













LLM會寫代碼≠推理+規(guī)劃!AAAI主席揭秘:代碼數(shù)據(jù)質(zhì)量太高|LeCun力贊
自從ChatGPT發(fā)布后,各種基于大模型的產(chǎn)品也快速融入了普通人的生活中,但即便非AI從業(yè)者在使用過幾次后也可以發(fā)現(xiàn),大模型經(jīng)常會胡編亂造,生成錯誤的事實。
不過對于程序員來說,把GPT-4等大模型當作「代碼輔助生成工具」來用的效果明顯要比「事實檢索工具」要好用很多,因為代碼生成往往會涉及到復(fù)雜的邏輯分析等,所以也有人將這種推理(廣義規(guī)劃)能力歸因于大型語言模型(LLM)的涌現(xiàn)。
學術(shù)界也一直在就「LLM能否推理」這個問題爭論不休。

最近,計算機科學家、亞利桑那州立大學教授Subbarao Kambhampati(Rao)以「LLM真的能推理和規(guī)劃嗎?」(Can LLMs Really Reason & Plan?)為題,全面總結(jié)了語言模型在推理和規(guī)劃方面的研究成果,其中也談到了LLM的代碼生成與推理能力的關(guān)聯(lián)。

視頻鏈接:https://www.youtube.com/watch?v=uTXXYi75QCU
PPT鏈接:https://www.dropbox.com/scl/fi/g3qm2zevcfkp73wik2bz2/SCAI-AI-Day-talk-Final-as-given.pdf
一句話總結(jié):LLM的代碼生成質(zhì)量比英語(自然語言)生成質(zhì)量更高,只能說明「在GitHub上進行近似檢索」要比「通用Web上檢索」更容易,而不能反映出任何潛在的推理能力。
造成這種差異的原因主要有兩個:
1. 用于LLM訓練的代碼數(shù)據(jù)質(zhì)量要比文本質(zhì)量更高
2. 形式語言中「語法和語義的距離」比高度靈活的自然語言要低

圖靈獎得主Yann LeCun也表示贊同:自回歸LLM對編碼非常有幫助,即便LLM真的不具備規(guī)劃能力。
Rao教授是AAAI的主席,IJCAI的理事,以及Partnership on AI的創(chuàng)始董事會成員;他的主要研究方向為:

1. 面向人類的AI系統(tǒng)(Human-Aware AI Systems):可解釋的人工智能交互。人工智能系統(tǒng)的規(guī)劃和決策。人機組隊。主動決策支持。可學習的規(guī)劃模型和Model Lite規(guī)劃。可解釋的行為和解釋。人為因素評估。
2. 自動規(guī)劃(Automated Planning,AI):度量、時間、部分可訪問和隨機世界中的規(guī)劃合成、啟發(fā)式方法。規(guī)劃的多目標優(yōu)化。用富有表現(xiàn)力的動作推理。行程安排。加快學習以幫助規(guī)劃者。約束滿足與運籌學技術(shù)。規(guī)劃在自動化制造和空間自主方面的應(yīng)用。
3. 社交媒體分析與信息整合(Social Media Analysis & Information Integration):社交媒體平臺上的人類行為分析。信息集成中用于查詢優(yōu)化和執(zhí)行的自適應(yīng)技術(shù)。源發(fā)現(xiàn)和源元數(shù)據(jù)學習。
代碼生成≠推理+規(guī)劃
已故的計算機科學家Drew McDermott曾經(jīng)說過,規(guī)劃只是一種語言的自動編程,每個原語都對應(yīng)于可執(zhí)行的操作(planning is just automatic programming on a language with primitives corresponding to executable actions)。
也就是說,廣義上的規(guī)劃可以寫成程序,如果GPT-4或其他大模型可以正確地生成代碼,那也就證明了LLM具有規(guī)劃能力。
比如說去年5月,英偉達、加州理工等研究團隊合作開發(fā)出了Voyager(旅行者)智能體,也是Minecraft(《我的世界》游戲)中首個基于LLM的具身、終身學習智能體(embodied lifelong learning agent),可以不斷探索世界,獲得各種技能,并在沒有人為干預(yù)的情況下進行新的發(fā)現(xiàn)。

