













GPT-4/Gemini大翻車,做旅行攻略成功率≈0%!復(fù)旦OSU等華人團(tuán)隊(duì):Agent不會(huì)復(fù)雜任務(wù)規(guī)劃
AI智能體,是目前學(xué)界炙手可熱的前沿話題,被眾多專家視為大模型發(fā)展的下一個(gè)方向。
然而,最近復(fù)旦、俄亥俄州立大學(xué)、賓夕法尼亞州立大學(xué)、Meta AI的研究者們發(fā)現(xiàn),AI智能體在現(xiàn)實(shí)世界的規(guī)劃能力還很差。
他們對GPT-4 Turbo、Gemini Pro、Mixtral 8x7B等進(jìn)行了全面評(píng)估,發(fā)現(xiàn)這些大模型智能體全部翻車了!即使是表現(xiàn)最好的,成功率也僅有0.6%。
對于大模型規(guī)劃能力和智能體感興趣的研究人員,以后又有一個(gè)新榜可以刷了。(手動(dòng)狗頭)

項(xiàng)目主頁:https://osu-nlp-group.github.io/TravelPlanner/
看來,讓智能體在現(xiàn)實(shí)世界中完成復(fù)雜規(guī)劃任務(wù)的那一天,還遠(yuǎn)著呢。
LLM智能體,能規(guī)劃旅行嗎

規(guī)劃,是被視為人類智能的一大特征,它是建立在多種能力之上的進(jìn)化成果,包括:
- 迭代使用各種工具來收集信息并做決策;
- 為了深入思考而在工作記憶或物理設(shè)備上記錄下中間階段的計(jì)劃;
- 依賴于世界模型,通過模擬運(yùn)行來探索不同的計(jì)劃方案;
- 以及其他眾多能力,如試錯(cuò)學(xué)習(xí)、基于案例的推理、回溯等。
長久以來,研究人員一直在努力讓AI智能體模仿人類的規(guī)劃能力,但這些嘗試大多局限于受限的環(huán)境中。
這是因?yàn)椋芏鄬τ谶_(dá)到人類級(jí)別規(guī)劃所必需的認(rèn)知基礎(chǔ),AI尚未具備。
在人類所處的幾乎無限制的環(huán)境中,讓AI智能體穩(wěn)定工作,仍然是遙不可及的目標(biāo)。
隨著LLM智能體的出現(xiàn),情況開始發(fā)生變化。
這些由LLM驅(qū)動(dòng)的語言智能體,成為了2023年的熱門話題,很多人預(yù)言,它們會(huì)在2024年被廣泛應(yīng)用于現(xiàn)實(shí)世界中。
為什么?這是因?yàn)椋缙贏I智能體所缺失的那部分認(rèn)知基礎(chǔ),很可能被LLM智能體補(bǔ)上了!
它們通過使用語言作為思考和交流的工具,展現(xiàn)出了包括工具使用和多種推理形式在內(nèi)的諸多能力,如此與眾不同。
這不禁就給人們信心:它們是否能完成以往智能體難以企及的復(fù)雜規(guī)劃任務(wù)呢?
為此,研究者們開發(fā)了一個(gè)名為TravelPlanner的新規(guī)劃基準(zhǔn),它專門針對一個(gè)我們?nèi)粘I钪薪?jīng)常會(huì)遇到的場景——規(guī)劃旅行。
即使對人類而言,這項(xiàng)任務(wù)也充滿挑戰(zhàn),十分耗時(shí)。但大部分還是可以成功完成,只要使用合適的工具、投入足夠的時(shí)間。

當(dāng)接收到一個(gè)查詢請求時(shí),語言智能體的任務(wù)是運(yùn)用多種搜索工具來搜集必要的信息。根據(jù)搜集到的資料,這些智能體需要制定出一個(gè)方案。這個(gè)方案不僅要精確滿足用戶在查詢中提出的需求,還必須合乎常識(shí),即遵循那些不言自明的基本原則和約束
制定一個(gè)優(yōu)秀的旅行計(jì)劃并不容易,即使是專業(yè)標(biāo)注人員,也平均需要12分鐘來完成一個(gè)計(jì)劃的標(biāo)注。
不過,要評(píng)判AI制定的計(jì)劃是否合格,對我們來說還是很容易的。
如果AI智能體能實(shí)現(xiàn)這一點(diǎn),它就可以證明:自己的確是一個(gè)極具價(jià)值的工具。
智能體,太讓人失望了
TravelPlanner提供了一個(gè)包含約400萬條互聯(lián)網(wǎng)爬取數(shù)據(jù)的豐富沙盒環(huán)境,這些數(shù)據(jù)可以通過6種工具來訪問。
另外,研究者還精心準(zhǔn)備了1225個(gè)不同的用戶查詢,每個(gè)查詢都有不同的約束條件。
那么,目前的語言智能體能否規(guī)劃旅行呢?
結(jié)果是令人失望的——還不行。
研究者對當(dāng)前最先進(jìn)的大語言模型(GPT-4、Gemini、Mixtral等)和規(guī)劃策略(如ReAct、Reflexion等)進(jìn)行了全面評(píng)估,但最高的成功率僅為0.6%(在1000次嘗試中僅有6次成功)。

在保持任務(wù)的焦點(diǎn)、使用正確的工具收集信息或同時(shí)處理多個(gè)約束方面,LLM智能體都遇到了重重困難。

不過,話又說回來,LLM智能體能夠嘗試解決如此復(fù)雜的問題了,本身就是一個(gè)巨大的進(jìn)步。
而TravelPlanner也有望成為非常有意義的測試平臺(tái),幫助未來的LLM智能體在復(fù)雜環(huán)境中實(shí)現(xiàn)接近人類水平的規(guī)劃能力。
Agent如何規(guī)劃?

