騰訊歐拉平臺數據血緣架構及應用

一、背景和目標

騰訊歐拉數據平臺,是一款基于 DataOps 理念,實現(xiàn)生產即治理的一站式數據平臺,主要包括三個子產品:
- 首先是資產工廠,負責整體的數倉建設、數倉模型的開發(fā)。
- 第二塊是歐拉的治理引擎,負責全鏈路成本的數據治理。
- 第三塊是數據發(fā)現(xiàn),負責元數據的管理。
數據血緣是歐拉的一個子模塊,直接服務于以上三個子產品,也是本次分享的主題。

為什么要做數據血緣?主要有兩個原因,一個是現(xiàn)狀不能滿足血緣數據需求,另一個是希望以血緣為基礎做更多的事情。
之前公司內部另外一個 BG 負責引擎的開發(fā),我們只能拿到 yarn 日志和 hook 的相關信息,所以只能拿到離線數倉內部表級別的數據血緣,拿不到埋點日志下發(fā)到管道再接入離線數倉這種鏈路血緣,因此整體覆蓋度不夠。另外,血緣的粒度不夠細,我們之前拿到的是表級別的血緣,但需要字段級的血緣。同時,接口服務功能較少,有一些限流的限制。還有一個比較重要的問題是缺少血緣圖譜挖掘計算模型,包括算法庫。
我們還希望能夠以血緣為基礎做更多的事情,包括全鏈路的數據治理、指標的全鏈路觀測、血緣的成本洞察,以及基于血緣的一些數倉開發(fā)。這些問題和需求共同催生了歐拉數據血緣的建設。

血緣的建設包括兩個方面,首先是提升數據血緣的廣度,涵蓋從數據生產、數據加工,到數據應用的全鏈路。包括數據生產環(huán)節(jié)的騰訊燈塔、大同,數據加工環(huán)節(jié)的歐拉平臺,以及數據應用環(huán)節(jié)的 DataTalk 報表、TAB 的 ABtest 等等,已覆蓋 20+ 產品,形成了非常完整的全鏈路資源。
另一方面,提升數據血緣的深度,做更精細化的血緣建設。除了任務血緣之外,還有表血緣、字段血緣,目前字段血緣是最深的層級,而我們在研發(fā)一種更深層級的血緣,稱為數值血緣。
任務血緣的主要工作是打通各平臺產品間的任務級別抽象,實現(xiàn)全鏈路、跨平臺的完整的任務血緣關系圖譜,覆蓋了騰訊內部多種離線和實時數據產品。
表血緣是要打造全鏈路血緣數據圖譜,包括各種表級別的抽象,比如離線 Hive 表、MySQL 關系庫的表,還有 OLAP、Impala 等等,消息隊列也被定義為表級別的抽象。
在表血緣的基礎上,我們會把血緣粒度拓展至字段級別。目前已經完成了離線數倉內部 SQL 任務的字段血緣建設。如果不考慮非 SQL 的任務(jar 包任務或 Spark 任務),字段級血緣會產生斷層,我們的策略是以表血緣為基礎,上下游進行全量依賴。假設下游表的每個字段都依賴于上游表的全部字段,可以把整個字段血緣串起來,避免中間產生斷層。
數值血緣是我們內部開發(fā)的更深層次的血緣。基于 SQL 解析后的 AST,分成實體池、邏輯池和模型池,以這三個池為基礎,放在圖庫里,就可以形成一張非常大的AST 粒度的血緣圖譜。覆蓋的產品主要包括 calcite 、NTLR 等。數值血緣可以幫助我們識別出加工某個指標所需的全部前置數據集合,這是目前我們在進行的最深粒度的血緣建設。
數據血緣有著非常多的應用場景,包括歐拉血緣查詢服務,還有很多基線項目、成本分攤項目以及各種數據治理項。覆蓋的業(yè)務包括整體 PCG 的 ToC 業(yè)務,比如 QQ、騰訊視頻、騰訊新聞、騰訊看點、微視、應用寶等。
二、項目架構
接下來介紹歐拉數據血緣項目架構。

