國內(nèi)最大MoE開源大模型來了,還基于此搞出個火遍港臺的AI聊天應用
元象 XVERSE 發(fā)布中國最大 MoE 開源模型:XVERSE-MoE-A36B,加速 AI 應用低成本部署,將國產(chǎn)開源提升至國際領(lǐng)先水平。
該模型總參數(shù) 255B,激活參數(shù) 36B,達到 100B 模型性能的「跨級」躍升,同時訓練時間減少 30%,推理性能提升 100%,使每 token 成本大幅下降。
元象「高性能全家桶」系列全部開源,無條件免費商用,讓海量中小企業(yè)、研究者和開發(fā)者能按需選擇。

MoE(Mixture of Experts)是業(yè)界最前沿的混合專家模型架構(gòu) ,將多個細分領(lǐng)域的專家模型組合成一個超級模型,打破了傳統(tǒng)擴展定律(Scaling Law)的局限,可在擴大模型規(guī)模時,不顯著增加訓練和推理的計算成本,保持模型性能最大化。出于這個原因,行業(yè)前沿模型包括谷歌 Gemini-1.5、OpenAI 的 GPT-4 、馬斯克旗下 xAI 公司的 Grok 等大模型都使用了 MoE。
在多個權(quán)威評測中,元象 MoE 效果大幅超越多個同類模型,包括國內(nèi)千億 MoE 模型 Skywork-MoE、傳統(tǒng) MoE 霸主 Mixtral-8x22B 以及 3140 億參數(shù)的 MoE 開源模型 Grok-1-A86B 等。

免費下載大模型
- Hugging Face:https://huggingface.co/xverse/XVERSE-MoE-A36B
- 魔搭:https://modelscope.cn/models/xverse/XVERSE-MoE-A36B
- Github:https://github.com/xverse-ai/XVERSE-MoE-A36B
- 官網(wǎng):chat.xverse.cn
落地應用好且省 登頂港臺娛樂應用榜
元象此次開源,不僅填補國內(nèi)空白,也在商業(yè)應用上更進一步。
元象基于 MoE 模型自主研發(fā)的 AI 角色扮演與互動網(wǎng)文 APP Saylo,通過逼真的 AI 角色扮演和有趣的開放劇情,火遍港臺,下載量在中國臺灣和香港娛樂榜分別位列第一和第三。
MoE 訓練范式具有「更高性能、更低成本」優(yōu)勢,元象在通用預訓練基礎(chǔ)上,使用海量劇本數(shù)據(jù)「繼續(xù)預訓練」(Continue Pre-training),并與傳統(tǒng) SFT(監(jiān)督微調(diào))或 RLHF(基于人類反饋的強化學習)不同,采用了大規(guī)模語料知識注入,讓模型既保持了強大的通用語言理解能力,又大幅提升「劇本」這一特定應用領(lǐng)域的表現(xiàn)。

高性能「開源標桿」
元象是國內(nèi)領(lǐng)先的 AI 與 3D 公司,秉持「通用人工智能 AGI」信仰,持續(xù)打造「高性能開源全家桶」,不僅填補國產(chǎn)開源空白,更將其推向了國際領(lǐng)先水平。

2023 年 11 月,此前國內(nèi)大部分開源參數(shù)多在 7B 到 13B,而行業(yè)共識是模型達到 50 到 60B 參數(shù)門檻,大模型才能「智能涌現(xiàn)」,生態(tài)亟需「大」模型時,元象率先開源了 XVERSE-65B,是當時中國最大參數(shù)開源。

2024 年 1 月,元象又開源全球最長上下文窗口大模型,支持輸入 25 萬漢字,還附手把手訓練教程,讓大模型應用一舉進入「長文本時代」。

此次國內(nèi)最大參數(shù) MoE 開源,又是給生態(tài)貢獻了一個助推低成本 AI 應用利器。
引領(lǐng)文娛應用
借助在 AI 和 3D 領(lǐng)域的客戶積累,元象也迅速將大模型推向商用。
2023 年 11 月,元象成為全國最早一批、廣東省前五獲得《生成式人工智能服務管理暫行辦法》國家備案的大模型,具備向全社會開放的產(chǎn)品能力。

