













「think step by step」還不夠,讓模型「think more steps」更有用
如今,大型語言模型(LLM)及其高級提示策略的出現(xiàn),標志著對語言模型的研究取得了重大進展,尤其是在經(jīng)典的 NLP 任務中。這其中一個關鍵的創(chuàng)新是思維鏈(CoT)提示技術,該技術因其在多步驟問題解決中的能力而聞名。這項技術遵循了人類的順序推理,在各種挑戰(zhàn)中表現(xiàn)出了優(yōu)秀的性能,其中包括跨域、長泛化和跨語言的任務。CoT 及其富有邏輯的、循序漸進的推理方法,在復雜的問題解決場景中提供了至關重要的可解釋性。
盡管 CoT 取得了長足的進展,但研究界尚未就 CoT 及其變體的具體機制和有效原因達成共識。這種知識差距意味著提高 CoT 性能仍是一個探索領域。而這種探索主要依賴于試錯,因為目前還缺乏改進 CoT 效果的系統(tǒng)性方法論,研究人員只能依賴猜測和實驗。但是這也同時表明該領域存在著重要的研究機遇:對 CoT 的內(nèi)部運作形成更深入、更結構化的理解。如果實現(xiàn)這個目標,不僅能揭開當前 CoT 過程的神秘面紗,還能為在各種復雜的 NLP 任務中更可靠、更高效地應用這種技術鋪平道路。
來自美國西北大學、利物浦大學和新澤西理工大學等的研究者們,進一步探討了推理步驟的長度與結論準確性之間的關系,幫助人們加深關于如何有效解決 NLP 問題的理解。下面這篇文章探索了推理步驟是否是促使 CoT 發(fā)揮作用的 prompt 中最關鍵的部分(見圖 1)。本文實驗中嚴格的控制變量,特別是在加入新的推理步驟時,研究者會確保不會引入額外的知識。在零樣本實驗中,研究者將初始 prompt 從「請逐步思考」調(diào)整為「請逐步思考,并且盡可能思考出更多的步驟」。對于小樣本問題,研究者設計了一個實驗,在保持所有其他因素不變的情況下,擴展基礎推理步驟。

- 論文標題:The Impact of Reasoning Step Length on Large Language Models
- 論文鏈接:https://arxiv.org/pdf/2401.04925.pdf

本文的第一組實驗評估了在上述策略下,使用 Auto-CoT 技術,在零樣本和小樣本任務中推理性能的提高情況。隨后,本文評估了不同方法在不同推理步數(shù)下的準確性。接著,研究者擴大了調(diào)研對象,比較了本文提出的策略在不同 LLM(如 GPT-3.5 和 GPT-4)上的有效性。研究結果表明,在一定范圍內(nèi),推理鏈的長度與 LLM 的能力之間存在明顯的相關性。但耐人尋味的是,當研究者在推理鏈中引入誤導信息時,性能仍然有所提高。這推導出了一個重要結論:影響性能的關鍵因素似乎是思維鏈的長度,而不是其準確性。
本文的主要發(fā)現(xiàn)如下所示:
- 對于小樣本 CoT,推理步數(shù)和精度之間存在直接的線性關系。這為優(yōu)化復雜推理中的 CoT 提示提供了一種可量化的方法。具體來說,增加 prompt 中的推理步驟大大提高了 LLM 在多個數(shù)據(jù)集上的推理能力。反過來,即使在保留了關鍵信息的情況下,縮短推理步驟也會顯著削弱模型的推理能力。
- 即使是不正確的推理,如果能保持必要的推理長度,也能產(chǎn)生有利的結果。例如,在數(shù)學問題等任務中,過程中產(chǎn)生的中間數(shù)字出錯也不太會影響最終結果。
- 增加推理步驟所產(chǎn)生的收益大小受限于任務本身:更簡單的任務需要更少的步驟,而更復雜的任務則從更長的推理序列中獲得顯著收益。
- 增加零樣本 CoT 中的推理步驟也可以顯著提高 LLM 的準確性。
研究方法
研究者通過分析來檢驗推理步驟與 CoT 提示性能之間的關系。方法的核心假設是,推理過程中的序列化步驟是 CoT 提示中最關鍵的組成部分,能夠使語言模型在生成回復內(nèi)容時應用更多的邏輯進行推理。為了測試這一觀點,本文設計了一個實驗,在 CoT 的推理過程中先后擴展和壓縮基礎推理步驟,同時保持所有其他因素不變。具體而言,研究者只系統(tǒng)地改變推理步驟的數(shù)量,不引入新的推理內(nèi)容或刪除已有的推理內(nèi)容。研究者在下文中評估了零樣本和少樣本的 CoT 提示。整個實驗過程如圖 2 所示。通過這種控制變量分析的方法,研究者闡明了 CoT 如何影響 LLM 生成邏輯健全的應答能力。

