消滅「幻覺」!谷歌全新ASPIRE方法讓LLM給自己打分,效果碾壓10x體量模型
大模型的「幻覺」問題馬上要有解了?
威斯康星麥迪遜大學和谷歌的研究人員最近開發了一個名為ASPIRE的系統,可以讓大模型對自己的輸出給出評分。
如果用戶看到模型的生成的結果評分不高,就能意識到這個回復可能是幻覺。
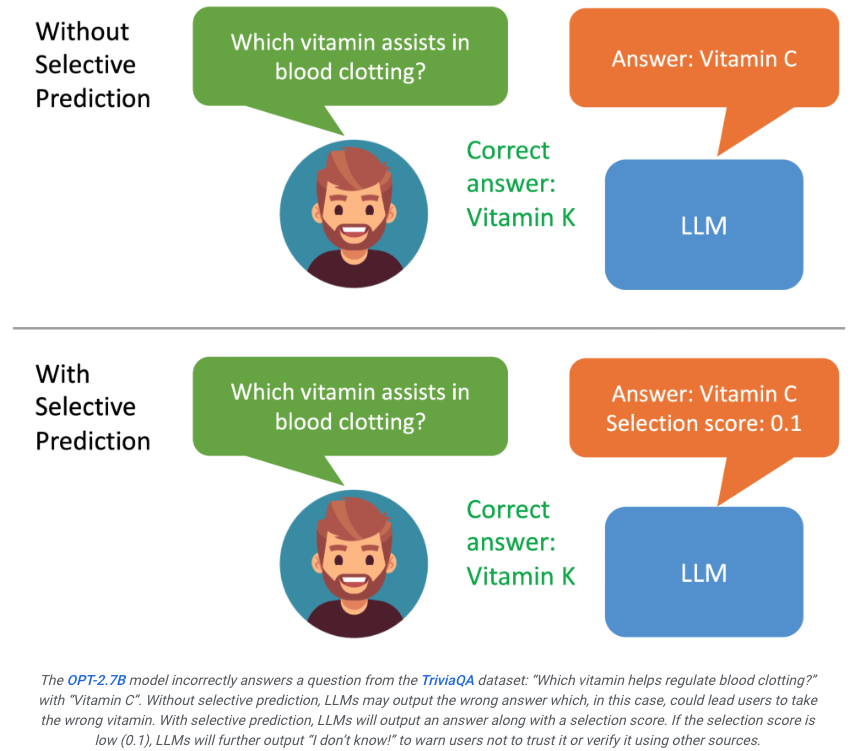
如果系統可以進一步篩選評分的結果進行輸出,比如如果評分過低,大模型就可能生成「我沒法回答這個問」,從而有望最大限度的改善幻覺問題。

論文地址:https://aclanthology.org/2023.findings-emnlp.345.pdf
ASPIRE能讓LLM輸出答案以及答案的置信度得分。
研究人員的實驗結果表明,ASPIRE在各種QA數據集(例如 CoQA 基準)上顯著優于傳統的選擇性預測方法。
讓LLM不僅要回答問題,還要評估這些答案 。
在選擇性預測的基準測試上,研究人員通過ASPIRE系統取得了超過10倍規模的模型的成績。
就像讓學生在課本后面驗證他們自己的答案,雖然聽起來有點不靠譜,但是細細一想,每個人在做出一道題目之后,確實會對答案的滿意程度會有一個評分。
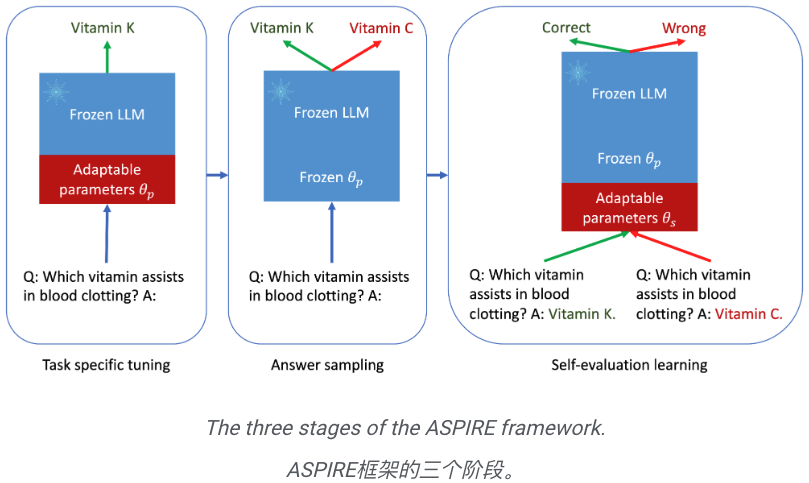
這就是ASPIRE的本質,它涉及三個階段:
(1) 針對特定任務的調優,
(2) 答案采樣,
(3) 自我評估學習。
在研究人員看來,ASPIRE不僅僅是另一個框架,它代表著一個全面提升LLM可靠性,降低幻覺的美好未來。
如果LLM可以成為決策過程中值得信賴的合作伙伴。
