萬字梳理:阿里、騰訊等8家中國互聯(lián)網(wǎng)大廠的50款大模型及應(yīng)用,能否全面超越GPT-4?

自美國OpenAI公司推出的ChatGPT風(fēng)靡全球,并引發(fā)新一輪人工智能浪潮,國內(nèi)外科技巨頭爭相布局大模型領(lǐng)域。
此次,鈦媒體AGI梳理了2023年至今,阿里、百度、字節(jié)、騰訊、華為、小紅書、美圖、科大訊飛、三六零8家互聯(lián)網(wǎng)科技公司在 AI 領(lǐng)域的最新技術(shù)成果,共計包含50款A(yù)I大模型及AI應(yīng)用,以幫助讀者快速了解互聯(lián)網(wǎng)大廠在AI領(lǐng)域的最新技術(shù)動向。
阿里巴巴
2024年3月
中國版“Sora”,文生視頻框架——AtomoVideo
產(chǎn)品介紹:AtomoVideo是阿里巴巴推出的一個高保真圖像視頻生成框架,該框架利用高質(zhì)量的數(shù)據(jù)集和訓(xùn)練策略,保持了時間性、運動強度、一致性和穩(wěn)定性,并具有高靈活性,可應(yīng)用于長序列視頻預(yù)測任務(wù)。
因與Open AI此前推出的文生視頻模型Sora功能相似,AtomoVideo也被稱為中國版“Sora"。
產(chǎn)品功能:用戶只需上傳一張照片就能生成對應(yīng)的視頻。據(jù)悉AtomoVideo的核心在于多粒度圖像注入技術(shù),這一技術(shù)使得生成的視頻對于給定的圖像具有更高的保真度,能夠更好地保留原始圖像的細節(jié)和特征,從而使得生成的視頻更加逼真。

另外,AtomoVideo的架構(gòu)也具有很高的靈活性,它可以靈活地擴展到視頻幀預(yù)測任務(wù),通過迭代生成實現(xiàn)長序列預(yù)測,使得AtomoVideo在處理長序列的視頻預(yù)測任務(wù)時,也能夠保持良好的性能。
目前,阿里只發(fā)布了AtomoVideo的論文,代碼,試玩頁面還未公布。
適用人群或場景:視頻創(chuàng)作者、影視拍攝
論文地址:https://arxiv.org/abs/2403.01800
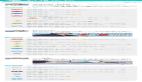
電商人的AIGC創(chuàng)作平臺——繪蛙
產(chǎn)品介紹:繪蛙是阿里AI電商團隊針對淘寶、電商達人推出的一款可以生成文案和圖片的智能創(chuàng)作平臺,旨在提升電商營銷效率。
產(chǎn)品功能:主要是AI文案生成和AI圖片生成。在AI文案中,商家可以實現(xiàn)單商品種草、小紅書爆文改寫、穿搭分享等。以爆文改寫為例,商家只需輸入?yún)⒖脊P記內(nèi)容,然后添加種草商品賣點、人設(shè)、筆記話題,即可生成小紅書風(fēng)格文案。
AI生圖中,用戶可以通過選擇商品、選擇模特和選擇參考圖生成自己想要的商品圖片,支持自己上傳模特圖,也有自帶的數(shù)字模特庫可供使用,可以定制專屬自己的AI模特,幫助商家節(jié)省商品拍攝和模特成本。
適用人群:淘寶、天貓店家、帶貨主播、電商達人
上線時間:未知
體驗地址:https://www.ihuiwa.com/(需邀請碼)
AI 圖片-音頻-視頻模型——EMO
產(chǎn)品介紹:EMO是阿里巴巴推出的AI圖片-音頻-視頻模型,該模型采用了 Stable Diffusion 的生成能力和 Audio2Video 擴散模型,能夠生成富有表現(xiàn)力的人像視頻。
不同于 OpenAI 的文生視頻模型 Sora,EMO 主攻的是直接以圖+音頻生成視頻方向,能夠直接從給定的圖像和音頻,剪輯生成一段帶有豐富人物表情的人物頭部視頻。
產(chǎn)品功能:用戶只需要上傳一張照片和一段任意音頻,EMO就可以根據(jù)圖片和音頻生成一段會說話唱歌的AI視頻。視頻中人物具備豐富流暢的面部表情,能做到人物開口說話和唱歌時和和音頻保持一致,最長時間可達1分30秒左右。
比如,你可以上傳一張高啟強的照片+一段羅翔老師的音頻,就能得到一段“高啟強普法”視頻。或者,你可以上傳一張蒙娜麗莎的照片,讓蒙娜麗莎給你唱現(xiàn)代歌曲,唱rap等。

適用人群:有演講需求人群、電商主播、視頻自媒體及講師等
GitHub:https://github.com/HumanAIGC/EMO
論文地址:https://arxiv.org/abs/2402.17485
項目主頁: https://humanaigc.github.io/emote-portrait-alive/
2024年1月
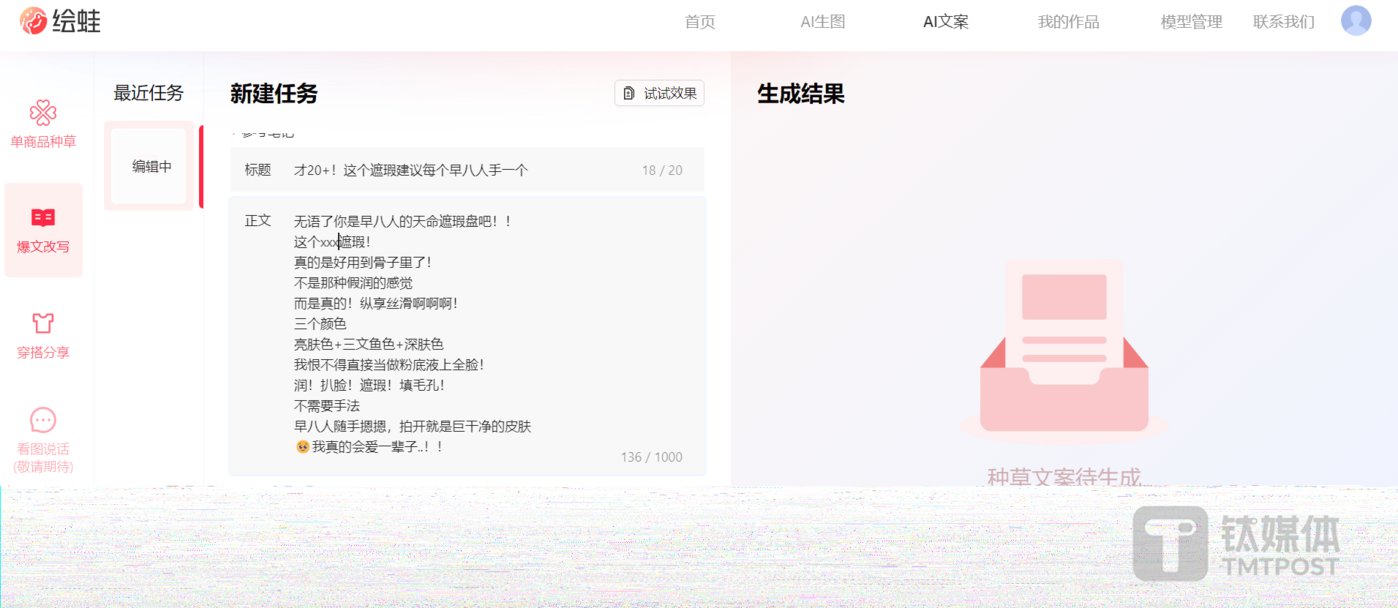
性能堪比Gemini Ultra的多模態(tài)大模型——Qwen-VL-Max
產(chǎn)品介紹:Qwen-VL是阿里推出的開源多模態(tài)視覺模型,2024年1月,繼Plus版本之后,阿里又推出了Qwen-VL-Max版本。
產(chǎn)品功能:基礎(chǔ)能力方面,Qwen-VL-Max能夠準確描述和識別圖片信息,并根據(jù)圖片進行信息推理和擴展創(chuàng)作。這一特性使得該模型在多個權(quán)威測評中表現(xiàn)出色,整體性能堪比GPT-4V和Gemini Ultra。
視覺推理方面,Qwen-VL-Max可以理解并分析復(fù)雜的圖片信息,包括識人、答題、創(chuàng)作和寫代碼等任務(wù)。同時該模型還具備視覺定位功能,可根據(jù)畫面指定區(qū)域進行問答。
此外,Qwen-VL-Max在圖像文本處理方面也取得了顯著進步,中英文文本識別能力顯著提高,支持百萬像素以上的高清分辨率圖和極端寬高比的圖像,不僅能完整復(fù)現(xiàn)密集文本,還能從表格和文檔中提取信息。
體驗地址:https://huggingface.co/spaces/Qwen/Qwen-VL-Max
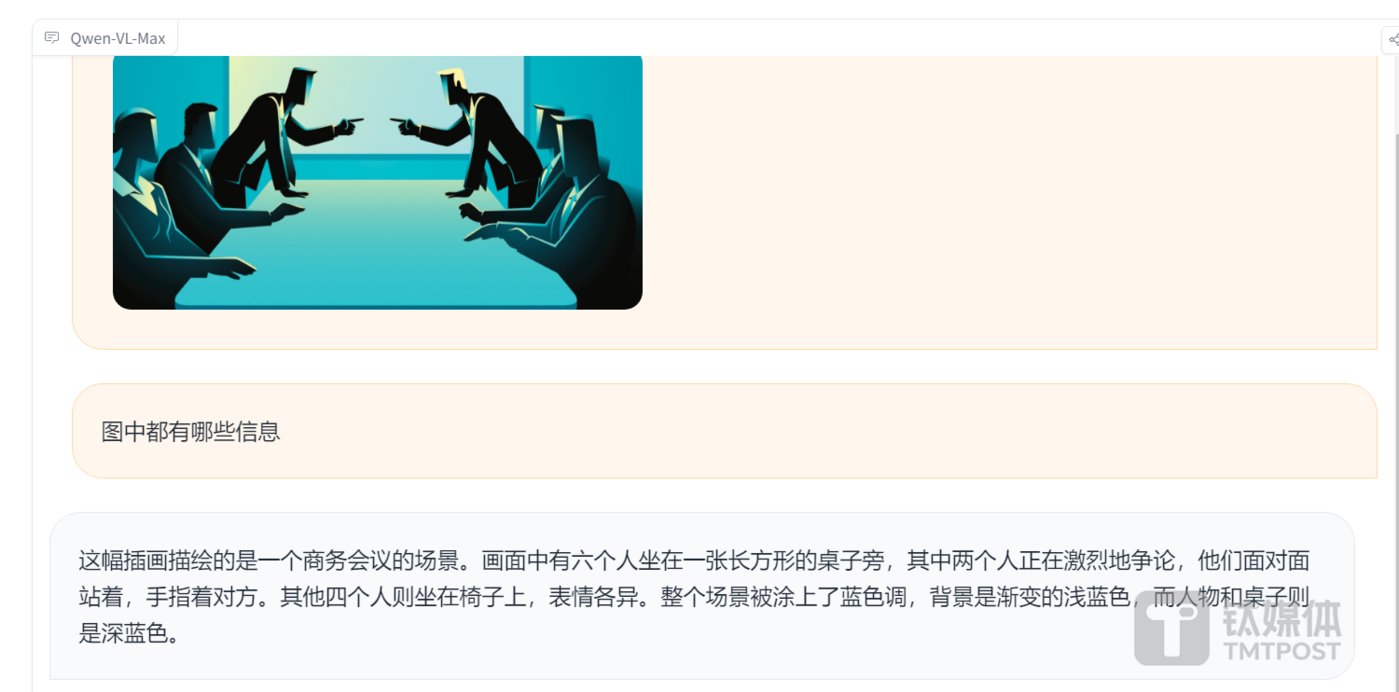
AI 生成3D動畫工具——Motionshop
產(chǎn)品介紹:Motionshop是阿里巴巴智能計算研究院推出的一個AI角色動畫框架,該框架利用視頻處理、角色檢測/分割/追蹤、姿態(tài)分析、模型提取和動畫渲染等多種技術(shù),使得動態(tài)視頻中的主角能夠輕松跨越現(xiàn)實與虛擬的界限,一鍵變身為3D角色模型且不改變視頻中的其他場景和人物。
產(chǎn)品功能:用戶只需上傳視頻,AI便能智能識別視頻中的主要人物,并將其無縫轉(zhuǎn)換為生動的3D角色模型。同時保持視頻中人物動作同步與真實感,能精確復(fù)刻原視頻中人物的動作細節(jié),確保3D角色的動作流暢自然,提供高度逼真的視覺效果。此外,Motionshop能將現(xiàn)實世界的人物與3D虛擬角色得以完美融合,創(chuàng)造出跨越現(xiàn)實與虛擬界限的全新體驗,為視頻內(nèi)容增添無限可能。
適用人群或場景:視頻內(nèi)容生產(chǎn)者、影視拍攝
項目主頁: https://aigc3d.github.io/motionshop/
體驗地址:https://www.modelscope.cn/studios/Damo_XR_Lab/motionshop/summary
能讓圖片開口說話、唱歌的模型框架——DreamTalk
產(chǎn)品介紹:DreamTalk是由清華大學(xué)、阿里巴巴和華中科大共同開發(fā)的一個可以讓人物照片開口說話、唱歌的模型框架。
產(chǎn)品功能:上傳一張照片和音頻,DreamTalk能夠生成人物臉部動作看起來很真實的高質(zhì)量視頻,而且嘴唇動作能和音頻都能一一對應(yīng)。同時DreamTalk還支持多種語言,無論是中文、英文還是其他語言都能很好地同步。

