簡(jiǎn)單通用:視覺基礎(chǔ)網(wǎng)絡(luò)最高3倍無(wú)損訓(xùn)練加速,清華EfficientTrain++入選TPAMI 2024
本文經(jīng)計(jì)算機(jī)視覺研究院公眾號(hào)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。

- 論文鏈接:https://arxiv.org/pdf/2405.08768
- 代碼和預(yù)訓(xùn)練模型已開源:https://github.com/LeapLabTHU/EfficientTrain
- 會(huì)議版本論文(ICCV 2023):https://arxiv.org/pdf/2211.09703
計(jì)算機(jī)視覺研究院專欄
Column of Computer Vision Institute
本文主要介紹剛剛被 IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)錄用的一篇文章:EfficientTrain++: Generalized Curriculum Learning for Efficient Visual Backbone Training。
近年來(lái),「scaling」是計(jì)算機(jī)視覺研究的主角之一。隨著模型尺寸和訓(xùn)練數(shù)據(jù)規(guī)模的增大、學(xué)習(xí)算法的進(jìn)步以及正則化和數(shù)據(jù)增強(qiáng)等技術(shù)的廣泛應(yīng)用,通過(guò)大規(guī)模訓(xùn)練得到的視覺基礎(chǔ)網(wǎng)絡(luò)(如 ImageNet1K/22K 上訓(xùn)得的 Vision Transformer、MAE、DINOv2 等)已在視覺識(shí)別、目標(biāo)檢測(cè)、語(yǔ)義分割等諸多重要視覺任務(wù)上取得了令人驚艷的性能。
然而,「scaling」往往會(huì)帶來(lái)令人望而卻步的高昂模型訓(xùn)練開銷,顯著阻礙了視覺基礎(chǔ)模型的進(jìn)一步發(fā)展和工業(yè)應(yīng)用。
面向解決這一問(wèn)題,清華大學(xué)的研究團(tuán)隊(duì)提出了一種廣義課程學(xué)習(xí)(generalized curriculum learning)算法:EfficientTrain++。其核心思想在于,將「篩選和使用由易到難的數(shù)據(jù)、逐步訓(xùn)練模型」的傳統(tǒng)課程學(xué)習(xí)范式推廣至「不進(jìn)行數(shù)據(jù)維度的篩選,一直使用全部訓(xùn)練數(shù)據(jù),但在訓(xùn)練過(guò)程中逐步揭示每個(gè)數(shù)據(jù)樣本的由易到難的特征或模式(pattern)」。
EfficientTrain++ 具有幾個(gè)重要的亮點(diǎn):
- 即插即用地實(shí)現(xiàn)視覺基礎(chǔ)網(wǎng)絡(luò) 1.5?3.0× 無(wú)損訓(xùn)練加速。上游、下游模型性能均不損失。實(shí)測(cè)速度與理論結(jié)果一致。
