本,每個(gè)服務(wù)器都有10個(gè)表的副本。總共有100個(gè)表副本。
因此,同時(shí)保持10個(gè)數(shù)據(jù)庫服務(wù)器運(yùn)行也需要路由查詢到正確的數(shù)據(jù)庫。
首先,在的Spring Boot應(yīng)用程序中創(chuàng)建了10個(gè)數(shù)據(jù)源,每個(gè)數(shù)據(jù)源都有不同的數(shù)據(jù)庫URL。現(xiàn)在,我們需要一種方法將數(shù)據(jù)庫連接路由到正確的數(shù)據(jù)源。因此,我們使用了AbstractRoutingDataSource,它是一個(gè)路由getConnection()調(diào)用到其中一個(gè)多個(gè)目標(biāo)數(shù)據(jù)源的抽象DataSource實(shí)現(xiàn),這個(gè)目標(biāo)數(shù)據(jù)源基于一個(gè)查找鍵。然后,我們重寫了這個(gè)方法determineCurrentLookupKey。
因此,這個(gè)方法返回一個(gè)鍵,用于標(biāo)識(shí)我們已定義的10個(gè)數(shù)據(jù)源中的一個(gè)特定數(shù)據(jù)源。因此,我們也更改了一些用于確定表和數(shù)據(jù)庫的邏輯。我們使用個(gè)位數(shù)字標(biāo)識(shí)數(shù)據(jù)庫服務(wù)器,使用十位數(shù)來標(biāo)識(shí)表。例如,用戶ID為447將被路由到第7個(gè)數(shù)據(jù)庫服務(wù)器及該服務(wù)器上的第4個(gè)表副本。因此,我們?cè)?0個(gè)數(shù)據(jù)庫服務(wù)器上有100個(gè)表,這大大提高了性能。
結(jié)論
在這個(gè)例子中,我們既使用了表分片又使用了數(shù)據(jù)庫分片。除此以外,我們可以進(jìn)一步提高性能,方法是在單個(gè)服務(wù)器中增加更多的數(shù)據(jù)庫,可能總共有1000個(gè)表的副本。