據(jù)悉,DreamTalk 由三個關(guān)鍵組件組成:降噪網(wǎng)絡(luò)、風(fēng)格感知唇部專家和風(fēng)格預(yù)測器。通過三項技術(shù)結(jié)合的方式,DreamTalk 能夠生成具有多種說話風(fēng)格的逼真說話面孔,并實現(xiàn)準確的嘴唇動作。
適用人群或場景:演講、產(chǎn)品講解、開會,直播、電商、線上授課等
項目主頁: https://dreamtalk-project.github.io/
論文地址: https://arxiv.org/pdf/2312.09767.pdfGithub
地址: https://github.com/ali-vilab/dreamtalk
2023年12月
可控視頻生成框架——DreamMoving
產(chǎn)品介紹:DreaMoving是一種基于擴散模型打造的可控視頻生成框架,通過圖文就能制作高質(zhì)量人類跳舞視頻。
產(chǎn)品功能:用戶只需上傳一張人像,以及一段提示詞,就能生成對應(yīng)的視頻,而且改變提示詞,生成的人物的背景和身上的衣服也會跟著變化。簡單來說就是,一張圖、一句話就能讓任何人或角色在任何場景里跳舞。

適用人群或場景:娛樂主播、視頻制作
論文鏈接:https://arxiv.org/pdf/2311.17117.pdf
項目地址:https://humanaigc.github.io/animate-anyone/
體驗地址:https://huggingface.co/spaces/xunsong/Moore-AnimateAnyone
2023年11月
文生視頻模型——I2VGen-XL
產(chǎn)品介紹:I2VGen-XL是阿里云推出的一款高清圖像生成視頻模型,這款模型的核心組件由兩個部分構(gòu)成,用以解決語義一致性和清晰度問題。
產(chǎn)品功能:用戶只需上傳一張圖片,即可生成一段分辨率為1280*720的高清視頻。由于在大規(guī)模混合視頻和圖像數(shù)據(jù)上進行了預(yù)訓(xùn)練,并在少量高質(zhì)量數(shù)據(jù)集上進行了微調(diào),這些數(shù)據(jù)集具有廣泛的分布和多樣的類別,這使得I2VGen-XL展示了良好的泛化能力,適用于不同類型的數(shù)據(jù)。

