Rust編程基礎核心之所有權
什么是所有權?
Rust 的核心功能(之一)是 所有權(ownership)。雖然該功能很容易解釋,但它對語言的其他部分有著深刻的影響。
所有程序都必須管理其運行時使用計算機內存的方式。一些語言中具有垃圾回收機制,在程序運行時有規律地尋找不再使用的內存,例如:Java、Go;在另一些語言中,程序員必須親自分配和釋放內存,例如:C、C++。Rust 則選擇了第三種方式:通過所有權系統管理內存,編譯器在編譯時會根據一系列的規則進行檢查。如果違反了任何這些規則,程序都不能編譯。在運行時,所有權系統的任何功能都不會減慢程序。
因為所有權對很多程序員來說都是一個新概念,需要一些時間來適應。隨著你對 Rust 和所有權系統的規則越來越有經驗,你就越能自然地編寫出安全和高效的代碼, 需要學習者能夠持之以恒。
當理解了所有權,將會有一個堅實的基礎來理解那些使 Rust 獨特的功能。

棧和堆基礎
在很多語言中,并不需要經常考慮到棧與堆。不過在像 Rust 這樣的系統編程語言中,值是位于棧上還是堆上在更大程度上影響了語言的行為以及為何必須做出這樣的抉擇。
棧和堆都是代碼在運行時可供使用的內存,但是它們的結構不同。棧以放入值的順序存儲值并以相反順序取出值。這也被稱作 后進先出(last in, first out)。
增加數據叫做 進棧(pushing onto the stack),而移出數據叫做 出棧(popping off the stack)。棧中的所有數據都必須占用已知且固定的大小。在編譯時大小未知或大小可能變化的數據,要改為存儲在堆上。
堆是缺乏組織的:當向堆放入數據時,你要請求一定大小的空間。內存分配器(memory allocator)在堆的某處找到一塊足夠大的空位,把它標記為已使用,并返回一個表示該位置地址的 指針(pointer)。這個過程稱作 在堆上分配內存(allocating on the heap),有時簡稱為 “分配”(allocating)。因為指向放入堆中數據的指針是已知的并且大小是固定的,你可以將該指針存儲在棧上,不過當需要實際數據時,必須訪問指針。
入棧比在堆上分配內存要快,因為(入棧時)分配器無需為存儲新數據去搜索內存空間;其位置總是在棧頂。相比之下,在堆上分配內存則需要更多的工作,這是因為分配器必須首先找到一塊足夠存放數據的內存空間,并接著做一些記錄為下一次分配做準備。
訪問堆上的數據比訪問棧上的數據慢,因為必須通過指針來訪問。現代處理器在內存中跳轉越少就越快(緩存)。出于同樣原因,處理器在處理的數據彼此較近的時候(比如在棧上)比較遠的時候(比如可能在堆上)能更好的工作。當你的代碼調用一個函數時,傳遞給函數的值(包括可能指向堆上數據的指針)和函數的局部變量被壓入棧中。當函數結束時,這些值被移出棧。
