一文解析如何基于 LangChain 構(gòu)建 LLM 應(yīng)用程序
Hello folks,我是 Luga,今天我們繼續(xù)來聊一下人工智能(AI)生態(tài)領(lǐng)域相關(guān)的技術(shù) - LangChain ,本文將繼續(xù)聚焦在針對 LangChain 的技術(shù)進(jìn)行剖析,使得大家能夠了解 LangChain 實(shí)現(xiàn)機(jī)制以便更好地對利用其進(jìn)行應(yīng)用及市場開發(fā)。
在日新月異的人工智能領(lǐng)域,語言模型已經(jīng)成為舞臺(tái)主角,重新定義了人機(jī)交互的方式。ChatGPT 的廣泛認(rèn)可以及 Google 等科技巨頭紛紛推出類似產(chǎn)品,使語言模型,尤其是 LLM,成為科技界矚目焦點(diǎn)。

從某種意義上來講,LLM 代表了人工智能理解、解釋和生成人類語言能力的重大飛躍,經(jīng)過海量文本數(shù)據(jù)的訓(xùn)練,能夠掌握復(fù)雜的語言模式和語義細(xì)微差別。憑借前所未有的語言處理能力,LLM 可以幫助用戶以卓越的準(zhǔn)確性和效率生成高質(zhì)量內(nèi)容。
而 LangChain 作為一個(gè)圍繞 LLM 構(gòu)建的框架,為自然語言處理方面開辟了一個(gè)充滿可能性的新世界,可以創(chuàng)建各種應(yīng)用程序,并能夠有效解決文本生成、情感分析以及語言翻譯等難題,極大地釋放了 LLM 的潛力。
一、什么是 LangChain ?
作為一款開源的 Python 框架,LangChain 旨在促進(jìn)基于 LLM 的應(yīng)用程序開發(fā)。基于所提供了一套工具、組件和接口等套件,LangChain 簡化了以 LLM 為核心的應(yīng)用程序的構(gòu)建過程。通過 LangChain,開發(fā)人員能夠輕松管理與語言模型的交互,無縫連接不同的組件,并集成 API 和數(shù)據(jù)庫等資源。
此外,借助 LangChain 技術(shù),我們能夠構(gòu)建出一系列應(yīng)用程序,這些應(yīng)用程序能夠生成創(chuàng)新性且與上下文相關(guān)的內(nèi)容。無論是撰寫博客文章、產(chǎn)品描述,與聊天機(jī)器人對話,還是生成問答(GQA)和摘要等,利用 LLM 的應(yīng)用程序開發(fā)變得更加簡便高效。

圖:LangChain Github Star 歷史(由 star-history.com 生成)
從另一角度而言,這種基于 LangChain 的技術(shù)應(yīng)用使得開發(fā)人員可以利用 LangChain 提供的強(qiáng)大語言模型能力,快速開發(fā)出符合用戶需求的應(yīng)用,從而提升用戶體驗(yàn)并節(jié)約開發(fā)時(shí)間和成本。
二、LLM 的局限性與 LangChain 的解決方案
在實(shí)際的場景中,LLM 擅長在常規(guī)上下文下對提示做出響應(yīng),但在未接受過訓(xùn)練的特定領(lǐng)域卻會(huì)遇到挑戰(zhàn)。Prompts 則是人們用來引導(dǎo) LLM 生成回復(fù)的查詢。為了讓 LLM 在特定領(lǐng)域發(fā)揮更佳效果,機(jī)器學(xué)習(xí)工程師需要將其與組織內(nèi)部數(shù)據(jù)來源整合,并應(yīng)用提示工程技術(shù)。
LangChain 的出現(xiàn)簡化了開發(fā)數(shù)據(jù)響應(yīng)式應(yīng)用程序的中間步驟,并提高了 Prompt Engineering 的效率。同時(shí),提供了一套易用、直觀的工具和界面,使開發(fā)人員能夠輕松地將 LLM 與數(shù)據(jù)源和提示工程技術(shù)進(jìn)行整合。

作為一項(xiàng)重要技術(shù),那么,LangChain 具備哪些核心的優(yōu)勢呢?