此外,為了提高視頻質(zhì)量,該研究訓(xùn)練了一個單獨的 VLDM,專門處理高質(zhì)量、高分辨率數(shù)據(jù),并對第一階段生成的視頻采用 SDEdit 引入的噪聲去噪過程。
視頻生成效果方面,與 Gen2、Pika 生成效果相比, I2VGen-XL 生成的視頻動作更加豐富,主要表現(xiàn)在更真實、更多樣的動作,而 Gen-2 和 Pika 生成的視頻似乎更接近靜態(tài)。
使用人群及場景:視頻內(nèi)容創(chuàng)作者、影視制作
項目地址:https://i2vgen-xl.github.io/
論文地址:https://arxiv.org/abs/2311.04145
Github:https://arxiv.org/abs/2311.04145
開源的圖像到視頻動畫合成框架——AnimateAnyone
產(chǎn)品介紹:Animate Anyone是一款能將靜態(tài)圖像轉(zhuǎn)換為角色視頻的模型框架。該框架在擴散模型的基礎(chǔ)之上,引入了ReferenceNet、Pose Guider姿態(tài)引導(dǎo)器和時序生成模塊等技術(shù),以實現(xiàn)照片動起來時保持一致性、可控性和穩(wěn)定性,輸出高質(zhì)量的動態(tài)化視頻。
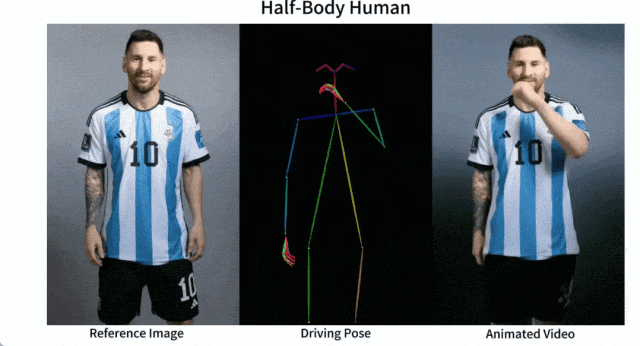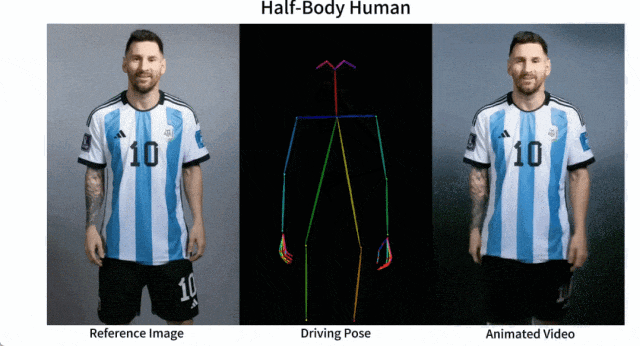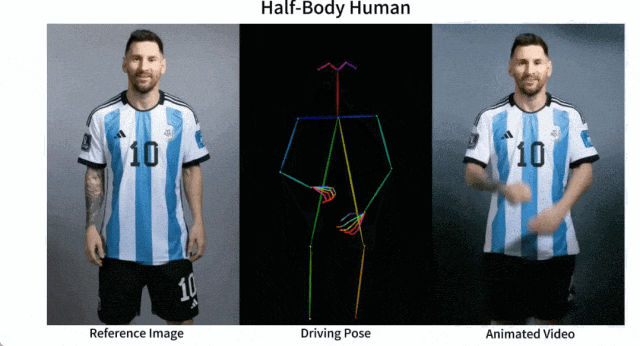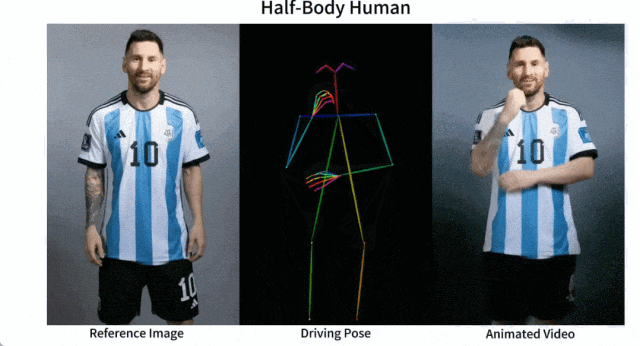
產(chǎn)品功能:角色視頻生成,利用驅(qū)動信號從靜態(tài)圖像生成逼真的角色視頻;擴散模型支持,借助擴散模型的力量,提供高質(zhì)量的動畫效果;ReferenceNet設(shè)計,通過空間注意力合并詳細特征,保持外觀特征的一致性;姿勢指導(dǎo)器,引入高效的姿勢指導(dǎo)器,確保角色動作的可控性和連續(xù)性;平滑過渡:采用有效的時間建模方法,保證視頻幀之間的平滑過渡。
目前,Animate Anyone已在GitHub上斬獲了近1.3萬個星標,并在國內(nèi)外引起了熱烈討論。
適用人群或場景:時尚行業(yè),展示服裝、造型;視頻內(nèi)容創(chuàng)作者、電商、舞者
論文鏈接:https://arxiv.org/pdf/2311.17117.pdf
項目鏈接:https://humanaigc.github.io/animate-anyone/
2023年4-7月
通義系列大模型——通義千問、通義萬相和通義聽悟
產(chǎn)品介紹:通義千問是阿里自研的 AI 大語言模型,可以幫助用戶解決生活和工作中的問題,提供智能問答服務(wù)。2023年10月31日,通義千問2.0正式發(fā)布,阿里也隨之推出通義千問App。相較于1.0版本,通義千問2.0在復(fù)雜指令理解、文學(xué)創(chuàng)作、通用數(shù)學(xué)、知識記憶、幻覺抵御等能力上均有顯著提升。
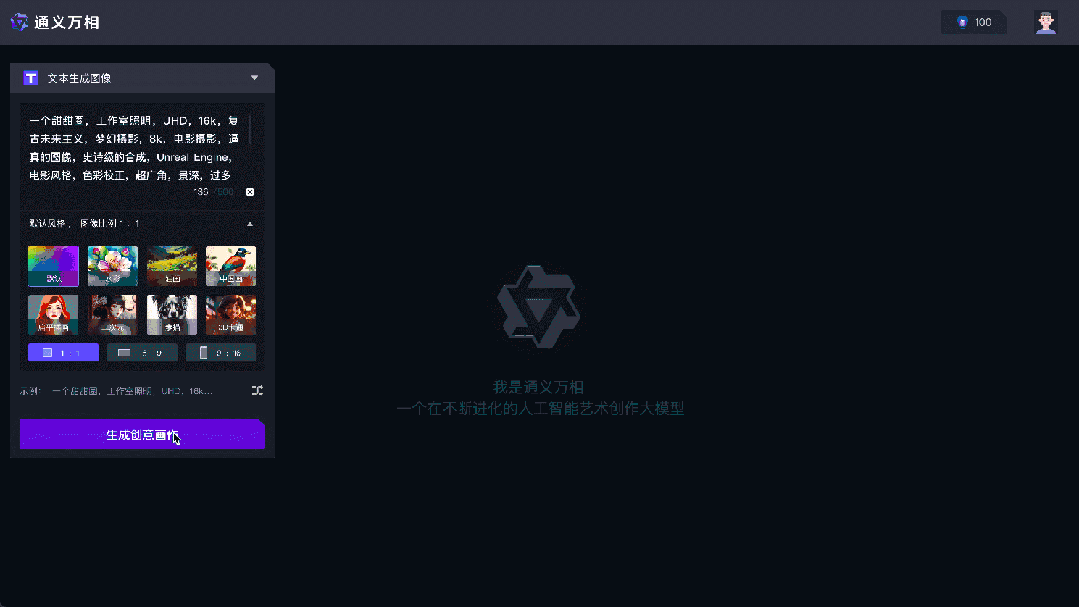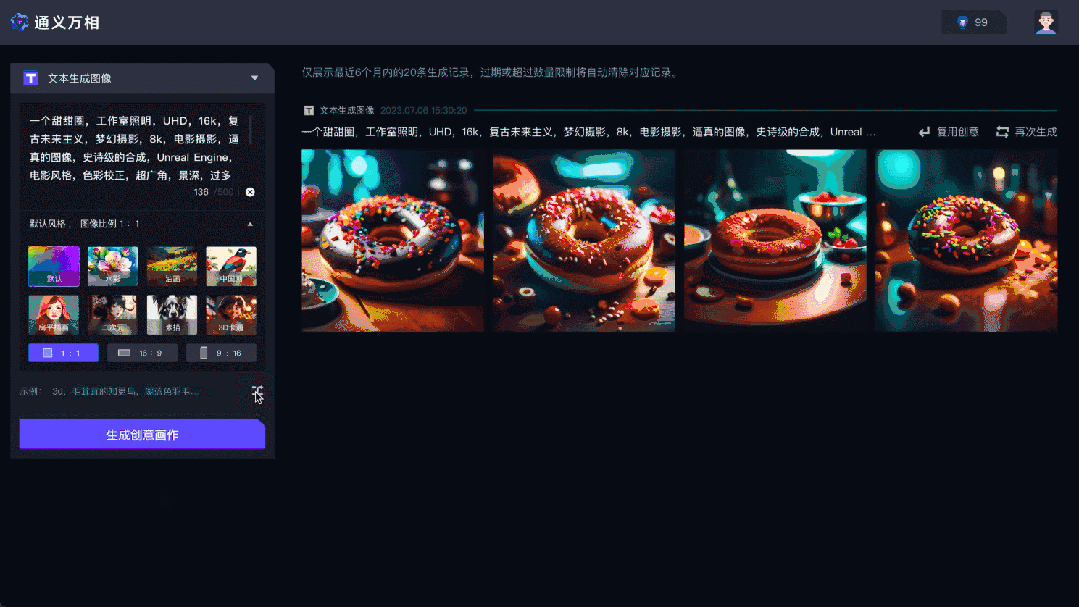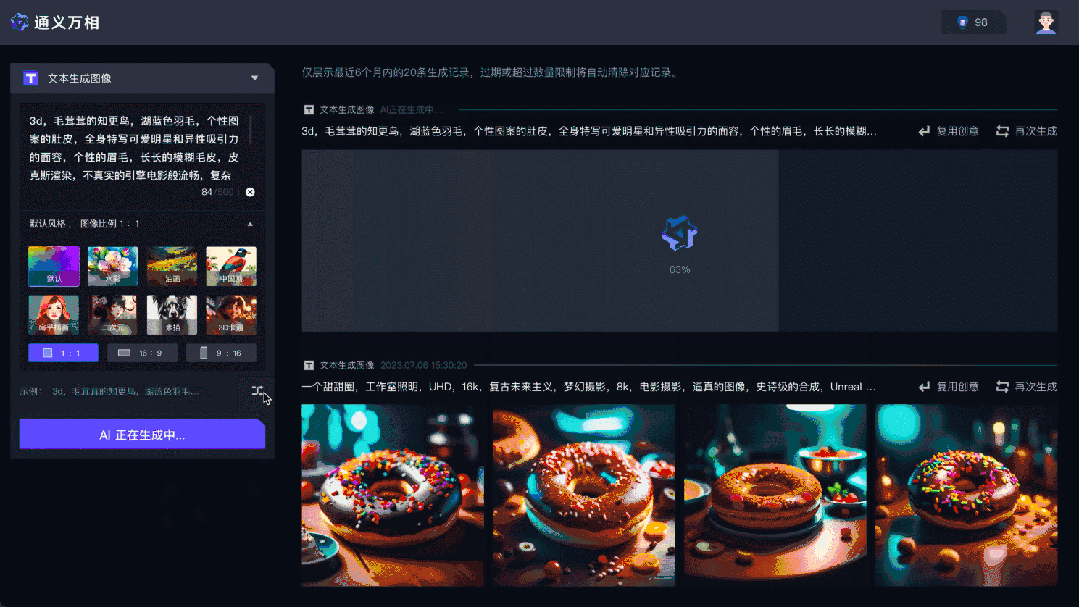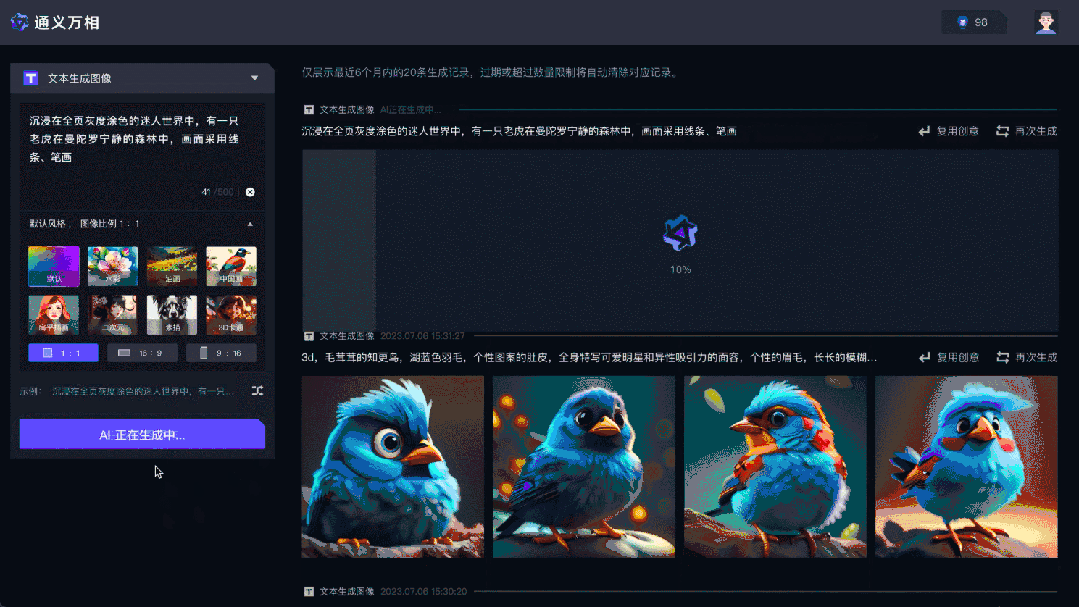
通義萬相是阿里通義大模型家族中的一款A(yù)I繪畫大模型,可輔助人類進行圖片創(chuàng)作。基于阿里研發(fā)的組合式生成模型Composer,通義萬相提出了基于擴散模型的「組合式生成」框架,通過對配色、布局、風(fēng)格等圖像設(shè)計元素進行拆解和組合,提供了高度可控性和極大自由度的圖像生成效果。
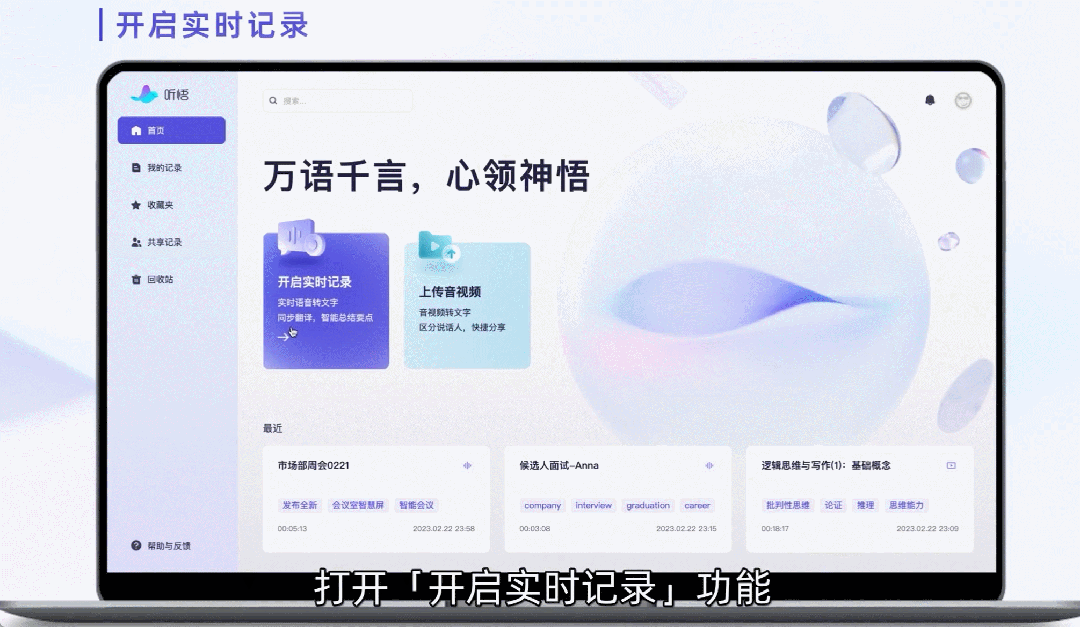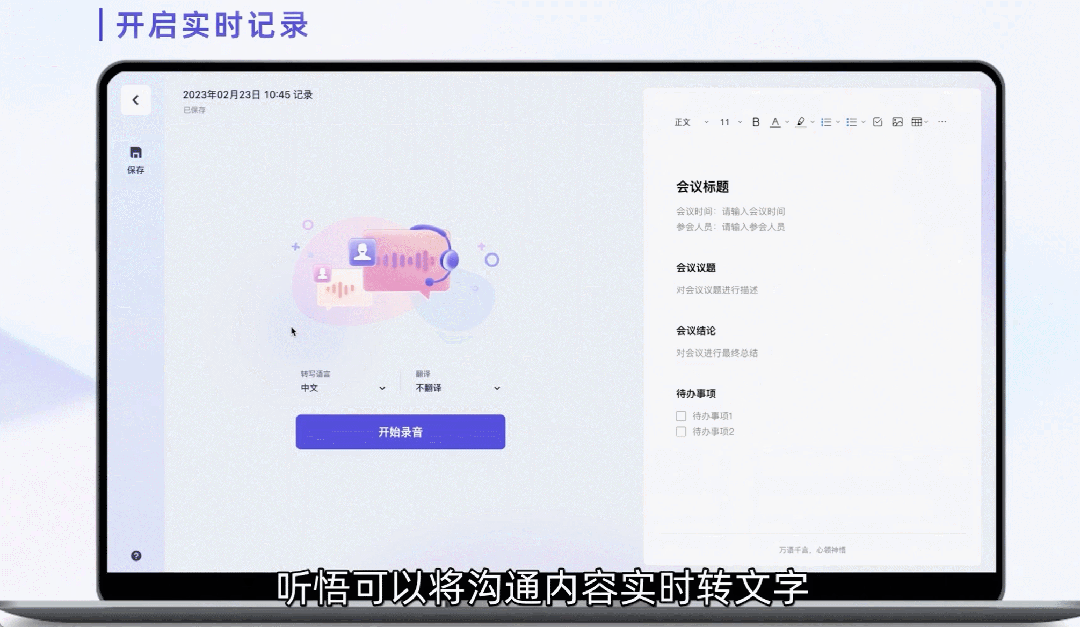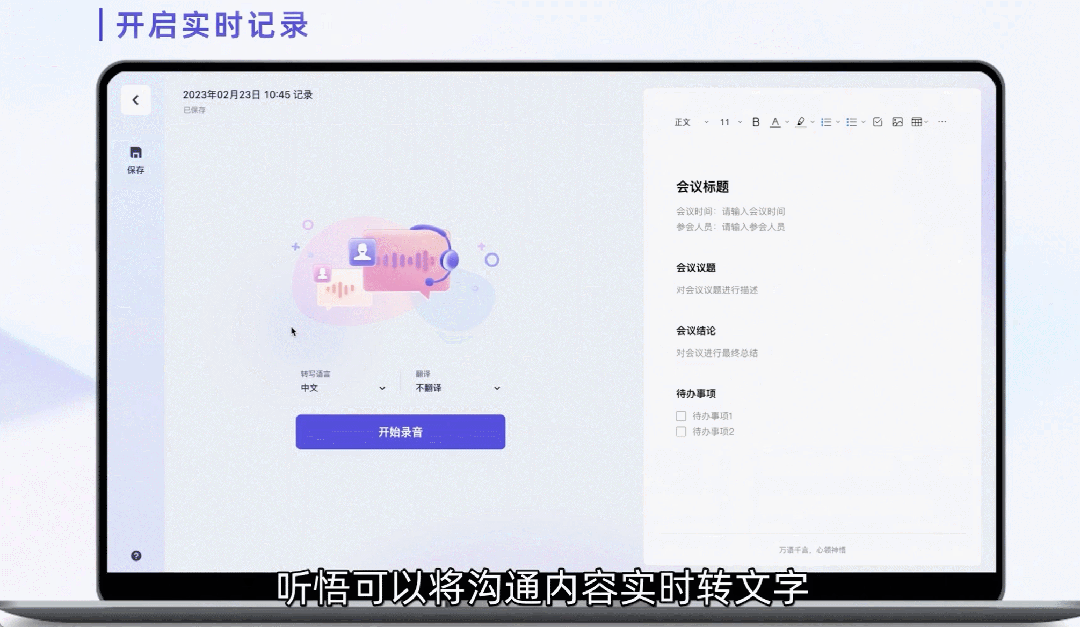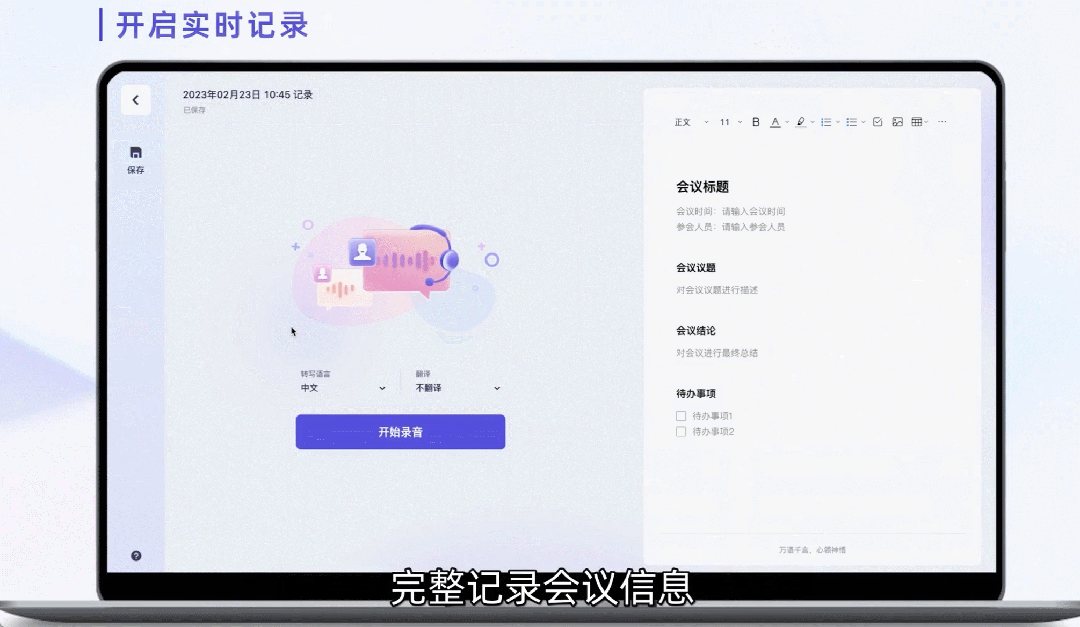
通義聽悟是是依托通義千問大模型和音視頻AI模型的AI助手,旨在幫助用戶及客戶在泛音視頻內(nèi)容場景下提升信息生產(chǎn)、整理、挖掘、洞察效率。
產(chǎn)品功能:通義千問具備多輪對話、文案創(chuàng)作、邏輯推理、多模態(tài)理解及多語言支持等功能。用戶可以就任何問題與其對話互動,比如可以問他生活類常識、講故事、寫作文或文案、解答數(shù)學(xué)題等,但通義千問不具備多模態(tài)能力,不具備圖像生成功能。
通義萬相主要功能有三個,即文生圖、相似圖生成和風(fēng)格遷移。在基礎(chǔ)文生圖功能中,可根據(jù)用戶提示詞生成水彩、扁平插畫、二次元、油畫、3D卡通畫等風(fēng)格圖像;相似圖片生成功能中,用戶上傳任意圖片后,即可進行創(chuàng)意發(fā)散,生成內(nèi)容、風(fēng)格相似的AI畫作。此外該模型還支持圖像風(fēng)格遷移,用戶上傳原圖和風(fēng)格圖,可自動把原圖處理為指定的風(fēng)格圖。
通義聽悟融合融合了十多項 AI 功能,面向線上線下各種泛音視頻場景,通義聽悟可以提供音視頻內(nèi)容的實時字幕 / 轉(zhuǎn)寫、多語言翻譯、內(nèi)容理解 / 摘要,涵蓋全文概要、章節(jié)速覽、發(fā)言總結(jié)等高階 AI 功能。
適用人群或場景:通義千問適用人群較為廣泛,通義萬相適用于藝術(shù)繪畫創(chuàng)作,設(shè)計師、動漫愛好者;通義聽悟可應(yīng)用于智能客服、智能家居、智能音箱、智能穿戴設(shè)備等領(lǐng)域。
通義千問體驗地址:https://tongyi.aliyun.com/qianwen/
通義萬相體驗地址:https://tongyi.aliyun.com/wanxiang/
通義聽悟體驗地址:https://tingwu.aliyun.com/home
百度
2024年1月
統(tǒng)一模態(tài)視頻生成系統(tǒng)——UniVG
產(chǎn)品介紹:UniVG是百度推出的一款統(tǒng)一模態(tài)視頻生成系統(tǒng),其獨特之處在于針對高自由度和低自由度兩種任務(wù)采用不同的生成方式,以更好地平衡兩者之間的關(guān)系。