跟蹤哪部分代碼正在使用堆上的哪些數據,最大限度的減少堆上的重復數據的數量,以及清理堆上不再使用的數據確保不會耗盡空間,這些問題正是所有權系統要處理的。一旦理解了所有權,就不需要經常考慮棧和堆了,不過明白了所有權的主要目的就是為了管理堆數據,能夠幫助解釋為什么所有權要以這種方式工作。
所有權規則
所有權規則核心主要有三條,務必牢記:
- Rust 中的每一個值都有一個 所有者(owner)。
- 值在任一時刻有且只有一個所有者。
- 當所有者(變量)離開作用域,這個值將被丟棄。
在所有權的第一個例子中,我們看看一些變量的 作用域(scope)。作用域是一個項(item)在程序中有效的范圍。假設有這樣一個變量:
let s = "hello";變量 s 綁定到了一個字符串字面值,這個字符串值是硬編碼進程序代碼中的。這個變量從聲明的點開始直到當前 作用域 結束時都是有效的。可以看下面的標注:
{ // s 在這里無效,它尚未聲明
let s = "hello";// 從此處起,s 是有效的
// 使用 s
} // 此作用域已結束,s 不再有效換句話說,這里有兩個重要的時間點:
- 當 s 進入作用域 時,它就是有效的。
- 這一直持續到它 離開作用域 為止。
目前為止,變量是否有效與作用域的關系跟其他編程語言是類似的。現在在此基礎上介紹 String 類型。
看下面的一段代碼:
let s = String::from("hello");這兩個冒號 :: 是運算符,允許將特定的 from 函數置于 String 類型的命名空間(namespace)下,而不需要使用類似 string_from 這樣的名字。
可以 修改此類字符串如下:
let mut s = String::from("hello");
s.push_str(", world!"); // push_str() 在字符串后追加字面值
println!("{}", s); // 將打印 `hello, world!`我們已經見過字符串字面值,即被硬編碼進程序里的字符串值, 它們是不可變的。那么這里有什么區別呢?為什么 String 可變而字面值卻不行呢?區別在于兩個類型對內存的處理上。
所有權內存和分配
對于字符串字面值,我們在編譯時就知道其內容,所以文本被直接硬編碼進最終的可執行文件中。這使得字符串字面值快速且高效。不過這些特性都只得益于字符串字面值的不可變性。不幸的是,我們不能為了每一個在編譯時大小未知的文本而將一塊內存放入二進制文件中,并且它的大小還可能隨著程序運行而改變。
對于 String 類型,為了支持一個可變,可增長的文本片段,需要在堆上分配一塊在編譯時未知大小的內存來存放內容。這意味著:
- 必須在運行時向內存分配器(memory allocator)請求內存。
- 需要一個當我們處理完 String 時將內存返回給分配器的方法。
第一部分由我們完成:當調用 String::from 時,它的實現 (implementation) 請求其所需的內存。這在編程語言中是非常通用的。