1.重新發(fā)揮語言模型的作用
借助 LangChain,組織可以將 LLM 的能力重新用于特定領(lǐng)域的應(yīng)用程序,而無需重新培訓(xùn)或微調(diào)。開發(fā)團(tuán)隊(duì)可以構(gòu)建引用專有信息的復(fù)雜應(yīng)用程序,從而增強(qiáng)模型的響應(yīng)能力。舉例來說,我們可以利用 LangChain 構(gòu)建應(yīng)用程序,從存儲(chǔ)的內(nèi)部文檔中檢索數(shù)據(jù),并將其整合為對話響應(yīng)。我們還可以創(chuàng)建 RAG (檢索增強(qiáng)生成) 工作流程,在提示期間向語言模型引入新信息。通過實(shí)施 RAG 和其他上下文感知工作流程,可以減少模型產(chǎn)生的幻覺,提高響應(yīng)的準(zhǔn)確性。
2.簡化人工智能開發(fā)
LangChain 通過簡化數(shù)據(jù)源集成的復(fù)雜性并快速提煉,簡化了 AI 開發(fā)過程。開發(fā)人員可以自定義序列,快速構(gòu)建復(fù)雜的應(yīng)用程序。軟件團(tuán)隊(duì)可以修改 LangChain 提供的模板和庫,以減少開發(fā)時(shí)間,而不必從頭編寫業(yè)務(wù)邏輯。
3.開發(fā)者支持
LangChain 為 AI 開發(fā)者提供了連接語言模型和外部數(shù)據(jù)源的工具。畢竟,它是開源的,并得到活躍社區(qū)的支持。組織可以免費(fèi)使用 LangChain,并獲得其他熟悉該框架的開發(fā)人員的支持。
三、LangChain 的核心組件解析
LangChain 的獨(dú)特之處之一便是其靈活性和模塊化。通過將自然語言處理管道分解為單獨(dú)的組件,開發(fā)人員可以輕松混合和匹配這些構(gòu)建塊,以創(chuàng)建滿足其特定需求的自定義工作流程,從而使得 LangChain 成為一個(gè)高度適應(yīng)性的框架,可用于為廣泛的用例和行業(yè)構(gòu)建對話式人工智能應(yīng)用程序。
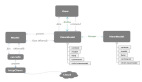
LangChain 是提供了一組模塊,能夠構(gòu)建完整的 LLM(Language Model)應(yīng)用程序管道,并與各種數(shù)據(jù)加載器、向量存儲(chǔ)和 LLM 提供程序等進(jìn)行廣泛的集成。LangChain的主要核心組件可參考如下圖所示:

LangChain 關(guān)鍵組件
1.Model I/O
LangChain 的核心是強(qiáng)大的語言模型(LLM),使應(yīng)用程序能夠理解和生成類似人類的文本。通過 LangChain,開發(fā)人員能夠出色地完成各種與語言相關(guān)的任務(wù)。無論是理解用戶查詢、生成響應(yīng),還是執(zhí)行復(fù)雜的語言任務(wù),LangChain 的模型都是語言處理能力的支柱。
Models 模塊負(fù)責(zé)管理與語言模型的交互。LangChain 支持一系列 LLM,包括 GPT-3、OpenAI 等。開發(fā)者可以使用 Models 模塊來管理 LLM 的配置,例如設(shè)置溫度、top-p 等參數(shù)。模型模塊對于提高 LLM 的能力并使開發(fā)人員能夠構(gòu)建可生成創(chuàng)意和上下文相關(guān)內(nèi)容的應(yīng)用程序至關(guān)重要。
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-davinci-003")
# The LLM takes a prompt as an input and outputs a completion
prompt = "When can I achieve financial freedom?"
completion = llm(prompt)2.Chains
Chains 模塊在應(yīng)用程序中負(fù)責(zé)鏈接不同的組件,開發(fā)人員可以利用 Chains 模塊創(chuàng)建鏈?zhǔn)浇Y(jié)構(gòu),將提示、模型和其他應(yīng)用程序組件有機(jī)地連接在一起。這種鏈?zhǔn)浇Y(jié)構(gòu)對于構(gòu)建需要多個(gè)組件協(xié)同工作的復(fù)雜應(yīng)用程序至關(guān)重要。
通過 Chains 模塊,開發(fā)人員可以靈活組合和配置不同的組件,形成一個(gè)完整的應(yīng)用程序管道,實(shí)現(xiàn)高度定制化的功能和邏輯。
chain = LLMChain(llm = llm,
prompt = prompt)
chain.run("ai")3.Agents
Agents 模塊在應(yīng)用程序中承擔(dān)了管理應(yīng)用程序與外界之間交互的重要角色。通過使用 Agents 模塊,開發(fā)人員可以構(gòu)建各種類型的應(yīng)用程序,如個(gè)人助理、智能聊天機(jī)器人等。這些應(yīng)用程序可以基于語音或文本輸入進(jìn)行交互,并通過分析和理解輸入數(shù)據(jù)來提供相應(yīng)的響應(yīng)和服務(wù)。
Agents 模塊為開發(fā)人員提供了一個(gè)靈活、可擴(kuò)展的工具,使他們能夠輕松構(gòu)建具有交互功能的應(yīng)用程序,為用戶提供個(gè)性化、智能化的體驗(yàn)。
class Agent:
def __init__(self, config):
self.config = config
self.chain = Chain(config)
self.proxy = Proxy(config)
self.memory = Memory(config)
self.callback = Callback(config)
def parse_input(self, input):
# 解析用戶的輸入和上下文信息
...4.Memory
LangChain 的 Memory 模塊承擔(dān)了數(shù)據(jù)存儲(chǔ)的管理任務(wù)。通過使用 Memory 模塊,開發(fā)人員可以輕松地存儲(chǔ)和檢索各種類型的數(shù)據(jù),如文本、圖像、音頻等。
Memory 模塊提供了高度可擴(kuò)展的存儲(chǔ)機(jī)制,可以適應(yīng)不同規(guī)模和類型的數(shù)據(jù)存儲(chǔ)需求。開發(fā)人員可以根據(jù)應(yīng)用程序的需要,靈活地組織和管理存儲(chǔ)的數(shù)據(jù),以滿足應(yīng)用程序的要求。
conversation = ConversationChain(llm=llm, verbose=True)
conversation.predict(input="I am the last one.")
