













SelfOcc:首篇純視覺環視自監督三維占有預測(清華大學)
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
寫在前面&筆者的個人理解
三維場景標注通常需要耗費大量的人力物力財力,是制約自動駕駛模型訓練迭代的一大瓶頸問題,從大量的二維視頻中自監督地學習出有效的三維場景表示是一個有效的解決方案。我們提出的SelfOcc通過使用NeRF監督首次實現僅使用視頻序列進行三維場景表示(BEV或TPV)學習。SelfOcc在自監督單目場景補全、環視三維語義占有預測、新視角深度合成、單目深度估計和環視深度估計等任務上均取得了SOTA的性能。

SelfOcc的相關背景
自監督3D占用預測
在當前的自動駕駛技術領域,以視覺為核心的系統通常依賴于精細的三維(3D)標注來學習有效的3D表示。然而,這種依賴精細3D標注的方法面臨著嚴峻挑戰,主要表現在3D標注獲取的高成本,尤其是在近來被提出的3D占用預測任務中,這一問題尤為突出。
3D占用預測任務的核心在于預測一個場景中各個體素是否被占用。但是,要實現這一點,大多數現有方法需要對每個體素進行逐一的語義監督。這種方法雖然能夠提供精確的3D表示,但其訓練過程極其耗時且成本高昂,這使得這些方法難以應用于大規模數據訓練。為了解決這一問題,目前已有一些自監督的3D占用預測方法被提出,如SceneRF和BTS。然而,這些方法主要針對單目視頻,無法有效處理環視場景。
在這種背景下,SelfOcc方法的提出顯得尤為重要。SelfOcc的目標是通過自監督學習方式,有效學習3D表示。與傳統方法不同,SelfOcc不單單聚焦于單一視角,而是通過顯式建模3D表示,天然地融合了單目和環視兩種視角。這種方法能夠利用單目視頻的數據來理解3D結構,同時也能夠處理環視視頻,從而為自動駕駛車輛提供更全面、更精確的環境感知能力。
可泛化神經輻射場
以2D圖像為基礎的自監督3D重建的主要范式是神經輻射場(NeRF),它通過從多個視角捕獲的2D圖像來重建3D場景。NeRF的核心優勢在于其能夠生成高度真實且連續的三維視覺效果,但傳統的NeRF方法在訓練過程中需要大量的同一場景的不同視角圖像,這在實際應用中是一個顯著的限制。而且,傳統NeRF缺乏對新場景的泛化能力,意味著它無法有效處理之前未見過的場景。
為了克服這些限制,部分研究工作提出了以圖像特征為條件的NeRF。這種方法的目的是通過較少的視角來實現對3D場景的重建,同時增強模型對新場景的泛化能力。然而,這種方法僅依賴于2D圖像特征作為主要的信息源,而忽略了3D特征編碼對于深層次的3D感知和理解的重要性。
在這個背景下,SelfOcc提供了一個新的視角。與傳統的以2D圖像特征為基礎的方法不同,SelfOcc顯著地強調了學習場景級別的3D表示的重要性。它的特征提取過程主要在三維空間內進行,這意味著SelfOcc不僅關注二維圖像所呈現的表面信息,而更重要的是,它能夠探索和理解空間中的深層結構和關系。這種方法通過直接在三維空間內提取和處理特征,能夠更全面地捕捉到場景的三維特性,從而提高了三維重建的質量和準確性。
自監督深度估計
NeRF的訓練過程面臨著一些顯著的挑戰,特別是收斂速度慢和容易發生過擬合的問題。這些問題主要源于NeRF對場景的高度非線性建模和對訓練數據的密集依賴。為此,一些研究工作開始引入深度信息作為輔助監督,或者采用自監督深度估計約束。
引入深度信息作為輔助監督的方法基于這樣一個理念:通過提供額外的深度信息,可以幫助NeRF更好地理解場景的空間結構,從而加速訓練過程并減少過擬合的風險。同時,自監督深度估計約束的引入旨在通過對深度估計的優化來提高NeRF模型的泛化能力。然而,這些方法在實際應用中也面臨一些固有的挑戰。首先,NeRF的體渲染積分過程為優化深度引入了多余的自由度,這使得深度優化變得復雜且不穩定。此外,視角變換后的雙線性插值限制了優化深度的感受野,導致深度估計易受局部特征的影響,從而容易陷入局部最優。
為了克服這些挑戰,SelfOcc提出了一種創新的MVS-embedded策略,以實現穩定高效的自監督深度優化。MVS(Multi-View Stereo)技術是一種成熟的三維重建技術,它能夠從多個視角的圖像中重建出精確的三維模型。SelfOcc通過將MVS技術嵌入到NeRF的訓練過程中,利用MVS的強大深度估計能力來指導NeRF模型的優化。這種策略有效地減少了體渲染過程中的自由度,使得深度優化過程更加穩定和高效。同時,MVS-embedded策略通過整合多個視角的信息,擴大了深度優化的感受野,從而減少了局部最優的風險。
詳解SelfOcc算法

