













順著網線爬過來成真了,Audio2Photoreal通過對話就能生成逼真表情與動作
當你和朋友隔著冷冰冰的手機屏幕聊天時,你得猜猜對方的語氣。當 Ta 發語音時,你的腦海中還能浮現出 Ta 的表情甚至動作。如果能視頻通話顯然是最好的,但在實際情況下并不能隨時撥打視頻。
如果你正在與一個遠程朋友聊天,不是通過冰冷的屏幕文字,也不是缺乏表情的虛擬形象,而是一個逼真、動態、充滿表情的數字化虛擬人。這個虛擬人不僅能夠完美地復現你朋友的微笑、眼神,甚至是細微的肢體動作。你會不會感到更加的親切和溫暖呢?真是體現了那一句「我會順著網線爬過來找你的」。
這不是科幻想象,而是在實際中可以實現的技術了。
面部表情和肢體動作包含的信息量很大,這會極大程度上影響內容表達的意思。比如眼睛一直看著對方說話和眼神基本上沒有交流的說話,給人的感覺是截然不同的,這也會影響另一方對溝通內容的理解。我們在交流過程中對這些細微的表情和動作都有著極敏銳的捕捉能力,并用它們來形成對交談伙伴意圖、舒適度或理解程度的高級理解。因此,開發能夠捕捉這些微妙之處的高度逼真的對話虛擬人對于互動至關重要。
為此,Meta 與加利福尼亞大學的研究者提出了一種根據兩人對話的語音音頻生成逼真虛擬人的方法。它可以合成各種高頻手勢和表情豐富的面部動作,這些動作與語音非常同步。對于身體和手部,他們利用了基于自回歸 VQ 的方法和擴散模型的優勢。對于面部,他們使用以音頻為條件的擴散模型。然后將預測的面部、身體和手部運動渲染為逼真虛擬人。研究者證明了在擴散模型上添加引導姿勢條件能夠生成比以前的作品更多樣化和合理的對話手勢。

- 論文地址:https://huggingface.co/papers/2401.01885
- 項目地址:https://people.eecs.berkeley.edu/~evonne_ng/projects/audio2photoreal/
研究者表示,他們是第一個研究如何為人際對話生成逼真面部、身體和手部動作的團隊。與之前的研究相比,研究者基于 VQ 和擴散的方法合成了更逼真、更多樣的動作。
方法概覽
研究者從記錄的多視角數據中提取潛在表情代碼來表示面部,并用運動骨架中的關節角度來表示身體姿勢。如圖 3 所示,本文系統由兩個生成模型組成,在輸入二人對話音頻的情況下,生成表情代碼和身體姿勢序列。然后,表情代碼和身體姿勢序列可以使用神經虛擬人渲染器逐幀渲染,該渲染器可以從給定的相機視圖中生成帶有面部、身體和手部的完整紋理頭像。
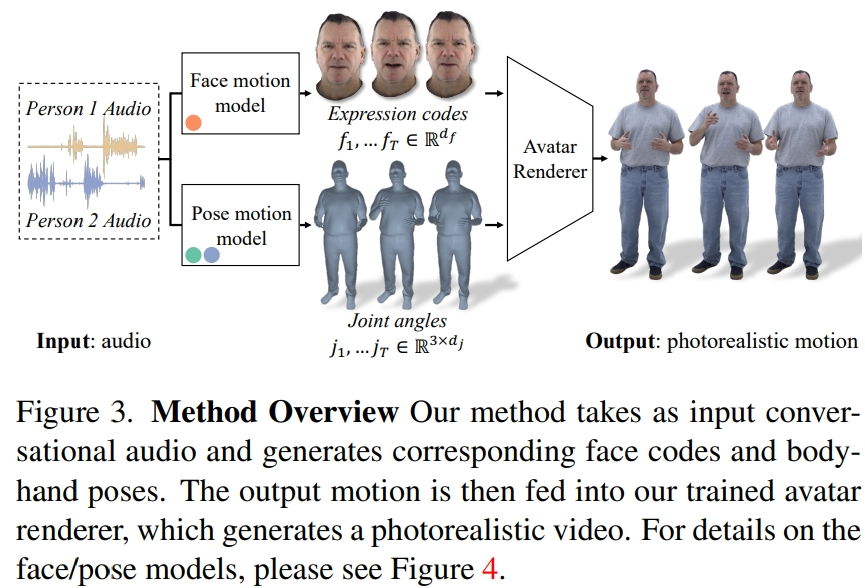
需要注意的是,身體和臉部的動態變化非常不同。首先,面部與輸入音頻的相關性很強,尤其是嘴唇的運動,而身體與語音的相關性較弱。這就導致在給定的語音輸入中,肢體手勢有著更加復雜的多樣性。其次,由于在兩個不同的空間中表示面部和身體,因此它們各自遵循不同的時間動態。因此,研究者用兩個獨立的運動模型來模擬面部和身體。這樣,臉部模型就可以「主攻」與語音一致的臉部細節,而身體模型則可以更加專注于生成多樣但合理的身體運動。
面部運動模型是一個擴散模型,以輸入音頻和由預先訓練的唇部回歸器生成的唇部頂點為條件(圖 4a)。對于肢體運動模型,研究者發現僅以音頻為條件的純擴散模型產生的運動缺乏多樣性,而且在在時間序列上顯得不夠協調。但是,當研究者以不同的引導姿勢為條件時,質量就會提高。因此,他們將身體運動模型分為兩部分:首先,自回歸音頻條件變換器預測 1fp 時的粗略引導姿勢(圖 4b),然后擴散模型利用這些粗略引導姿勢來填充細粒度和高頻運動(圖 4c)。關于方法設置的更多細節請參閱原文。