而在更早的 10 月,元象與騰訊音樂聯(lián)合推出 lyraXVERSE 加速大模型,并借助該技術(shù)全面升級音樂助手「AI 小琴」的問答、聊天與創(chuàng)作能力,讓她情商與智商雙高,為用戶提供個性化、更深入、陪伴感十足的音樂互動體驗。

元象大模型陸續(xù)與 QQ 音樂、虎牙直播、全民 K 歌、騰訊云等深度合作與應用探索,為文化、娛樂、旅游、金融領(lǐng)域打造創(chuàng)新領(lǐng)先的用戶體驗。

MoE 技術(shù)自研與創(chuàng)新
MoE 是目前業(yè)界最前沿的模型框架,由于技術(shù)較新,國內(nèi)開源模型或?qū)W術(shù)研究尚未普及。元象自研 MoE 的高效訓練和推理框架,并持續(xù)推動技術(shù)創(chuàng)新。
2024 年 4 月推出的 XVERSE-MoE-A4.2B 中,元象推動 MoE 專家架構(gòu)革新。與傳統(tǒng) MoE(如 Mixtral 8x7B)將每個專家大小等同于標準 FFN 不同,元象采用更細粒度的專家設計,每個專家大小僅為標準 FFN 的四分之一,提高了模型靈活性與性能;還將專家分為共享專家(Shared Expert)和非共享專家(Non-shared Expert)兩類。共享專家在計算過程中始終保持激活狀態(tài),而非共享專家則根據(jù)需要選擇性激活。這種設計有利于將通用知識壓縮至共享專家參數(shù)中,減少非共享專家參數(shù)間的知識冗余。

此次推出 XVERSE-MoE-A36B,繼續(xù)在 MoE 效率和效果方面進行技術(shù)創(chuàng)新。
(1)效率方面
MoE 架構(gòu)與 4D 拓撲設計:MoE 架構(gòu)的關(guān)鍵特性是由多個專家組成。由于專家之間需要大量的信息交換,通信負擔極重。為了解決這個問題,我們采用了 4D 拓撲架構(gòu),平衡了通信、顯存和計算資源的分配。這種設計優(yōu)化了計算節(jié)點之間的通信路徑,提高了整體計算效率。
專家路由與預丟棄策略:MoE 的另一個特點是「專家路由機制」,即需要對不同的輸入進行分配,并丟棄一些超出專家計算容量的冗余數(shù)據(jù)。為此團隊設計一套預丟棄策略,減少不必要的計算和傳輸。同時在計算流程中實現(xiàn)了高效的算子融合,進一步提升模型的訓練性能。
通信與計算重疊:由于 MoE 架構(gòu)的專家之間需要大量通信,會影響整體計算效率。為此團隊設計了「多維度的通信與計算重疊」機制,即在進行參數(shù)通信的同時,最大比例并行地執(zhí)行計算任務,從而減少通信等待時間。
(2)效果方面
專家權(quán)重:MoE 中的專家總數(shù)為 N ,每個 token 會選擇 topK 個專家參與后續(xù)的計算,由于專家容量的限制,每個 token 實際選擇到的專家數(shù)為 M,M<=K<N。被選擇到的專家計算完之后,會通過加權(quán)平均的方式匯總得到每個 token 的計算結(jié)果。這里專家的權(quán)重如何設置是一個問題,我們通過對比實驗的方式來進行選擇。根據(jù)對比實驗的效果,我們選擇實驗 2 的設置進行正式實驗。
實驗 1:權(quán)重在 topM 范圍內(nèi)歸一化
實驗 2:權(quán)重在 topK 范圍內(nèi)歸一化
實驗 3:權(quán)重在 topN 范圍內(nèi)歸一化
實驗 4:權(quán)重都為 1
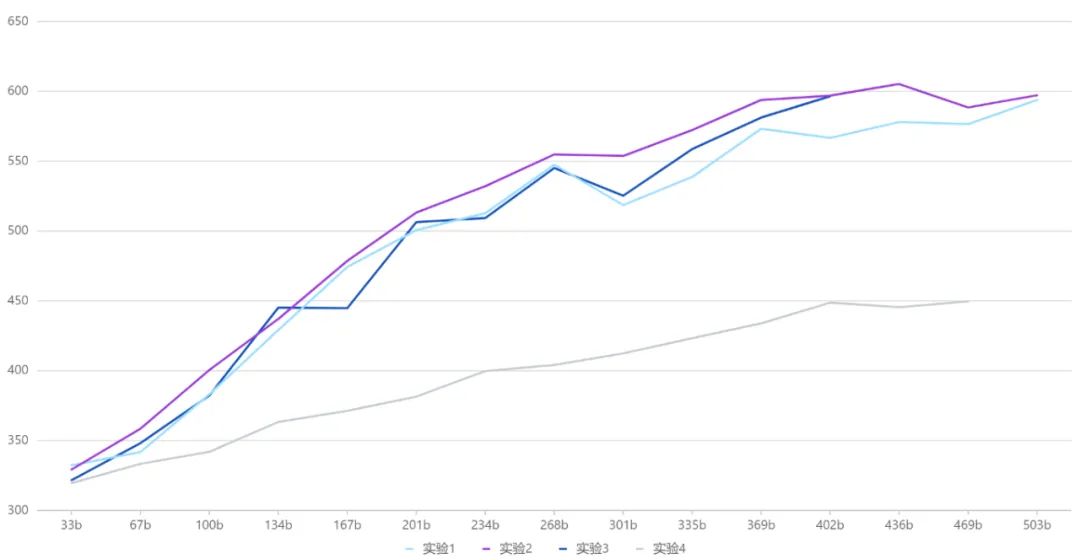
對比實驗結(jié)果
舉例說明,假設 N=8,K=4,M=3(2 號專家上 token 被丟棄),不同專家權(quán)重的計算方式所得的權(quán)重如下圖:

數(shù)據(jù)動態(tài)切換:元象以往開源的模型,往往在訓練前就鎖定了訓練數(shù)據(jù)集,并在整個訓練過程中保持不變。這種做法雖然簡單,但會受制于初始數(shù)據(jù)的質(zhì)量和覆蓋面。此次 MoE 模型的訓練借鑒了「課程學習」理念,在訓練過程中實現(xiàn)了動態(tài)數(shù)據(jù)切換,在不同階段多次引入新處理的高質(zhì)量數(shù)據(jù),并動態(tài)調(diào)整數(shù)據(jù)采樣比例。
這讓模型不再被初始語料集所限制,而是能夠持續(xù)學習新引入的高質(zhì)量數(shù)據(jù),提升了語料覆蓋面和泛化能力。同時通過調(diào)整采樣比例,也有助于平衡不同數(shù)據(jù)源對模型性能的影響。

不同數(shù)據(jù)版本的效果曲線圖
學習率調(diào)度策略(LR Scheduler):在訓練過程中動態(tài)切換數(shù)據(jù)集,雖有助于持續(xù)引入新知識,但也給模型帶來了新的適應挑戰(zhàn)。為了確保模型能快速且充分地學習新進數(shù)據(jù),團隊對學習率調(diào)度器進行了優(yōu)化調(diào)整,在每次數(shù)據(jù)切換時會根據(jù)模型收斂狀態(tài),相應調(diào)整學習率。實驗表明,這一策略有效提升了模型在數(shù)據(jù)切換后的學習速度和整體訓練效果。
下圖是整個訓練過程中 MMLU、HumanEval 兩個評測數(shù)據(jù)集的效果曲線圖。

訓練過程中 MMLU、HumanEval 的性能曲線持續(xù)拔高
通過設計與優(yōu)化,元象 MoE 模型與其 Dense 模型 XVERSE-65B-2 相比,訓練時間減少 30%、推理性能提升 100%,模型效果更佳,達到業(yè)界領(lǐng)先水平。