只要通過不斷優化選擇性預測的能力,人類距離充分發揮大模型的潛力就又近了一步。
研究人員希望能憑借ASPIRE,開啟下一代LLM的進化,從而能創建更可靠和更具有自我意識的人工智能。
ASPIRE 的機制
針對特定任務的微調
ASPIRE執行特定于任務的微調以訓練適應性參數 ,同時凍結LLM。
,同時凍結LLM。
給定生成任務的訓練數據集,它會微調預訓練的LLM以提高其預測性能。
為此,可以采用參數高效的微調技術(例如,軟提示詞微調和LoRA)來微調任務上的預訓練LLM,因為它們可以有效地通過少量目標獲得強泛化任務數據。
具體來說,LLM參數(θ)被凍結,并添加自適應參數 進行微調。
進行微調。
僅更新 θ (p) 以最小化標準 LLM 訓練損失(例如交叉熵)。
這種微調可以提高選擇性預測性能,因為它不僅提高了預測精度,而且還提高了正確輸出序列的可能性。
答案采樣
在針對特定任務進行調優后,ASPIRE使用LLM和學習到的 為每個訓練問題生成不同的答案,并創建用于自評估學習的數據集。
為每個訓練問題生成不同的答案,并創建用于自評估學習的數據集。
研究人員的目標是生成具有高可能性的輸出序列。他們使用波束搜索(Beam Search)作為解碼算法來生成高似然輸出序列,并使用Rouge-L度量來確定生成的輸出序列是否正確。
自評估學習
在對每個查詢的高似然輸出進行采樣后,ASPIRE添加自適應參數 ,并且僅微調
,并且僅微調 來學習自評估。
來學習自評估。
由于輸出序列的生成僅取決于 θ 和 ,因此凍結 θ 和學習到的
,因此凍結 θ 和學習到的 可以避免在學習自評估時改變LLM的預測行為-評估。