conversation.predict(input="he is first.")
conversation.predict(input="She is third from the bottom")
5.Retrieval
以 Indexes 組件為例,Indexs 模塊在應(yīng)用程序中承擔(dān)了數(shù)據(jù)索引的管理任務(wù)。開發(fā)人員可以利用 Indexs 模塊創(chuàng)建用于搜索和檢索數(shù)據(jù)的索引結(jié)構(gòu)。Indexs 模塊對于構(gòu)建需要進(jìn)行數(shù)據(jù)搜索和檢索的應(yīng)用程序至關(guān)重要。
使用 Indexs 模塊,開發(fā)人員可以根據(jù)應(yīng)用程序的需求創(chuàng)建不同類型的索引,如文本索引、關(guān)鍵詞索引等。這些索引結(jié)構(gòu)可以針對特定的數(shù)據(jù)屬性或特征進(jìn)行優(yōu)化,以實(shí)現(xiàn)更快速和精確的數(shù)據(jù)搜索和檢索。開發(fā)人員可以根據(jù)數(shù)據(jù)的特點(diǎn)和應(yīng)用程序的需求,靈活地配置和管理索引結(jié)構(gòu)。
retriever = db.as_retriever()
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True)
query = "Forgive me for my unruly, indulgent love of freedom in this life?"
result = qa({"query": query})
print(result['result'])6.Calbacks
LangChain 提供了一個(gè)回調(diào)系統(tǒng),使的我們能夠連接到 LLM 請求的不同階段。這個(gè)回調(diào)系統(tǒng)對于日志記錄、監(jiān)控、流傳輸和其他任務(wù)非常有用。
通過使用這些回調(diào)函數(shù),我們可以靈活地控制和管理 LLM 請求的各個(gè)階段。同時(shí),還可以根據(jù)應(yīng)用程序的需求,自定義回調(diào)函數(shù)的行為,以實(shí)現(xiàn)特定的功能和邏輯。
class BaseCallbackHandler:
"""Base callback handler that can be used to handle callbacks from langchain."""
def on_llm_start(
self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any
) -> Any:
"""Run when LLM starts running."""
def on_chat_model_start(
self, serialized: Dict[str, Any], messages: List[List[BaseMessage]], **kwargs: Any
) -> Any:
"""Run when Chat Model starts running."""
def on_llm_new_token(self, token: str, **kwargs: Any) -> Any:
"""Run on new LLM token. Only available when streaming is enabled."""通過對上述關(guān)鍵組件的解析,我們可以大致了解 LangChain 的工作原理和流程,即將 Agents、Memory、Indexs 和回調(diào)系統(tǒng)等關(guān)鍵組件結(jié)合起來,實(shí)現(xiàn)應(yīng)用程序與外界的交互、數(shù)據(jù)的存儲(chǔ)和索引,以及自定義操作的執(zhí)行。
這種組合使得 LangChain 能夠構(gòu)建出強(qiáng)大、靈活的應(yīng)用程序,為用戶提供個(gè)性化、智能化的體驗(yàn)。具體可參考如下工作流:

LLM LangChain 工作流程
四、使用 LangChain 進(jìn)行 LLM 應(yīng)用程序構(gòu)建
在開始之前,我們需要確保正確安裝 LangChain 的軟件包,并按照指南進(jìn)行設(shè)置和配置。這包括安裝所需的編程語言環(huán)境(如Python)、安裝 LangChain 的相關(guān)庫和依賴項(xiàng),并進(jìn)行必要的配置和設(shè)置,以確保 LangChain 可以正常運(yùn)行。
一旦安裝和設(shè)置完成,我們可以開始導(dǎo)入和使用 LLM。為了有效使用 LLM,我們需要導(dǎo)入適當(dāng)?shù)膸旌鸵蕾図?xiàng),以便在應(yīng)用程序中能夠調(diào)用和使用 LLM 的功能。
1.設(shè)置 LangChain
這里,主要為 LangChain 環(huán)境設(shè)置相關(guān)的依賴庫,具體可參考如下:
import langchain
import openai
import os
import IPython
from langchain.llms import OpenAI
from dotenv import load_dotenv
from langchain.chat_models import ChatOpenAI
