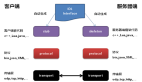
系統設計面試問題:如何設計 Spotify,一個音樂流媒體系統
這是一道系統設計面試題,就是如何設計一個類似 Spotify 的音樂流媒體系統。在真正的面試中,通常,您會關注應用程序的一兩個主要功能,但在本文中,我想對如何設計這樣的系統進行一個較為全面的概述,然后您可以更深入地研究其中每個單獨的部分。
本文內容可以分為以下四點,
- 分析系統的功能需求、用戶量以及數據量
- 設計系統的高層架構,包括移動應用程序、負載均衡器、Web 服務器、數據存儲等組件
- 選擇合適的存儲結構,包括 Blob 存儲和 SQL 數據庫,并設計數據表和關系
- 根據系統的擴展需求,引入 CDN、緩存、數據庫復制等技術,提高系統性能
初始預估
在這個階段,我們假設系統需要處理 50 萬用戶和 3000 萬首歌曲。我們將有播放歌曲的用戶和上傳歌曲的藝術家。
 圖片
圖片
數據估計
我們首先估計我們需要的存儲空間。我們需要將歌曲存儲在某種存儲中,以及存儲歌曲元數據和用戶元數據。我們假設:
- 歌曲存儲:Spotify 和類似服務通常使用 Ogg Vorbis 或 AAC 等格式進行流式傳輸,平均歌曲大小為 3MB
- 歌曲元數據:每首歌曲的平均元數據大小約為 100 字節
- 用戶元數據:平均而言,我們將為每個用戶存儲 1KB 的數據
 圖片
圖片
根據這些假設,我們可以計算出我們需要的存儲空間:
 圖片
圖片
系統架構
我們的系統由以下幾個組件組成:
 圖片
圖片
移動應用程序:這是用戶與服務交互的前端。用戶可以搜索歌曲、播放音樂、創建播放列表等。當用戶執行操作(例如播放歌曲)時,應用程序會向后端服務器發送請求。
負載均衡器:這是一個中間層,它將傳入的流量分配到多個 Web 服務器上。這提高了我們的應用程序的可用性和容錯能力。
Web 服務器 (API) :這是處理來自移動應用程序的請求的 API 層。例如,如果用戶想要播放歌曲,請求就會發送到這些網絡服務器。然后,服務器確定歌曲所在的位置(在數據庫或存儲服務中)以及如何檢索它。
存儲結構
數據存儲將分為兩個獨立的服務 - 歌曲的 Blob 存儲(我們將在其中存儲實際的歌曲文件)和 SQL 數據庫(我們將在其中存儲歌曲和用戶元數據)。
 圖片
圖片
歌曲 - Blob 存儲:這是一個用于存儲實際的歌曲文件的 Blob(二進制大對象)存儲服務。這些服務旨在存儲大量非結構化數據。我們可以使用一些云服務提供商的 Blob 存儲服務,例如 AWS S3、GCP、Azure Blob 存儲等。
用戶、藝術家和歌曲元數據 — SQL 數據庫:這是一個用于存儲結構化數據的 SQL 數據庫服務。這些數據包括用戶信息(如用戶名、密碼和電子郵件地址)和歌曲元數據(如歌曲名稱、藝術家姓名、專輯詳細信息等)。我們可以使用一些關系型數據庫管理系統,例如 MySQL、PostgreSQL、Oracle 等。
為什么用戶、藝術家和歌曲元數據選擇用 SQL 數據庫?因為 SQL 數據庫非常適合此類結構化數據,因為它們允許復雜的查詢以及不同類型數據之間的關系。
每個歌曲文件都存儲為“blob”,SQL 數據庫通常會存儲對此文件的訪問連接(如 URL)。
表結構設計
我們的表結構設計由以下幾個部分組成:
 圖片
圖片
- 歌曲 - Blob 存儲:每個歌曲文件都存儲為一個“blob”,它有一個唯一的標識符和一個 URL,指向它在 Blob 存儲中的位置。我們可以使用這個 URL 來訪問和下載歌曲文件。
- 用戶、藝術家和歌曲元數據 - SQL 數據庫:我們在 SQL 數據庫中創建了以下幾個表來存儲結構化數據:
- Users:這個表包含了用戶的元數據,如 UserID、Username、Email、PasswordHash、CreatedAt、LastLogin 等。
- Songs:這個表包含了歌曲的元數據,如 SongID、Title、ArtistID、Duration、ReleaseDate 和 FileURL。FileURL 是歌曲文件在 Blob 存儲中的 URL,我們可以使用它來訪問和下載歌曲文件。