產(chǎn)品功能:用戶只需提供一張圖片或一段文字,就能生成一段流暢的視頻,與早期的AI視頻生成工具相比,UniVG所生成的每一幀畫面都更加穩(wěn)定、連貫。
據(jù)悉,UniVG系統(tǒng)引入了“多條件交叉注意力”技術(shù),用于高自由度視頻生成,以生成與輸入圖像或文本語義一致的視頻。而在低自由度視頻生成方面,采用了“偏置高斯噪聲”的方法,相較于傳統(tǒng)的完全隨機高斯噪聲更能有效地保留輸入條件的原始內(nèi)容。
適用人群及場景:視頻內(nèi)容創(chuàng)作者
項目地址:https://top.aibase.com/tool/univg
項目演示頁面: https://univg-baidu.github.io/
統(tǒng)一圖像生成框架——UNIMO-G
產(chǎn)品介紹:百度推出的UNIMO-G統(tǒng)一圖像生成框架,通過多模態(tài)條件擴散實現(xiàn)文本到圖像生成,克服了文本描述簡潔性對生成復(fù)雜細節(jié)圖像的挑戰(zhàn)。
產(chǎn)品功能:用戶只要給出一張圖,然后給出各種提示詞,UNIMO-G就能根據(jù)提示詞在圖像基礎(chǔ)上按照提示生成對應(yīng)圖像,比如上傳一張馬斯克圖像,輸入提示詞給他穿上警服,就能得到一張身穿警服的馬斯克圖像。