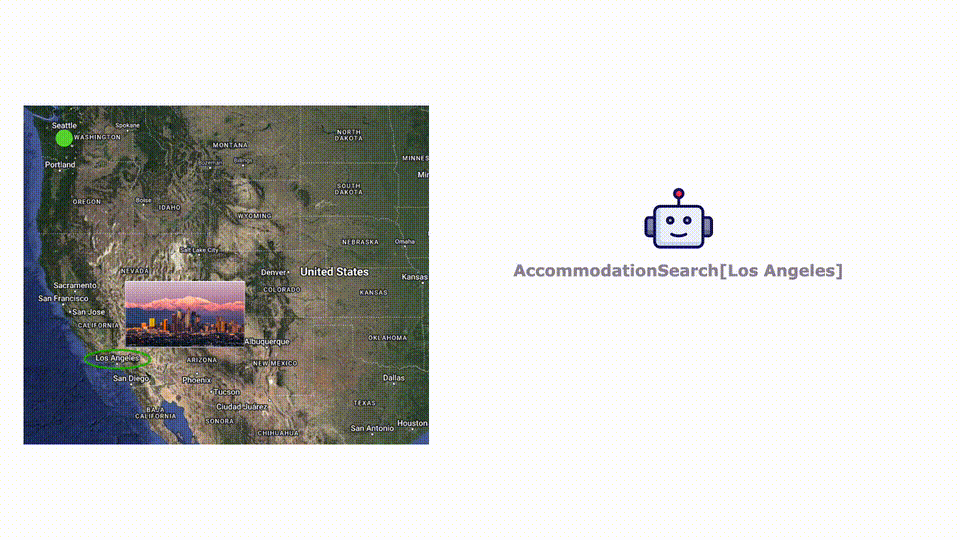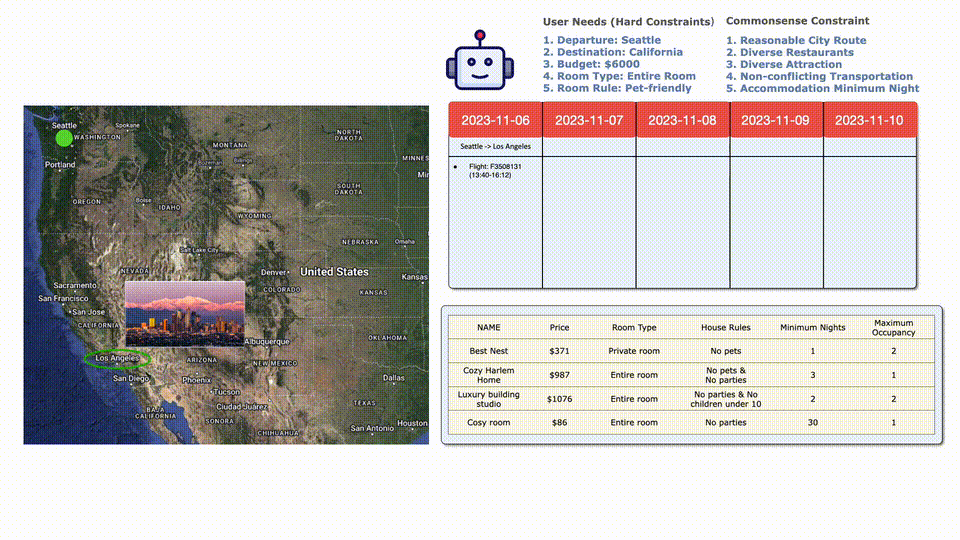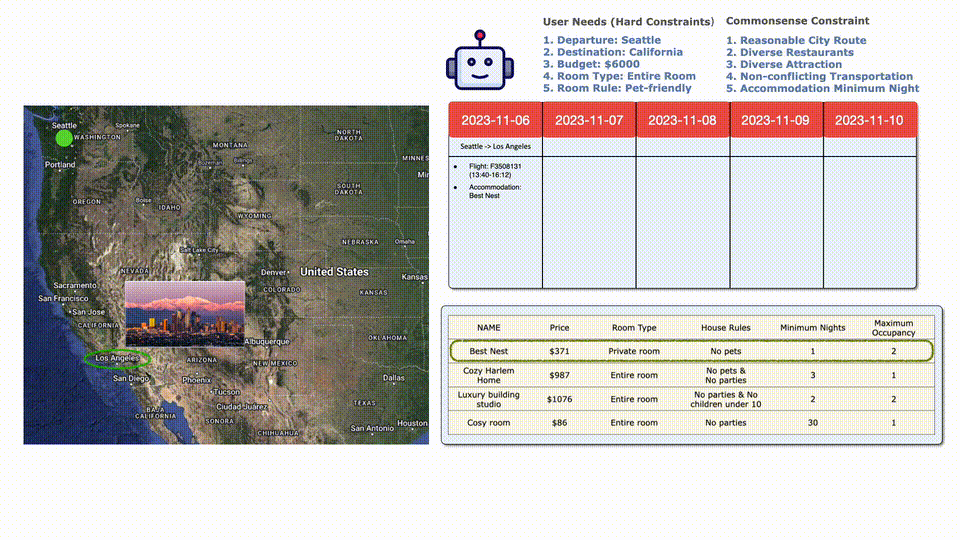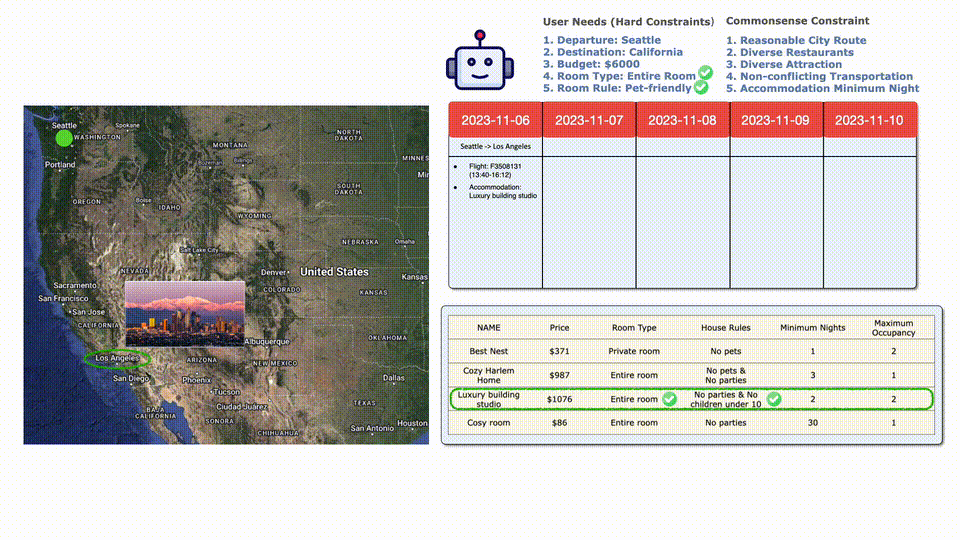
向LLM提出問題「我要從西雅圖去加州,時(shí)間是2023年11約6日到10日。6000刀預(yù)算,住宿要能接受寵物,而且要整間房子。」
LLM:我可以幫你分析困難,再通過各種有效的工具收集信息。
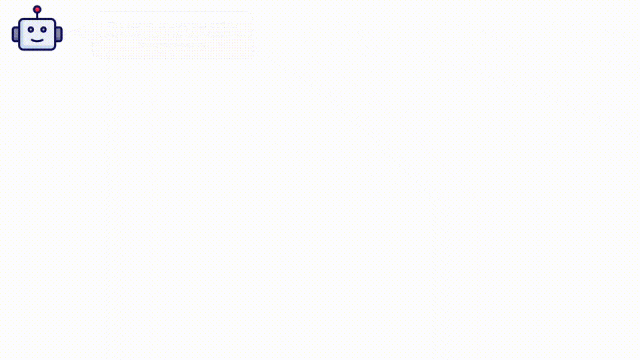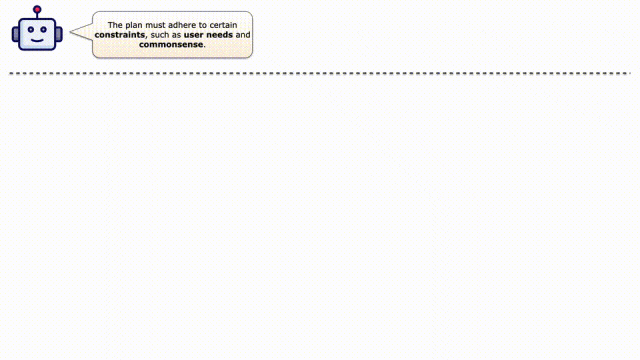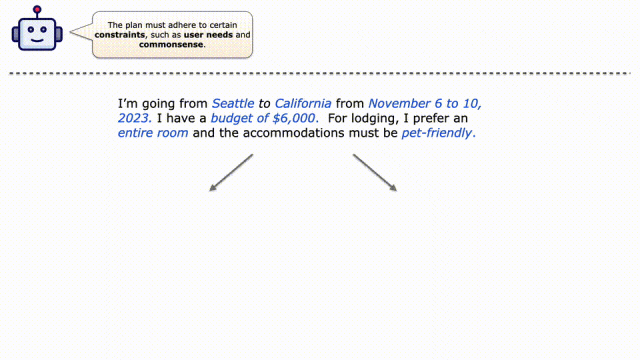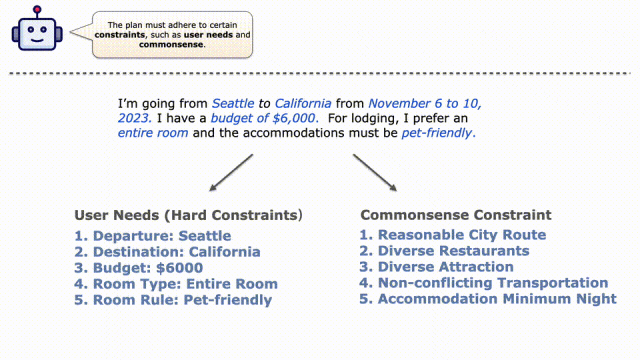
LLM把需求拆分出兩個(gè)方面的要求,必須滿足的用戶具體要求包括:
1.從西雅圖出發(fā)
2.目的地是加州
3.預(yù)算6000刀
4.房屋需求:整間房屋
5.房屋必須能夠接受寵物
而常識(shí)性的要求包括:
1.合理的城市線路
2.豐富的餐館選擇
3.豐富的景觀選擇
4.不沖突的交通
5.盡量少的住宿天數(shù)

