













比A100性價比更高!FlightLLM讓大模型推理不再為性能和成本同時發(fā)愁
大語言模型在端側(cè)的規(guī)模化應(yīng)用對計算性能、能效比需求的“提拽式”牽引,在算法與芯片之間,撕開了一道充分的推理競爭場。
面對想象中的終端場景,基于 GPU 和 FPGA 的推理方案的應(yīng)用潛力需要被重新審視。
近日,無問芯穹、清華大學(xué)和上海交通大學(xué)聯(lián)合提出了一種面向 FPGA 的大模型輕量化部署流程,首次在單塊 Xilinx U280 FPGA 上實(shí)現(xiàn)了 LLaMA2-7B 的高效推理。
第一作者為清華大學(xué)電子系博士及無問芯穹硬件負(fù)責(zé)人曾書霖,通訊作者為上海交通大學(xué)副教授、無問芯穹聯(lián)合創(chuàng)始人兼首席科學(xué)家戴國浩,清華大學(xué)電子工程系教授、系主任及無問芯穹發(fā)起人汪玉。
相關(guān)工作現(xiàn)已被可重構(gòu)計算領(lǐng)域頂級會議 FPGA’24 接收。

論文鏈接:https://arxiv.org/pdf/2401.03868.pdf
回顧上一輪清華電子系相關(guān)工作被 FPGA 國際會議收錄的蹤跡,要追溯到 2016 年的 Going Deeper with Embedded FPGA Platform for Convolutional Neural Network 與 2017 年 ESE: Efficient Speech Recognition Engine with Sparse LSTM on FPGA。
前者催化了深鑒科技的創(chuàng)立,后者被 FPGA 國際會議評為當(dāng)年唯一的最佳論文,并為其特設(shè)了一個 Tutorial 環(huán)節(jié)「The Role of FPGAs in Machine Learning」,專門討論 FPGA 在機(jī)器學(xué)習(xí)領(lǐng)域所扮演角色的變化。
隨著 FPGA 在高性能計算領(lǐng)域的應(yīng)用潛力被不斷挖掘,震動從學(xué)術(shù)界傳導(dǎo)到產(chǎn)業(yè)界,引發(fā)了一輪半導(dǎo)體領(lǐng)域的 FPGA 公司收購熱。
在幾乎所有可能對未來世界產(chǎn)生重大影響的產(chǎn)、研趨勢中,高性能計算都處于關(guān)鍵位置。雖然設(shè)備的核心計算部件仍是 CPU 和 GPU ,但在一個人工智能算法不斷進(jìn)步、新標(biāo)準(zhǔn)不斷涌現(xiàn)的時代里,加速這些日新月異的算法推理工作至關(guān)重要。
在軟硬件協(xié)同優(yōu)化趨勢下,F(xiàn)PGA 在靈活構(gòu)建高效的大模型推理系統(tǒng)中將發(fā)揮越來越重要的作用。它被認(rèn)為是通往 5G 通信、數(shù)據(jù)中心、無人駕駛等諸多千億美元級別市場的鑰匙。
被 FPGA’24 接收的新成果名為 FlightLLM。在單 batch 場景下相比在同等工藝 V100S GPU 上使用 vLLM 推理框架和 SmoothQuant 量化庫,F(xiàn)lightLLM 可實(shí)現(xiàn) 6.0 倍的能效比提升和 1.8 倍的性價比提升。

放眼未來 1 至 2 年,大模型可能將在代碼補(bǔ)全、實(shí)時聊天機(jī)器人、售后支持等延時敏感應(yīng)用場景中落地。在這些場景中,延時低、功耗小對于用戶的交互體驗至關(guān)重要。
然而,目前大模型的計算量和存儲量相比傳統(tǒng)神經(jīng)網(wǎng)絡(luò)呈現(xiàn)數(shù)量級增加,這導(dǎo)致其推理速度和能效很難滿足這些需要快速反饋、能耗敏感場景的需求。
為解決上述問題,行業(yè)內(nèi)通常采用如稀疏化、量化的方法來壓縮大模型。但是 GPU 硬件平臺僅能支持部分粗粒度的模型壓縮方法,對于定制化的模型壓縮方法的計算效率很低。
作者認(rèn)為,F(xiàn)PGA 具有低成本、可配置、低功耗的特性,可成為加速大模型推理的潛在解決方案。但要想用好,仍需要解決以下挑戰(zhàn):

- 計算效率低下:大模型中靈活的稀疏模式(例如塊稀疏、N:M 稀疏等)導(dǎo)致計算效率低下。
- 內(nèi)存帶寬利用率低:大模型的 decode 階段反復(fù)從片外存儲器中讀寫細(xì)粒度的數(shù)據(jù),導(dǎo)致較低的帶寬利用率(29%-43%)。
- 編譯開銷大:大模型的動態(tài)稀疏模式和可變輸入長度構(gòu)成了一個龐大的指令空間。例如,為 2048 種輸入 token 長度生成指令將導(dǎo)致在 FPGA 上約 TB 量級的存儲開銷。
FlightLLM 的核心思想是利用 FPGA 上特定的資源(如 DSP48 和異構(gòu)存儲層次結(jié)構(gòu))來解決大模型的計算和存儲開銷問題。