據(jù)了解,UNIMO-G的核心組件包括多模態(tài)大語言模型和基于編碼的多模態(tài)輸入生成圖像的條件去噪擴散網(wǎng)絡(luò)。這一框架還采用了精心設(shè)計的數(shù)據(jù)處理管道,涉及語言基礎(chǔ)和圖像分割,用以構(gòu)建多模態(tài)提示。
在測試中,UNIMO-G在文本到圖像生成和零樣本主題驅(qū)動合成方面表現(xiàn)卓越,特別是在處理包含多個圖像實體的復(fù)雜多模態(tài)提示時,生成高保真圖像的效果顯著。
適用人群及場景:藝術(shù)創(chuàng)作者、漫畫愛好者、攝影師
項目地址:https://top.aibase.com/tool/unimo-g
論文地址:https://arxiv.org/pdf/2401.13388.pdf
2023年3月
文心大模型系列產(chǎn)品——文心一言、文心一格和文心千帆
產(chǎn)品介紹:文心大模型是百度于2019年推出的自然語言處理大模型。該模型基于ERNIE系列模型具備跨模態(tài)、跨語言的深度語義理解與生成能力。2023年10月,文心大模型4.0 版本發(fā)布,實現(xiàn)基礎(chǔ)模型的全面升級,理解、生成、邏輯、記憶四大能力顯著提升,綜合能力可直接對標GPT-4。
文心一言是百度基于文心大模型打造的生成式AI產(chǎn)品,與阿里的”通義千問”類似,可以進行任何內(nèi)容的問答對話,可作為生活中的智能小助手。
文心一格是百度基于文心大模型推出的AI藝術(shù)創(chuàng)作平臺,可以生成多樣化AI創(chuàng)意圖片,輔助創(chuàng)意設(shè)計。
文心千帆是百度旗下企業(yè)級大模型生產(chǎn)平臺,提供包括文心一言在內(nèi)的大模型服務(wù)及第三方大模型服務(wù),還提供大模型開發(fā)和應(yīng)用的整套工具鏈。
產(chǎn)品功能:文心一言具有文學(xué)創(chuàng)作、商業(yè)文案創(chuàng)作、數(shù)理邏輯推算、中文理解、音頻、圖像生成等多模態(tài)生成能力。比如用戶可以用文心一言解答任何生活及工作問題,幫助用戶撰寫任何領(lǐng)域的文案,解答數(shù)學(xué)邏輯題,用語音講故事等。
文心一格的主要功能就是圖像生成功能。用戶只需要輸入一句話或提示詞,文心一格就能按照指示自動生成圖像,且用戶可以追加更詳細的提示詞對圖像進一步優(yōu)化或改變圖像風(fēng)格等。同時文心一格還具有二次編輯圖片和圖片疊加功能,比如可以涂抹掉圖像中不滿意的部分,讓模型重新調(diào)整生成。或者給出兩張圖片,模型會自動生成一張疊加后的創(chuàng)意圖。此外,文心一格還推出了海報創(chuàng)作、圖片擴展和提升圖片清晰度等功能,提供多種生圖服務(wù)滿足用戶需求。
文心千帆主要功能有兩個:其一是文心千帆以文心一言為核心,為企業(yè)提供大模型服務(wù),幫助客戶改造產(chǎn)品和生產(chǎn)流程。其二,作為一個大模型生產(chǎn)平臺,企業(yè)可以在文心千帆上基于任何開源或閉源的大模型,開發(fā)自己的專屬大模型。

適用人群及場景:文心一言受眾群體廣泛,文心一格適合有繪畫創(chuàng)作和圖像設(shè)計需求群體。文心千帆主要面向企業(yè)級B端客戶。
體驗地址:
文心一格:https://yige.baidu.com/creation
文心千帆:https://cloud.baidu.com/product/wenxinworkshop
字節(jié)跳動
2024年2月
字節(jié)版DALL·E文生圖模型——SDXL-Lightning
產(chǎn)品介紹:SDXL-Lightning是一款由字節(jié)跳動開發(fā)的開源免費的文生圖模型,能根據(jù)文本快速生成相應(yīng)的高分辨率圖像。
產(chǎn)品功能:用戶在SDXL-Lightning上輸入提示詞,然后選擇推理步驟(選擇范圍為1步—8步),等待數(shù)秒即可生成一張高清圖像。
與以往的文生圖模型相比,SDXL-Lightning的生成速度有顯著提高,能夠在最少步驟內(nèi)完成文本到1024px分辨率圖像的生成,適用于需要快速響應(yīng)的應(yīng)用場景。

SDXL-Lightning的生成速度之所以能夠顯著提升,主要是因為它通過結(jié)合漸進式蒸餾和對抗式蒸餾的方法,解決了擴散模型在生成過程中存在的速度慢和計算成本高的問題,同時保持生成圖像的高質(zhì)量和多樣性,避免了傳統(tǒng)蒸餾方法中存在的圖像模糊問題。
使用SDXL-Lightning模型,可在幾秒鐘之內(nèi)生成高達1024像素分辨率的圖像。目前,該模型已經(jīng)在Hugging Face平臺上開源,并且下載量超過2200次,登上了Hugging Face流行趨勢第三名,超越了gemma-2b,僅次于最新的谷歌gemma-7b,以及stabilityai/stable-cascade。
適用人群或場景:視頻內(nèi)容創(chuàng)作者、影視制作
體驗地址:https://huggingface.co/spaces/AP123/SDXL-Lightning
文生視頻模型——Boximator
產(chǎn)品介紹:Boximator是字節(jié)跳動推出的一款文生視頻模型。與Gen-2、Pink1.0等模型不同的是,Boximator可以通過文本精準控制生成視頻中人物或物體的動作。
產(chǎn)品功能:與Open AI發(fā)布的文生視頻模型類似,Boximator也是通過用戶給出文字描述或提示,就能按照指示生成對應(yīng)的視頻。據(jù)了解,為了實現(xiàn)對視頻中物體、人物的動作控制,Boximator使用了“軟框”和“硬框”兩種約束方法。

硬框可精確定義目標對象的邊界框。用戶可以在圖片中畫出感興趣的對象,Boximator會將其視為硬框約束,在之后的幀中精準定位該對象的位置。
軟框定義一個對象可能存在的區(qū)域,形成一個寬松的邊界框。對象需要停留在這個區(qū)域內(nèi),但位置可以有一定變化,實現(xiàn)適度的隨機性。
兩類框都包含目標對象的ID,用于在不同幀中跟蹤同一對象。此外,框還包含坐標、類型等信息的編碼。
不過,據(jù)字節(jié)跳動相關(guān)人士稱,Boximator是視頻生成領(lǐng)域控制對象運動的技術(shù)方法研究項目,目前還無法作為完善的產(chǎn)品落地,距離國外領(lǐng)先的視頻生成模型在畫面質(zhì)量、保真率、視頻時長等方面還有很大差距。
適用人群或場景:短視頻創(chuàng)作者、影視制作
論文地址: https://arxiv.org/abs/2402.01566
項目地址: https://boximator.github.io/
文生圖AIGC工具——Dreamina
產(chǎn)品介紹:Dreamina是字節(jié)跳動旗下的AIGC工具,可以根據(jù)用戶的文字提示生成創(chuàng)意圖片。
產(chǎn)品功能:用戶只需輸入一段文字,Dreamina即可生成四幅由AI生成的創(chuàng)意圖像。同時Dreamina支持多種圖像風(fēng)格,包括抽象、寫實等,以滿足不同用戶的審美需求。此外,Dreamina還具備圖像調(diào)整功能,用戶可以對生成的圖片進行修整,包括調(diào)整圖片的大小比例和選擇不同的模板類型。這種靈活性使得用戶可以根據(jù)個人喜好或特定需求調(diào)整生成的圖像。
適用人群或場景:藝術(shù)創(chuàng)作者、漫畫愛好者
體驗地址:https://dreamina.jianying.com/ai-tool/platform
AI 開發(fā)平臺——Coze扣子
產(chǎn)品介紹:Coze扣子是字節(jié)跳動AI部門Flow開發(fā)的一站式 AI 開發(fā)平臺,無論用戶是否有編程基礎(chǔ),都可以利用Coze在30秒內(nèi)輕松創(chuàng)建專屬自己的“AI機器人”。
產(chǎn)品功能:在注冊、登陸賬號之后,用戶可以通過首頁超過60個的插件能力,以及創(chuàng)建Bot,實現(xiàn)多個能力應(yīng)用。例如,我們希望有一個“新聞搜索助手”,通過簡單的對話在30秒內(nèi)就可以自動生成一個 AI 機器人,不需要任何代碼編程,小白也能輕松上手。
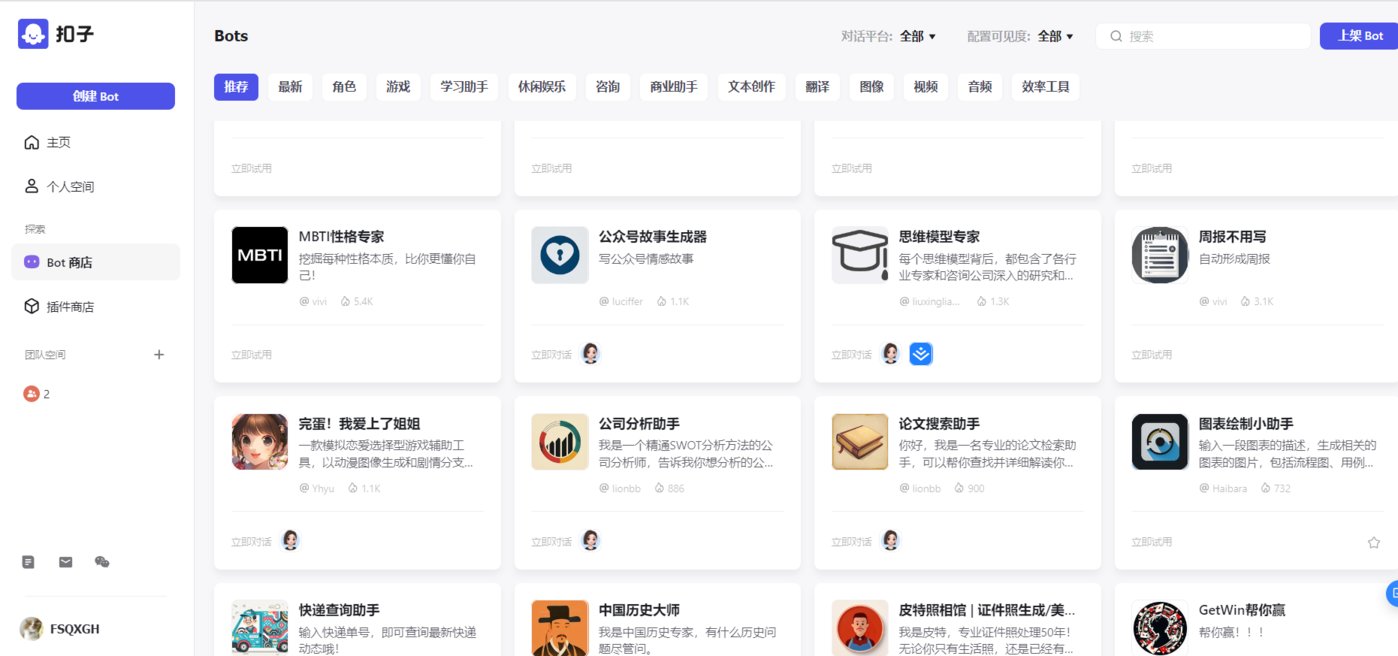
同時,“扣子”平臺也有一些自帶的bot,涵蓋旅游、出行和娛樂等場景,可以直接點擊使用,而且還具備可無限擴展的能力集,全面實現(xiàn)個性化定義 AI 機器人技術(shù)能力。
此外,coze還支持上傳創(chuàng)建自己所需bot的數(shù)據(jù),可以與自己的數(shù)據(jù)進行交互,并且扣子還具備長期的對話記憶能力,通過數(shù)據(jù)交互和持久記憶為用戶提供更加精準的回答。
適用人群或場景:所有用戶都可適用
體驗地址:https://www.coze.cn/store/bot
2024年1月
AI視頻生成模型——MagicVideo-V2
產(chǎn)品介紹:MagicVideo-V2 是字節(jié)推出的AI視頻生成模型,它將文本到圖像模型、視頻運動發(fā)生器、參考圖像嵌入模塊和幀插值模塊集成到端到端視頻生成管道中。這種結(jié)構(gòu)使 MagicVideo-V2 能夠制作高分辨率、美觀的視頻,并具有出色的保真度和流暢度。