我們首先進行了選型工作。
第一個考察的產品是 Apache 的 Atlas,這也是目前使用率最廣的數據血緣開源產品,但在實際應用中存在著一些問題,比如 Atlas 只有表級血緣,字段血緣不完善,且對大數據引擎的依賴比較強,關系擴展也比較麻煩,需要比較多的二次開發(fā)。
另一些產品,如 OpenMetadata、Datahub,它們對血緣的支持相對比較弱,更側重于元數據管理和數據發(fā)現(xiàn)的服務。Metacat、Amundsen 基本上只有數據發(fā)現(xiàn)功能。
基于以上原因,我們最終選擇基于騰訊豐富的產品生態(tài)自建血緣架構,如 EasyGraph 圖數據庫和成熟的 ES 產品,還有分布式的基于內存的 NoSQL 服務 Meepo 等等。

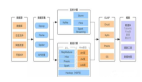
上圖展示了整體的項目架構。最底層 UniMeta,是歐拉內部的元數據管理平臺,包含數據的接入和導出。血緣建設是基于 UniMeta 接過來的一些基礎數據,比如 Yarn 日志,我們從中解析出讀表和寫表。UniMeta 中還包括經常用到的 Hive 的 hook 機制。我們也會通過 UniMeta 同步一些產品配置,比如離線表導出到MySQL、Impala、ClickHouse,基本上都是通過產品配置來進行血緣的解析。還有其它一些產品會發(fā)來內部血緣的消息隊列。極端情況下,比如 jar 包任務,會有一些手工填報的血緣。整體上包括離線、實時和接口三種數據類型。
在 UniMeta 基礎之上,有血緣 ETL 邏輯加工,常規(guī)數倉的建模和加工環(huán)節(jié),包括數據清洗、血緣淘汰、血緣融合等。血緣關系整體上分成兩類,一類是血緣關系,即存在實際數據流轉關系;另一種是我們建立的對應關系,比如表和任務之間或表和字段之間的對應關系。
其中有一部分數據會通過 SQL 解析框架,進行 SQL 層級的血緣解析,最終把解析好的數據輸出到 ETL。SQL 解析框架,底層是我們自研的 SQL 解析引擎,附帶代碼格式化。還有基于 AST 的算法庫,實現(xiàn) AST 級別 SQL 的用戶操作。
在 ETL 基礎之上,有全鏈路的血緣數據質量監(jiān)控,會生成血緣整體的監(jiān)控報表。目前,表級血緣的層級有 40+ 層。這里會催生一些數據治理項,在正常的數倉建模情況下應該不會有這么高的層級,我們會把高層級異常的血緣推送給用戶,進行血緣的壓縮,優(yōu)化整個數據鏈路。另外,還會對表的上下游數量進行監(jiān)控。
在血緣基礎之上,基于 GraphX 構建了圖算法庫,因為整體的 AST 血源是一個樹形結構。我們利用 GraphX 的迭代計算功能,最終形成精細化的血緣建設,包含任務級血緣、表級血緣、字段級血緣、數值血緣,還可以自定義血緣圖譜,這些都會存儲到圖譜數據庫里。
底層的數據結構包含 EasyGraph,就是圖數據庫,ES 用于節(jié)點屬性的模糊檢索,MySQL 用來存儲元數據信息,Redis 提供預計算的功能,GraphX 把血源的全部下游整體計算好之后,數據以 KV 的形式放在 Redis 里,增加血緣查詢的效率以及接口訪問速度。另外還會把血緣在離線倉 TDW 備份。
依托血緣數據,以 REST APIS 的形式對外提供統(tǒng)一的血緣服務,包括數據檢索服務、血緣查詢服務、路徑查詢服務。
通過 UniMeta 的智能網關和權限管理對外賦能,目前更多的是血緣在內部的應用,包括數據治理、成本血緣建設、基線項目、數倉開發(fā)、血緣查詢。
三、模塊化建設
接下來介紹每個子模塊的細節(jié)。

