













譯者 | 朱先忠
審校 | 重樓
簡(jiǎn)介

隨著大型語(yǔ)言模型(LLM)席卷全球,向量搜索引擎也緊隨其后。同時(shí),向量數(shù)據(jù)庫(kù)也構(gòu)成大型語(yǔ)言模型長(zhǎng)期記憶系統(tǒng)的基礎(chǔ)。
通過(guò)有效的算法找到相關(guān)信息并使其作為上下文傳遞給語(yǔ)言模型,向量搜索引擎可以提供超出訓(xùn)練截止值的最新信息,并在不進(jìn)行微調(diào)的情況下提高模型輸出的質(zhì)量。這個(gè)過(guò)程通常被稱為檢索增強(qiáng)生成(RAG:Retrieval Augmented Generation),它將近似最近鄰(ANN:Approximate Nearest Neighbor)搜索這一曾經(jīng)深?yuàn)W的算法挑戰(zhàn)推向了機(jī)器學(xué)習(xí)領(lǐng)域聚光燈下!
在所有眾說(shuō)紛紜的爭(zhēng)議中,人們普遍認(rèn)為向量搜索引擎與大型語(yǔ)言模型有著密不可分的聯(lián)系。相關(guān)的故事還有很多很多。基于向量搜索技術(shù),已經(jīng)存在大量強(qiáng)大的應(yīng)用程序,遠(yuǎn)遠(yuǎn)超出改進(jìn)LLM的檢索增強(qiáng)生成這一種技術(shù)!
在這篇文章中,我將向您展示向量搜索引擎在數(shù)據(jù)理解、數(shù)據(jù)探索、模型可解釋性等方面的十個(gè)我最喜歡的應(yīng)用案例。
以下是我們將要介紹的應(yīng)用程序,按其復(fù)雜性大致遞增的順序分別是:
- 圖像相似性搜索
- 反向圖像搜索
- 對(duì)象相似性搜索
- 穩(wěn)健型OCR文檔搜索
- 語(yǔ)義搜索
- 跨模型檢索
- 探索感知相似性
- 比較模型表示
- 概念插值
- 概念空間遍歷
1.圖像相似性搜索
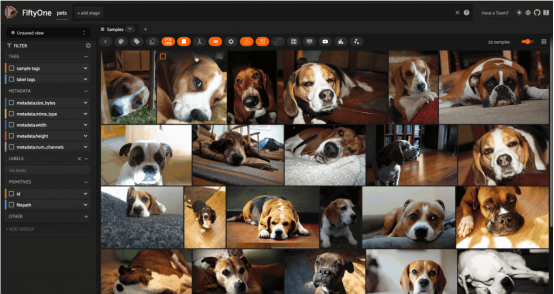
對(duì)來(lái)自O(shè)xford IIIT寵物數(shù)據(jù)集(已獲許可證)的圖像進(jìn)行圖像相似性搜索(圖片由作者本人提供)
也許最簡(jiǎn)單的應(yīng)用算是圖像相似性搜索。在這種應(yīng)用中,你首先要準(zhǔn)備一個(gè)由圖像組成的數(shù)據(jù)集——它可以是任何東西,從簡(jiǎn)單的個(gè)人相冊(cè)到極其復(fù)雜的經(jīng)數(shù)千臺(tái)分布式相機(jī)多年來(lái)拍攝的數(shù)十億張圖像的龐大存儲(chǔ)庫(kù)。
設(shè)置準(zhǔn)備階段很簡(jiǎn)單:首先計(jì)算該數(shù)據(jù)集中每一幅圖像的嵌入,并從這些嵌入向量中生成一個(gè)對(duì)應(yīng)的向量索引值。在最初的批計(jì)算之后,不需要作進(jìn)一步的推斷。探索此數(shù)據(jù)集結(jié)構(gòu)的一個(gè)好方法是從數(shù)據(jù)集中選擇一張圖像,然后查詢向量索引中的k個(gè)最近鄰居(最相似的圖像)。這種方式可以為查詢圖像周圍的圖像空間填充的密度提供一種直觀的感覺(jué)。