產(chǎn)品功能:文本轉(zhuǎn)圖像功能,MagicVideo-V2 擁有先進的文本到圖像模型,可以將文字轉(zhuǎn)換為圖像元素,為生成視頻提供基礎(chǔ)素材;視頻運動生成功能:利用視頻運動生成器,可以自動生成視頻,節(jié)省用戶的時間和精力;參考圖像嵌入功能,MagicVideo-V2 支持參考圖像嵌入功能,在生成視頻時可以參考指定圖像,使視頻內(nèi)容更加準確和多樣化。此外,MagicVideo-V2 的幀插值模塊能夠平滑過渡視頻中的每一幀,使生成的視頻更加流暢和連貫。
適用人群或場景:電影制作、創(chuàng)意廣告視頻、創(chuàng)意短片
論文地址:https://arxiv.org/abs/2401.04468
項目網(wǎng)站:https://magicvideov2.github.io
2023年12月
AI 劇情互動平臺——BagelBell
產(chǎn)品介紹:BagelBell是字節(jié)推出的一款A(yù)I 劇情互動平臺,用戶可以通過 AI 身份圖、故事名稱和故事介紹了解不同的 AI 故事并與自己喜歡的故事互動。
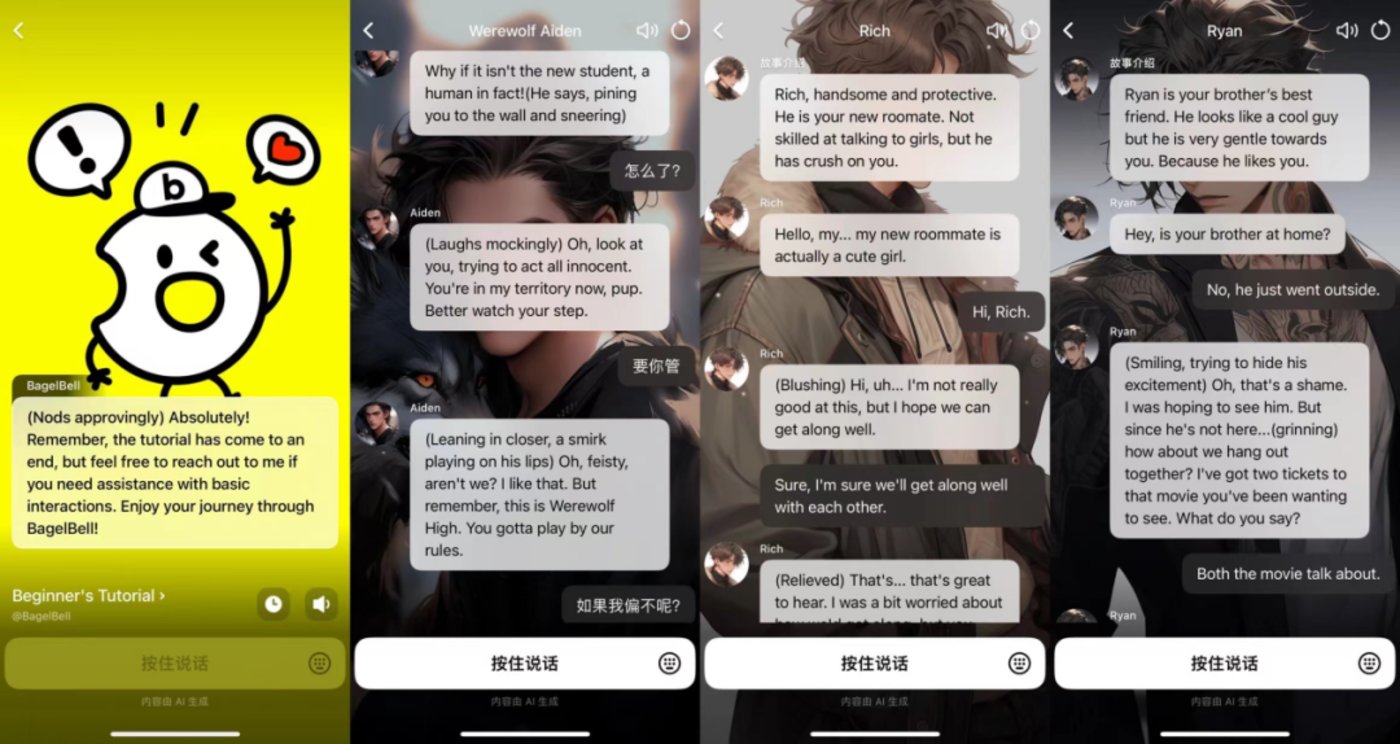
產(chǎn)品功能:BageBel 為用戶提供了一個充滿活力和創(chuàng)造力的虛擬世界,讓用戶可以在這個世界中探索故事、創(chuàng)作角色,并與 AI角色進行互動。這種獨特的體驗不僅可以讓用戶享受到故事帶來的樂趣,還可以激發(fā)用戶的創(chuàng)造力和想象力。目前 BagelBell 故事類型十分豐富,涉及狼人、校園、懸疑、霸總、女仆、年下等多個類別,不過多為戀愛題材。
適用群體或場景:劇本創(chuàng)作、游戲創(chuàng)作
體驗地址:https://www.anybagel.com/
2023年11月
字節(jié)海外版AI智能助手——ChitChop
產(chǎn)品介紹:ChitChop是字節(jié)跳動在海外推出的AI智能助手,可以為用戶提供多達200+的智能機器人服務(wù),通過提供創(chuàng)造性靈感、提高工作效率等方式輔助用戶的工作和生活。
產(chǎn)品功能:首先ChitChop具有豐富的應(yīng)用場景,提供AI創(chuàng)作、AI繪圖、娛樂休閑、學(xué)習(xí)提升、工作提效、生活助手六大場景的AI小工具,為用戶提供創(chuàng)造性靈感,提高工作效率。
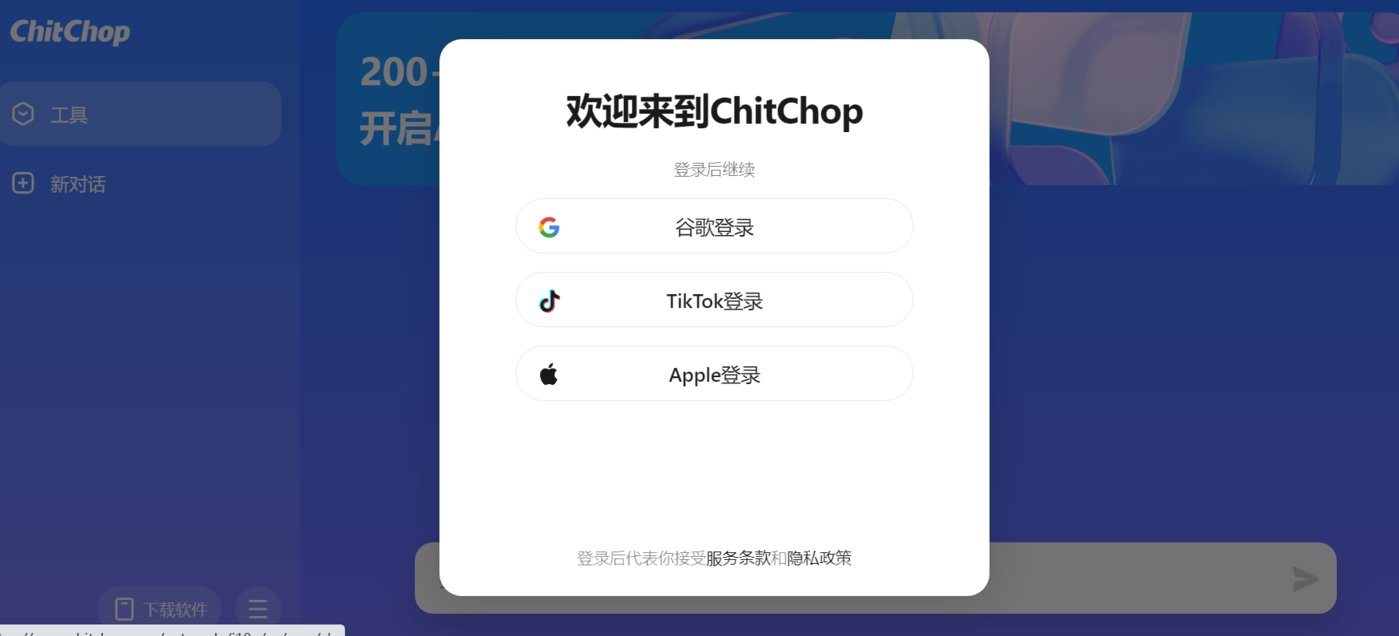
其次,輸入簡單輸入提示即可互動,只需輸入幾個簡單的提示詞,你就可以把你的想法變成藝術(shù)圖像或者與A!進行交流互動。
再次,文件智能分析和總結(jié)功能,添加上傳一個文件,即可分析、總結(jié)和對文件內(nèi)容發(fā)起討論,幫助用戶高效地學(xué)習(xí)和分析內(nèi)容。
最后是實時互聯(lián)網(wǎng)搜索功能,可以與人工智能交互進行搜索。此外,還內(nèi)置200多個智能機器人,可幫助用戶提高創(chuàng)造力,學(xué)習(xí)新話題,甚至與人工智能虛擬角色玩游戲。
適用人群或場景:海外用戶均適用
體驗地址:https://www.chitchop.com/tool
2023年8月
AI智能聊天助手——豆包和Cici
產(chǎn)品介紹:豆包和Cici都是字節(jié)跳動基于云雀模型開發(fā)的AI智能聊天助手,可以回答各種問題并進行對話,幫助用戶獲取信息,只不過豆包是針對國內(nèi)用戶開放的,Cici是豆包的海外版本。
產(chǎn)品功能:豆包和Cici的功能一致,提供問答、智能創(chuàng)作、聊天等服務(wù)。進入豆包/Cici官網(wǎng)首頁登陸后,用戶可直接與豆包/Cici對話,比如可以讓豆包幫助寫爆款文案、生成圖片、英語翻譯等。豆包/Cici還支持創(chuàng)建專屬的智能助手,比如可以定制自己的智能導(dǎo)游,可以幫助自己做旅游形成規(guī)劃,提供更多包含交通、景點及美食的旅游相關(guān)的信息。此外,豆包/Cici還有具備很多現(xiàn)成的AI智能體可供使用,涉及生活、娛樂、寫作、情感和游戲多領(lǐng)域。
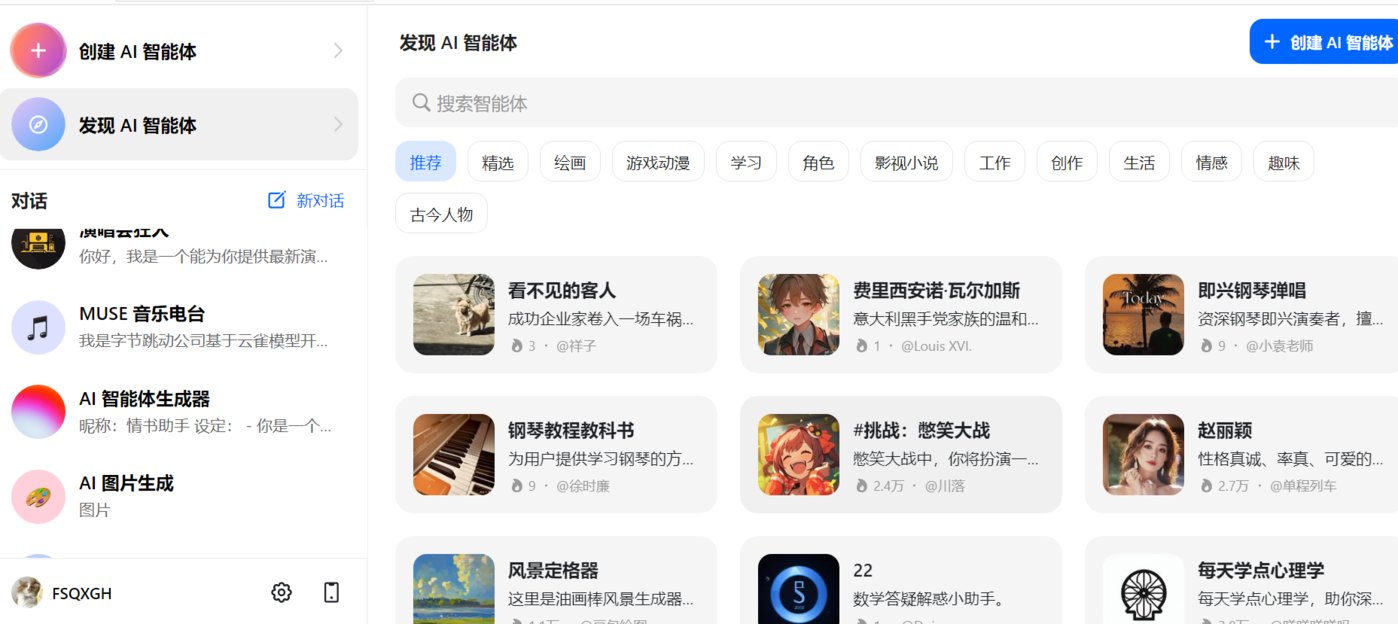
適用人群或場景:所有C端用戶均適用
體驗地址:https://www.doubao.com/chat/bot/discover
字節(jié)跳動大語言模型——云雀
產(chǎn)品介紹:云雀是字節(jié)跳動自研的大語言模型,該模型采用 Transformer 架構(gòu),能夠通過便捷的自然語言交互,高效完成互動對話、信息獲取、協(xié)助創(chuàng)作等任務(wù)。
產(chǎn)品功能:內(nèi)容創(chuàng)作功能,可以根據(jù)用戶指令進行內(nèi)容創(chuàng)作,生成文案大綱及廣告、營銷文案等;智能問答功能,用戶可以通過云雀快速獲取生活常識、工作技能,助力高效解決工作、生活等各類場景中的問題;邏輯推理能力,可進行思維、常識、科學(xué)推理 通過分析問題的前提條件和假設(shè)來推理出答案或解決方案,給出新的想法和見解;代碼生成 功能,作為大語言模型,云雀具備代碼生成能力和知識儲備,可高效的輔助代碼生產(chǎn)場景;信息提取能力,云雀可以深入理解文本信息之間的邏輯關(guān)系,從非結(jié)構(gòu)化的文本信息中抽取所需的結(jié)構(gòu)化信息。
體驗地址:https://www.volcengine.com/contact/yunque
多模態(tài)大模型——BuboGPT
產(chǎn)品介紹:BuboGPT是字節(jié)研發(fā)的一款多模態(tài)大模型,通過整合文本、圖像和音頻輸入,可以執(zhí)行跨模態(tài)交互并做到對多模態(tài)的細粒度理解。