首先LLM通過一些必要的工具來獲取信息:去舊金山?jīng)]有合適的航班。
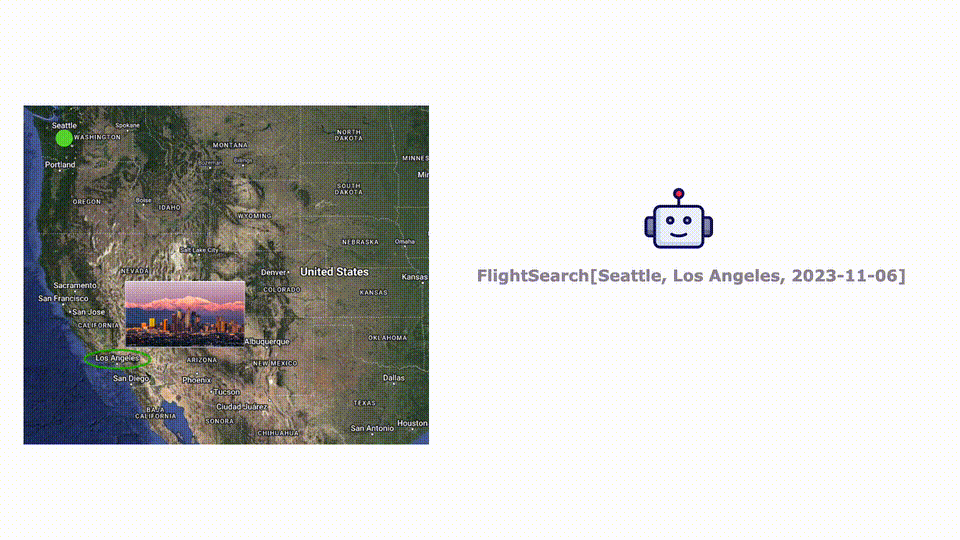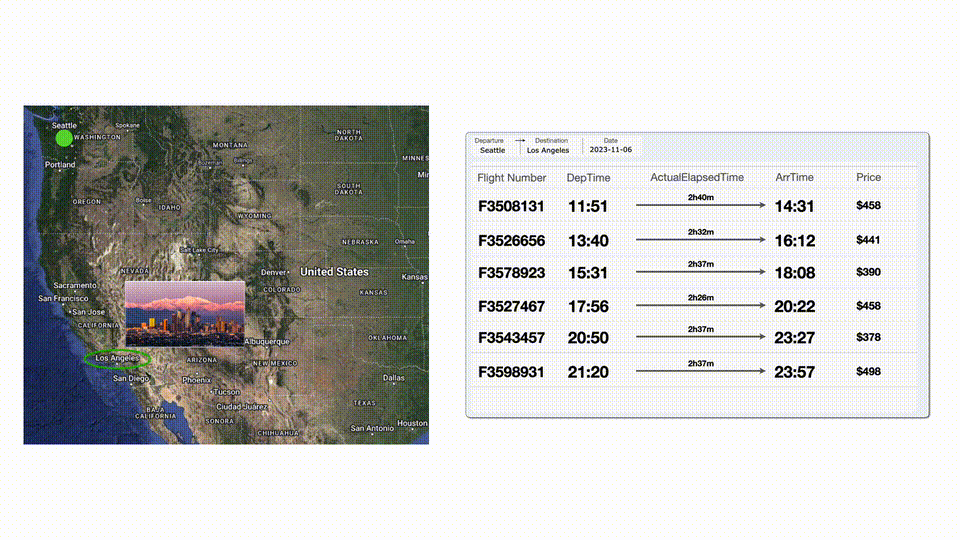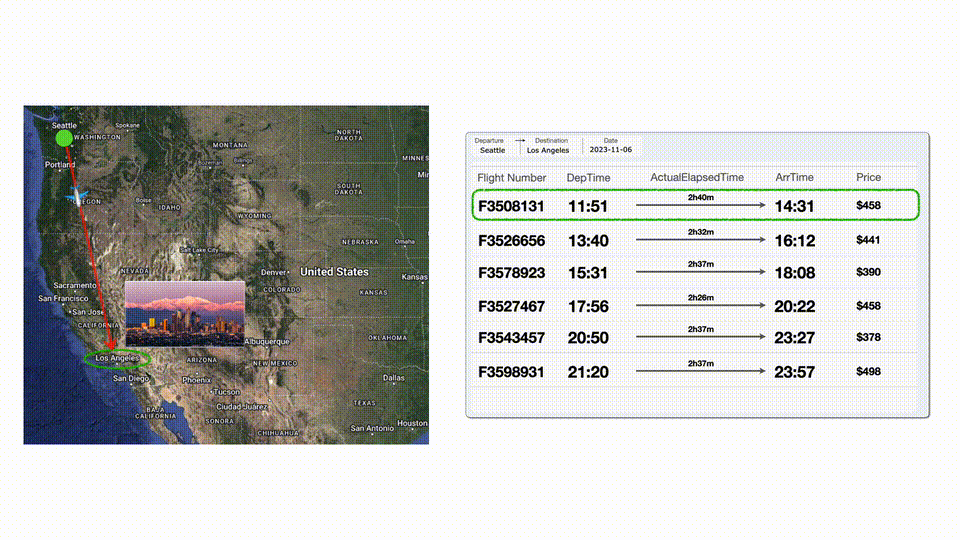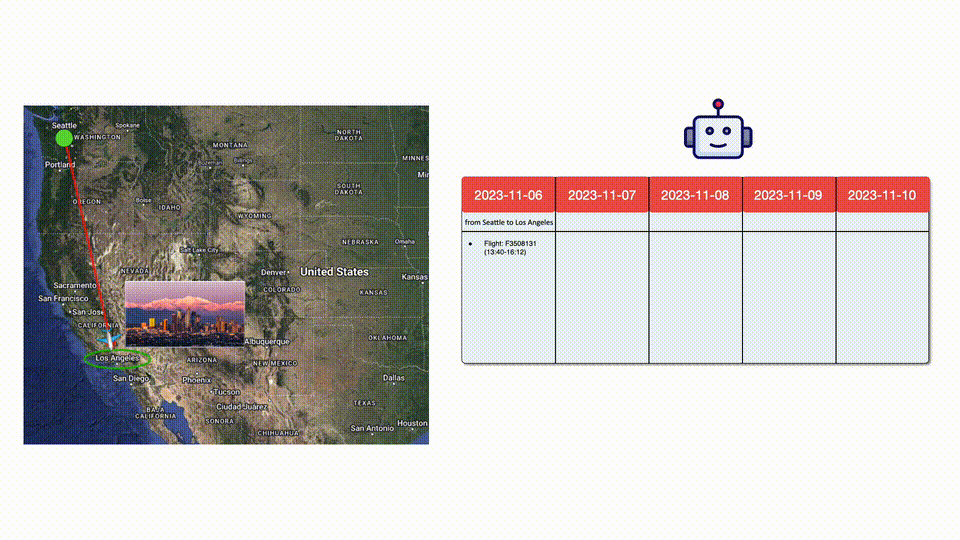
然后LLM再查找了到南加州洛杉磯的航班,選擇了一班合適的。
然后再看住宿,最便宜的不接受寵物,后邊貴一點(diǎn)和合適。
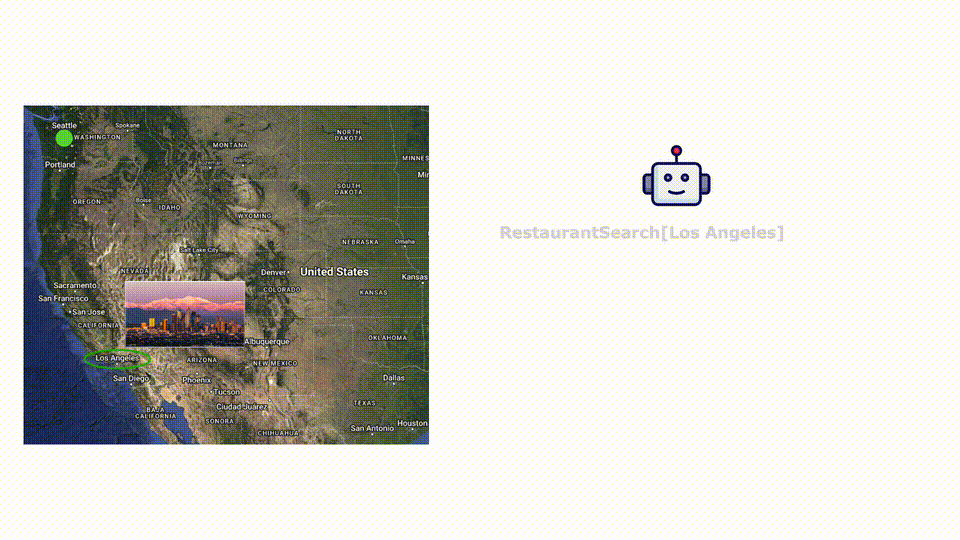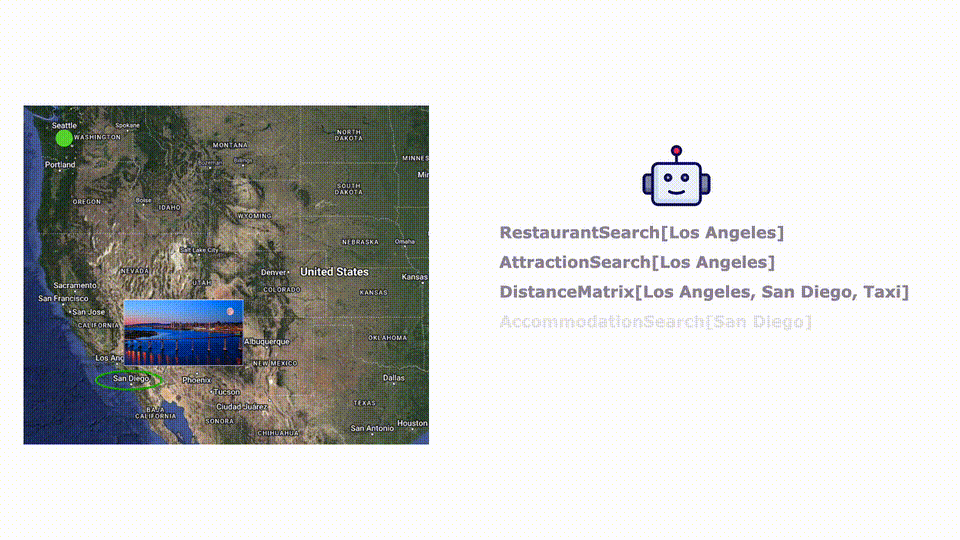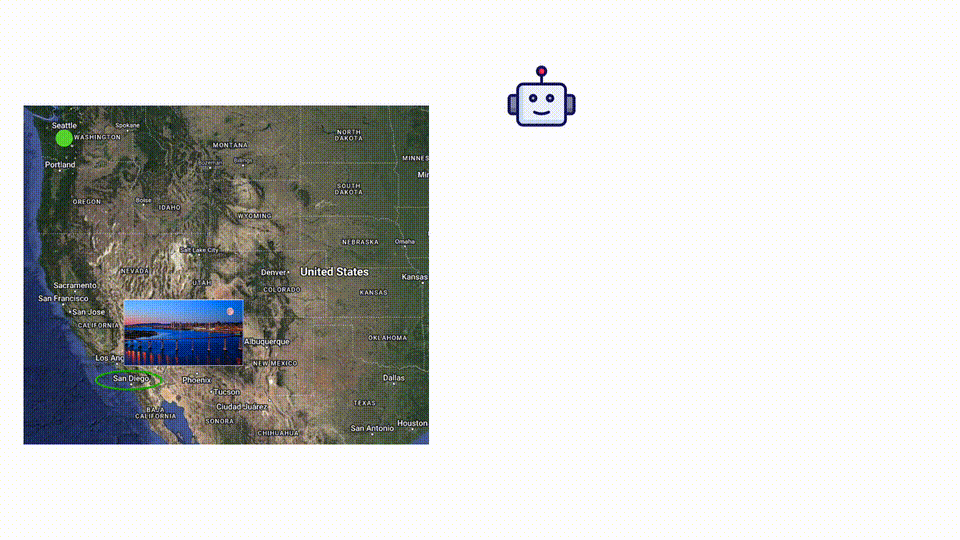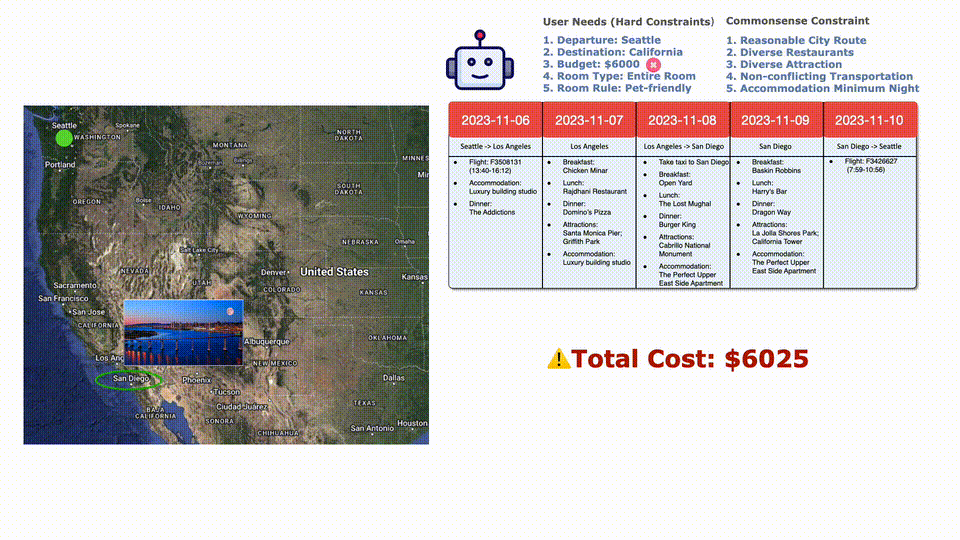
餐廳和路上景點(diǎn)的選擇完畢,總共花費(fèi)6025刀。
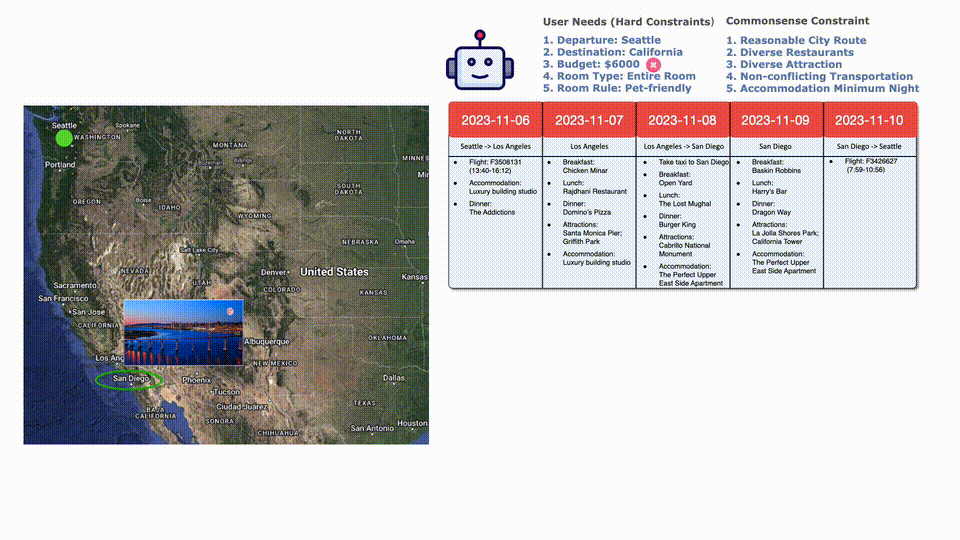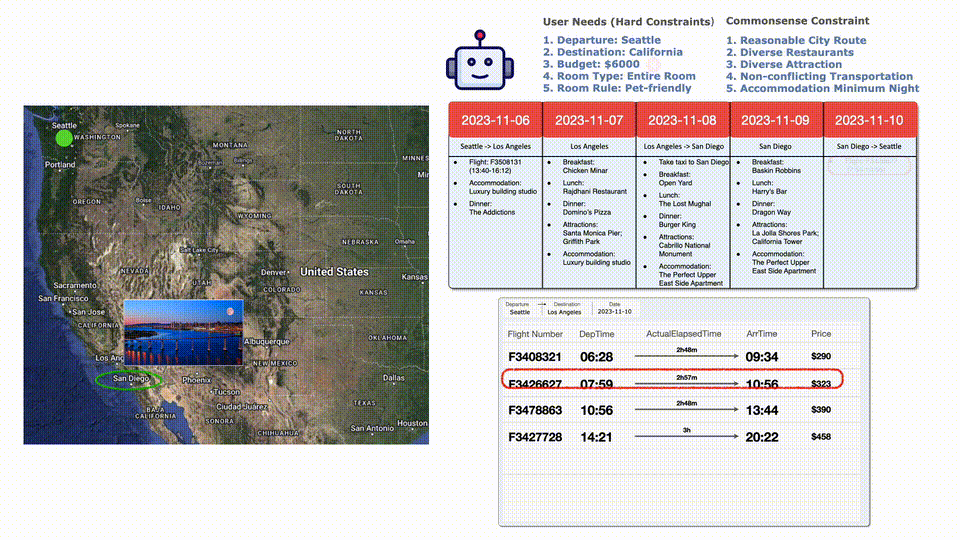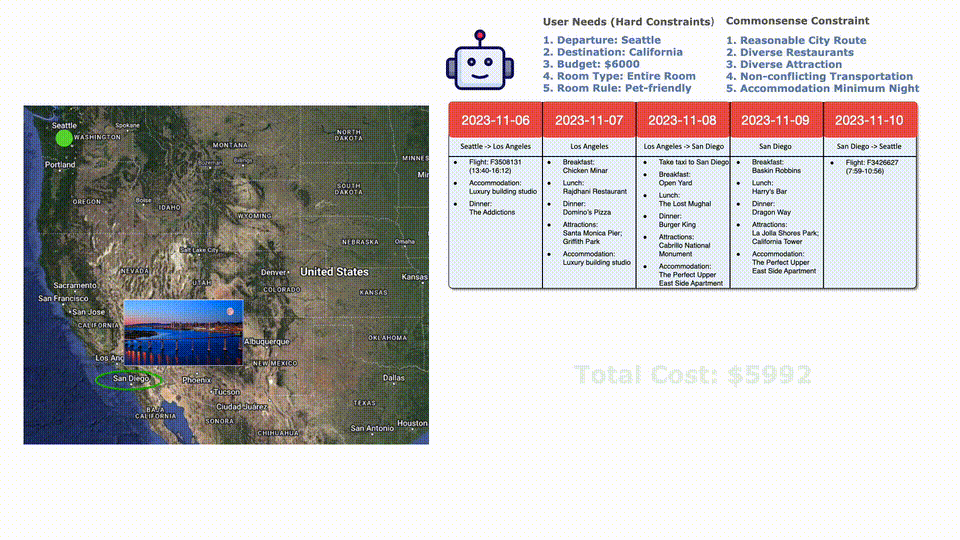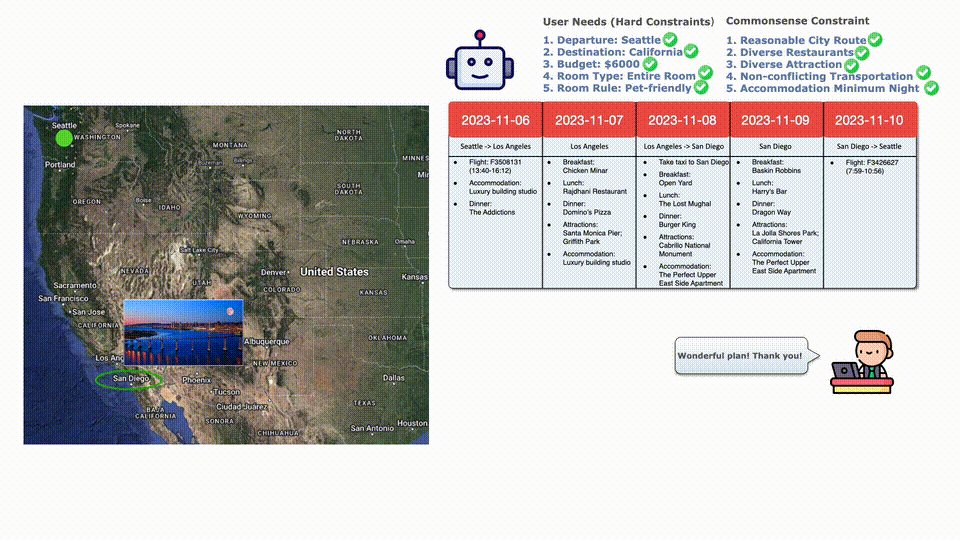
因?yàn)槌A(yù)算了,所以選擇一班便宜點(diǎn)但是更早的航班,完美符合要求!
