Stable Diffusion 3論文終于發(fā)布,架構(gòu)細(xì)節(jié)大揭秘,對(duì)復(fù)現(xiàn)Sora有幫助?
Stable Diffusion 3 的論文終于來了!
這個(gè)模型于兩周前發(fā)布,采用了與 Sora 相同的 DiT(Diffusion Transformer)架構(gòu),一經(jīng)發(fā)布就引起了不小的轟動(dòng)。
與之前的版本相比,Stable Diffusion 3 生成的圖在質(zhì)量上實(shí)現(xiàn)了很大改進(jìn),支持多主題提示,文字書寫效果也更好了(明顯不再亂碼)。
Stability AI 表示,Stable Diffusion 3 是一個(gè)模型系列,參數(shù)量從 800M 到 8B 不等。這個(gè)參數(shù)量意味著,它可以在很多便攜式設(shè)備上直接跑,大大降低了 AI 大模型的使用門檻。
在最新發(fā)布的論文中,Stability AI 表示,在基于人類偏好的評(píng)估中,Stable Diffusion 3 優(yōu)于當(dāng)前最先進(jìn)的文本到圖像生成系統(tǒng),如 DALL?E 3、Midjourney v6 和 Ideogram v1。不久之后,他們將公開該研究的實(shí)驗(yàn)數(shù)據(jù)、代碼和模型權(quán)重。
在論文中,Stability AI 透露了關(guān)于 Stable Diffusion 3 的更多細(xì)節(jié)。

- 論文標(biāo)題:Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
- 論文鏈接:https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable+Diffusion+3+Paper.pdf
架構(gòu)細(xì)節(jié)
對(duì)于文本到圖像的生成,Stable Diffusion 3 模型必須同時(shí)考慮文本和圖像兩種模式。因此,論文作者稱這種新架構(gòu)為 MMDiT,意指其處理多種模態(tài)的能力。與之前版本的 Stable Diffusion 一樣,作者使用預(yù)訓(xùn)練模型來推導(dǎo)合適的文本和圖像表征。具體來說,他們使用了三種不同的文本嵌入模型 —— 兩種 CLIP 模型和 T5—— 來編碼文本表征,并使用改進(jìn)的自編碼模型來編碼圖像 token。
