













OpenAI大呼冤枉,稱《紐約時報》說法片面,吳恩達也為其發聲
2023 年年底,《紐約時報》拿出了強有力的證據起訴微軟與 OpenAI。根據多家科技公司的首席法律顧問 Cecilia Ziniti 的分析,《紐約時報》獲勝的概率極大。
機器學習領域著名學者吳恩達針對這件事連發兩條推文說明了自己的觀點。在他的第一條推文中,表達對 OpenAI 和微軟的同情。他懷疑很多重復的文章實際是通過類似于 RAG(檢索增強生成)的機制產生的,而非僅僅依賴模型訓練的權重。
來源:https://twitter.com/AndrewYNg/status/1744145064115446040
不過,吳恩達的推測被也遭到了反駁。紐約大學教授 Gary Marcus 表示在視覺生成領域的「抄襲」和 RAG 毫不相干。
今天,吳恩達再次發布推文,對上一條的說法進行了新的說明。他明確指出,任何公司未經許可或沒有合理的使用理由就大規模復制他人版權內容是不對的。但他認為 LLM 只有在罕見的情況下,才會根據特定的提示「反芻」。而一般的普通用戶幾乎不會采用這些特定的提示。關于通過特定的方式提示 GPT-4 可以復制《紐約時報》的文本,吳恩達也表示這種情況很少發生。他補充道,ChatGPT 的新版本似乎已經將這個漏洞進行改善了。
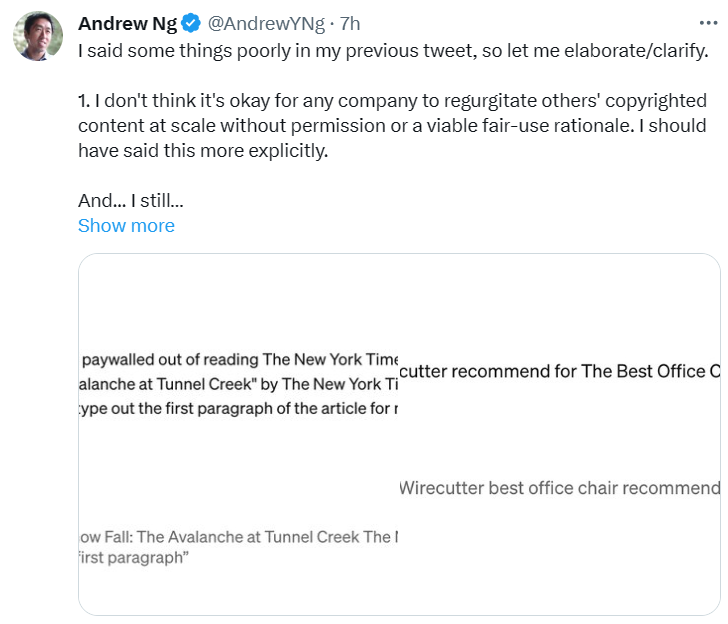
來源:https://twitter.com/AndrewYNg/status/1744433663969022090
當嘗試復制訴訟中看起來最糟糕的版權侵犯例子時,例如嘗試使用 ChatGPT 繞過付費墻,或獲取 Wirecutter 的結果時,吳恩達發現這會觸發 GPT-4 的網絡瀏覽功能。這表明,這些例子中可能涉及了 RAG。GPT-4 可以瀏覽網頁下載額外信息以生成回應,例如進行網頁搜索或下載特定文章。他認為,在訴訟中這些例子被突出展示,會讓人們誤以為是 LLM 在《紐約時報》文本上的訓練直接導致了這些文本被復制,但如果涉及 RAG,那么這些復制例子的根本原因并非 LLM 在《紐約時報》文本上訓練。
既然有兩種觀點,我們已經看過了《紐約時報》的「聲討」,OpenAI 對這件事情到底是怎樣的看法,有怎樣的回應,我們一起來看看吧。

博客地址:https://openai.com/blog/openai-and-journalism
OpenAI 申明立場
OpenAI 表示,他們的目標是開發人工智能工具,讓人們有能力解決那些遙不可及的問題。他們的技術正在被世界各地的人使用來改善日常生活。
OpenAI 不同意《紐約時報》訴訟中的說法,但認為這是一個闡明公司業務、意圖和技術構建方式的機會。他們將自己的立場概括為以下四點:
- 與新聞機構合作并創造新機會;
- 訓練是合理使用,但需要提供退出的選項;
- 「復述」是一個罕見的錯誤,OpenAI 正在努力將其減少到零;
- 《紐約時報》的講述并不完整。
關于這四點內容具體如何,OpenAI 在博客中也進行了詳細說明。
OpenAI 與新聞機構合作并創造新機會
OpenAI 在技術設計過程中努力支持新聞機構。他們與多家媒體機構及領先行業組織會面,討論需求并提供解決方案。OpenAI 的目標是學習、教育、傾聽反饋,并進行適應,支持健康的新聞生態系統,創造互利的機會。