然而,第二部分實現起來就各有區別了。在有 垃圾回收(garbage collector,GC)的語言中,GC 記錄并清除不再使用的內存,而我們并不需要關心它。在大部分沒有 GC 的語言中,識別出不再使用的內存并調用代碼顯式釋放就是我們的責任了,跟請求內存的時候一樣。從歷史的角度上說正確處理內存回收曾經是一個困難的編程問題。如果忘記回收了會浪費內存。如果過早回收了,將會出現無效變量。如果重復回收,這也是個 bug。我們需要精確的為一個 allocate 配對一個 free。
Rust 采取了一個不同的策略:內存在擁有它的變量離開作用域后就被自動釋放。下面是作用域例子的一個使用 String 而不是字符串字面值的版本:
{
let s = String::from("hello"); // 從此處起,s 是有效的
// 使用 s
} // 此作用域已結束,
// s 不再有效這是一個將 String 需要的內存返回給分配器的很自然的位置:當 s 離開作用域的時候。當變量離開作用域,Rust 為我們調用一個特殊的函數。這個函數叫做 drop,在這里 String 的作者可以放置釋放內存的代碼。Rust 在結尾的 } 處自動調用 drop。
這個模式對編寫 Rust 代碼的方式有著深遠的影響。現在它看起來很簡單,不過在更復雜的場景下代碼的行為可能是不可預測的,比如當有多個變量使用在堆上分配的內存時。下面來探索一些場景。
變量與數據交互方式之移動
在 Rust 中,多個變量可以采取不同的方式與同一數據進行交互。看下面的例子:
let x = 5;
let y = x;我們大致可以猜到這在干什么:將 5 綁定到 x;接著生成一個值 x 的拷貝并綁定到 y。現在有了兩個變量,x 和 y,都等于 5。因為整數是有已知固定大小的簡單值,所以這兩個 5 被放入了棧中。
現在看看這個 String 版本:
let s1 = String::from("hello");
let s2 = s1;這看起來與上面的代碼非常類似,所以我們可能會假設它們的運行方式也是類似的:也就是說,第二行可能會生成一個 s1 的拷貝并綁定到 s2 上。不過,事實上并不完全是這樣。
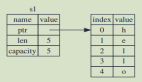
下面先看一張圖解:
從左邊代表的s1內容可以看到, String是由三部分組成: 一個指向存放字符串內容內存的指針, 一個是長度和一個容量。這一組數據存儲在棧上, 而右側的數據, 也就是"hello"字符串內容則是存儲在堆上。
這里我們要區分一下長度和容量。長度是表示String的內容當前使用了多少字節的內存; 而容量是String從分配器總共獲取了多少字節的內存。長度和容量的區別非常重要, 但在這里的上下文中并不重要, 所以現在暫時忽略容量。
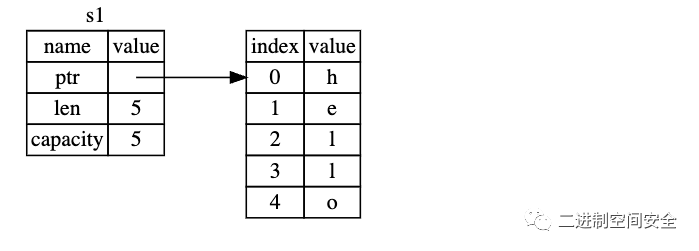