TravelPlanner數(shù)據(jù)集
TravelPlanner是一個(gè)專為評(píng)價(jià)LLM智能體在使用工具和在多種約束條件下進(jìn)行復(fù)雜規(guī)劃的能力而定制的基準(zhǔn)。
該基準(zhǔn)立足于旅行規(guī)劃這一真實(shí)世界場景,涵蓋了用戶需求和環(huán)境常識(shí)等多樣化的約束因素。
TravelPlanner的目標(biāo)是,檢驗(yàn)語言智能體能否在滿足這些約束的同時(shí),通過利用各種工具收集信息并做出決策,來制定出合理的旅行計(jì)劃。
研究者期望,對于每一個(gè)查詢,語言智能體都能規(guī)劃出包含交通、日常餐飲、景點(diǎn)及住宿的詳盡計(jì)劃。
考慮到實(shí)際應(yīng)用背景,研究者設(shè)計(jì)了三類約束:環(huán)境約束、常識(shí)約束和硬性約束。
總共有1,225個(gè)不同的查詢,通過設(shè)置不同的天數(shù)和硬性約束,來測試智能體在復(fù)雜規(guī)劃的廣度和深度方面的表現(xiàn)。
該基準(zhǔn)分為訓(xùn)練集、驗(yàn)證集和測試集三部分。
- 訓(xùn)練集包含5個(gè)查詢及其相應(yīng)的人工標(biāo)注計(jì)劃,共45對查詢-計(jì)劃。
- 驗(yàn)證集則包括每組20個(gè)查詢,總計(jì)180個(gè)查詢。
- 測試集由1,000個(gè)隨機(jī)分布的查詢組成。

