許多主要新聞媒體正屏蔽 OpenAI 爬蟲
作者:Zicheng
據路透社研究所的一項調查,越來越多的新聞媒體已對OpenAI的數據爬取說“不”,在傳統媒體領域,這一比例甚至超過了50%。
自OpenAI的內容生成式人工智能模型面世以來,大量互聯網數據成為了不斷訓練和優化模型的“餌料”,但據路透社研究所的一項調查,有越來越多的新聞媒體已對OpenAI的數據爬取說“不”,在傳統媒體領域,這一比例甚至超過了50%。
路透社研究所分析了《紐約時報》、《華爾街日報》、《華盛頓郵報》、CNN、NPR 等多家主流新聞媒體,涵蓋美國、英國、德國、印度等10個國家,并將其歸為傳統印刷媒體(紙媒)、廣播電視媒體、數字媒體三大類。研究發現,57%的傳統印刷媒體屏蔽了OpenAI 的爬蟲程序,廣播電視媒體和數字媒體的比例分別為48%和 31%。
研究還發現,屏蔽 OpenAI 的新聞網站比例因國家和地區差異而存在很大不同,在美國,這一比例高達79%,而在墨西哥和波蘭僅為 20%。
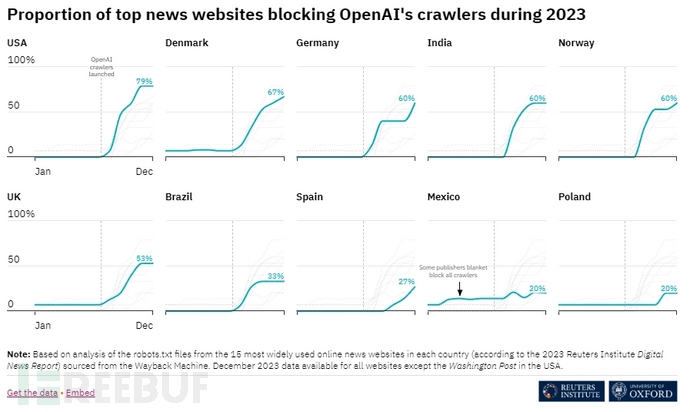
所研究調查的10個國家新聞媒體對 OpenAI爬蟲采取屏蔽措施的比例差異
此外, 在屏蔽了OpenAI 爬蟲的新聞媒體中,有97%也同樣屏蔽了谷歌人工智能的爬蟲。
研究揭示了一些新聞媒體不希望他們的內容被人工智能使用,如果人們使用人工智能從網絡上獲取新聞,這些媒體會認為自己將被拋棄或取代。Gartner 副總裁、杰出分析師安德魯·弗蘭克 (Andrew Frank) 表示:“路透社的研究強調了生成式人工智能面臨的一個根本挑戰:它依賴于真實的人生成的真實內容,而這些人將其視為對他們生計的威脅。”
與此同時,康奈爾大學最近的一項研究發現,當新的人工智能模型根據先前模型而不是人類輸入的數據進行訓練時,它們往往會趨向于“模型崩潰”或退化,導致越來越多地生成錯誤信息。
OpenAI 于去年 8 月初推出了人工智能爬蟲,谷歌也于 9 月緊隨其后。根據這項研究,一旦這些媒體做出屏蔽決定,恐將很難改變立場對其進行解除。
責任編輯:趙寧寧
來源:
FreeBuf.COM