有關(guān)圖像相似性搜索的更多信息和工作代碼,請(qǐng)參閱鏈接https://docs.voxel51.com/user_guide/brain.html#image-similarity。
2.反向圖像搜索
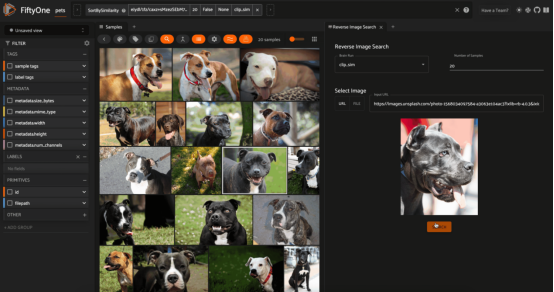
根據(jù)牛津IIIT寵物數(shù)據(jù)集對(duì)Unsplash(由Mladen ??eki?提供)網(wǎng)站的圖像進(jìn)行反向圖像搜索(圖片由作者本人提供)
類似地,圖像相似性搜索的一個(gè)自然擴(kuò)展是在數(shù)據(jù)集中找到與外部圖像最相似的圖像。這可以是來(lái)自本地文件系統(tǒng)的圖像,也可以是來(lái)自互聯(lián)網(wǎng)的圖像!
要執(zhí)行反向圖像搜索,也要首先為數(shù)據(jù)集創(chuàng)建向量索引,這與圖像相似性搜索示例中介紹的是一樣的。二者的區(qū)別在于運(yùn)行時(shí)階段,即計(jì)算查詢圖像的嵌入,然后使用該向量查詢向量數(shù)據(jù)庫(kù)。
有關(guān)反向圖像搜索的更多信息和工作代碼,請(qǐng)參閱鏈接:https://github.com/jacobmarks/reverse-image-search-plugin。
3.對(duì)象相似性搜索
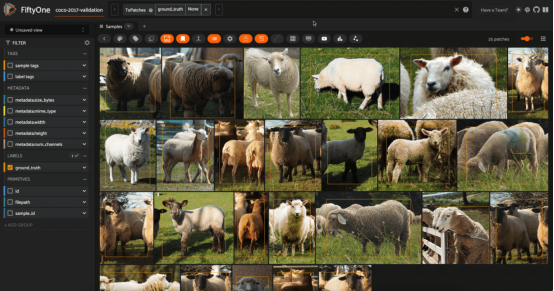
COCO-2017數(shù)據(jù)集驗(yàn)證分割(經(jīng)許可)中針對(duì)綿羊的對(duì)象相似性搜索(圖片由作者本人提供)
如果你想更深入地研究圖像中的內(nèi)容,那么對(duì)象或“圖塊”相似性搜索可能就是你想要研究的內(nèi)容。其中一個(gè)這方面的例子是人物重新識(shí)別,即您有一張帶有感興趣人物的圖像,并且您希望在數(shù)據(jù)集中找到該人物的所有實(shí)例。
人可能只占據(jù)每個(gè)圖像的一小部分,因此他們所處的整個(gè)圖像的嵌入可能強(qiáng)烈依賴于這些圖像中的其他內(nèi)容——例如,一張圖片中可能有多個(gè)人。
一個(gè)更好的解決方案是將每個(gè)對(duì)象檢測(cè)圖塊視為一個(gè)單獨(dú)的實(shí)體,并計(jì)算每個(gè)對(duì)象的嵌入。然后,用這些補(bǔ)圖塊創(chuàng)建一個(gè)向量索引,并對(duì)要重新識(shí)別的人的圖塊進(jìn)行相似性搜索。作為一個(gè)這方面的學(xué)習(xí)起點(diǎn),您可能首先需要學(xué)會(huì)使用ResNet模型。
這里有兩個(gè)微妙之處:
- 在向量索引中,需要存儲(chǔ)元數(shù)據(jù),將每個(gè)補(bǔ)丁映射回?cái)?shù)據(jù)集中對(duì)應(yīng)的圖像。
- 在實(shí)例化索引之前,您需要運(yùn)行一個(gè)對(duì)象檢測(cè)模型來(lái)生成這些檢測(cè)圖塊。您可能還希望只計(jì)算某些類對(duì)象(如人)的圖塊嵌入,而不計(jì)算其他類對(duì)象(椅子、桌子等)。有關(guān)對(duì)象相似性搜索的更多信息和工作代碼,請(qǐng)參閱鏈接:https://docs.voxel51.com/user_guide/brain.html#object-similarity。