- 通用于不同的訓(xùn)練數(shù)據(jù)規(guī)模(例如 ImageNet-1K/22K,22K 效果甚至更為明顯)。通用于監(jiān)督學(xué)習(xí)、自監(jiān)督學(xué)習(xí)(例如 MAE)。通用于不同訓(xùn)練開銷(例如對(duì)應(yīng)于 0-300 或更多 epochs)。
- 通用于 ViT、ConvNet 等多種網(wǎng)絡(luò)結(jié)構(gòu)(文中測(cè)試了二十余種尺寸、種類不同的模型,一致有效)。
- 對(duì)較小模型,訓(xùn)練加速之外,還可顯著提升性能(例如在沒(méi)有額外信息幫助、沒(méi)有額外訓(xùn)練開銷的條件下,在 ImageNet-1K 上得到了 81.3% 的 DeiT-S,可與原版 Swin-Tiny 抗衡)。
- 對(duì)兩種有挑戰(zhàn)性的常見實(shí)際情形開發(fā)了專門的實(shí)際效率優(yōu)化技術(shù):1)CPU / 硬盤不夠強(qiáng)力,數(shù)據(jù)預(yù)處理效率跟不上 GPU;2)大規(guī)模并行訓(xùn)練,例如在 ImageNet-22K 上使用 64 或以上的 GPUs 訓(xùn)練大型模型。
接下來(lái),我們一起來(lái)看看該研究的細(xì)節(jié)。
一.研究動(dòng)機(jī)
近年來(lái),大型基礎(chǔ)模型(foundation models)的蓬勃發(fā)展極大促進(jìn)了人工智能和深度學(xué)習(xí)的進(jìn)步。在計(jì)算機(jī)視覺領(lǐng)域,Vision Transformer(ViT)、CLIP、SAM、DINOv2 等代表性工作已經(jīng)證明,同步增大(scaling up)神經(jīng)網(wǎng)絡(luò)尺寸和訓(xùn)練數(shù)據(jù)規(guī)模能夠顯著拓展識(shí)別、檢測(cè)、分割等大量重要視覺任務(wù)的性能邊界。
然而,大型基礎(chǔ)模型往往具有高昂的訓(xùn)練開銷,圖 1 給出了兩個(gè)典型例子。以使用 8 塊 NVIDIA V100 或性能更強(qiáng)的 GPU 為例,GPT-3、ViT-G 僅完成一次訓(xùn)練即需要等效為數(shù)年甚至數(shù)十年的時(shí)間。如此高昂的訓(xùn)練成本,無(wú)論是對(duì)學(xué)術(shù)界還是工業(yè)界而言,都是較難負(fù)擔(dān)的巨大開銷,往往只有少數(shù)頂尖機(jī)構(gòu)消耗大量資源才能推進(jìn)深度學(xué)習(xí)的進(jìn)展。因此,一個(gè)亟待解決的問(wèn)題是:如何有效提升大型深度學(xué)習(xí)模型的訓(xùn)練效率?
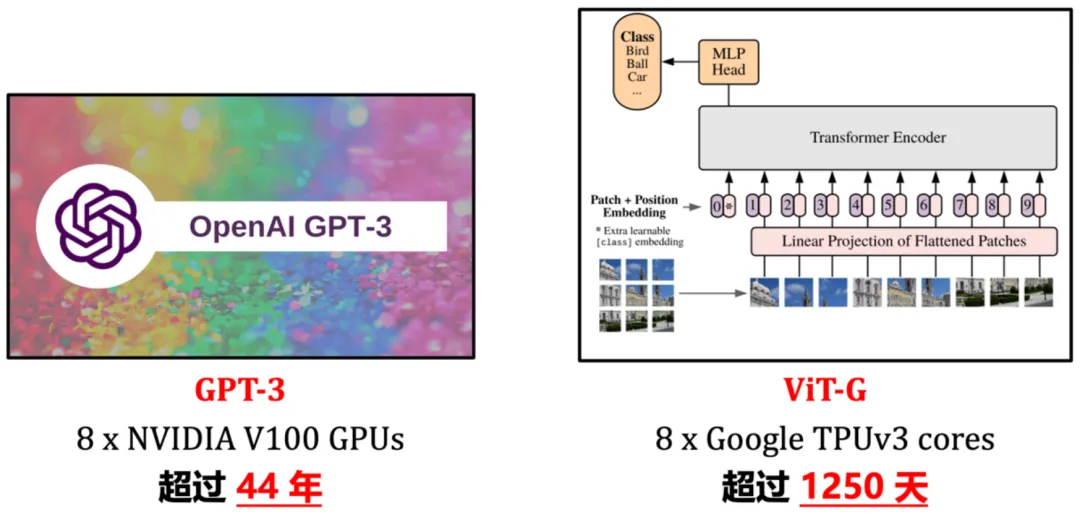
圖 1 示例:大型深度學(xué)習(xí)基礎(chǔ)模型的高昂訓(xùn)練開銷
對(duì)于計(jì)算機(jī)視覺模型而言,一個(gè)經(jīng)典的思路是課程學(xué)習(xí)(curriculum learning),如圖 2 所示,即模仿人類漸進(jìn)式、高度結(jié)構(gòu)化的學(xué)習(xí)過(guò)程,在模型訓(xùn)練過(guò)程中,從最「簡(jiǎn)單」的訓(xùn)練數(shù)據(jù)開始,逐步引入由易到難的數(shù)據(jù)。