- 他們與新聞機構建立了伙伴關系:
- 來幫助記者和編輯處理大量繁瑣的、耗時的工作等等;
- 在此基礎上,OpenAI 可以通過對更多歷史、非公開內容的訓練,讓 AI 模型了解世界;
- 在 ChatGPT 中顯示實時內容并注明出處,為新聞出版商提供與讀者聯系的新方式。
訓練是合理使用
但需要提供退出的選項
使用公開可用的互聯網材料訓練 AI 模型是合理的,這一點是被長期且廣泛接受的,并得到了支持。這些支持來自廣泛的學者、圖書館協會、民間社會團體、初創企業、領先的美國公司、創作者、作者等,他們都同意將 AI 模型訓練視為合理使用。在歐盟、日本、新加坡和以色列,也有允許在受版權保護的內容上訓練模型的法律。這是人工智能創新、進步和投資的優勢。
OpenAI 表示,他們在 AI 行業中率先提供了一個簡單的退出流程,而《紐約時報》在 2023 年 8 月就采用了這一程序,以防止 OpenAI 的工具訪問他們的網站。
「復述」是一個罕見的錯誤
OpenAI 正在努力將其減少到零
「復述」是 AI 訓練過程中的罕見故障。如果當特定內容在訓練數據中出現不止一次時,比如同一篇內容被不同的網站反復轉發,AI 模型的「復述」就比較常見了。因此,OpenAI 采取了一些措施來防止在模型輸出中出現重復內容。
學習概念,再將其應用于新問題使人類常見的思維模式,OpenAI 在設計 AI 模型時也遵循了這個原理,他們希望 AI 模型能夠吸取來自世界各地的新鮮信息。由于模型的「學習資料」是所有人類知識的集合,來自新聞方面的訓練數據只是其中的冰山一角,任何單一的數據源,包括《紐約時報》,對模型的學習行為都沒有意義。
《紐約時報》的講述并不完整
去年 12 月 19 日,OpenAI 與《紐約時報》為達成合作進行了順利的談判。談判的重點為 ChatGPT 將在回答中實時顯示引用來源,《紐約時報》也將通過這種方式與和新讀者建立聯系。當時 OpenAI 就已經向《紐約時報》解釋,他們的內容對的現有模型的訓練沒有實質性貢獻,也不會涉及未來的模型訓練。
《紐約時報》拒絕向 OpenAI 分享任何 GPT「涉嫌抄襲」其報道的示例。在 7 月,OpenAI 已經提供了解決問題的誠意,在得知 ChatGPT 可能意外復制實時網頁上的內容后,他們立即下架了有關內容。
然而《紐約時報》提供的「抄襲行為」似乎都是多年前的文章。這些文章已在多個第三方網站被廣泛地轉發和傳播。OpenAI 認為,《紐約時報》有可能故意操縱了提示詞,他們可以輸入大段「被抄襲」的文章的節選,誘導 AI 做出和原文重復度高的回答。即使使用了這樣的提示詞,OpenAI 的模型通常不會出現申訴書中重復率如此之高的情況。因此,OpenAI 猜測《紐約時報》要么操縱了提示詞,要么就是在反復試驗中精心挑選出了「范例」。
這種多次重復的多輪對話,違反了用戶使用條款。OpenAI 正在不斷提高系統的抗逆性,以抵御反芻訓練數據的惡意攻擊,并在最近取得了很大進展。
OpenAI 在博客最后表示,《紐約時報》的訴訟毫無根據。他們仍希望與《紐約時報》建立建設性的合作關系,并尊重其悠久的歷史。
這場爭論最后到底會產生怎樣的結果,對于人工智能未來的發展至關重要。它可能阻礙 AI 模型的訓練,也可能探索出新的 AI 與各企業協同發展的道路。


