首先是統(tǒng)一的實體 UID 規(guī)范。因為圖譜包含不同類型的節(jié)點,需要設計一套統(tǒng)一的 UID 規(guī)范。包含表、字段、任務、消息隊列、NoSQL(Redis 或者 Hbase),還有 HDFS 的路徑和 API 接口,都會納入到全鏈路的血緣數據圖譜里。目前已經接入 40 多個實體類型。
這里設計了一套 UID 的生成規(guī)則,參考了 URL 的設計理念,其中 product 對應的是 scheme,因為騰訊內部通過規(guī)劃產品和運營產品來唯一定義一個項目,所以使用 product 對 UID 進行唯一確定。在產品之下會有各種各樣的類型,type 字段對應 URL 的 host:port,再通過屬性來唯一定義一個實體類型。在 ID 的基礎之上,基于 MD5 的 hash 算法生成唯一的 UID,再通過 UID 存儲到圖庫里。
我們還做了點邊解耦的操作,通過對點、邊進行分別的維護,點的維護人和邊的維護人可以不一樣,這可以保證底層點屬性的統(tǒng)一,避免重復接入,還可以提供比較好的靈活性和擴展性。

下一個介紹的是血緣的邊建設。邊建設采用了化整為零的策略,構建原子關系,例如離線數倉內部表和表之間就是原子關系,表導出到 MySQL 或 ClickHouse 也是一種原子關系。關系分為兩種類型,一種是存在數據流轉的關系,這個關系其實就是普通意義上的血緣關系,比如任務血緣、表血緣、字段血緣。另外一種關系就是對應關系,比如表和任務的對應關系,任務和實例的對應關系。
構建了原子關系之后,就可以對這些原子關系進行自由的組合去生成自定義的血緣圖譜,并提供了圖譜路徑的查詢接口,例如右側自定義血緣的接口,可以通過任務找到其下游任務,再通過下游任務找到對應的表,然后再通過這個表找到對應的下游表,最后找到對應的 HDFS,形成一種路徑查詢。

上圖是整體的 SQL 解析框架,目前大部分的大數據引擎 SQL 解析都是基于 Calcite 和 Antlr。有這個信息之后,并不是直接對 SQL 進行解析,而是對 Calcite 和 Antlr 生成的語法樹進行轉換操作,轉換成自研的 AST 語法樹,會提供一個非常方便的轉換模塊,相應的有一些完善的 debug 機制,還有類似 Calcite 的語法擴展功能。
我們 AI 自研的語法結構,相比原生的 Calcite 會有一些優(yōu)勢。在某些特定的場景下,我們會打通和圖庫的融合,在圖庫里存儲數倉所有 SQL 任務,這樣做的好處在于,比如我們有一個 AST 算法庫,從 SQL 中選擇一個字段,把所有相關聯(lián)的邏輯取出來,再組合成線上可以執(zhí)行的 SQL,就會形成 AST 級別的血緣。我們也有基于 AST 對 SQL 的轉換,還有代碼可視化的模塊,比如可以按照 PCG 內部 SQL 的格式化標準,用戶不需要再關注代碼格式,只需要通過公用的工具來進行格式化,特別是在進行 code review 的時候。我們以 UDF 的形式對外提供后端的接口服務,還有 SQL 的可視化服務。

圖算法庫是比較有特色的一個功能,基于 Spark 的 GraphX 來進行圖計算。目前已經落地的場景,包括血緣數據探查,例如上下游的最大深度,還有層級的分布情況以及血緣環(huán)路的檢測,我們會進行相應的檢測,推送給業(yè)務進行數據治理。
此外,還有數據治理的挖掘項,包括常見的冷表冷字段的下線,耗時最長鏈路的優(yōu)化。
第三塊,我們會用 GraphX 做血緣的預計算,如果只從圖庫進行血緣的上下游查詢,有時候它的接口響應速度不是那么理想,我們會用 GraphX 做一個圖計算,然后把數據放在 Redis 里,提升接口的訪問速度。
最后是成本分攤項目,后面會有詳細介紹。