零樣本 CoT 分析
在零樣本場景中,研究者將最初的 prompt 從「請逐步思考」修改為「請逐步思考,并且盡可能思考出更多的步驟」。之所以做出這一改變,是因為與少樣本 CoT 環(huán)境不同,使用者不能在使用過程中引入額外的推理步驟。通過改變初始 prompt,研究者引導 LLM 進行了更廣泛的思考。這種方法的重要性在于能夠提高模型的準確性,而且不需要少樣本場景中的典型方案:增量訓練或額外的示例驅(qū)動優(yōu)化方法。這種精細化策略確保了更全面、更詳細的推理過程,顯著提高了模型在零樣本條件下的性能。
小樣本 CoT 分析
本節(jié)將通過增加或壓縮推理步驟來修改 CoT 中的推理鏈。其目的是研究推理結構的變化如何影響 LLM 決策。在推理步驟的擴展過程中,研究者需要避免引入任何新的任務相關信息。這樣,推理步驟就成了唯一的研究變量。
為此,研究者設計了以下研究策略,以擴展不同 LLM 應用程序的推理步驟。人們思考問題的方式通常有固定的模式,例如,一遍又一遍地重復問題以獲得更深入的理解、創(chuàng)建數(shù)學方程以減輕記憶負擔、分析問題中單詞的含義以幫助理解主題、總結當前狀態(tài)以簡化對主題的描述。基于零樣本 CoT 和 Auto-CoT 的啟發(fā),研究者期望 CoT 的過程成為一種標準化的模式,并通過在 prompt 部分限制 CoT 思維的方向來獲得正確的結果。本文方法的核心是模擬人類思維的過程,重塑思維鏈。表 6 中給出了五種通用的 prompt 策略。

- 單詞思維:這種策略是要求模型解釋單詞并重建知識庫。通常情況下,一個單詞有多種不同的含義,這樣做的效果是讓模型跳出條條框框,根據(jù)生成的解釋重新解釋問題中的單詞。這一過程不會引入新的信息。在 prompt 中,研究者給出了模型正在思考的單詞的例子,模型會根據(jù)新問題自動挑選單詞進行這一過程。
- 問題重載:反復閱讀問題,減少其他文本對思維鏈的干擾。簡而言之,讓模型記住問題。
- 重復狀態(tài):與反復閱讀類似,在一長串推理之后加入一個當前狀態(tài)的小結,目的是幫助模型簡化記憶,減少其他文本對 CoT 的干擾。
- 自我驗證:人類在回答問題時會檢查自己的答案是否正確。因此,在模型得到答案之前,研究者增加了一個自我驗證過程,根據(jù)一些基本信息來判斷答案是否合理。
- 方程制備:對于數(shù)學問題,制作公式可以幫助人類總結和簡化記憶。對于一些需要假設未知數(shù) x 的問題,建立方程是一個必不可少的過程。研究者模擬了這個過程,并讓模型嘗試在數(shù)學問題中建立方程。
總體而言,本文的即時策略都在模型有所體現(xiàn)。表 1 展示的內(nèi)容是其中一個例子,其他四種策略的示例可以在原論文中查看。