上圖是SelfOcc方法的整體流程圖:SelfOcc首先利用2D圖像主干網絡提取得到多尺度圖像特征,再使用3D特征編碼器從圖像特征中提取3D場景表示,最后通過輕量級解碼器將3D表示解碼為符號距離場(SDF),并通過時序幀之間的提渲染約束實現監督。
從2D圖像到3D占用
SelfOcc首先通過一個圖像編碼器處理2D輸入圖像。該圖像編碼器的主要任務是將標準的2D圖像轉換為包含豐富信息的多尺度特征圖,從而為后續的三維表示提供必要的原始數據。隨后,SelfOcc利用三維編碼器處理這些多尺度圖像特征圖。三維編碼器的功能是將二維圖像特征轉化為三維空間表示(BEV/TPV)。這一轉換過程是將二維平面信息擴展到三維空間的關鍵步驟,它使得模型能夠探索和理解空間中的深層結構和關系。最后,SelfOcc使用一個輕量級的解碼器從3D表示中解碼出最終的三維占用預測結果。
從3D占用到2D圖像
為了有效地自監督生成的3D表示,SelfOcc采用了基于SDF的體渲染技術,將3D表示渲染為2D圖像和深度圖。
具體而言,SelfOcc首先使用解碼器將3D表示解碼為符號距離場(SDF)。SDF提供了一種描述物體表面的有效方式,其中每個點的值表示該點到最近表面的距離,正負號表示點在物體內部還是外部。相較于密度場,SDF具有更加明確的物理意義和關于梯度大小的約束,從而使其在進行正則化和優化時更加高效。此外,SDF的另一個優點是其在處理復雜幾何形狀時的精確度,因為一個點的符號可以直接確定它在表面內還是在表面外。
得到SDF場之后,SelfOcc通過體渲染生成2D結果。在這個過程中,一條從觀察點出發穿過三維場景的光線被模擬,沿光線路徑收集體素的屬性信息,然后基于這些信息計算出最終像素的顏色和強度。
以3D占用為核心的監督策略
基于MVS的深度優化策略

SelfOcc提出了一種創新的深度優化策略,稱之為MVS-embedded策略,旨在解決NeRF框架下使用傳統自監督深度估計約束時遇到的一些關鍵問題。自監督深度估計通常需要經過一個復雜的積分過程,該過程涉及將深度信息積分到一個單一的值,隨后通過透視投影進行兩個視角間的轉換,并最終通過比較目標像素和源圖像上經過雙線性插值得到的源像素來評估深度估計的準確性。然而,這種做法存在一些本質的限制。首先,積分過程的多自由度問題導致了深度估計在優化過程中的震蕩和不確定性。此外,采用雙線性插值的方法限制了深度優化的感受野,意味著深度估計過程過于依賴于局部特征,難以捕捉到更廣闊的場景上下文,從而容易陷入局部極值。
為了克服這些限制,SelfOcc提出了一種直接優化一條射線上的多個深度proposal的權重的方法,從而避免了復雜的積分過程。這種策略的核心在于,通過對射線上不同深度點的權重進行優化,我們可以更直接地評估每個深度點的貢獻和重要性,從而獲得更準確和穩定的深度估計。此外,這種方法中多個深度proposal的引入顯著增大了深度優化的感受野,這意味著我們的優化過程可以考慮到更廣泛的場景信息,從而減少局部極值的問題。
時序約束和SDF場的正則化
考慮到自動駕駛相機通常朝外并且每個相機的視角重疊區域較小,SelfOcc選擇使用時序上相鄰的幀——即之前和之后的幀——作為NeRF的監督目標。這種方法考慮到了自動駕駛場景中視角變化的獨特性,通過利用時間上的連續性來彌補空間視角重疊不足的問題。
在SDF場的正則化方面,我們采用了多種措施以確保SDF的物理意義和連續性。首先,我們引入了Eikonal loss,這是一種常用于保證SDF物理合理性的正則化方法。Eikonal loss的主要作用是確保SDF在空間中的梯度大小保持恒定,這有助于保持SDF場的一致性和準確性。其次,我們還引入了二階導數約束,這種約束的目的是提高SDF的空間連續性。通過限制SDF的二階導數,我們可以更好地控制SDF場的平滑度,減少在復雜幾何形狀處的不連續和尖銳變化。除此之外,我們還引入了稀疏性約束,這是為了強制模型將看不到的區域預測為空。在自動駕駛的應用中,由于視角的限制,總會有一部分區域是不可見的。通過稀疏性約束,我們可以確保這些不可見區域在SDF場中被合理處理,避免在這些區域產生誤導性的預測。這些正則化措施在面對少視角的欠定問題時,能夠有效地引導SDF學習過程,確保學到的SDF場在滿足視角重建的要求的同時,盡可能地與物理先驗對齊。
實驗
我們在三個主要自動駕駛數據集上開展了實驗,包括nuScenes,SemanticKITTI和KITTI-2015,覆蓋三維占有預測,新視角深度預測和深度估計等自監督三維理解任務。所有實驗在8張RTX 3090上進行,訓練和測試代碼均已開源。以下是主要實驗結果和可視化,更多內容詳見論文和GitHub倉庫。
自監督3D占用預測