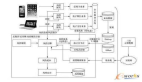
在構建血緣的過程中,會做全鏈路血緣數據質量的監(jiān)控和探查。前文中提到了血緣整體的數據監(jiān)控報表,再來講一下數據一致性的保證,我們采用了 Lambda 架構來構建血緣數據。在此過程中,需要保證兩方面的數據一致性,第一個是離線和實時數據的一致性,因為實時和離線是分別處理的。第二是需要保證圖庫和離線數據的一致性,離線數據在導入圖庫的時候可能會產生數據上的偏差。之所以采用 Lambda 架構是因為目前血緣數據仍然以離線數據為準,實時的血緣不能覆蓋全部的血緣關系。
圖計算和挖掘任務是依賴于離線數據的,右邊的圖是保證一致性的架構。第一步實時任務正常寫入 todo。第二個流程,是來解決離線和實時數據的一致性,在 2.1 的時候,會向實時任務發(fā)送消費暫停的信號,實時任務就會停止寫入圖庫,再用離線數據去更新圖庫里的數據,這樣來保證離線和實時數據的一致性。第三個流程是用來保證圖庫和離線數據的一致性,采用圖庫數據進行一個 dump 操作,dump 之后再和離線數據進行對比,將差異向圖庫同步。在第四步,向實時任務發(fā)送正常消費信號,任務就可以正常進行消費。

通過 REST API 對外提供統(tǒng)一的血緣服務。首先數據檢索是直接基于圖數據存儲的 ES 數據,目前可以進行任務節(jié)點、表節(jié)點、指標的模糊檢索。
實時血緣查詢是基于內部 EasyGraph 圖庫,來進行實時的血緣查詢,包括上下游的多層級血緣查詢、血緣可視化的交互與展示,這邊也會提供預計算的血緣查詢服務,首先使用 GraphX 進行血緣的預計算,比如剛才提到有 4 萬多個下游的節(jié)點,如果圖庫好的話需要幾分鐘,這在產品級別是不能接受的。這種情況下,我們就會使用預計算的數據,響應時間就會壓縮到幾十毫秒。
在統(tǒng)一血緣服務基礎之上,會通過智能網關和權限管理進行對外賦能,另一方面我們用內部應用直接進行調用。
四、應用場景
最后介紹內部的應用場景,整體分為五大類。

- 首先是數據治理,血緣最直接的應用就是應用在數據治理上,包括冷表、冷字段、甚至 HDFS 冷數據的下線,還有空跑任務、空跑邏輯的下線,耗時最長鏈路的優(yōu)化等等。
- 第二是血緣查詢,直接面向用戶進行血緣查詢。
- 第三是數倉開發(fā),支持 SQL 代碼的可視化,邏輯資產管理,低效、無效代碼的檢測,因為是 AST 級別的血緣,所以能夠有效地把低效和無效代碼檢測出來。另外,會基于 AST 的血緣進行微數倉相關的探索。
- 第四是基線項目,對全鏈路任務的失敗或者延遲進行監(jiān)控。
- 最后是全鏈路血緣成本洞察項目,結合血緣和成本核算兩塊內容。
1. 數據治理

數據治理,整體按數據治理的難度分為淺水區(qū)和深水區(qū)。
淺水區(qū)包含表熱度和字段熱度,低熱度或者無熱度的冷表下線、冷字段下線和冷數據下線。再往下一層會有空跑任務的下線和空跑邏輯的下線,如果某個字段判定為冷字段,那么這個字段的所有加工邏輯就會被判斷為空跑邏輯,我們會把這些信息發(fā)給用戶,讓用戶進行 SQL 級別的下線操作。
深水區(qū)包括重復計算的判斷,也是基于 AST 級別的血緣建設,最終我們希望形成表 ROI、字段 ROI還有指標 ROI 的建設,目前還在開發(fā)中。
2. 全鏈路血緣成本洞察