- Artists:這個表包含了藝術家的信息,如 ArtistID、Name、Bio、Country 等。
- ArtistsSongs:這是一個連接表,它建立了 Artists 和 Songs 表之間的多對多關系。它包含了 ArtistID(指向 Artists 表的外鍵)和 SongID(指向 Songs 表的外鍵)。
播放歌曲
當我們存儲結構設計好以后,我們就可以進行播放歌曲的操作了。
 圖片
圖片
當用戶想要播放一首歌曲時,移動應用程序會向 Web 服務器發送一個請求,包含歌曲的 ID。Web 服務器會從 SQL 數據庫中查詢歌曲的元數據,包括 FileURL。然后,Web 服務器會使用 FileURL 從 Blob 存儲中獲取歌曲文件,并將其逐塊流式傳輸到移動應用程序。
或者我們可以直接將 FileURL 返回給移動應用程序,讓它從 Blob 存儲中直接下載歌曲文件,從而減少 Web 服務器的負載。
系統擴展
當系統處于規模化階段,我們假設系統需要處理 5000 萬用戶和 2 億首歌曲。我們需要重新計算數據,引入緩存和 CDN,以及擴展數據庫。
數據估計
我們需要重新計算我們需要的存儲空間。我們需要將歌曲存儲在某種存儲中,以及存儲歌曲元數據和用戶元數據。我們假設:
- 歌曲存儲:Spotify 和類似服務通常使用 Ogg Vorbis 或 AAC 等格式進行流式傳輸,平均歌曲大小為 3MB
- 歌曲元數據:每首歌曲的平均元數據大小約為 100 字節
- 用戶元數據:平均而言,我們將為每個用戶存儲 1KB 的數據
 圖片
圖片
根據這些假設,我們可以計算出我們需要的存儲空間:
 圖片
圖片
接下來,我們的系統架構與初始階段相比,有以下幾個變化。
引入 CDN
由于流量增加,我們需要引入緩存和 CDN(如 Cloudfront / Cloudflare)來提供歌曲,并且每個 CDN 在地理位置上都將靠近一個區域。因此它可以比我們原有的 web 服務器更快地提供歌曲。
并且我們可以使用 LRU(最近最少使用)驅逐策略來緩存流行歌曲,不流行的歌曲仍然會從 Blob 存儲中獲取,然后緩存到 CDN。歌曲文件還可以直接從云存儲傳輸到客戶端,這將減少網絡服務器的負載。
 圖片
圖片
擴展數據庫
數據庫也需要擴展。由于我們知道我們的應用程序的讀取次數多于寫入次數,這意味著有很多用戶在聽歌曲,但上傳歌曲的藝術家數量相對較少。
我們可以搭建數據庫主從,將用戶的讀操作和寫操作分開,當用戶檢索歌曲和元數據時請求會到達從數據庫,當用戶上傳歌曲時,請求會到達主數據庫。通過讀寫分離,我們可以提高應用程序的歌曲播放速度。
 圖片
圖片
總結一下
我們給大家介紹了如何設計一個類似 Spotify 的音樂流媒體系統,從基礎版本到規模化階段,我們都給出了合理的方案和估計。我們的設計具有以下優點:
- 可用性高:我們使用了負載均衡器、CDN、緩存和數據庫復制等技術,來保證我們的系統在高流量下仍然可以正常運行,并且能夠應對故障和異常情況。
- 性能好:我們使用了 Blob 存儲和 SQL 數據庫來分別存儲非結構化和結構化數據,并且優化了數據操作和傳輸的效率,使得用戶可以快速地搜索和播放歌曲。
- 擴展性強:我們的系統可以根據用戶量和數據量的增長,動態地調整存儲和計算資源,以滿足不同的需求和場景。
當然我們的設計也有一些地方沒有闡述,大家可以自己研究,
- 數據一致性:由于我們使用了數據庫復制和緩存等技術,我們的系統可能會出現數據不一致的情況,例如,當一個藝術家更新了一首歌曲的元數據時,用戶可能會看到不同的版本,取決于他們訪問的是哪個數據庫或緩存節點。
- 數據安全性:由于我們的系統涉及到用戶和藝術家的敏感信息,例如密碼、電子郵件、歌曲版權等,我們需要保證這些數據的安全性,防止被泄露或篡改。我們需要使用一些加密和身份驗證等技術,來保護我們的數據和服務。
- 數據分析:由于我們的系統收集了大量的用戶和歌曲的數據,我們可以利用這些數據進行一些數據分析和挖掘,例如,推薦系統、用戶畫像、歌曲分類等。這些功能可以提高我們的系統的價值和用戶體驗,但也需要額外的存儲和計算資源。