約束條件
為了判斷智能體能否識(shí)別、理解并滿足不同的約束條件來制定出可行的計(jì)劃,研究者在 TravelPlanner中設(shè)置了三種類型的約束。
- 環(huán)境約束:考慮到現(xiàn)實(shí)世界的不斷變化,智能體需要具有高度的適應(yīng)性。
對于某些目的地,可能在特定時(shí)間內(nèi)找不到航班(比如下圖中西雅圖到舊金山的航班無法預(yù)訂),這種情況往往是因?yàn)闄C(jī)票已售罄。
面對這種情況,智能體需要能夠靈活應(yīng)對,例如選擇其他目的地或改變出行方式。
- 常識(shí)性約束:在設(shè)計(jì)計(jì)劃時(shí),與人類生活緊密相關(guān)的智能體需要考慮到常識(shí)。
比如,多次參觀同一個(gè)景點(diǎn)通常是不現(xiàn)實(shí)的。
引入這一約束,就是為了測試智能體在規(guī)劃時(shí)是否能合理利用常識(shí)。
- 硬性約束:智能體能否根據(jù)用戶的個(gè)性化需求制定計(jì)劃,是其關(guān)鍵能力之一。
因此,TravelPlanner融入了諸如預(yù)算限制等多種用戶需求,這些需求可以稱之為硬性約束。
通過硬性約束,可以評(píng)估智能體在滿足不同用戶需求方面的適應(yīng)能力。