 圖 2 經(jīng)典課程學(xué)習(xí)范式(圖片來(lái)源:《A Survey on Curriculum Learning》,TPAMI’22)
圖 2 經(jīng)典課程學(xué)習(xí)范式(圖片來(lái)源:《A Survey on Curriculum Learning》,TPAMI’22)
然而,盡管動(dòng)機(jī)比較自然,課程學(xué)習(xí)并沒(méi)有被大規(guī)模應(yīng)用為訓(xùn)練視覺基礎(chǔ)模型的通用方法,其主要原因在于存在兩個(gè)關(guān)鍵的瓶頸,如圖 3 所示。其一,設(shè)計(jì)有效的訓(xùn)練課程(curriculum)并非易事。區(qū)別「簡(jiǎn)單」、「困難」樣本往往需要借助于額外的預(yù)訓(xùn)練模型、設(shè)計(jì)較復(fù)雜的 AutoML 算法、引入強(qiáng)化學(xué)習(xí)等,且通用性較差。其二,課程學(xué)習(xí)本身的建模存在一定不合理性。自然分布中的視覺數(shù)據(jù)往往具有高度的多樣性,圖 3 下方給出了一個(gè)例子(從 ImageNet 中隨機(jī)抽取的鸚鵡圖片),模型訓(xùn)練數(shù)據(jù)中包含大量不同動(dòng)作的鸚鵡、離鏡頭不同距離的鸚鵡、不同視角、不同背景的鸚鵡、以及鸚鵡與人或物的多樣化的交互等,將如此多樣化的數(shù)據(jù)數(shù)據(jù)僅僅以「簡(jiǎn)單」、「困難」的單一維度指標(biāo)進(jìn)行區(qū)分,事實(shí)上是一個(gè)比較粗糙和牽強(qiáng)的建模方式。
 圖 3 阻礙課程學(xué)習(xí)大規(guī)模應(yīng)用于訓(xùn)練視覺基礎(chǔ)模型的兩個(gè)關(guān)鍵瓶頸
圖 3 阻礙課程學(xué)習(xí)大規(guī)模應(yīng)用于訓(xùn)練視覺基礎(chǔ)模型的兩個(gè)關(guān)鍵瓶頸
二.方法簡(jiǎn)介
受到上述挑戰(zhàn)的啟發(fā),本文提出了一種廣義課程學(xué)習(xí)(generalized curriculum learning)范式,其核心思想在于,將「篩選和使用由易到難的數(shù)據(jù)、逐步訓(xùn)練模型」的傳統(tǒng)課程學(xué)習(xí)范式推廣至「不進(jìn)行數(shù)據(jù)維度的篩選,一直使用全部訓(xùn)練數(shù)據(jù),但在訓(xùn)練過(guò)程中逐步揭示每個(gè)數(shù)據(jù)樣本的由易到難的特征或模式」,這樣就有效避開了因數(shù)據(jù)篩選范式引發(fā)的局限和次優(yōu)設(shè)計(jì),如圖 4 所示。

圖 4 傳統(tǒng)課程學(xué)習(xí)(樣本維度) v.s. 廣義課程學(xué)習(xí)(特征維度)