產(chǎn)品功能:首先是多模態(tài)理解能力,BuboGPT實現(xiàn)了文本、視覺和音頻的聯(lián)合多模態(tài)理解和對話功能;其次是視覺對接能力,BuboGPT能夠?qū)⑽谋九c圖像中的特定部分進行準確關(guān)聯(lián),實現(xiàn)細粒度的視覺對接;再次是音頻理解能力,BuboGPT能夠準確描述音頻片段中的各個聲音部分,即使對人類來說一些音頻片段過于短暫難以察覺;最后是對齊和非對齊理解能力;BuboGPT能夠處理匹配的音頻-圖像對,實現(xiàn)完美的對齊理解,并能對任意音頻-圖像對進行高質(zhì)量的響應(yīng)。
項目地址:https://bubo-gpt.github.io/
論文地址:https://arxiv.org/abs/2307.08581
騰訊
2024年1月
多模態(tài)音樂生成模型——M2UGen
產(chǎn)品介紹:M2UGen是一款多模態(tài)音樂生成模型,融合了音樂理解和多模態(tài)音樂生成任務(wù),旨在助力用戶進行音樂藝術(shù)創(chuàng)作。
產(chǎn)品功能:M2UGen具備音樂理解和生成能力,不僅可以從文字生成音樂,它還支持圖像、視頻和音頻生成音樂,還可以編輯生成的音樂。
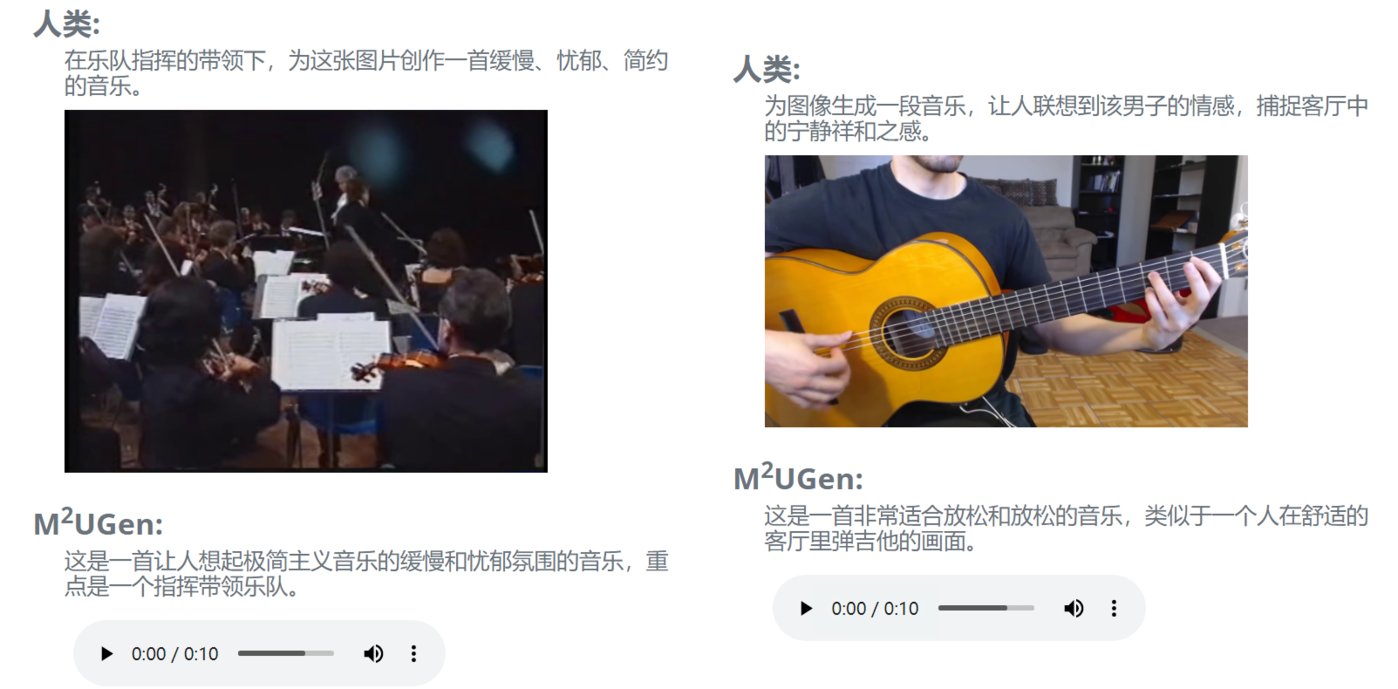
該模型利用MERT等編碼器進行音樂理解,ViT進行圖像理解,ViViT進行視頻理解,并使用MusicGen/AudioLDM2模型作為音樂生成模型(音樂解碼器)。用戶可以輕松移除或替換特定樂器,調(diào)整音樂的節(jié)奏和速度。這使得用戶能夠創(chuàng)造出符合其獨特創(chuàng)意的音樂作品。
適用人群或場景:音樂創(chuàng)作、音頻視頻剪輯
論文地址:https://arxiv.org/pdf/2311.11255.pdf
體驗地址:https://crypto-code.github.io/M2UGen-Demo/
2023年12月
AI視頻大模型——AnimateZero
產(chǎn)品介紹:AnimateZero是騰訊AI團隊發(fā)布的一款A(yù)I視頻生成模型,通過改進預(yù)訓(xùn)練的視頻擴散模型(Video Diffusion Models),能夠更精確地控制視頻的外觀和運動。