之前的成本核算和分攤不夠精確,我們把中臺或者上游產品的成本向業(yè)務分攤,目前參照的是用量,但是用量難以準確反映出下游實際使用了多少成本。通過把成本和血緣進行結合,能夠把每個上游表的成本向每一個下游節(jié)點進行分攤,整體構成了全鏈路血緣成本的鏈路。
右圖是整體的構建思路,首先第一層有 a、b、c、d、e、f 6 個節(jié)點,每個節(jié)點都有對應的成本,逐層進行分攤,第一層 a 節(jié)點會向它的下游 b 和 c 分別分攤 100 / 2,會產生 50 的成本,低的節(jié)點目前就會有 150 的成本,依次再進行第二層、第三層的分攤,這樣把所有節(jié)點的成本分攤到全部的葉子節(jié)點。不一定所有的葉子節(jié)點都是我們的成本節(jié)點,例如原子指標和派生指標,可能派生指標的表是基于原子指標表來進行開發(fā)的,但是原子指標和派生指標都會作為成本節(jié)點來進行分攤。
3. 全鏈路成本血緣洞察

這里我們碰到一些問題,例如成本節(jié)點如何確定?目前采用的方式是,把所有的葉子節(jié)點判斷為成本節(jié)點,但在實際業(yè)務中會與此不太一致。所以我們也提供了一個方案,讓用戶自己來確定是否是成本節(jié)點,自行進行補充和選擇。
第二個問題就是成本逐層向下分攤時的權重問題,目前我們采用的是向下游平均分攤成本的方式,各個子節(jié)點的權重是 n 分之一,但很多業(yè)務提出這樣做是有問題的,理想的方式是按照下游的實際使用量,包含字段維度和記錄數的維度,字段維度就是下游使用了上游表的多少個字段,然后記錄數維度就是下游在它的 where 條件中用這個條件查出來了多少記錄數,目前還在研究與開發(fā)中。
還有環(huán)路問題,稍微有些復雜,我們考慮了幾種方案。首先把環(huán)路進行拆解,從 c 到 a 就不會去分擔成本。第二個方案是是無限循環(huán)的分攤方案,它會讓環(huán)路進行無限循環(huán),最終它會在每一個節(jié)點上分攤到無限循環(huán)之后的成本,其實可以通過無窮級數來事先預計算,不需要無限循環(huán),只需要循環(huán)一次,乘以無窮級數的求和的結果就可以了。不過我們最終采用的是環(huán)路的整體判斷方案,把 a、b、c 作為環(huán)路的整體,然后再向 d 進行分攤。
第四個是圖計算的性能問題,我們用 GraphX 進行圖計算,迭代次數過多,會有數據傾斜的問題,我們綜合采用了多種方案來進行性能優(yōu)化。實際應用可以使成本治理,從單點擴展到全部鏈路,成本分攤的邏輯,更加符合數據加工的邏輯。我們可以幫助業(yè)務直接觀察到自身的成本來源,幫助上游產品(數據中臺)向下游分攤自身的成本。另外我們會針對單個節(jié)點,給出對應的成本優(yōu)化建議。最終我們希望以血緣成本為基礎,進行數倉的全局優(yōu)化。
4. 基線項目

最后是基線項目,對整個任務鏈條進行監(jiān)控和保障。具體實現(xiàn)過程為,A、B、C、D 是正常的數據鏈路,比如 D 是保障任務,某一天 B 任務延遲,導致其下游延遲。在基線項目中有一個水位線的概念,與 Flink 處理延遲消息的水位線比較類似,因為 B 的延遲導致了 D 的水位線超過了預警線,在這種情況下,會在整個鏈條上進行預警,這只是單個任務。比如 D 任務可能會有其他的路徑,它的每一條路徑都會推高 D 的水位線,如果超過預警線就會進行監(jiān)控預警。