4.穩(wěn)健型OCR文檔搜索
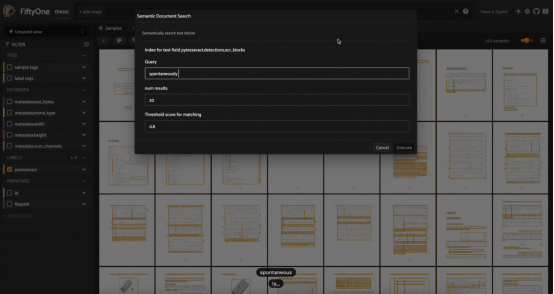
使用我的博士論文中的Tesseract OCR引擎生成的文本塊進(jìn)行模糊/語(yǔ)義搜索,這里使用GTE-base模型進(jìn)行嵌入計(jì)算(圖片由作者本人提供)
光學(xué)字符識(shí)別(OCR)是一種可以將手寫(xiě)筆記、舊期刊文章、醫(yī)療記錄和藏在壁櫥里的情書(shū)等文檔數(shù)字化的技術(shù)。像Tesseract和PaddleOCR這樣的OCR引擎的工作原理是識(shí)別圖像中的單個(gè)字符和符號(hào),并創(chuàng)建連續(xù)的文本“塊”——比如段落。
一旦你有了這樣的文本,你就可以在預(yù)測(cè)的文本塊上執(zhí)行傳統(tǒng)的自然語(yǔ)言關(guān)鍵字搜索,如鏈接https://github.com/jacobmarks/keyword-search-plugin處提供的插件源碼所實(shí)現(xiàn)的那樣。然而,這種搜索方法容易出現(xiàn)單字符錯(cuò)誤。如果OCR引擎意外地將“l(fā)”識(shí)別為“1”,則搜索“control”的關(guān)鍵字將失敗。
我們可以使用向量搜索來(lái)克服這一挑戰(zhàn)!使用文本嵌入模型嵌入文本塊,如Hugging Face的句子轉(zhuǎn)換器庫(kù)中的GTE-base模型,并創(chuàng)建一個(gè)向量索引。然后,我們可以通過(guò)嵌入搜索文本和查詢索引,在數(shù)字化文檔中執(zhí)行模糊和/或語(yǔ)義搜索。從宏觀角度上看,這些文檔中的文本塊類似于對(duì)象相似性搜索中的對(duì)象檢測(cè)補(bǔ)丁!
有關(guān)穩(wěn)健型OCR文檔搜索應(yīng)用的更多信息和工作代碼,請(qǐng)參閱鏈接:https://github.com/jacobmarks/semantic-document-search-plugin。
5.語(yǔ)義搜索

在COCO 2017驗(yàn)證拆分集合中使用自然語(yǔ)言進(jìn)行語(yǔ)義圖像搜索(圖片由作者本人提供)
通過(guò)多模態(tài)模型,我們可以將語(yǔ)義搜索的概念從文本擴(kuò)展到圖像。像CLIP、OpenCLIP和MetaCLIP這樣的模型被訓(xùn)練來(lái)找到圖像及其字幕的常見(jiàn)表示,因此狗的圖像的嵌入向量將與文本提示“a photo of a dog(狗的照片)”的嵌入向量非常相似。
這意味著,明智的做法是(即“允許”我們)從數(shù)據(jù)集中圖像的CLIP嵌入中創(chuàng)建一個(gè)向量索引,然后對(duì)該向量數(shù)據(jù)庫(kù)運(yùn)行向量搜索查詢,其中查詢向量是文本提示的CLIP嵌入式。
值得注意的是,通過(guò)將視頻中的各個(gè)幀視為圖像,并將每個(gè)幀的嵌入添加到向量索引中,您還可以實(shí)現(xiàn)在視頻中進(jìn)行語(yǔ)義搜索!