論文鏈接:https://arxiv.org/abs/2305.16291
Voyager的核心思想就是讓LLM輸出代碼來執(zhí)行任務(wù),并且在模擬器中運行,包含三個關(guān)鍵組件:最大化探索(exploration)的自動課程(curriculum );用于存儲和檢索復(fù)雜行為的可執(zhí)行代碼的不斷增長的技能庫;新的迭代提示機制,包含環(huán)境反饋、執(zhí)行錯誤和自我驗證以改進程序。
Voyager通過黑盒查詢與GPT-4進行交互,從而無需對模型參數(shù)進行微調(diào)。
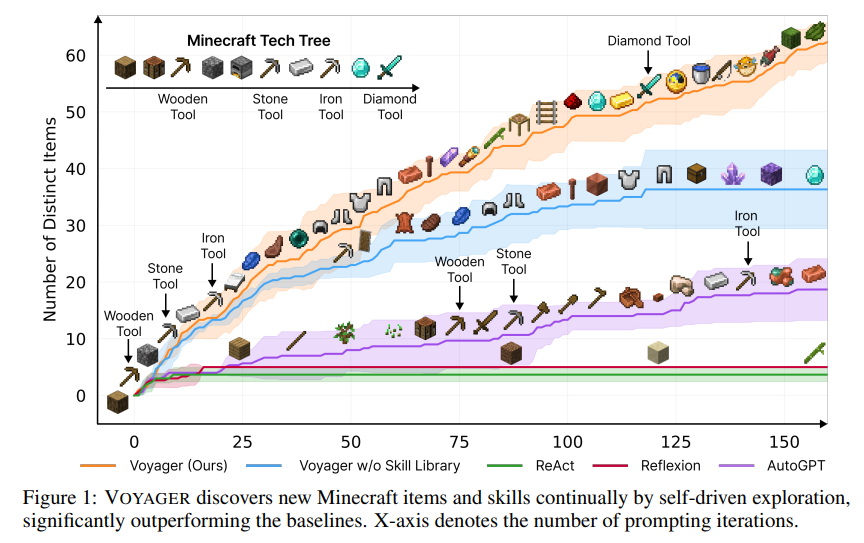
雖然還有其他類似Voyager的工作可以利用LLM以代碼生成的方式完成規(guī)劃,但這也并不能證明LLM就具有規(guī)劃能力。
從原理上說,LLM本質(zhì)上是一個近似檢索器(approximate retrieval),能否成功規(guī)劃取決于訓練數(shù)據(jù)的質(zhì)量。
在自然語言生成上,LLM需要吞噬海量數(shù)據(jù),其中很多數(shù)據(jù)在事實基礎(chǔ)或是價值體系上都存在很大分歧,比如地平論者和疫苗反對者也有自己的一套理論,可以寫出令人信服的文章。
而在代碼生成上,訓練數(shù)據(jù)主要來自GitHub上的開源代碼,其中大部分都是「有效數(shù)據(jù)」,而且軟件工程師的價值體系對代碼的質(zhì)量影響微乎其微,這也可以解釋為什么代碼生成的質(zhì)量要比文本補全的質(zhì)量更高。
盡管如此,但代碼生成的本質(zhì)上仍然是近似檢索,其正確性無法保證,所以在使用GitHub Copilot等輔助工具時,經(jīng)常可以看到有人抱怨花了太長時間在生成代碼的調(diào)試上,生成的代碼往往看似運行良好,但背地里蘊藏bug
代碼看起來能正常運行的部分原因可以歸結(jié)為兩個原因:
1. 系統(tǒng)中存在一個輔助工具(增量解釋器),可以標記處明顯的執(zhí)行異常,可以讓人類程序員在調(diào)試過程中注意到;
2. 語法上正確的代碼段在語義上也可能是正確的,雖然無法完全保證,但語法正確是可執(zhí)行的先決條件(對于自然語言來說也是如此)。
語言模型的自我驗證
在少數(shù)情況下,例如上面提到的Voyager模型,其開發(fā)者聲稱:生成的代碼質(zhì)量已經(jīng)足夠好,可以直接在世界上運行,但仔細閱讀就會發(fā)現(xiàn),這種效果主要依賴于世界對規(guī)劃模糊性的寬容。
某些論文中也會采用「LLM自我驗證」(self-verify,self-critique自我批評)的方式,即在運行代碼之前在目標場景中嘗試執(zhí)行驗證一次,但同樣,沒有理由相信LLM具有自我驗證的能力。
下面兩篇論文就對模型的驗證能力產(chǎn)生質(zhì)疑。

論文鏈接:https://arxiv.org/abs/2310.12397
這篇論文系統(tǒng)地研究LLMs的迭代提示的有效性在圖著色(Graph Coloring)的背景下(一個典型的NP完全推理問題),涉及到命題可滿足性以及實際問題,如調(diào)度和分配;文中提出了一個原則性的實證研究GPT4在解決圖著色實例或驗證候選著色的正確性的性能。
在迭代模式中,研究人員要求模型來驗證自己的答案,并用外部正確的推理機來驗證所提出的解決方案。
結(jié)果發(fā)現(xiàn):
1. LLMs在解決圖著色實例方面很差;
2. 在驗證解決方案方面并沒有更好的表現(xiàn)-因此在迭代模式下,LLMs批評LLM生成的解決方案無效;
3. 批評的正確性和內(nèi)容(LLMs本身和外部求解器)似乎在很大程度上與迭代提示的性能無關(guān)。
第二篇論文研究了大模型能否通過自我批評來改進規(guī)劃。

論文鏈接:https://arxiv.org/abs/2310.08118
這篇論文的研究結(jié)果表明,自我批評似乎會降低規(guī)劃生成性能,在使用GPT-4的情況下,無論是外部驗證器還是自我驗證器都在該系統(tǒng)中產(chǎn)生了非常多的誤報,損害了系統(tǒng)的可靠性。
并且反饋信號為二元(正確、錯誤)和詳細信息對規(guī)劃生成的影響都很小,即LLM在自我批評、迭代規(guī)劃任務(wù)框架下的有效性值得懷疑。






