上圖是基線項目的整體結構,可以實現(xiàn)全鏈路的可追蹤、可預警和可歸因,比較核心的服務,例如完成時間的預測、動態(tài)最長路徑的推送、歷史最長路徑的計算,會以兩種形式推送給用戶,第一種是企業(yè)微信以文本形式來推送,第二種是通過一個平臺,以甘特圖的形式展示出全鏈路整體的延遲或者監(jiān)控情況。
以上就是本次分享的內容,謝謝大家。
五、問答環(huán)節(jié)
Q1:請問從頭開始血緣關系建設的話,是從任務到字段建設好,還是從字段到任務建設好?
A1:我們推薦從任務到字段,表血緣需要和任務血緣進行對齊操作,字段血緣也需要和表血緣進行對齊操作。表血緣的上下游有,它的字段血緣肯定是要有上下游關系的。還有一個情況,目前任務級血緣是最準的,因為任務血緣是用戶進行線上的任務增刪改查的操作,下發(fā)的消息或者 MDB 數據,所以我們還是推薦從任務血緣向表血緣和字段血緣進行向下建設。
Q2:怎么評估血緣的準確性?
A2:我們有一個內部監(jiān)控,這個監(jiān)控只能去監(jiān)控解析的成功率和一些比較固定的形式。我們目前采用的方法還是結合固定監(jiān)控和人工探查。比如字段血緣,其實目前的解析準確率已經很高了,能達到 99% 以上,但是 99% 這個數值,也是通過人工選取一些樣例數據,對比解析的結果和人工判斷的結果,得到的準確率。
Q3:在讀寫數據的時候用的 JDBC 或者自定義的 data source,怎么把這些血緣串聯(lián)起來?現(xiàn)在是否支持?
A3:我們目前能夠收集到的就是任務的配置,但是 JDBC 我們目前還沒有介入到這一塊,因為可能涉及到jar 包任務。剛才提到 jar 包任務,我們會進行上下游表級血緣的全量依賴,并對字段級別進行存量依賴。我們會分兩個概念,表級別的,我們可以通過配置來拿到,字段級別就會使用表級別的血緣進行上下游的存量依賴。
Q4:基線項目的用戶都有哪些角色?
A4:基線項目目前主要面對的是 DE 和 DS,即數據工程師和數據分析師,保證任務和指標能夠正常產出。他們會關注任務今天為什么會延遲,會逐層地往上找,我們通過基線項目及時給他發(fā)一個預警,告訴他鏈條中哪一個節(jié)點出了延遲或者出了問題,方便快速地進行定位。
Q5:支持 Spark dataframe 的字段血緣嗎?
A5:這個屬于 jar 包任務,目前處于全量依賴的階段,根據表血源去把字段血源制成全量依賴,避免字段級別的血緣突然在某一層斷掉。
Q6:主要用的數據結構和算法?
A6:SQL 解析框架用到的數據結構和算法會比較多,因為這個是純自研的 SQL 解析框架,并且它和普通的 SQL 解析框架還不太一樣,它不是直接去寫 SQL 的 Parser,而是基于 Calcite 和 Antlr 解析好的 AST 語法樹,進行轉換操作,轉換到我們自研的語法結構。數據結構主要是遞歸和回溯,另外有比較細節(jié)的算法,處理某個問題節(jié)點會應用到特定的算法。
Q7:歐拉平臺考慮對外開放嗎?還是只對內?如果對外開放依賴組件這么多,會不會有維護和運維的成本?
A7:據我了解,是有對外開放規(guī)劃的,而且目前已經和多方進行了合作。歐拉平臺有一些模塊集成在騰訊云上,有對外售賣。例如治理引擎,對事后的存量數據資產進行問題的掃描、發(fā)現(xiàn)、推進、治理等等。這個模塊目前在騰訊云上是有對外開放的。歐拉在內部的平臺更加完善,功能也更多,有一些跟內部的組件有深度的耦合和依賴。未來我們也會逐步考慮有哪些組件可以抽象出來,對外開放。