FlightLLM的整體架構(gòu)。
盡管在理論上,稀疏可以為大模型推理帶來性能提升,但它們不能直接在現(xiàn)有硬件架構(gòu)上實(shí)現(xiàn)。在基于 Transformer 的大模型中,大多采用稀疏注意力和剪枝等稀疏化方法來加速推理。
然而,稀疏化所生成的稀疏矩陣,其密度和稀疏模式并不確定。這給硬件設(shè)計帶來了很大的挑戰(zhàn),特別是對于 FPGA 這種基于固定 DSP48 乘法單元的架構(gòu)。此前的工作引入了大量額外的硬件架構(gòu)來支持稀疏計算,但這會導(dǎo)致硬件資源顯著增加。根據(jù)估算,需要多消耗近 5 倍的硬件資源。
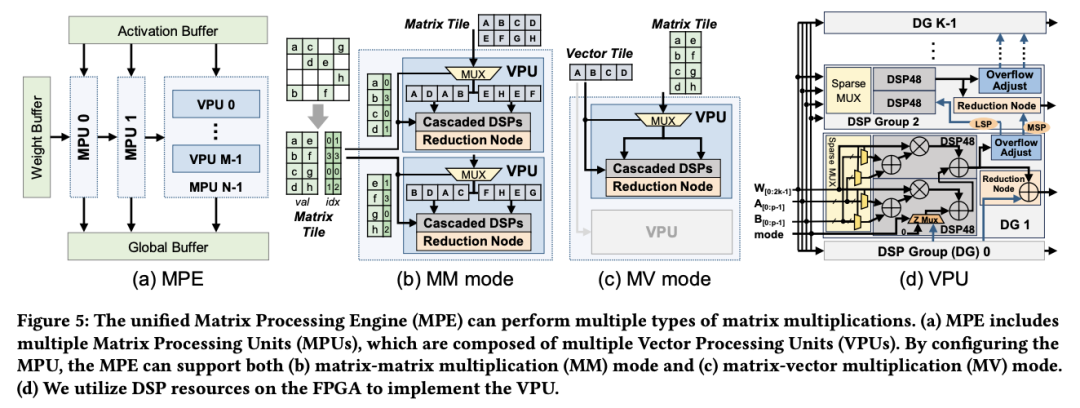
(a) 統(tǒng)一矩陣處理引擎(Matrix Processing Engine, MPE),可靈活支持(b)矩陣-矩陣乘(Matrix-Matrix multiplication, MMMult)和(c)矩陣-向量乘(Matrix-Vector multiplication, MVMult)計算模式。(d)每個MPE由多個基于稀疏DSP48鏈的向量處理引擎(Vector Processing Engine, VPE)組成。
為此,F(xiàn)lightLLM 采用了軟硬件協(xié)同設(shè)計來克服低計算效率的挑戰(zhàn)。研究者設(shè)計了統(tǒng)一的矩陣處理引擎(MPE),以處理與矩陣計算相關(guān)的所有操作(見上圖)。
此前的工作均通過級聯(lián) DSP 來充分利用 DSP48 的硬件資源來減少硬件開銷。然而,由于級聯(lián)鏈的路徑是固定的,因此完全級聯(lián)的 DSP 架構(gòu)對稀疏計算不友好。
FlightLLM 在這一問題上提出了針對性的解決方案。FlightLLM 利用 FPGA 上的 DSP48 計算單元,設(shè)計了一個可配置的稀疏 DSP 鏈。稀疏 DSP 鏈支持多種的稀疏模式,其計算效率(即運(yùn)行時 DSP 利用率)提升了 1.6 倍。
此外,在解碼階段,作者發(fā)現(xiàn)大模型推理的主要效率限制來自于頻繁訪問片外存儲器的小數(shù)據(jù)量激活向量。
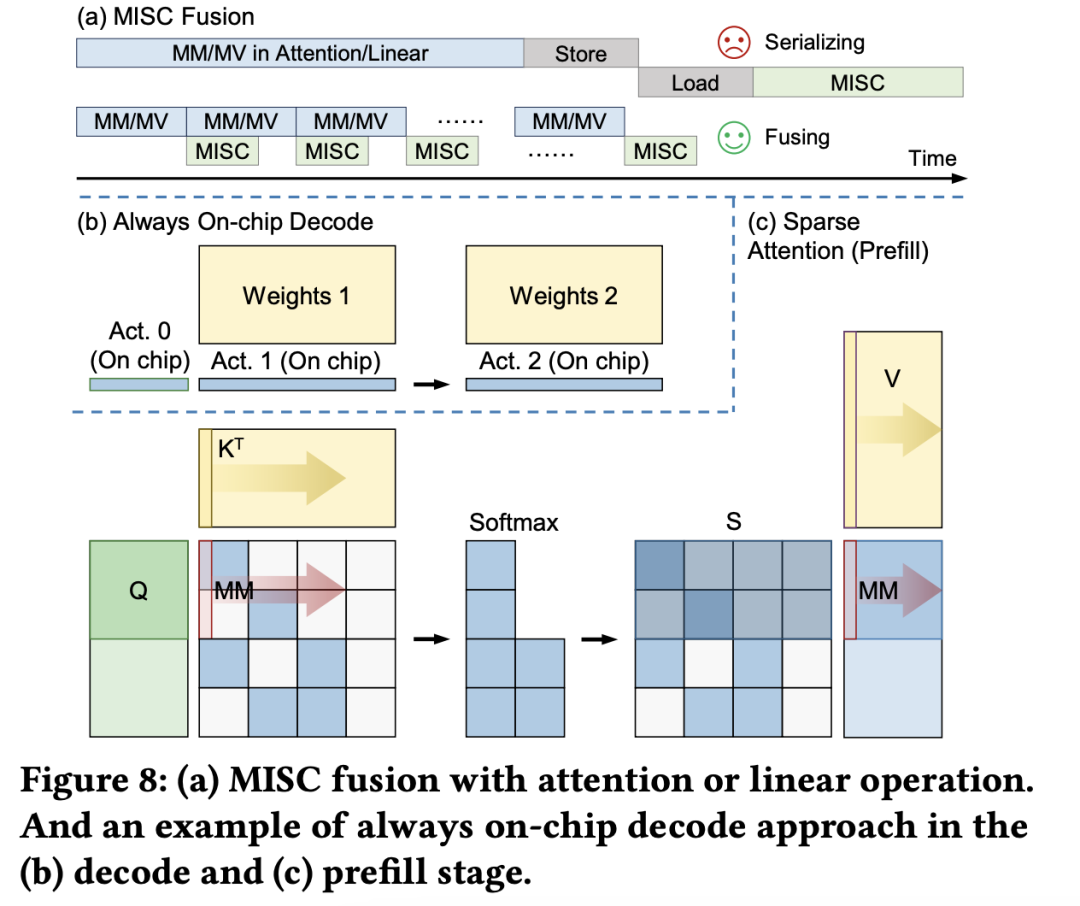
(a)大模型推理階段的注意力層/線性層與非線性激活操作(MISC)的算子融合實(shí)現(xiàn);全片上解碼在(b)預(yù)取(Prefill)階段和(c)解碼(Decode)階段的示意圖:利用算子融合和FPGA的高片上存儲,使得大模型推理解碼階段的激活值無須寫到片外。
為了減少激活向量的片外存儲器訪問,解決訪存帶寬利用率低的挑戰(zhàn),F(xiàn)lightLLM 使用了算子融合技術(shù),將解碼階段每次推斷中的計算進(jìn)行融合,提出了 always-on-chip decode 的數(shù)據(jù)流。通過混合精度量化和算子融合的設(shè)計,將 decode 階段的激活值最大程度在片上緩存中復(fù)用。
最后,由于大模型每次推理過程 token 長度都會增加,因此需要不同的指令。而大模型有大量計算和存儲需求,即使使用粗粒度指令,指令數(shù)量仍然非常龐大。