可以避免在學習自評估時改變LLM的預測行為-評估。
研究人員優化了 ,使得改編后的LLM可以自己區分正確和錯誤的答案。
,使得改編后的LLM可以自己區分正確和錯誤的答案。
在這個框架中,可以使用任何參數有效的微調方法來訓練 和
和 。
。
在這項工作中,研究人員使用軟提示微調,這是一種簡單而有效的機制,用于學習「軟提示」來調節凍結的語言模型,從而比傳統的離散文本提示更有效地執行特定的下游任務。
這種方法背后的核心在于認識到,如果能夠開發出有效激發自我評價的提示,那么應該可以通過結合有針對性的訓練目標的軟提示微調來發現這些提示。
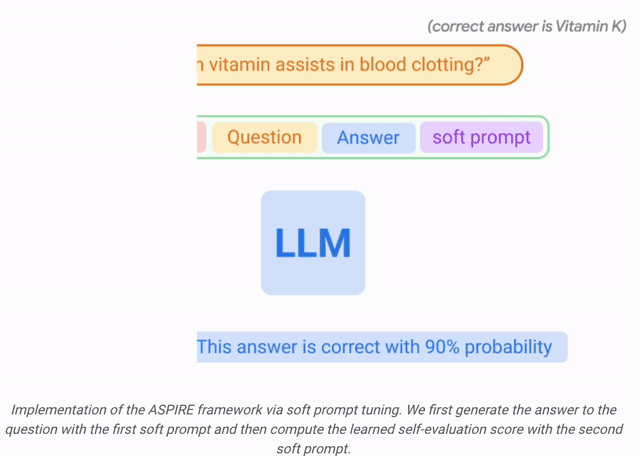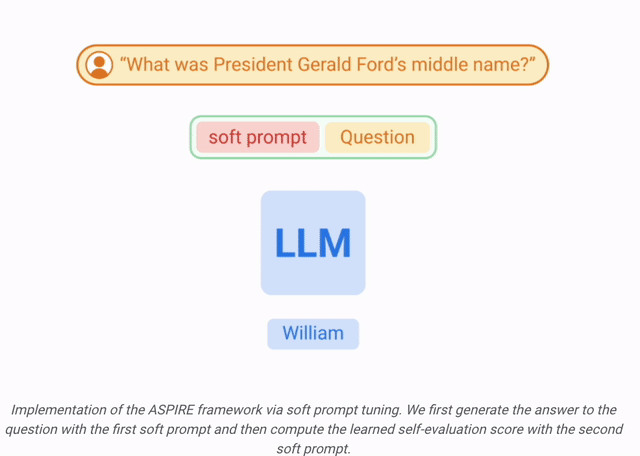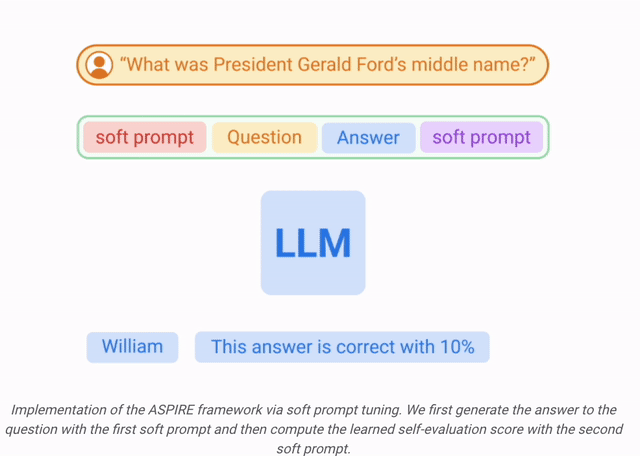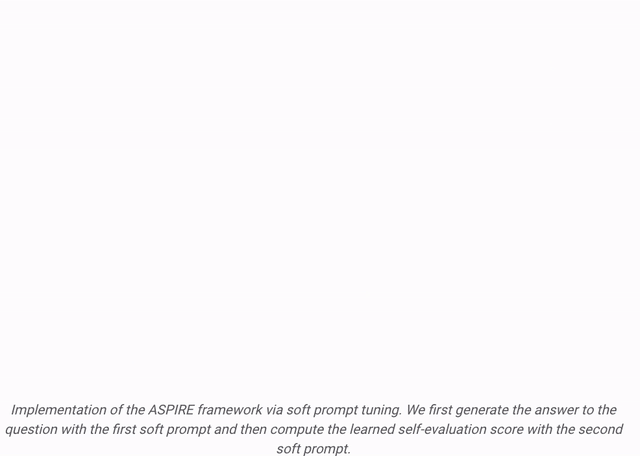
在訓練 和
和 后,研究人員通過波束搜索解碼獲得查詢的預測(beam search decoding)。
后,研究人員通過波束搜索解碼獲得查詢的預測(beam search decoding)。
然后,研究人員定義一個選擇分數,將生成答案的可能性與學習到的自我評估分數(即,預測對于查詢正確的可能性)結合起來,以做出選擇性預測。
結果
為了證明ASPIRE的效果,研究人員使用各種開放式預訓練Transformer (OPT)模型在三個問答數據集(CoQA、TriviaQA和SQuAD)上對其進行評估。
通過使用軟提示調整訓練 研究人員觀察到LLM的準確性大幅提高。