有關(guān)語(yǔ)義搜索算法的更多信息和工作代碼,請(qǐng)參閱鏈接:https://docs.voxel51.com/user_guide/brain.html#text-similarity。
6.跨模型檢索
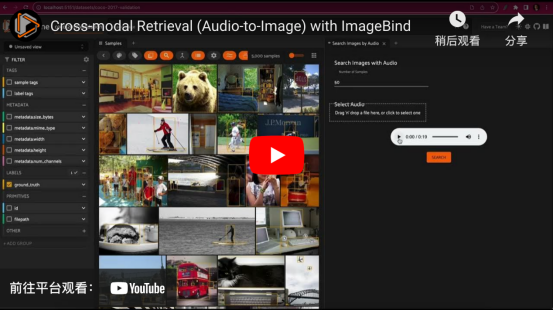
與一列火車中的輸入音頻文件匹配的圖像跨模型檢索。這是使用ImageBind和Qdrant向量索引在COCO 2017驗(yàn)證拆分集上實(shí)現(xiàn)的(視頻由作者本人提供)
從某種意義上說(shuō),在圖像數(shù)據(jù)集中進(jìn)行語(yǔ)義搜索是一種跨模型檢索形式。從概念角度來(lái)解釋這種算法的話,我們檢索與文本查詢相對(duì)應(yīng)的圖像。有了像ImageBind這樣的模型工具,我們就可以更深入地研究這方面的應(yīng)用!
ImageBind將來(lái)自六種不同模態(tài)的數(shù)據(jù)(圖像、文本、音頻、深度、熱和慣性測(cè)量單元)嵌入同一嵌入空間。這意味著,我們可以為這些模態(tài)中的任何一種生成向量索引,并使用這些模態(tài)中任何其他模態(tài)的樣本查詢?cè)撍饕@纾覀兛梢耘臄z一個(gè)汽車?guó)Q喇叭的音頻片段,并檢索所有汽車的圖像!
有關(guān)跨模型檢索的更多信息和工作代碼,請(qǐng)參閱鏈接:https://github.com/jacobmarks/audio-retrieval-plugin。
7.探索感知相似性
向量搜索故事的一個(gè)非常重要的部分是模型,到目前為止我們基本上沒(méi)有作相關(guān)性介紹。其實(shí),我們的向量索引中的元素是來(lái)自模型的嵌入。這些嵌入可以是定制嵌入模型的最終輸出,也可以是在另一個(gè)任務(wù)(如分類)上訓(xùn)練的模型的隱藏或潛在表示。
無(wú)論如何,我們用來(lái)嵌入樣本的模型可能會(huì)對(duì)驗(yàn)證哪些樣本與其他樣本最相似產(chǎn)生重大影響。對(duì)于CLIP模型來(lái)說(shuō),它能夠捕獲語(yǔ)義概念,但難以表示圖像中的結(jié)構(gòu)信息。另一方面,ResNet模型非常善于表示結(jié)構(gòu)和布局的相似性,能夠在像素和圖像切片的級(jí)別上進(jìn)行操作。然后是像DreamSim這樣的嵌入模型,該模型的目的是彌合差距并捕捉中等水平的相似性——將模型的相似性概念與人類感知的內(nèi)容相一致。
最后,我們重點(diǎn)介紹一下向量搜索。這種搜索技術(shù)為我們提供了一種探索模型如何“看到”世界的方法。可以說(shuō),通過(guò)為我們感興趣的每個(gè)模型(在相同的數(shù)據(jù)上)創(chuàng)建一個(gè)單獨(dú)的向量索引,我們就可以快速找到不同模型如何在內(nèi)部表示數(shù)據(jù)的直覺(jué)結(jié)論。