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
from langchain.embeddings import OpenAIEmbeddings
from langchain.chains import LLMChain
from langchain.chains import RetrievalQA
from langchain import ConversationChain
load_dotenv()
# API configuration
openai.api_key = os.getenv("OPENAI_API_KEY")2.初始化 LLM
要在 LangChain 中初始化 LLM,首先需要導(dǎo)入必要的庫和依賴項(xiàng)。如果大家使用 Python 編程語言,我們可以導(dǎo)入名為 "langchain" 的庫,并指定要使用的語言模型。
以下是一個(gè)示例代碼片段,展示了如何導(dǎo)入 "langchain" 庫和初始化 LLM,具體可參考:
# 導(dǎo)入必要的庫和依賴項(xiàng)
import langchain
# 指定要使用的語言模型
language_model = "gpt3.5-turbo" # 這里使用 GPT-3.5 Turbo 模型作為示例
# 初始化 LLM
llm = langchain.LLM(language_model)
# 接下來,可以使用 llm 對象來調(diào)用和使用 LLM 的各種功能和方法
# 例如,可以使用 llm.generate() 方法生成文本,或使用 llm.complete() 方法進(jìn)行自動(dòng)補(bǔ)全等
# 示例:使用 LLM 生成文本
prompt = "Hello, LangChain!"
response = llm.generate(prompt)
print(response)3.輸入 Prompts
初始化 LLM 后,我們可以通過輸入提示來生成文本或獲取響應(yīng)。Prompts 是語言模型生成文本的起點(diǎn)。根據(jù)需求,我們可以提供單個(gè)或多個(gè) Prompts。以下是一個(gè)簡單的示例:
# 初始化 LLM
llm = langchain.LLM(language_model)
# 提供單個(gè)提示
prompt = "Once upon a time"
response = llm.generate(prompt)
print(response)
# 提供多個(gè)提示
prompts = [
"The sun is shining",
"In a galaxy far, far away",
"Once upon a time"
]
responses = llm.generate(prompts)
for response in responses:
print(response)4.檢索生成的文本或響應(yīng)
輸入 Prompts 后,我們可以從 LLM 中檢索生成的文本或響應(yīng)。生成的文本或響應(yīng)將基于所提供的 Prompts,以及語言模型所具備的上下文理解和語言生成的功能。
當(dāng)我們提供一個(gè)或多個(gè) Prompts 時(shí),LLM 會(huì)使用這些 Prompts 作為起點(diǎn),并借助語言模型的能力來生成相關(guān)的文本。語言模型會(huì)考慮 Prompts 中的上下文信息,以及其在訓(xùn)練數(shù)據(jù)中學(xué)習(xí)到的語言規(guī)律和概率分布。這樣,生成的文本將會(huì)在一定程度上與 Prompts 相關(guān),并且具備一定的語法合理性和連貫性。
# Print the generated text
print(generated_text)
# Print the responses
for response in responses:
print(response)總而言之,通過遵循上述步驟并實(shí)現(xiàn)相應(yīng)的代碼,我們可以無縫地使用 LangChain 和預(yù)訓(xùn)練的 LLM,充分利用它們在文本生成和理解任務(wù)上的能力。這為我們解決各種自然語言處理問題提供了一種高效且靈活的方法。無論是開發(fā)智能對話系統(tǒng)、構(gòu)建文本生成應(yīng)用,還是進(jìn)行文本理解和分析,LangChain 和預(yù)訓(xùn)練的 LLM 都將成為有力的工具和技術(shù)基礎(chǔ)。
綜上所述,在構(gòu)建支持 LLM 的應(yīng)用程序方面,LangChain 為我們開辟了一個(gè)充滿無限可能性的世界。如果大家對文本完成、語言翻譯、情感分析、文本摘要或命名實(shí)體識(shí)別等領(lǐng)域感興趣,LangChain 提供了直觀易用的平臺(tái)和強(qiáng)大的 API,讓我們的想法轉(zhuǎn)化為現(xiàn)實(shí)。
借助 LangChain 和 LLM 的強(qiáng)大能力,我們可以創(chuàng)建出具備理解和生成類人文本能力的智能應(yīng)用程序,從而徹底改變我們與語言交互的方式。
Reference :
- [1] https://python.langchain.com/
- [2] https://machinehack.com/story/langchain-to-build-llm-powered-applications