當我們將s1賦值給s2, String的數據被復制了, 這意味著我們從棧上拷貝了它的指針、長度和容量。但并沒有復制指針指向的堆上的數據:"hello", 為了更好的理解, 可以參考下面的圖解:
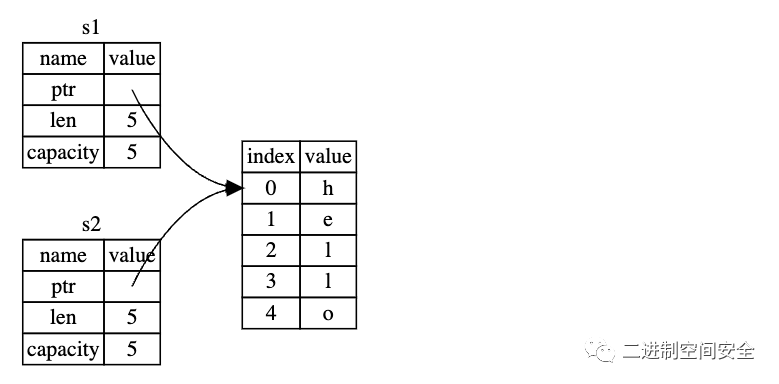
從圖中可以看出, 將s1賦給s2之后, s2有一份s1的拷貝,內容是: ptr、len和capacity, 設想一下, 如果此時Rust也拷貝了堆上的數據將會發生什么?那么內存看起來就像下面這樣:
如果Rust真的這樣做了, 在操作s2 = s1的過程中,假如堆里的數據不是"hello",而是一串大數據, 那么在運行時可能會對性能造成重大的影響。
之前我們提到過當變量離開作用域后,Rust 自動調用 drop 函數并清理變量的堆內存。當執行語句:s2 = s1時, 兩個數據指針指向了同一個位置, 此時就有一個問題: 當s2和s1離開作用域, 它們都會嘗試釋放相同的內存, 這是一個典型的二次釋放(double free)的錯誤, 也是之前提到過的內存安全性bug之一, 兩次釋放(相同)內存會導致內存污染, 它可能會導致潛在的安全漏洞。
為了確保內存安全,在 let s2 = s1; 之后,Rust 認為 s1 不再有效,因此 Rust 不需要在 s1 離開作用域后清理任何東西。看看在 s2 被創建之后嘗試使用 s1 會發生什么, 代碼如下:
let s1 = String::from("hello");
let s2 = s1;
println!("{}, world!", s1);這段代碼執行后, 會得到一個錯誤, 因為Rust禁止使用無效的引用,如圖:

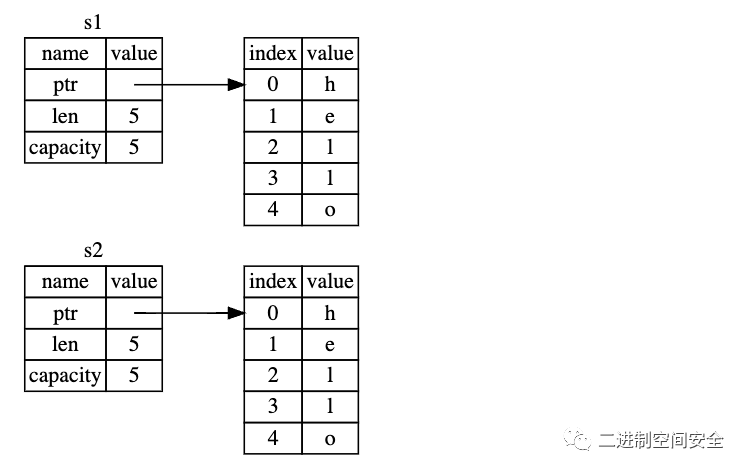
如果在其他語言中聽說過術語 淺拷貝(shallow copy)和 深拷貝(deep copy),那么拷貝指針、長度和容量而不拷貝數據可能聽起來像淺拷貝。不過因為 Rust 同時使第一個變量無效了,這個操作被稱為 移動(move),而不是叫做淺拷貝。上面的例子可以解讀為 s1 被 移動 到了 s2 中。那么具體發生了什么,可以參考下圖:
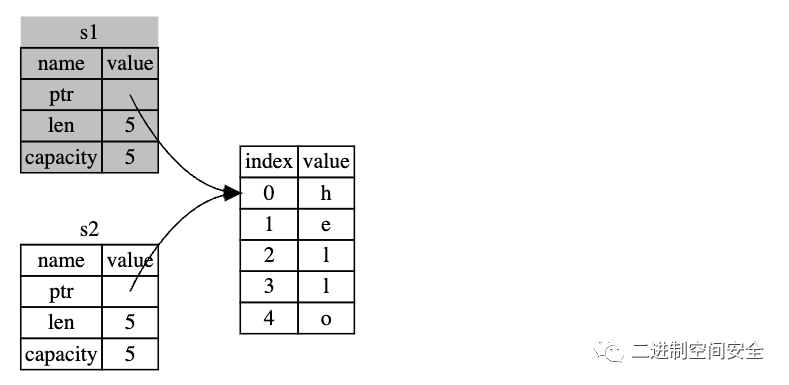
當執行let s2 = s1后, s1被移動到s2, 隨后被釋放, 這樣就解決了二次釋放問題, 只有s2是有效的, 當其離開作用域, s2會釋放自己的內存,完美解決。
另外,這里還隱含了一個設計選擇:Rust 永遠也不會自動創建數據的 “深拷貝”。因此,任何 自動 的復制可以被認為對運行時性能影響較小。
變量與數據交互方式之二: 克隆
如果我們 確實 需要深度復制 String 中堆上的數據,而不僅僅是棧上的數據,可以使用一個叫做 clone 的通用函數。
看下面的代碼:
let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {}, s2 = {}", s1, s2);這段代碼能正常運行, 并且堆上的數據現在可以被復制了。
我們在代碼中下個斷點, 使用調試器觀察下s1的內容,如圖:
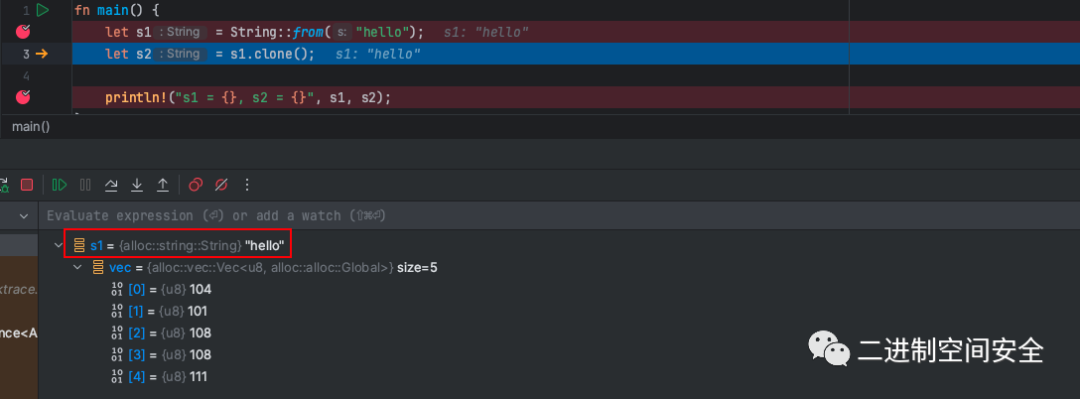
結合上一章節的分析, 此時s1變量中保存的指針ptr指向的內存保存了內容:"hello"。
現在執行語句: let s2 = s1.clone(); 單不執行一下看下s2的內容,如圖:
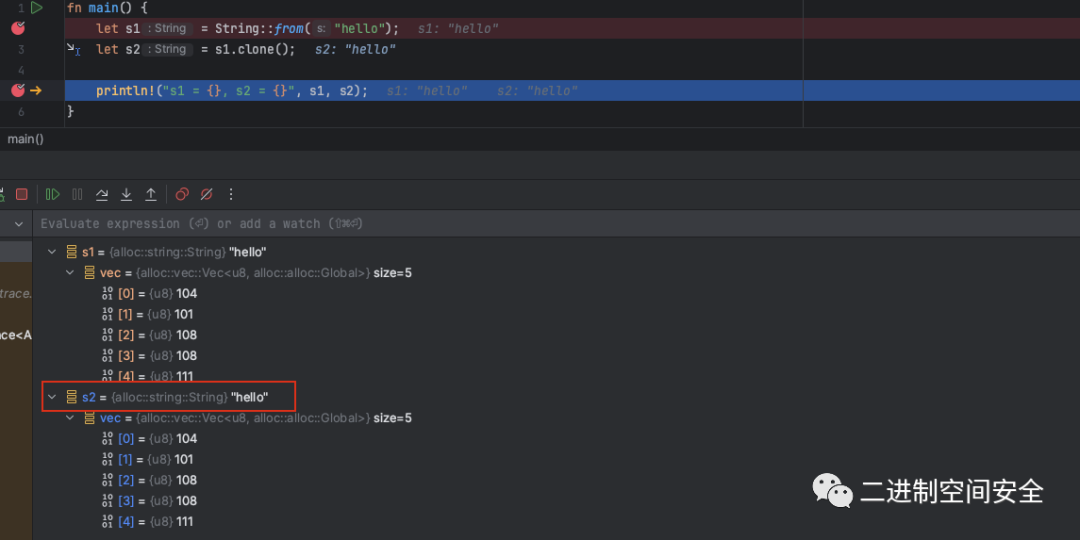
可以看到, clone()函數的確將字符串內容復制到變量s2中。
注意:當出現 clone 調用時,我們心里要清楚一些特定的代碼被執行而且這些代碼可能相當消耗資源。很容易能察覺到一些不尋常的事情正在發生。
下面再看一段代碼:
let x = 5;
let y = x;
println!("x = {}, y = {}", x, y);執行這段代碼, 結果如下:

這段代碼似乎與我們剛剛學到的內容相矛盾:沒有調用 clone,不過 x 依然有效且沒有被移動到 y 中。
原因是像整型這樣的在編譯時已知大小的類型被整個存儲在棧上,所以拷貝其實際的值是快速的。這意味著沒有理由在創建變量 y 后使 x 無效。換句話說,這里沒有深淺拷貝的區別,所以這里調用 clone 并不會與通常的淺拷貝有什么不同,我們可以不用管它。
Rust 有一個叫做 Copy trait 的特殊注解,可以用在類似整型這樣的存儲在棧上的類型上, 如果一個類型實現了 Copy trait,那么一個舊的變量在將其賦值給其他變量后仍然可用。
Rust 不允許自身或其任何部分實現了 Drop trait 的類型使用 Copy trait。如果我們對其值離開作用域時需要特殊處理的類型使用 Copy 注解,將會出現一個編譯時錯誤。
那么哪些類型實現了 Copy trait 呢?可以查看給定類型的文檔來確認,不過作為一個通用的規則,任何一組簡單標量值的組合都可以實現 Copy,任何不需要分配內存或某種形式資源的類型都可以實現 Copy 。如下是一些 Copy 的類型:
- 所有整數類型,比如 u32。
- 布爾類型,bool,它的值是 true 和 false。
- 所有浮點數類型,比如 f64。
- 字符類型,char。
- 元組,當且僅當其包含的類型也都實現 Copy 的時候。比如,(i32, i32) 實現了 Copy,但 (i32, String) 就沒有。
所有權和函數
將值傳遞給函數與給變量賦值的原理相似。向函數傳遞值可能會移動或者復制,就像賦值語句一樣。
看一下下面的代碼:
fn main() {
let s = String::from("hello"); // s 進入作用域
takes_ownership(s); // s 的值移動到函數里 ...