這一范式的提出主要基于一個(gè)有趣的現(xiàn)象:在一個(gè)自然的視覺模型訓(xùn)練過(guò)程中,雖然模型總是可以隨時(shí)獲取數(shù)據(jù)中包含的全部信息,但模型總會(huì)自然地先學(xué)習(xí)識(shí)別數(shù)據(jù)中包含的某些比較簡(jiǎn)單的判別特征(pattern),而后在此基礎(chǔ)上再逐步學(xué)習(xí)識(shí)別更難的判別特征。并且,這一規(guī)律是比較普遍的,「比較簡(jiǎn)單」的判別特征在頻域和空域都可以較方便地找到。本文設(shè)計(jì)了一系列有趣的實(shí)驗(yàn)來(lái)證明上述發(fā)現(xiàn),如下所述。
從頻域的角度來(lái)說(shuō),「低頻特征」對(duì)于模型而言「比較簡(jiǎn)單」。在圖 5 中,本文作者使用標(biāo)準(zhǔn) ImageNet-1K 訓(xùn)練數(shù)據(jù)訓(xùn)練了一個(gè) DeiT-S 模型,并使用帶寬不同的低通濾波器對(duì)驗(yàn)證集進(jìn)行濾波,只保留驗(yàn)證圖像的低頻分量,在此基礎(chǔ)上報(bào)告 DeiT-S 在訓(xùn)練過(guò)程中、在低通濾波的驗(yàn)證數(shù)據(jù)上的準(zhǔn)確率,所得準(zhǔn)確率相對(duì)訓(xùn)練過(guò)程的曲線顯示于圖 5 右側(cè)。
我們可以看到一個(gè)有趣的現(xiàn)象:在訓(xùn)練早期階段,僅使用低通濾波的驗(yàn)證數(shù)據(jù)不會(huì)顯著降低準(zhǔn)確性,且曲線與正常驗(yàn)證集準(zhǔn)確率間的分離點(diǎn)隨濾波器帶寬的增大而逐漸右移。這一現(xiàn)象表明,盡管模型始終可以訪問(wèn)訓(xùn)練數(shù)據(jù)的低頻和高頻部分,但其學(xué)習(xí)過(guò)程自然地從僅關(guān)注低頻信息開始,識(shí)別較高頻特征的能力則在訓(xùn)練后期逐步習(xí)得(這一現(xiàn)象的更多證據(jù)可參考原文)。
 圖 5 頻域角度上,模型自然傾向于先學(xué)習(xí)識(shí)別低頻特征
圖 5 頻域角度上,模型自然傾向于先學(xué)習(xí)識(shí)別低頻特征
這一發(fā)現(xiàn)引出了一個(gè)有趣的問(wèn)題:我們是否可以設(shè)計(jì)一個(gè)訓(xùn)練課程(curriculum),從只為模型提供視覺輸入的低頻信息開始,而后逐漸引入高頻信息?
圖 6 研究了這個(gè)想法,即僅在特定長(zhǎng)度的早期訓(xùn)練階段對(duì)訓(xùn)練數(shù)據(jù)執(zhí)行低通濾波,訓(xùn)練過(guò)程的其余部分保持不變。從結(jié)果中可以觀察到,盡管最終性能提升有限,但有趣的是,即使在相當(dāng)長(zhǎng)的一段早期訓(xùn)練階段中僅向模型提供低頻分量,模型的最終精度也可以在很大程度上得到保留,這也與圖 5 中「模型在訓(xùn)練初期主要關(guān)注學(xué)習(xí)識(shí)別低頻特征」的觀察不謀而合。
這一發(fā)現(xiàn)啟發(fā)了本文作者關(guān)于訓(xùn)練效率的思考:既然模型在訓(xùn)練初期只需要數(shù)據(jù)中的低頻分量,且低頻分量包含的信息小于原始數(shù)據(jù),那么能否使模型以比處理原始輸入更少的計(jì)算成本高效地僅從低頻分量中學(xué)習(xí)?