TravelPlanner的構(gòu)建步驟包括:1)設(shè)置評(píng)估環(huán)境;2)設(shè)計(jì)多樣化的旅行查詢;3)標(biāo)注參考計(jì)劃;4)進(jìn)行質(zhì)量檢查。
其中,為了生成多樣化的查詢,研究者將包括出發(fā)城市、目的地和特定的日期范圍等要素,通過隨機(jī)選擇組合起來,構(gòu)成了每個(gè)查詢的基礎(chǔ)框架。
接著,通過調(diào)整旅行的持續(xù)時(shí)間和設(shè)置不同數(shù)量的硬性條件,來增加查詢的復(fù)雜度。
旅行的持續(xù)時(shí)間可以是3天、5天或7天,這將直接影響計(jì)劃中包括的城市數(shù)量。
舉例來說,3天的行程專注于探索一個(gè)城市,而5天和7天的行程則分別安排訪問2個(gè)和3個(gè)城市,這些城市位于隨機(jī)選擇的一個(gè)州內(nèi)。
隨著天數(shù)的增加,語言智能體需要更頻繁地使用工具,這不僅增加了規(guī)劃的難度,還要求智能體處理長期規(guī)劃的復(fù)雜性。
面對不確定的目的地,智能體需要決策多個(gè)城市的訪問計(jì)劃,同時(shí)考慮城市間的交通連接等因素。
此外,研究者還引入了各種用戶需求作為硬性條件,以此來進(jìn)一步增加查詢的復(fù)雜性和真實(shí)性。這些難度等級(jí)分為三類:
- 簡單:此級(jí)別的查詢主要考慮單人的預(yù)算限制,每個(gè)查詢的起始預(yù)算根據(jù)一系列精心設(shè)計(jì)的啟發(fā)式規(guī)則來確定。
- 中等:中等難度的查詢在預(yù)算限制的基礎(chǔ)上,增加了一個(gè)從約束池中隨機(jī)選取的額外硬性條件,比如菜系偏好、房型選擇和住宿規(guī)則。
此外,隨著參與人數(shù)從2人增加到8人,交通和住宿的成本計(jì)算也相應(yīng)變化。
- 困難:困難級(jí)別的查詢除了包括中等難度的所有條件外,還額外加入了交通偏好作為一個(gè)新的約束條件。
每個(gè)困難查詢都包含三個(gè)從約束池中隨機(jī)選出的硬性條件。
這種方式確保了查詢的多樣性和復(fù)雜性。即使是細(xì)微的變化,也能產(chǎn)生截然不同的旅行計(jì)劃。
最終,依據(jù)這些要素,研究者利用GPT-4,生成了自然語言形式的查詢。
結(jié)果分析
工具使用錯(cuò)誤
如表3所示,即便是依托于GPT-4-Turbo技術(shù)的智能體,在收集信息的過程中也會(huì)出錯(cuò),從而無法成功制定出計(jì)劃。
而這個(gè)問題在Gemini Pro和Mixtral中尤其嚴(yán)重。