以下是一個(gè)示例,展示了在NIGHTS數(shù)據(jù)集上使用CLIP、ResNet和DreamSim模型嵌入的相同查詢圖像的相似性搜索結(jié)果:
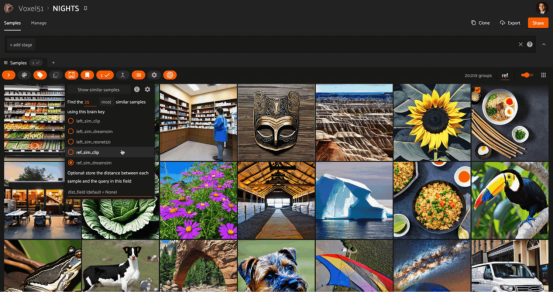
在NIGHTS數(shù)據(jù)集中的圖像上嵌入ResNet50的相似性搜索(使用Stable Diffusion生成的圖像)其中,ResNet模型在像素和圖塊級(jí)別上運(yùn)行;因此,檢索到的圖像在結(jié)構(gòu)上與查詢相似,但并不總是在語(yǔ)義上相似
在同一查詢圖像上嵌入CLIP的相似性搜索。CLIP模型尊重圖像的底層語(yǔ)義,但不尊重它們的布局
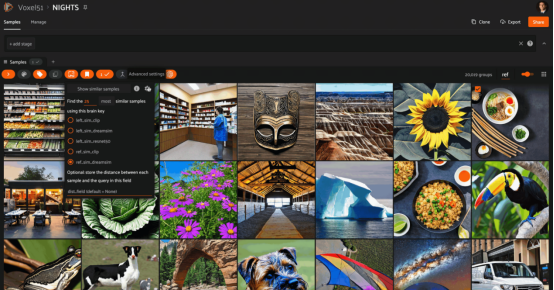
在同一查詢圖像上嵌入DreamSim的相似性搜索結(jié)果。DreamSim彌合了這一差距,在語(yǔ)義和結(jié)構(gòu)特征之間尋求最佳的中級(jí)相似性折衷
有關(guān)探索感知相似性的更多信息和工作代碼,請(qǐng)參閱鏈接:https://medium.com/voxel51/teaching-androids-to-dream-of-sheep-18d72f44f2b。
8.比較模型表示
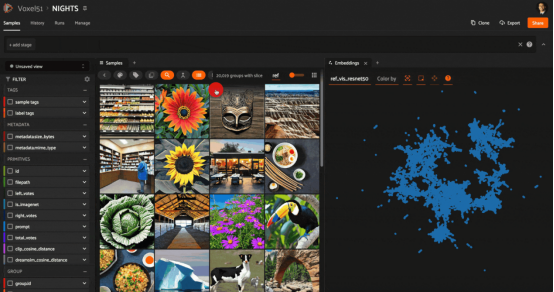
NIGHTS數(shù)據(jù)集的ResNet50和CLIP模型表示的啟發(fā)式比較。ResNet嵌入已經(jīng)使用UMAP(統(tǒng)一流形逼近與投影)方法減少到2D。在嵌入圖中選擇一個(gè)點(diǎn)并突出顯示附近的樣本,我們可以看到ResNet是如何捕捉構(gòu)圖和調(diào)色板的相似性而不是語(yǔ)義的相似性的。在具有CLIP嵌入的所選樣本上運(yùn)行向量搜索,我們可以看到,根據(jù)CLIP的大多數(shù)樣本沒(méi)有被ResNet搜索到。
通過(guò)將向量搜索和統(tǒng)一流形逼近與投影(UMAP:https://umap-learn.readthedocs.io/en/latest/)等降維技術(shù)相結(jié)合,我們可以對(duì)兩個(gè)模型之間的差異有新的了解。方法如下:
每個(gè)模型的嵌入中都包含有關(guān)模型如何表示數(shù)據(jù)的信息。借助于UMAP(或t-SNE或PCA)技術(shù),我們可以從原始模型(model1)生成嵌入的低維(2D或3D)表示。通過(guò)這樣做,我們犧牲了一些細(xì)節(jié),但希望保留一些關(guān)于哪些樣本被認(rèn)為與其他樣本相似的信息。另一方面,我們獲得的是將這些數(shù)據(jù)可視化的能力。
以原始模型(model1)的嵌入可視化為背景,我們可以在該圖中選擇一個(gè)點(diǎn),并針對(duì)模型2(model2)的嵌入對(duì)該樣本執(zhí)行向量搜索查詢。然后,我們就可以看到在2D可視化中檢索到的點(diǎn)所在的位置!