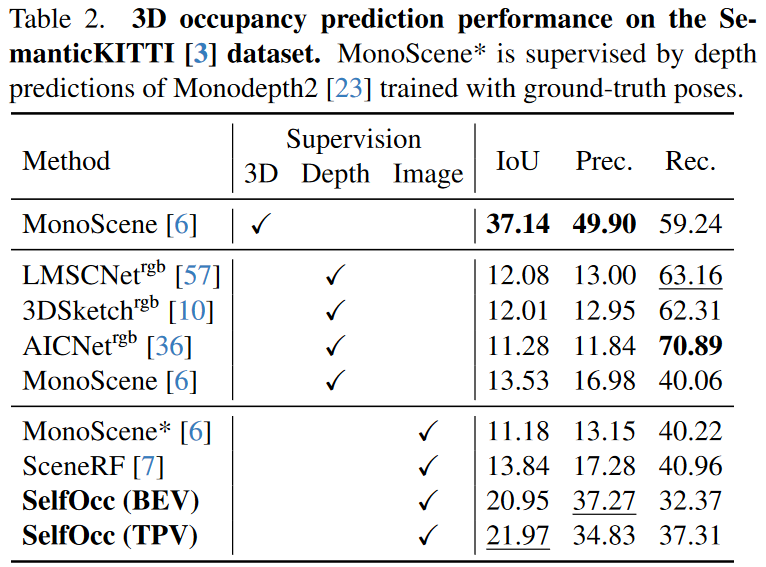
表1和表2列出了3D占用預測任務的結果。在Occ3D數據集上,與有監督方法相比,我們的方法沒有使用任何形式的3D監督,仍取得了較高的IoU以及合理的mIoU。45.01%的IoU表明SelfOcc從視頻序列中學習到了有意義的幾何結構。更重要的是,相比LiDAR監督的TPVFormer和3D真值監督的MonoScene,SelfOcc甚至取得了更高的IoU和mIoU。
在SemanticKITTI數據集上,我們將各種方法歸類為3D真值、深度和圖片監督三種類別。從表2可以看出,SelfOcc取得了基于視覺的深度監督和圖片監督的3D占有預測方法的新SOTA,并且在IoU指標上超過上一任SOTA方法SceneRF達58.7%。
自監督新視角深度預測

表3展示了SelfOcc在自監督新視角深度預測任務上的性能。SelfOcc在SemanticKITTI和nuScenes數據集上的所有指標上都優于之前最先進的SceneRF。
自監督深度預測

表4展示了SelfOcc在自監督深度估計任務上的性能。SelfOcc在nuScenes上取得了SOTA結果,且與KITTI-2015數據集上的SOTA方法性能相當。
可視化


上面兩幅圖展示了SelfOcc在nuScenes數據集上的自監督3D占有預測和深度估計的可視化結果。
論文信息
作者:黃原輝*,鄭文釗*,張博睿,周杰,魯繼文
機構:清華大學自動化系
文章鏈接:https://arxiv.org/pdf/2311.12754.pdf
項目主頁:https://huang-yh.github.io/SelfOcc/
代碼倉庫:https://github.com/huang-yh/SelfOcc (已開源)

原文鏈接:https://mp.weixin.qq.com/s/3ysN139lRE8Txl1YU7Nfyw

