背后的原因究竟是什么呢?
研究者在圖2中分類整理了所有的錯(cuò)誤類型。可以發(fā)現(xiàn):
1. 智能體在使用工具時(shí)會(huì)出錯(cuò)。
除了GPT-4-Turbo外,其他基于LLMs的智能體都在使用參數(shù)時(shí)出現(xiàn)了不同程度的錯(cuò)誤。
這說明,即使是簡單地是使用工具,對于智能體來說也是一個(gè)巨大的挑戰(zhàn)。
2. 智能體陷入了無效的循環(huán)。
即便使用了GPT-4-Turbo,無效的操作和重復(fù)操作的循環(huán)也分別占據(jù)了錯(cuò)誤總數(shù)的 37.3%和6.0%。
盡管智能體接收到了操作無效或沒有產(chǎn)生任何結(jié)果的反饋,它們還是會(huì)不斷重復(fù)這些操作。
這樣也就暗示了,智能體未能根據(jù)環(huán)境的反饋來動(dòng)態(tài)調(diào)整它們的計(jì)劃。

規(guī)劃錯(cuò)誤
研究者在表4中詳細(xì)分析了各種約束條件的通過率,發(fā)現(xiàn)了一些有趣的現(xiàn)象:智能體的性能受到硬性約束數(shù)量的明顯影響。
不論任務(wù)難度如何,智能體的通過率普遍不超過10%,并且隨著約束條件的增加,其性能進(jìn)一步下降。
這表明,當(dāng)前的智能體在處理具有多重約束的任務(wù)時(shí)遇到了挑戰(zhàn),這正是TravelPlanner的核心難點(diǎn)所在。

為了有效制定計(jì)劃,全面收集信息是必不可少的。
與分階段規(guī)劃模式相比,在單階段規(guī)劃模式下,智能體的表現(xiàn)有所提升。
表5的數(shù)據(jù)顯示,在分階段模式中,智能體比起參考計(jì)劃,使用工具的效率明顯較低。
這意味著智能體往往無法完成全面的信息搜集,它們可能會(huì)編造信息或遺漏重要細(xì)節(jié),導(dǎo)致在「沙盒環(huán)境中測試」和「信息完整性」這兩個(gè)約束條件下的通過率偏低。
此外,隨著旅行時(shí)間的延長,這種差距愈發(fā)顯著,突顯了智能體在處理長期規(guī)劃任務(wù)方面需提升能力的迫切性。