前面的示例使用的是與上一節(jié)中相同的NIGHTS數(shù)據(jù)集,對(duì)ResNet嵌入可視化,結(jié)果可以捕獲更多的組成方面和結(jié)構(gòu)方面的相似性信息,并使用CLIP(語(yǔ)義方面)嵌入執(zhí)行相似性搜索。
9.概念插值
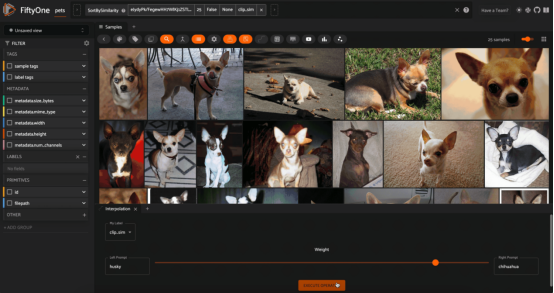
在Oxford IIIT寵物數(shù)據(jù)集上使用CLIP嵌入的“哈士奇(husky)”和“吉娃娃(chihuahua)”概念之間的插值
現(xiàn)在差不多到了本文的末尾,但幸運(yùn)的是,我把一些最好的內(nèi)容留到了最后。到目前為止,我們處理過(guò)的向量只有嵌入——向量索引是用嵌入填充的,查詢向量也是嵌入的。但有時(shí)在嵌入空間中還有額外的結(jié)構(gòu),我們可以利用它來(lái)更動(dòng)態(tài)地與數(shù)據(jù)交互。
這種動(dòng)態(tài)交互的一個(gè)例子是我喜歡的“概念插值”。它的工作原理如下:首先獲取圖像數(shù)據(jù)集,然后使用多模態(tài)模型(文本和圖像)生成向量索引。例如,選擇兩個(gè)文本提示,如“sunny”和“raining”,它們代表概念,并將值alpha設(shè)置在[0,1]范圍內(nèi)。我們可以為每個(gè)文本概念生成嵌入向量,并將這些向量添加到alpha指定的線性組合中。然后,我們對(duì)向量進(jìn)行歸一化,并將其用作對(duì)圖像嵌入的向量索引的查詢。
因?yàn)槲覀冊(cè)趦蓚€(gè)文本提示(概念)的嵌入向量之間進(jìn)行線性插值,所以我們?cè)诟拍畋旧碇g進(jìn)行非常松散的插值!我們可以動(dòng)態(tài)地更改alpha,并在每次交互時(shí)查詢我們的向量數(shù)據(jù)庫(kù)。
注意,這種概念插值的概念是實(shí)驗(yàn)性的(記住:這并不總是一個(gè)定義良好的操作)。我發(fā)現(xiàn),當(dāng)文本提示在概念上相關(guān),并且數(shù)據(jù)集足夠多樣化,而且在插值譜系的不同位置有不同的結(jié)果時(shí),它的效果最好。
有關(guān)概念插值的更多信息和工作代碼,請(qǐng)參閱鏈接:https://github.com/jacobmarks/concept-interpolation。
10.概念空間遍歷
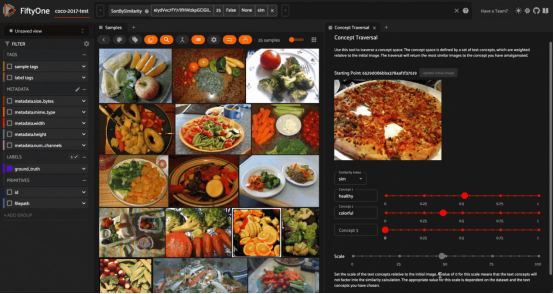
通過(guò)嵌入在各種文本提示的方向上移動(dòng)來(lái)遍歷“概念”的空間,這里給出的是在COCO 2017數(shù)據(jù)集的測(cè)試拆分子集上展示的結(jié)果。這里使用的是嵌入CLIP模型的圖像和文本(圖片由作者本人提供)