圖 6 在相當(dāng)長(zhǎng)的一段早期訓(xùn)練階段中僅向模型提供低頻分量并不會(huì)顯著影響最終性能
事實(shí)上,這一思路是完全可行的。如圖 7 左側(cè)所示,本文作者在圖像的傅里葉頻譜中引入了裁切操作,裁切出低頻部分,并將其映射回像素空間。這一低頻裁切操作準(zhǔn)確地保留了所有低頻信息,同時(shí)減小了圖像輸入的尺寸,因此模型從輸入中學(xué)習(xí)的計(jì)算成本可以呈指數(shù)級(jí)降低。
如果使用這一低頻裁切操作在訓(xùn)練早期階段處理模型輸入,可以顯著節(jié)省總體訓(xùn)練成本,但由于最大限度地保留了模型學(xué)習(xí)所必要的信息,仍然可以獲得性能幾乎不受損失的最終模型,實(shí)驗(yàn)結(jié)果如圖 7 右下方所示。

圖 7 低頻裁切(low-frequency cropping):使模型高效地僅從低頻信息中學(xué)習(xí)
在頻域操作之外,從空域變換的角度,同樣可以找到對(duì)于模型而言「比較簡(jiǎn)單」的特征。例如,沒(méi)有經(jīng)過(guò)較強(qiáng)數(shù)據(jù)增強(qiáng)或者扭曲處理的原始視覺輸入中所包含的自然圖像信息往往對(duì)于模型而言「比較簡(jiǎn)單」、更容易讓模型學(xué)習(xí),因?yàn)樗鼈兪菑默F(xiàn)實(shí)世界的分布中得出的,而數(shù)據(jù)增強(qiáng)等預(yù)處理技術(shù)所引入的額外信息、不變性等往往對(duì)于模型而言較難學(xué)習(xí)(圖 8 左側(cè)給出了一個(gè)典型示例)。
事實(shí)上,現(xiàn)有研究也已觀察到,數(shù)據(jù)增強(qiáng)主要在訓(xùn)練較晚期階段發(fā)揮作用(如《Improving Auto-Augment via Augmentation-Wise Weight Sharing》, NeurIPS’20)。
在這一維度上,為實(shí)現(xiàn)廣義課程學(xué)習(xí)的范式,可以簡(jiǎn)單地通過(guò)改變數(shù)據(jù)增強(qiáng)的強(qiáng)度方便地實(shí)現(xiàn)在訓(xùn)練早期階段僅向模型提供訓(xùn)練數(shù)據(jù)中較容易學(xué)習(xí)的自然圖像信息。圖 8 右側(cè)使用 RandAugment 作為代表性示例來(lái)驗(yàn)證了這個(gè)思路,RandAugment 包含了一系列常見的空域數(shù)據(jù)增強(qiáng)變換(例如隨機(jī)旋轉(zhuǎn)、更改銳度、仿射變換、更改曝光度等)。
可以觀察到,從較弱的數(shù)據(jù)增強(qiáng)開始訓(xùn)練模型可以有效提高模型最終表現(xiàn),同時(shí)這一技術(shù)與低頻裁切兼容。

圖 8 從空域的角度尋找模型 “較容易學(xué)習(xí)” 的特征:一個(gè)數(shù)據(jù)增強(qiáng)的視角
到此處為止,本文提出了廣義課程學(xué)習(xí)的核心框架與假設(shè),并通過(guò)揭示頻域、空域的兩個(gè)關(guān)鍵現(xiàn)象證明了廣義課程學(xué)習(xí)的合理性和有效性。在此基礎(chǔ)上,本文進(jìn)一步完成了一系列系統(tǒng)性工作,在下面列出。由于篇幅所限,關(guān)于更多研究細(xì)節(jié),可參考原論文。
- 融合頻域、空域的兩個(gè)核心發(fā)現(xiàn),提出和改進(jìn)了專門設(shè)計(jì)的優(yōu)化算法,建立了一個(gè)統(tǒng)一、整合的 EfficientTrain++ 廣義課程學(xué)習(xí)方案。
- 探討了低頻裁切操作在實(shí)際硬件上高效實(shí)現(xiàn)的具體方法,并從理論和實(shí)驗(yàn)兩個(gè)角度比較了兩種提取低頻信息的可行方法:低頻裁切和圖像降采樣,的區(qū)別和聯(lián)系。
- 對(duì)兩種有挑戰(zhàn)性的常見實(shí)際情形開發(fā)了專門的實(shí)際效率優(yōu)化技術(shù):1)CPU / 硬盤不夠強(qiáng)力,數(shù)據(jù)預(yù)處理效率跟不上 GPU;2)大規(guī)模并行訓(xùn)練,例如在 ImageNet-22K 上使用 64 或以上的 GPUs 訓(xùn)練大型模型。