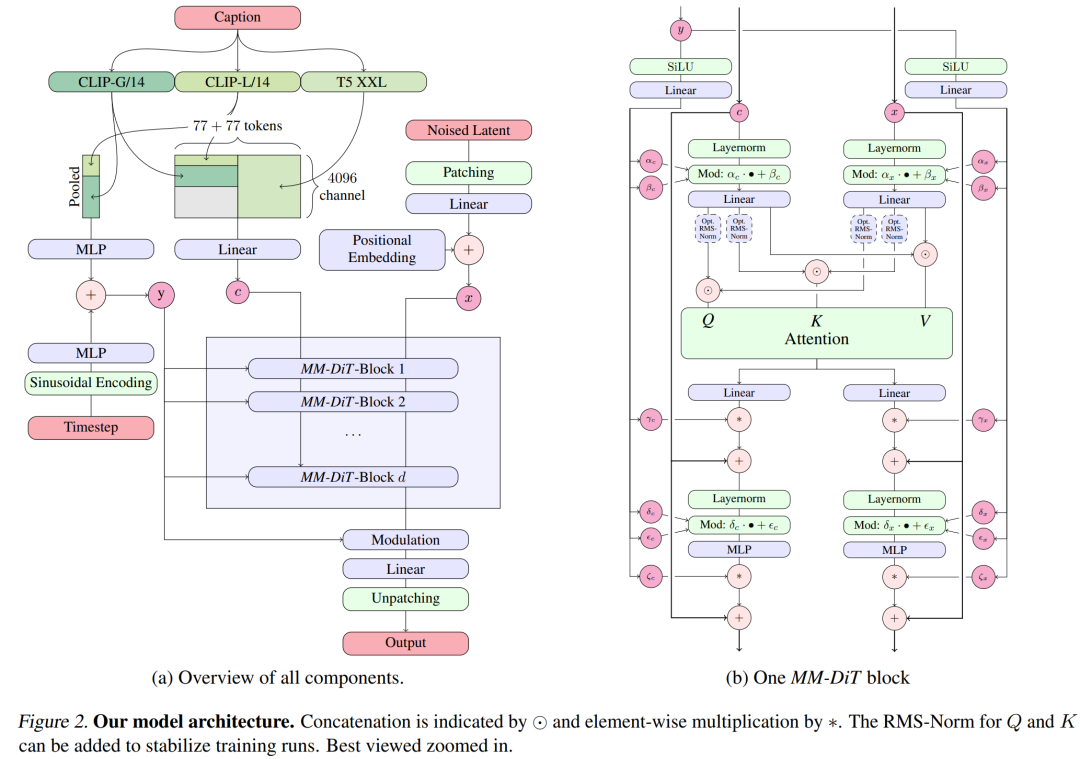
Stable Diffusion 3 模型架構(gòu)。
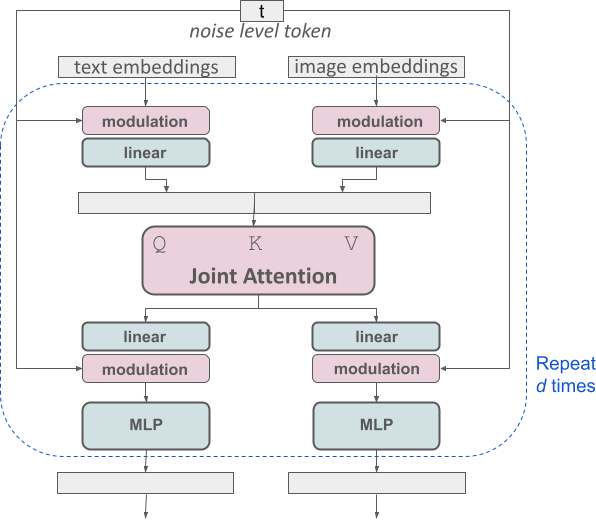
改進(jìn)的多模態(tài)擴(kuò)散 transformer:MMDiT 塊。
SD3 架構(gòu)基于 Sora 核心研發(fā)成員 William Peebles 和紐約大學(xué)計(jì)算機(jī)科學(xué)助理教授謝賽寧合作提出的 DiT。由于文本嵌入和圖像嵌入在概念上有很大不同,因此 SD3 的作者對(duì)兩種模態(tài)使用兩套不同的權(quán)重。如上圖所示,這相當(dāng)于為每種模態(tài)設(shè)置了兩個(gè)獨(dú)立的 transformer,但將兩種模態(tài)的序列結(jié)合起來進(jìn)行注意力運(yùn)算,從而使兩種表征都能在各自的空間內(nèi)工作,同時(shí)也將另一種表征考慮在內(nèi)。
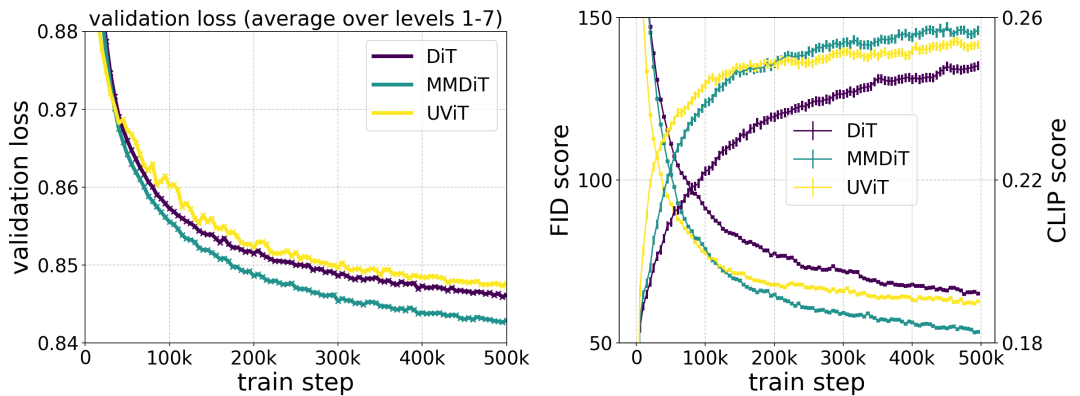
在訓(xùn)練過程中測(cè)量視覺保真度和文本對(duì)齊度時(shí),作者提出的 MMDiT 架構(gòu)優(yōu)于 UViT 和 DiT 等成熟的文本到圖像骨干。
通過這種方法,信息可以在圖像和文本 token 之間流動(dòng),從而提高模型的整體理解能力,并改善所生成輸出的文字排版。正如論文中所討論的那樣,這種架構(gòu)也很容易擴(kuò)展到視頻等多種模式。

得益于 Stable Diffusion 3 改進(jìn)的提示遵循能力,新模型有能力制作出聚焦于各種不同主題和質(zhì)量的圖像,同時(shí)還能高度靈活地處理圖像本身的風(fēng)格。

通過 re-weighting 改進(jìn) Rectified Flow