通過在不同輸入 token 長度下推理性能的測量,作者觀察到 prefill 和 decode 的延時和輸入 token 長度之間的關(guān)系存在著 「階梯」增長的特征,并且 prefill 階段延時隨輸入 token 長度增加得更快。
這是因為 prefill 階段是計算瓶頸,計算量隨 token 長度顯著增加;而 decode 階段是訪存瓶頸,因此延時增加不明顯。階梯狀增長的原因則主要是粗粒度指令集。由于矩陣 - 矩陣乘指令的輸出并行度是 128,矩陣 - 向量乘的輸出并行度是 16,因此 prefill 和 decode 的 「階梯」 的寬度分別為 128 和 16。
基于這些發(fā)現(xiàn),F(xiàn)lightLLM 提出了一種 token 長度自適應(yīng)的編譯方法,通過復(fù)用 prefill 階段和 decode 階段的指令來減少編譯指令的存儲開銷,進(jìn)而對每個 「階梯」輸入 token 長度的指令分組,以 「階梯」 寬度復(fù)用指令序列。這種設(shè)計顯著減少了指令的總存儲開銷。
目前,作者已在 Xilinx Alveo U280 FPGA(16nm)上實(shí)現(xiàn)了 FlightLLM。在 OPT-6.7B 和 LLaMA2-7B 上的實(shí)驗結(jié)果表明,F(xiàn)lightLLM 的端到端延遲優(yōu)于 NVIDIA V100S GPU。

此外,F(xiàn)lightLLM(基于 U280 FPGA 和 VHK158 FPGA)在能效上超過了 NVIDIA V100S 和 A100 GPU,分別提高了 6.0× 和 4.2×,在性價比上提高了 1.8× 和 1.5×。
更多詳細(xì)細(xì)節(jié),請參閱論文原文。






















