三行代碼無損加速40%,尤洋團隊AI訓練加速器入選ICLR Oral論文
用剪枝的方式加速AI訓練,也能實現無損操作了,只要三行代碼就能完成!
今年的深度學習頂會ICLR上,新加坡國立大學尤洋教授團隊的一項成果被收錄為Oral論文。
利用這項技術,可以在沒有損失的前提下,節約最高40%的訓練成本。

這項成果叫做InfoBatch,采用的依然是修剪樣本的加速方式。
但通過動態調整剪枝的內容,InfoBatch解決了加速帶來的訓練損失問題。
而且即插即用,不受架構限制,CNN網絡和Transformer模型都能優化。
目前,該算法已經受到了多家云計算公司的關注。

那么,InfoBatch能實現怎樣的加速效果呢?
無損降低40%訓練成本
研究團隊在多個數據集上開展的實驗。都驗證了InfoBatch的有效性。
這些實驗涵蓋的任務包括圖像的分類、分割和生成,以及語言模型的指令微調等。
在圖像分類任務上,研究團隊使用CIFAR10和CIFAR100數據集訓練了ResNet-18。
結果在30%、50%和70%的剪枝率下,InfoBatch的準確率都超越了隨機剪枝和其他baseline方法,而且在30%的剪枝率下沒有任何精度損失。
在剪枝率從30%增加到70%的過程中,InfoBatch的精度損失也顯著低于其他方式。

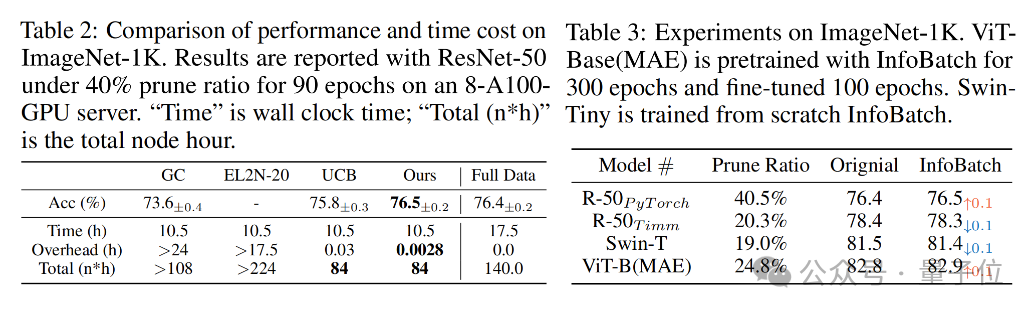
使用ImageNet-1K數據集訓練的ResNet-50時,在剪枝率為40%、epoch數量為90的條件下,InfoBatch可以實現UCB相同的訓練時間,但擁有更高的準確率,甚至超越了全數據訓練。
同時,ImageNet的額外(OverHead)時間成本顯著低于其他方式,僅為0.0028小時,也就是10秒鐘。
在訓練Vit-Base(pre-train階段300epoch,fine-tune階段100epoch模型時,InfoBatch依然可以在24.8%的成本節約率下保持與全量訓練相當的準確率。
跨架構測試比對結果還表明,面對不同的模型架構,InfoBatch表現出了較強的魯棒性。

除此之外,InfoBatch還能兼容現有的優化器,在與不同優化器共同使用時都體現了良好的無損加速效果。

不僅是這些視覺任務,InfoBatch還可以應用于語言模型的監督微調。
在常識(MMLU)、推理(BBH、DROP)等能力沒有明顯損失,甚至編程能力(HumanEval)還有小幅提升的情況下,InfoBatch可以在DQ的基礎上額外減少20%的時間消耗。

另外,根據作者最新更新,InfoBatch在檢測任務(YOLOv8)上也取得了無損加速30%的效果,代碼將會在github更新。
那么,InfoBatch是如何做到無損加速的呢?
動態調整剪枝內容
究其核心奧義,是無偏差的動態數據修剪。
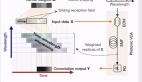
為了消除傳統剪枝方法梯度期望值方向偏差以及總更新量的減少的問題,InfoBatch采用了動態剪枝方式。
InfoBatch的前向傳播過程中,維護了每個樣本的分值(loss),并以均值為閾值,隨機對一定比例的低分樣本進行修剪。
同時,為了維護梯度更新期望,剩余的低分樣本的梯度被相應放大。
通過這種方式,InfoBatch訓練結果和原始數據訓練結果的性能差距相比于之前方法得到了改善。

具體來看,在訓練的前向過程中,InfoBatch會記錄樣本的損失值(loss)來作為樣本分數,這樣基本沒有額外打分的開銷。
對于首個epoch,InfoBatch初始化默認保留所有樣本;之后的每個epoch開始前,InfoBatch會按照剪枝概率r來隨機對分數小于平均值的樣本進行剪枝。
概率的具體表達式如下:

對于分數小于均值但留下繼續參與訓練的樣本,InfoBatch采用了重縮放方式,將對應梯度增大到了1/(1-r),這使得整體更新接近于無偏。
此外,InfoBatch還采用了漸進式的修剪過程,在訓練后期會使用完整的數據集。
這樣做的原因是,雖然理論上的期望更新基本一致,上述的期望值實際包含時刻t的多次取值。
也就是說,如果一個樣本在中間的某個輪次被剪枝,后續依舊大概率被訓練到;但在剩余更新輪次不足時,這個概率會大幅下降,導致殘余的梯度期望偏差。
因此,在最后的幾個訓練輪次中(通常是12.5%~17.5%左右),InfoBatch會采用完整的原始數據進行訓練。
論文地址:https://arxiv.org/abs/2303.04947
GitHub主頁:
https://github.com/NUS-HPC-AI-Lab/InfoBatch