Stable Diffusion 3 采用 Rectified Flow(RF)公式,在訓(xùn)練過程中,數(shù)據(jù)和噪聲以線性軌跡相連。這使得推理路徑更加平直,從而減少了采樣步驟。此外,作者還在訓(xùn)練過程中引入了一種新的軌跡采樣計(jì)劃。他們假設(shè),軌跡的中間部分會(huì)帶來更具挑戰(zhàn)性的預(yù)測(cè)任務(wù),因此該計(jì)劃給予軌跡中間部分更多權(quán)重。他們使用多種數(shù)據(jù)集、指標(biāo)和采樣器設(shè)置進(jìn)行比較,并將自己提出的方法與 LDM、EDM 和 ADM 等 60 種其他擴(kuò)散軌跡進(jìn)行了測(cè)試。結(jié)果表明,雖然以前的 RF 公式在少步采樣情況下性能有所提高,但隨著步數(shù)的增加,其相對(duì)性能會(huì)下降。相比之下,作者提出的重新加權(quán) RF 變體能持續(xù)提高性能。
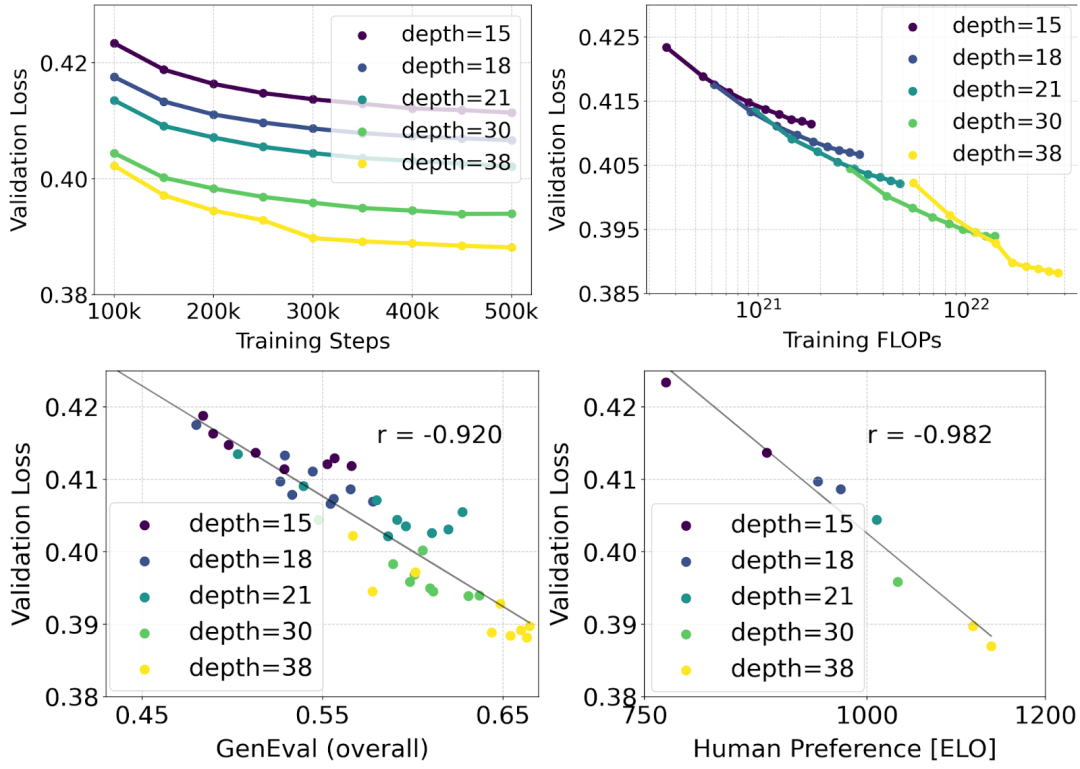
擴(kuò)展 Rectified Flow Transformer 模型
作者利用重新加權(quán)的 Rectified Flow 公式和 MMDiT 骨干對(duì)文本到圖像的合成進(jìn)行了擴(kuò)展(scaling)研究。他們訓(xùn)練的模型從帶有 450M 個(gè)參數(shù)的 15 個(gè)塊到帶有 8B 個(gè)參數(shù)的 38 個(gè)塊不等,并觀察到驗(yàn)證損失隨著模型大小和訓(xùn)練步驟的增加而平穩(wěn)降低(上圖的第一行)。為了檢驗(yàn)這是否轉(zhuǎn)化為對(duì)模型輸出的有意義改進(jìn),作者還評(píng)估了自動(dòng)圖像對(duì)齊指標(biāo)(GenEval)和人類偏好分?jǐn)?shù)(ELO)(上圖第二行)。結(jié)果表明,這些指標(biāo)與驗(yàn)證損失之間存在很強(qiáng)的相關(guān)性,這表明后者可以很好地預(yù)測(cè)模型的整體性能。此外,scaling 趨勢(shì)沒有顯示出飽和的跡象,這讓作者對(duì)未來繼續(xù)提高模型性能持樂觀態(tài)度。
靈活的文本編碼器
通過移除用于推理的內(nèi)存密集型 4.7B 參數(shù) T5 文本編碼器,SD3 的內(nèi)存需求可顯著降低,而性能損失卻很小。如圖所示,移除該文本編碼器不會(huì)影響視覺美感(不使用 T5 時(shí)的勝率為 50%),只會(huì)略微降低文本一致性(勝率為 46%)。不過,作者建議在生成書面文本時(shí)加入 T5,以充分發(fā)揮 SD3 的性能,因?yàn)樗麄冇^察到,如果不加入 T5,生成排版的性能下降幅度更大(勝率為 38%),如下圖所示:

只有在呈現(xiàn)涉及許多細(xì)節(jié)或大量書面文本的非常復(fù)雜的提示時(shí),移除 T5 進(jìn)行推理才會(huì)導(dǎo)致性能顯著下降。上圖顯示了每個(gè)示例的三個(gè)隨機(jī)樣本。
模型性能
作者將 Stable Diffusion 3 的輸出圖像與其他各種開源模型(包括 SDXL、SDXL Turbo、Stable Cascade、Playground v2.5 和 Pixart-α)以及閉源模型(如 DALL-E 3、Midjourney v6 和 Ideogram v1)進(jìn)行了比較,以便根據(jù)人類反饋來評(píng)估性能。在這些測(cè)試中,人類評(píng)估員從每個(gè)模型中獲得輸出示例,并根據(jù)模型輸出在多大程度上遵循所給提示的上下文(prompt following)、在多大程度上根據(jù)提示渲染文本(typography)以及哪幅圖像具有更高的美學(xué)質(zhì)量(visual aesthetics)來選擇最佳結(jié)果。
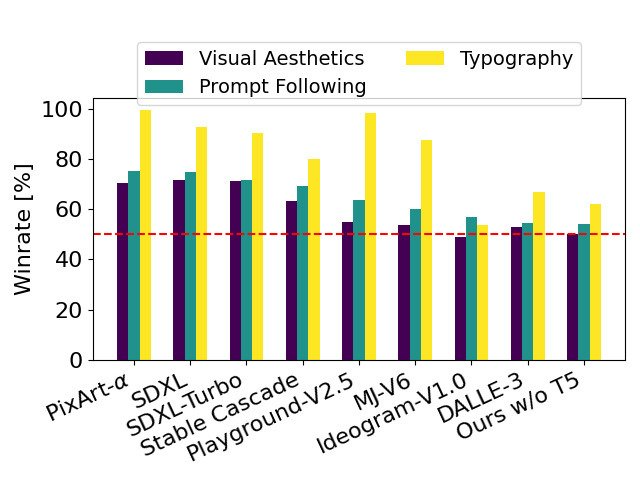
以 SD3 為基準(zhǔn),這個(gè)圖表概述了它在基于人類對(duì)視覺美學(xué)、提示遵循和文字排版的評(píng)估中的勝率。
從測(cè)試結(jié)果來看,作者發(fā)現(xiàn) Stable Diffusion 3 在上述所有方面都與當(dāng)前最先進(jìn)的文本到圖像生成系統(tǒng)相當(dāng),甚至更勝一籌。
在消費(fèi)級(jí)硬件上進(jìn)行的早期未優(yōu)化推理測(cè)試中,最大的 8B 參數(shù) SD3 模型適合 RTX 4090 的 24GB VRAM,使用 50 個(gè)采樣步驟生成分辨率為 1024x1024 的圖像需要 34 秒。

此外,在最初發(fā)布時(shí),Stable Diffusion 3 將有多種變體,從 800m 到 8B 參數(shù)模型不等,以進(jìn)一步消除硬件障礙。


更多細(xì)節(jié)請(qǐng)參考原論文。
參考鏈接:https://stability.ai/news/stable-diffusion-3-research-paper