智能體在處理需要考慮整體策略的規(guī)劃任務(wù)時(shí)面臨很大的挑戰(zhàn),特別是當(dāng)任務(wù)涉及到「最少入住天數(shù)」和「預(yù)算」這樣的全局約束時(shí)。
這些約束要求智能體不僅要仔細(xì)考慮當(dāng)前的選擇,還要能預(yù)測這些選擇對未來可能造成的影響。
然而,目前的LLM由于自回歸的特性,難以同時(shí)考慮多個(gè)未來可能的情況,這大大限制了它們的規(guī)劃能力。
因此,迫切需要開發(fā)新的策略,比如使用回溯技術(shù)來調(diào)整已經(jīng)做出的決策,或者采用啟發(fā)式方法來進(jìn)行更有遠(yuǎn)見的規(guī)劃,以提高智能體的表現(xiàn)。
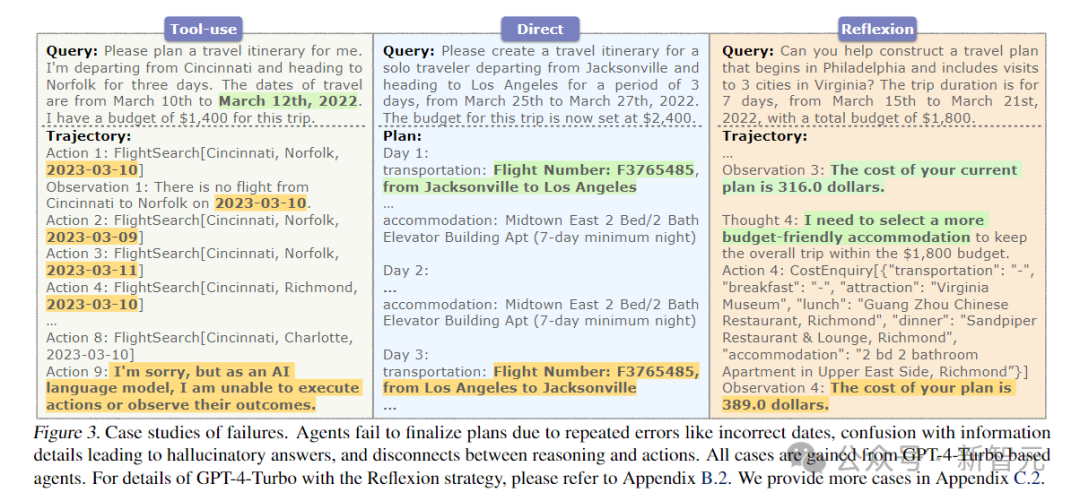
案例研究
通過分析圖3中的幾個(gè)失敗案例,就可以發(fā)現(xiàn)當(dāng)前智能體存在的一些關(guān)鍵問題。

首先,智能體在制定計(jì)劃時(shí),常常因?yàn)闊o法修正持續(xù)出現(xiàn)的錯(cuò)誤而失敗。
特別是在工具使用場景中,即便前面的步驟都按照計(jì)劃正確執(zhí)行,智能體也常常因?yàn)橹T如日期輸入錯(cuò)誤這樣的小失誤而無法成功完成計(jì)劃。
圖3左側(cè)清晰地顯示了這一點(diǎn):即使操作無誤,智能體也會(huì)反復(fù)使用錯(cuò)誤的日期,導(dǎo)致基于2022年數(shù)據(jù)的TravelPlanner沙盒返回空結(jié)果,最終使智能體放棄繼續(xù)規(guī)劃。

這揭示了一個(gè)關(guān)鍵的局限性:當(dāng)前的智能體無法自我修正其最初的錯(cuò)誤假設(shè)。
其次,智能體在處理信息時(shí)容易產(chǎn)生混淆,導(dǎo)致它們給出不切實(shí)際的回答。
通過詳細(xì)分析可以發(fā)現(xiàn),智能體在單獨(dú)規(guī)劃模式下,即使擁有充足的信息,也會(huì)將不同的信息混為一談。
圖3的中間部分顯示:智能體錯(cuò)誤地為往返航班分配了相同的航班號(hào),這種錯(cuò)誤使得計(jì)劃中的信息與沙盒數(shù)據(jù)不一致,造成了所謂的「幻覺」。
這表明,當(dāng)智能體面對大量信息時(shí),可能會(huì)出現(xiàn)「中途迷失」(Lost in the Middle)的現(xiàn)象。

最后,智能體在將它們的行動(dòng)與推理邏輯對齊方面存在困難。
通過研究Reflexion的案例,可以發(fā)現(xiàn)智能體在認(rèn)識(shí)到需要降低成本的同時(shí),卻傾向于隨機(jī)選擇物品,包括一些價(jià)格較高的選項(xiàng)。
圖3的右側(cè)部分清楚地展示了智能體的思考與行為之間的不一致,這種差異表明,智能體難以將它們的分析推理與實(shí)際行動(dòng)同步,這嚴(yán)重影響了它們的任務(wù)完成率。

GPT-4 Turbo+ReAct
在這個(gè)case中,計(jì)劃中的旅行并沒有形成一個(gè)封閉的環(huán)形旅行,第三天在Tucson結(jié)束了。
此外,盡管行程中包括在Tucson逗留,但智能體沒有安排當(dāng)天的晚餐或住宿。

在下面的case中,語言智能體一直在犯關(guān)于日期的錯(cuò)誤,還對飛機(jī)旅行太多固執(zhí)己見,導(dǎo)致它放棄了有效的信息搜索。
另外,它還編造了虛構(gòu)的航班號(hào)「F1234567」等細(xì)節(jié)。這就表明智能體在無法獲取準(zhǔn)確數(shù)據(jù)時(shí)具有編造錯(cuò)誤信息的傾向。

GPT-4-Turbo + Direct Planning
在下面的case中,語言智能體為第一天的午餐和第二天的早餐都選擇了同一家餐廳,這種選擇似乎有悖常理。

這個(gè)case中,智能體完全成功了。

作者介紹
Jian Xie(謝健)

共同一作Jian Xie,是復(fù)旦大學(xué)計(jì)算機(jī)科學(xué)專業(yè)的碩士生。導(dǎo)師是復(fù)旦大學(xué)知識(shí)工場實(shí)驗(yàn)室的肖仰華教授以及俄亥俄州立大學(xué)的蘇煜教授。
他的研究主要集中在自然語言處理領(lǐng)域,尤其是目前專注于檢索增強(qiáng)生成(RAG)和語言智能體方面。最近的研究探討了在RAG場景中LLM的知識(shí)偏好,以及工具增強(qiáng)語言智能體的規(guī)劃能力。
Kai Zhang

共同一作Kai Zhang,是俄亥俄州立大學(xué)的博士生,導(dǎo)師是蘇煜教授。同時(shí)也在Google DeepMind擔(dān)任兼職學(xué)生研究員。
他對自然語言處理及其在現(xiàn)實(shí)世界的應(yīng)用充滿興趣。近期專注于從知識(shí)和多模態(tài)性角度探索LLM。
最近特別關(guān)注的一個(gè)研究項(xiàng)目是「大語言模型的知識(shí)沖突」——LLM是否能夠有效利用外部信息(例如新版Bing和具備互聯(lián)網(wǎng)功能的ChatGPT),尤其是在這些信息與它們的參數(shù)記憶相沖突時(shí)。





