本文最終得到的 EfficientTrain++ 廣義課程學(xué)習(xí)方案如圖 9 所示。EfficientTrain++ 以模型訓(xùn)練總計(jì)算開銷的消耗百分比為依據(jù),動(dòng)態(tài)調(diào)整頻域低頻裁切的帶寬和空域數(shù)據(jù)增強(qiáng)的強(qiáng)度。
值得注意的是,作為一種即插即用的方法,EfficientTrain++ 無(wú)需進(jìn)一步的超參數(shù)調(diào)整或搜索即可直接應(yīng)用于多種視覺基礎(chǔ)網(wǎng)絡(luò)和多樣化的模型訓(xùn)練場(chǎng)景,效果比較穩(wěn)定、顯著。
 圖 9 統(tǒng)一、整合的廣義課程學(xué)習(xí)方案:EfficientTrain++
圖 9 統(tǒng)一、整合的廣義課程學(xué)習(xí)方案:EfficientTrain++
三.實(shí)驗(yàn)結(jié)果
作為一種即插即用的方法,EfficientTrain++ 在 ImageNet-1K 上,在基本不損失或提升性能的條件下,將多種視覺基礎(chǔ)網(wǎng)絡(luò)的實(shí)際訓(xùn)練開銷降低了 1.5 倍左右。

圖 10 ImageNet-1K 實(shí)驗(yàn)結(jié)果:EfficientTrain++ 在多種視覺基礎(chǔ)網(wǎng)絡(luò)上的表現(xiàn)
EfficientTrain++ 的增益通用于不同的訓(xùn)練開銷預(yù)算,嚴(yán)格相同表現(xiàn)的情況下,DeiT/Swin 在 ImageNet-1K 上的訓(xùn)加速比在 2-3 倍左右。
 圖 11 ImageNet-1K 實(shí)驗(yàn)結(jié)果:EfficientTrain++ 在不同訓(xùn)練開銷預(yù)算下的表現(xiàn)
圖 11 ImageNet-1K 實(shí)驗(yàn)結(jié)果:EfficientTrain++ 在不同訓(xùn)練開銷預(yù)算下的表現(xiàn)
EfficientTrain++ 在 ImageNet-22k 上可以取得 2-3 倍的性能無(wú)損預(yù)訓(xùn)練加速。
 圖 12 ImageNet-22K 實(shí)驗(yàn)結(jié)果:EfficientTrain++ 在更大規(guī)模訓(xùn)練數(shù)據(jù)上的表現(xiàn)
圖 12 ImageNet-22K 實(shí)驗(yàn)結(jié)果:EfficientTrain++ 在更大規(guī)模訓(xùn)練數(shù)據(jù)上的表現(xiàn)
對(duì)于較小的模型,EfficientTrain++ 可以實(shí)現(xiàn)顯著的性能上界提升。
 圖 13 ImageNet-1K 實(shí)驗(yàn)結(jié)果:EfficientTrain++ 可以顯著提升較小模型的性能上界
圖 13 ImageNet-1K 實(shí)驗(yàn)結(jié)果:EfficientTrain++ 可以顯著提升較小模型的性能上界
EfficientTrain++ 對(duì)于自監(jiān)督學(xué)習(xí)算法(如 MAE)同樣有效。
 圖 14 EfficientTrain++ 可以應(yīng)用于自監(jiān)督學(xué)習(xí)(如 MAE)
圖 14 EfficientTrain++ 可以應(yīng)用于自監(jiān)督學(xué)習(xí)(如 MAE)
EfficientTrain++ 訓(xùn)得的模型在目標(biāo)檢測(cè)、實(shí)例分割、語(yǔ)義分割等下游任務(wù)上同樣不損失性能。
 圖 15 COCO 目標(biāo)檢測(cè)、COCO 實(shí)例分割、ADE20K 語(yǔ)義分割實(shí)驗(yàn)結(jié)果
圖 15 COCO 目標(biāo)檢測(cè)、COCO 實(shí)例分割、ADE20K 語(yǔ)義分割實(shí)驗(yàn)結(jié)果