實驗及結果
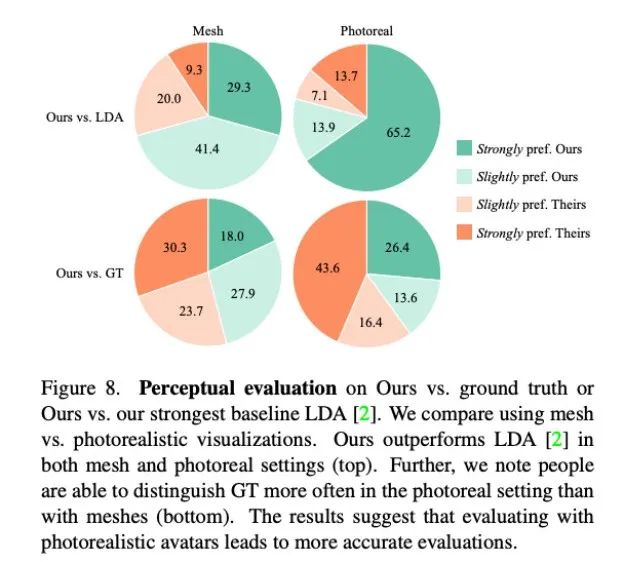
研究者根據真實數據定量評估了 Audio2Photoreal 有效生成逼真對話動作的能力。同時,還進行了感知評估,以證實定量結果,并衡量 Audio2Photoreal 在給定的對話環境中生成手勢的恰當性。實驗結果表明,當手勢呈現在逼真的虛擬化身上而不是 3D 網格上時,評估者對微妙手勢的感知更敏銳。
研究者將本文方法與 KNN、SHOW、LDA 這三種基線方法根據訓練集中的隨機運動序列進行了生成結果對比。并進行了消融實驗,測試了沒有音頻或指導姿勢的條件下、沒有引導姿勢但基于音頻的條件下、沒有音頻但基于引導姿勢的條件下 Audio2Photoreal 每個組件的有效性。
定量結果
表 1 顯示,與之前的研究相比,本文方法在生成多樣性最高的運動時,FD 分數最低。雖然隨機具有與 GT 相匹配的良好多樣性,但隨機片段與相應的對話動態并不匹配,導致 FD_g 較高。
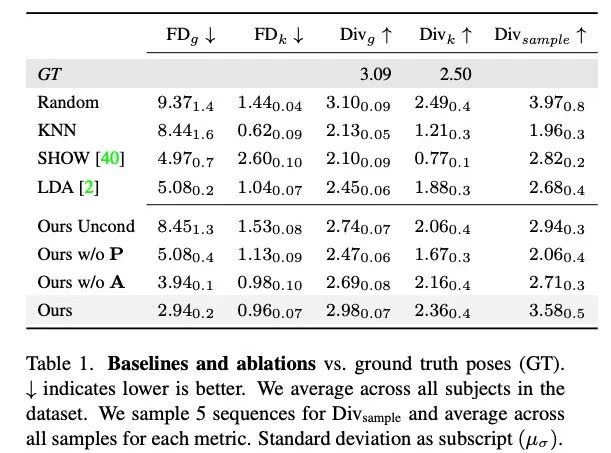
圖 5 展示了本文方法所生成的引導姿勢的多樣性。通過基于 VQ 的變換器 P 采樣,可以在相同音頻輸入的條件下生成風格迥異的姿勢。