最后,還有很重要的一種應(yīng)用是我喜歡的“概念空間遍歷”。與概念插值一樣,這種應(yīng)用從圖像數(shù)據(jù)集開(kāi)始,使用CLIP等多模態(tài)模型生成嵌入。然后,從數(shù)據(jù)集中選擇一個(gè)圖像。這個(gè)圖像將作為你的起點(diǎn),從這里你可以“穿越”概念的空間。
此后,您可以通過(guò)提供一個(gè)文本字符串作為概念的替代,來(lái)定義您想要移動(dòng)的方向。設(shè)置要在該方向上執(zhí)行的“步長(zhǎng)”的大小,該文本字符串的嵌入向量(具有乘法系數(shù))將添加到初始圖像的嵌入向量中。“目的地(destination)”向量將用于查詢向量數(shù)據(jù)庫(kù)。您可以添加任意數(shù)量的多個(gè)概念,并實(shí)時(shí)觀察檢索到的圖像集的更新。
與“概念插值”一樣,概念空間遍歷并不總是一個(gè)嚴(yán)格定義的過(guò)程。然而,我發(fā)現(xiàn)它很吸引人,并且當(dāng)應(yīng)用于文本嵌入的系數(shù)足夠高時(shí),足以將此系數(shù)充分考慮在內(nèi)時(shí),這種方法的表現(xiàn)還是相當(dāng)好。
有關(guān)概念空間遍歷的更多信息和工作代碼,請(qǐng)參閱鏈接:https://github.com/jacobmarks/concept-space-traversal-plugin。
結(jié)論
向量搜索引擎是非常強(qiáng)大的工具。它們當(dāng)之無(wú)愧可算是機(jī)器學(xué)習(xí)在檢索增強(qiáng)生成領(lǐng)域的“明星”。但其實(shí),向量數(shù)據(jù)庫(kù)的用途遠(yuǎn)不止于此。向量數(shù)據(jù)庫(kù)能夠幫助我們更深入地理解數(shù)據(jù),深入了解模型如何表示數(shù)據(jù),并為我們與數(shù)據(jù)交互提供新的途徑。
注意,向量數(shù)據(jù)庫(kù)未必只關(guān)聯(lián)到大型語(yǔ)言模型領(lǐng)域。事實(shí)證明,無(wú)論何時(shí)涉及嵌入,它們都是有用的,并且嵌入正好位于模型和數(shù)據(jù)的交叉點(diǎn)。我們對(duì)嵌入空間的結(jié)構(gòu)理解得越嚴(yán)格,我們支持向量搜索的數(shù)據(jù)和模型交互就越動(dòng)態(tài)和具有普遍性。
如果你覺(jué)得這篇文章很有趣,你可能還想看看這些向量搜索的相關(guān)帖子:
譯者介紹
朱先忠,51CTO社區(qū)編輯,51CTO專家博客、講師,濰坊一所高校計(jì)算機(jī)教師,自由編程界老兵一枚。
原文標(biāo)題:From RAGs to Riches,作者:Jacob Marks, Ph.D.





