實驗及結果
推理步驟與準確性的關系
表 2 比較了使用 GPT-3.5-turbo-1106 在三類推理任務的八個數(shù)據(jù)集上的準確性。
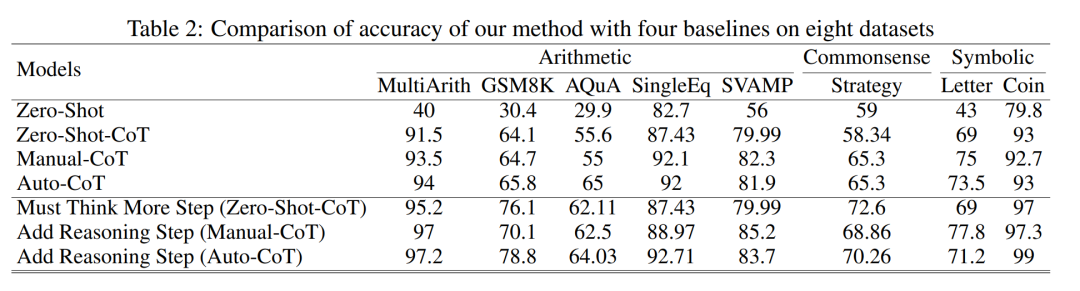
得益于研究者能夠?qū)⑺季S鏈過程標準化,接下來就可以量化在 CoT 的基本流程中增加步驟而對準確性的提高程度。本實驗的結果可以回答之前提出的問題:推理步驟與 CoT 性能之間的關系是什么?該實驗基于 GPT-3.5-turbo-1106 模型。研究者發(fā)現(xiàn),有效的 CoT 過程,例如在 CoT 過程中增加多達六個步驟的額外思維過程,會讓大型語言模型推理能力都會得到提高,并且是在所有的數(shù)據(jù)集上都有體現(xiàn)。換句話說,研究者發(fā)現(xiàn)準確性和 CoT 復雜性之間存在一定的線性關系。

錯誤答案的影響
推理步驟是影響 LLM 性能的唯一因素嗎?研究者做了以下嘗試。將 prompt 中的一個步驟更改為不正確的描述,看看它是否會影響思維鏈。對于這個實驗,本文研究者在所有 prompt 中添加一個錯誤。有關具體示例,請看表 3。

對于算術類型的問題,即使其中一個 prompt 結果出現(xiàn)偏差,對推理過程中思維鏈的影響也是微乎其微的,因此研究者認為在解決算術類型的問題時,大語言模型對提示中思維模式鏈的學習要多于單一計算。對于類似硬幣數(shù)據(jù)的邏輯問題,prompt 結果中的一個偏差往往會帶來整個思維鏈的支離破碎。研究者同樣使用 GPT-3.5-turbo-1106 完成這項實驗,并根據(jù)之前實驗得出的每個數(shù)據(jù)集的最佳步數(shù)保證了性能。結果如圖 4 所示。

壓縮推理步驟
先前的實驗已經(jīng)證明了增加推理步驟可以提高 LLM 推理的準確性。那么在小樣本問題中壓縮基礎推理步驟會損害 LLM 的性能嗎?為此,研究者進行了推理步驟壓縮實驗,并采用實驗設置中概述的技術,將推理過程濃縮成 Auto CoT 和 Few-Shot-CoT,減少推理步驟數(shù)。結果如圖 5 所示。

結果顯示,模型的性能顯著下降,回歸到與零樣本方法基本相當?shù)乃健_@個結果進一步表明,增加 CoT 推理步驟可以提高 CoT 性能,反之亦然。
不同規(guī)格模型的性能對比
研究者還提出疑問,我們能否觀察到縮放現(xiàn)象,即所需的推理步驟與 LLM 的大小有關?研究者研究了各種模型(包括 text-davinci-002、GPT-3.5-turbo-1106 和 GPT-4)中使用的平均推理步驟數(shù)。通過在 GSM8K 上的實驗計算出了每個模型達到峰值性能所需的平均推理步驟。在 8 個數(shù)據(jù)集中,該數(shù)據(jù)集與 text-davinci-002、GPT-3.5-turbo-1106 和 GPT-4 的性能差異最大。可以看出,在初始性能最差的 text-davinci-002 模型中,本文提出的策略具有最高的提升效果。結果如圖 6 所示。

協(xié)同工作實例中問題的影響
問題對 LLM 推理能力的影響是什么?研究者想探討改變 CoT 的推理是否會影響 CoT 的性能。由于本文主要研究推理步驟對性能的影響,所以研究者需要確認問題本身對性能沒有影響。因此,研究者選擇了數(shù)據(jù)集 MultiArith 和 GSM8K 和兩種 CoT 方法(auto-CoT 和 few-shot-CoT)在 GPT-3.5-turbo-1106 中進行實驗。本文的實驗方法包括對這些數(shù)學數(shù)據(jù)集中的樣本問題進行有意的修改,例如改變表 4 中問題的內(nèi)容。

值得注意的是,初步觀察表明,這些對于問題本身的修改對性能的影響是幾個要素里最小的,如表 5 所示。

這一初步發(fā)現(xiàn)表明,推理過程中步驟的長度是大模型的推理能力最主要的影響因素,問題本身的影響并不是最大的。
更多詳細內(nèi)容,請閱讀原論文。