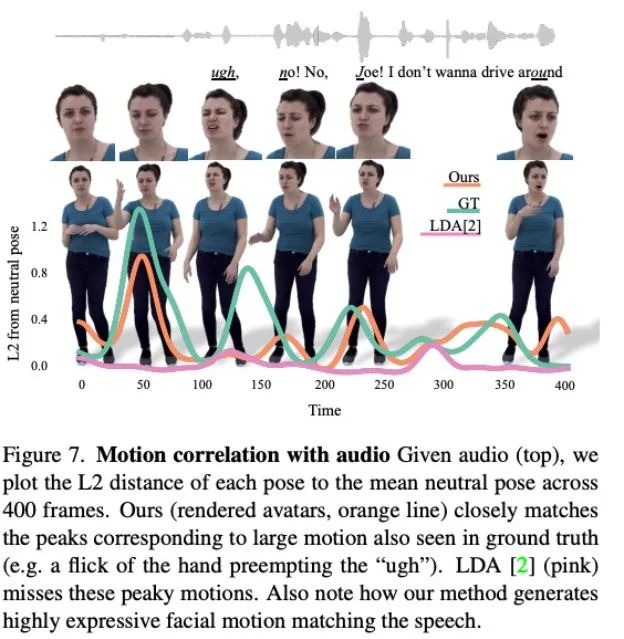
如圖 6 所示,擴散模型會學習生成動態動作,其中的動作會與對話音頻更加匹配。

圖 7 表現了 LDA 生成的運動缺乏活力,動作也較少。相比之下,本文方法合成的運動變化與實際情況更為吻合。
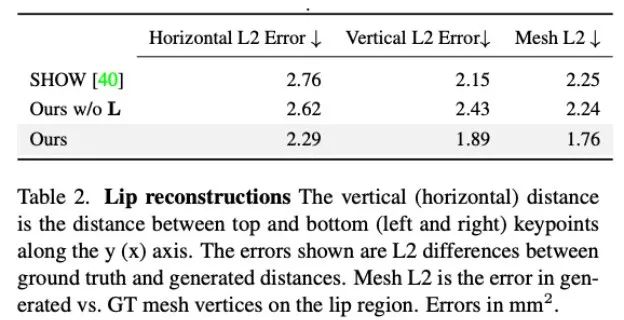
此外,研究者還分析了本文方法在生成嘴唇運動方面的準確度。如表 2 中的統計所示,Audio2Photoreal 顯著優于基線方法 SHOW,以及在消融實驗中移除預訓練的嘴唇回歸器后的表現。這一設計改善了說話時嘴形的同步問題,有效避免了不說話時口部出現隨機張開和閉合的動作,使得模型能夠實現更出色的的嘴唇動作重建,同時降低了面部網格頂點(網格 L2)的誤差。
定性評估
由于對話中手勢的連貫性難以被量化,研究者采用了定性方法做評估。他們在 MTurk 進行了兩組 A/B 測試。具體來說,他們請測評人員觀看本文方法與基線方法的生成結果或本文方法與真實情景的視頻對,請他們評估哪個視頻中的運動看起來更合理。
如圖 8 所示,本文方法顯著優于此前的基線方法 LDA,大約有 70% 的測評人員在網格和真實度方面更青睞 Audio2Photoreal。
如圖 8 頂部圖表所示,和 LDA 相比,評估人員對本文方法的評價從「略微更喜歡」轉變為「強烈喜歡」。和真實情況相比,也呈現同樣的評價。不過,在逼真程度方面,評估人員還是更認可真實情況,而不是 Audio2Photoreal。
更多技術細節,請閱讀原論文。
