// ... 所以到這里不再有效
let x = 5; // x 進入作用域
makes_copy(x); // x 應該移動函數里,
// 但 i32 是 Copy 的,
// 所以在后面可繼續使用 x
} // 這里,x 先移出了作用域,然后是 s。但因為 s 的值已被移走,
// 沒有特殊之處
fn takes_ownership(some_string: String) { // some_string 進入作用域
println!("{}", some_string);
} // 這里,some_string 移出作用域并調用 `drop` 方法。
// 占用的內存被釋放
fn makes_copy(some_integer: i32) { // some_integer 進入作用域
println!("{}", some_integer);
} // 這里,some_integer 移出作用域。沒有特殊之處當嘗試在調用 takes_ownership 后使用 s 時,Rust 會拋出一個編譯時錯誤。這些靜態檢查使我們免于犯錯。
返回值與作用域
返回值也可以轉移所有權, 看下面的代碼:
fn main() {
let s1 = gives_ownership(); // gives_ownership 將返回值
// 轉移給 s1
let s2 = String::from("hello"); // s2 進入作用域
let s3 = takes_and_gives_back(s2); // s2 被移動到
// takes_and_gives_back 中,
// 它也將返回值移給 s3
} // 這里,s3 移出作用域并被丟棄。s2 也移出作用域,但已被移走,
// 所以什么也不會發生。s1 離開作用域并被丟棄
fn gives_ownership() -> String { // gives_ownership 會將
// 返回值移動給
// 調用它的函數
let some_string = String::from("yours"); // some_string 進入作用域。
some_string // 返回 some_string
// 并移出給調用的函數
//
}
// takes_and_gives_back 將傳入字符串并返回該值
fn takes_and_gives_back(a_string: String) -> String { // a_string 進入作用域
//
a_string // 返回 a_string 并移出給調用的函數
}變量的所有權總是遵循相同的模式:將值賦給另一個變量時移動它。當持有堆中數據值的變量離開作用域時,其值將通過 drop 被清理掉,除非數據被移動為另一個變量所有。
雖然這樣是可以的,但是在每一個函數中都獲取所有權并接著返回所有權有些啰嗦。如果我們想要函數使用一個值但不獲取所有權該怎么辦呢?如果我們還要接著使用它的話,每次都傳進去再返回來就有點煩人了,除此之外,我們也可能想返回函數體中產生的一些數據。
我們可以使用元組來返回多個值, 看下面的代碼:
fn main() {
let s1 = String::from("hello");
let (s2, len) = calculate_length(s1);
println!("The length of '{}' is {}.", s2, len);
}
fn calculate_length(s: String) -> (String, usize) {
let length = s.len(); // len() 返回字符串的長度
(s, length)
}但是這未免有些形式主義,而且這種場景應該很常見。幸運的是,Rust 對此提供了一個不用獲取所有權就可以使用值的功能,叫做 引用(references)。