研究人員觀察到LLM的準確性大幅提高。
例如,與使用CoQA和SQuAD數據集的較大預訓練OPT-30B模型相比,采用ASPIRE的OPT-2.7B模型表現出更好的性能。
這些結果表明,通過適當的調整,較小的LLM在某些情況下可能有能力匹配或可能超過較大模型的準確性。

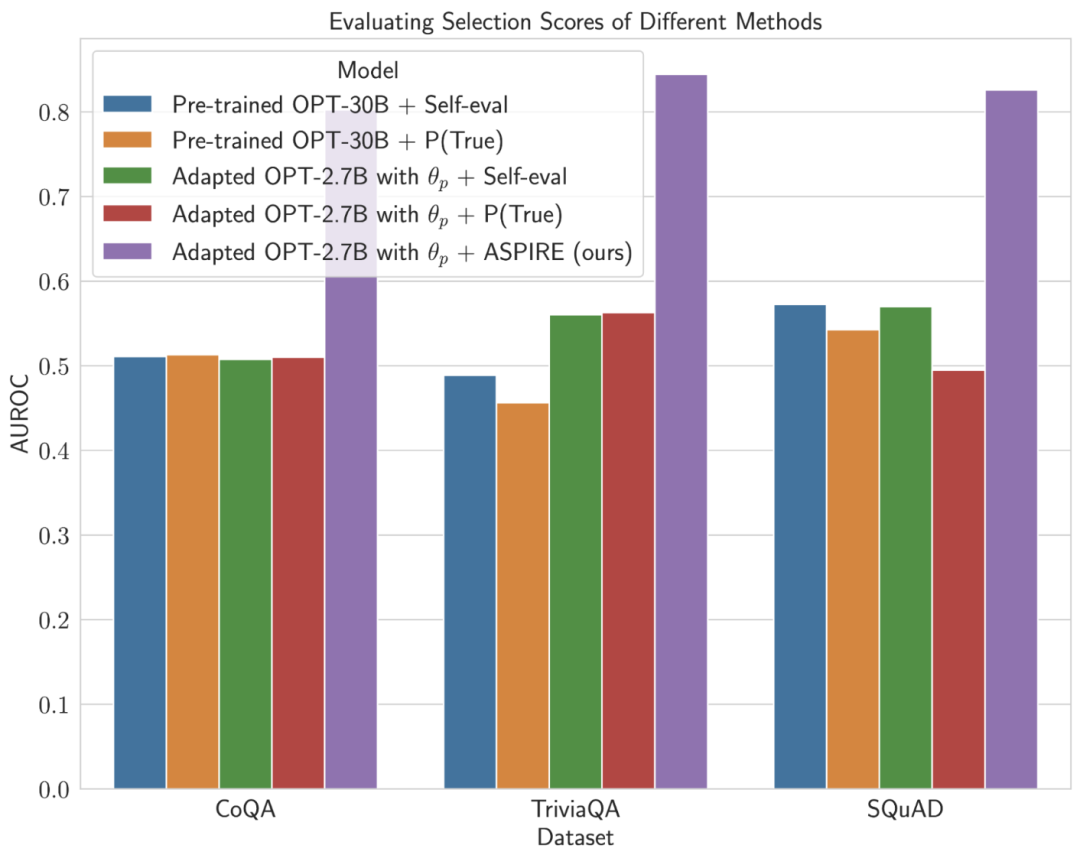
當深入研究固定模型預測的選擇分數計算時,ASPIRE獲得了比所有數據集的基線方法更高的AUROC分數(隨機選擇的正確輸出序列比隨機選擇的不正確輸出序列具有更高選擇分數的概率)。
例如,在CoQA基準上,與基線相比,ASPIRE將AUROC從51.3%提高到80.3%。
TriviaQA數據集評估中出現了一個有趣的模式。
雖然預訓練的OPT-30B模型表現出更高的基線精度,但當應用傳統的自我評估方法(Self-eval和P(True))時,其選擇性預測的性能并沒有顯著提高。
相比之下,小得多的OPT-2.7B模型在使用ASPIRE進行增強后,在這方面表現優于其他模型。
這種差異體現了一個重要的問題:利用傳統自我評估技術的較大LLM在選擇性預測方面可能不如較小的ASPIRE增強模型有效。

研究人員與ASPIRE的實驗之旅強調了LLM格局的關鍵轉變:語言模型的容量并不是其性能的全部和最終目的。
相反,可以通過策略調整來大幅提高模型的有效性,即使在較小的模型中也可以進行更精確、更自信的預測。
因此,ASPIRE證明了LLM的潛力,它可以明智地確定自己答案的確定性,并在選擇性預測任務中顯著地超越地超越其他10倍體量的模型。