產(chǎn)品功能:用戶可以通過輸入文本和圖像來生成視頻,比如由動漫人物的圖片生成的視頻,不僅人物動作流暢,還融入了眼睛變色、頭發(fā)蓬蓬的小細節(jié)。
而且AnimateZero還能通過插入文本嵌入來控制視頻的動態(tài)效果,比如將車子顏色更改:

適用人群或場景:視頻內(nèi)容創(chuàng)作者、影視制作
項目地址:https://vvictoryuki.github.io/animatezero.github.io/
GitHub:https://github.com/vvictoryuki/AnimateZero?tab=readme-ov-file
2023年10月
開源AI視頻生成模型——VideoCrafter
產(chǎn)品介紹:VideoCrafter是由騰訊和香港科技大學(xué)聯(lián)手打造的AI視頻生成大模型,能夠根據(jù)用戶提供的文本描述生成高質(zhì)量、流暢的視頻作品。2024年1月,騰訊對VideoCrafter進行升級更新,推出了VideoCrafter2模型。

產(chǎn)品功能:用戶只需輸入提示詞就能生成對應(yīng)的視頻,并可通過集成編輯器對生成的視頻進行編輯修改,在修改調(diào)整后,用戶還可以將視頻保存為MP4、MOV和AVI等多種格式。相比前一代產(chǎn)品,VideoCrafter2采用更為先進的圖像處理技術(shù),顯著提高視頻的視覺質(zhì)量,使圖像更為清晰、細膩;同時VideoCrafter2動態(tài)效果明顯增強,不僅關(guān)注靜態(tài)畫面,還專注于提升視頻中的動態(tài)效果,使得運動更加流暢自然。
此外, VideoCrafter2在視頻概念的組合方面表現(xiàn)出色,能夠更好地整合不同元素,創(chuàng)造出更有深度和創(chuàng)意的影片。
項目地址:https://ailab-cvc.github.io/videocrafter2/
GitHub:https://github.com/AILab-CVC/VideoCrafter
2023年9月
通用大語言模型——混元大模型
產(chǎn)品介紹:混元大模型是騰訊自研的大語言模型,具備強大的中文創(chuàng)作能力,復(fù)雜語境下的邏輯推理能力,以及可靠的任務(wù)執(zhí)行能力。
產(chǎn)品功能:騰訊混元大模型主要功能包含:智能互動問答、內(nèi)容創(chuàng)作、邏輯推理及圖像生成等。
內(nèi)容創(chuàng)作方面,該模型可以在多種場景下處理超長文本,通過位置編碼優(yōu)化,提升長文的處理效果和性能。結(jié)合指令跟隨優(yōu)化,讓產(chǎn)出內(nèi)容更符合字數(shù)要求。
邏輯推理能力方面,能夠準確理解用戶意圖,基于輸入數(shù)據(jù)或信息進行推理、分析。
2023年10月,混元大模型開放文生圖功能,用戶可以根據(jù)關(guān)鍵詞生成圖片,具有強大的中文理解能力。能夠生成各種風(fēng)格的圖片,包括景觀、人物、動漫等。生成的圖片具有真實感和自然度。
適用人群或場景:適用于文檔、會議、廣告營銷等多場景
體驗地址:https://hunyuan.tencent.com/
華為
2024年3月
圖像生成模型——PixArt-Σ
產(chǎn)品介紹:PIXART-Σ是華為推出的圖像生成模型,采用Diffusion Transformer (DiT) 架構(gòu),可直接生成 4K 分辨率的 AI 圖像。
產(chǎn)品功能:用戶只需輸入一段文字描述就能生成具有4K高分辨率的圖像,相較于前身PixArt-α,它提供了更高的圖像保真度和與文本提示更好的對齊。

具體來看,高質(zhì)量的訓(xùn)練數(shù)據(jù)和高效的 Token 壓縮。PIXART-Σ結(jié)合了更高質(zhì)量的圖像數(shù)據(jù),配對更精確和詳細的圖像標題,同時在 DiT 框架內(nèi)提出了一個新的注意力模塊,可以壓縮鍵(Key)和值(Value),顯著提高效率,促進超高分辨率圖像的生成。
正是由于這些改進,PIXART-Σ才能以較小的模型規(guī)模(6億參數(shù))實現(xiàn)優(yōu)于現(xiàn)有文本到圖像擴散模型(如 SDXL(26億參數(shù))和 SD Cascade(51億參數(shù)))的圖像質(zhì)量和用戶提示遵從能力。此外,PIXART-Σ 能夠生成4K 圖像,為創(chuàng)建高分辨率海報和壁紙?zhí)峁┝酥С郑行У卦鰪娏穗娪昂陀螒虻刃袠I(yè)中高質(zhì)量視覺內(nèi)容的制作。
適用人群或場景:藝術(shù)創(chuàng)作者、漫畫、繪畫、插畫師
項目地址:https://pixart-alpha.github.io/PixArt-sigma-project/
論文地址:https://arxiv.org/abs/2401.05252
2024年2月
華為微小模型——盤古π系列(PanGu-π-1B Pro 和 PanGu-π-1.5B Pro)
產(chǎn)品介紹: PanGu-π-1B Pro 和 PanGu-π-1.5B Pro是華為近期推出的參數(shù)規(guī)模分別為10億/15億的微小模型。
產(chǎn)品功能:以一個 1B 大小的語言模型作為載體,在分詞器裁剪、模型架構(gòu)調(diào)優(yōu)、參數(shù)繼承、多輪訓(xùn)練等方面具有巨大優(yōu)勢,GPU 的推理速度和效率遠超GPT-3.5。具體來看,首先,通過分詞器裁剪,刪除低頻詞匯,降低 Token 數(shù)量,減少計算開銷,為模型主體留足空間。
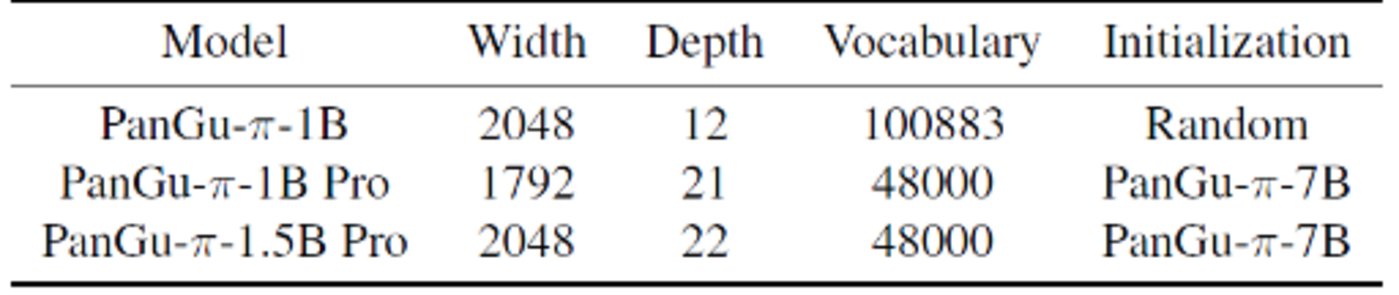
其次,模型架構(gòu)調(diào)優(yōu)成為關(guān)鍵,深度、寬度對小語言模型效果有著極大影響。通過對深度、寬度和擴展率的實驗,找到了最適合小模型的架構(gòu)配置。再次,運用參數(shù)繼承,有效提升小模型的效果并加速收斂。
最后,與大多數(shù)大模型只進行一輪訓(xùn)練不同,小模型的多輪訓(xùn)練被證明對于克服遺忘問題非常有效。通過第一輪訓(xùn)練的數(shù)據(jù)篩選和精煉,可以優(yōu)化第二輪訓(xùn)練的效果。實驗證明,多輪訓(xùn)練在小模型上表現(xiàn)出色,使得模型在有限的資源下也能取得顯著提升。
盤古 π 論文鏈接:https://arxiv.org/pdf/2312.17276.pdf
“小” 模型訓(xùn)練論文鏈接:https://arxiv.org/pdf/2402.02791.pdf
GitHub:https://github.com/YuchuanTian/RethinkTinyLM
2023年7月
華為通用多模態(tài)大模型—盤古3.0系列
產(chǎn)品介紹:盤古大模型 3.0 是一個面向行業(yè)的AI大模型系列,旨在提升核心競爭力,協(xié)助客戶、合作伙伴、開發(fā)者在各行業(yè)落地人工智能并創(chuàng)造價值。
產(chǎn)品功能:盤古大模型 3.0系列包含自然語言、視覺、多模態(tài)、預(yù)測、科學(xué)計算大模型等五個基礎(chǔ)大模型,可以為用戶提供知識問答、文案生成、代碼生成,以及多模態(tài)大模型的圖像生成、圖像理解等能力。
同時盤古模型3.0提供參數(shù)范圍從100億到1000億的不同規(guī)模參數(shù),可以滿足不同客戶的需求。目前,盤古模型已在金融、制造、藥品研發(fā)、煤炭、鐵路等各個行業(yè)成功落地。
適用人群或場景:B端用戶
體驗地址:https://pangu.huaweicloud.com/
小紅書
2024年1月
小紅書文案生成器——紅薯智語
產(chǎn)品介紹:紅薯智語是一種利用人工智能技術(shù),自動生成小紅書風(fēng)格文案的工具。
產(chǎn)品功能:首先是文案生成功能,用戶只需要上傳一張圖片,通過人工智能技術(shù)對圖片內(nèi)容進行分析,就能生成符合圖片內(nèi)容的文案。
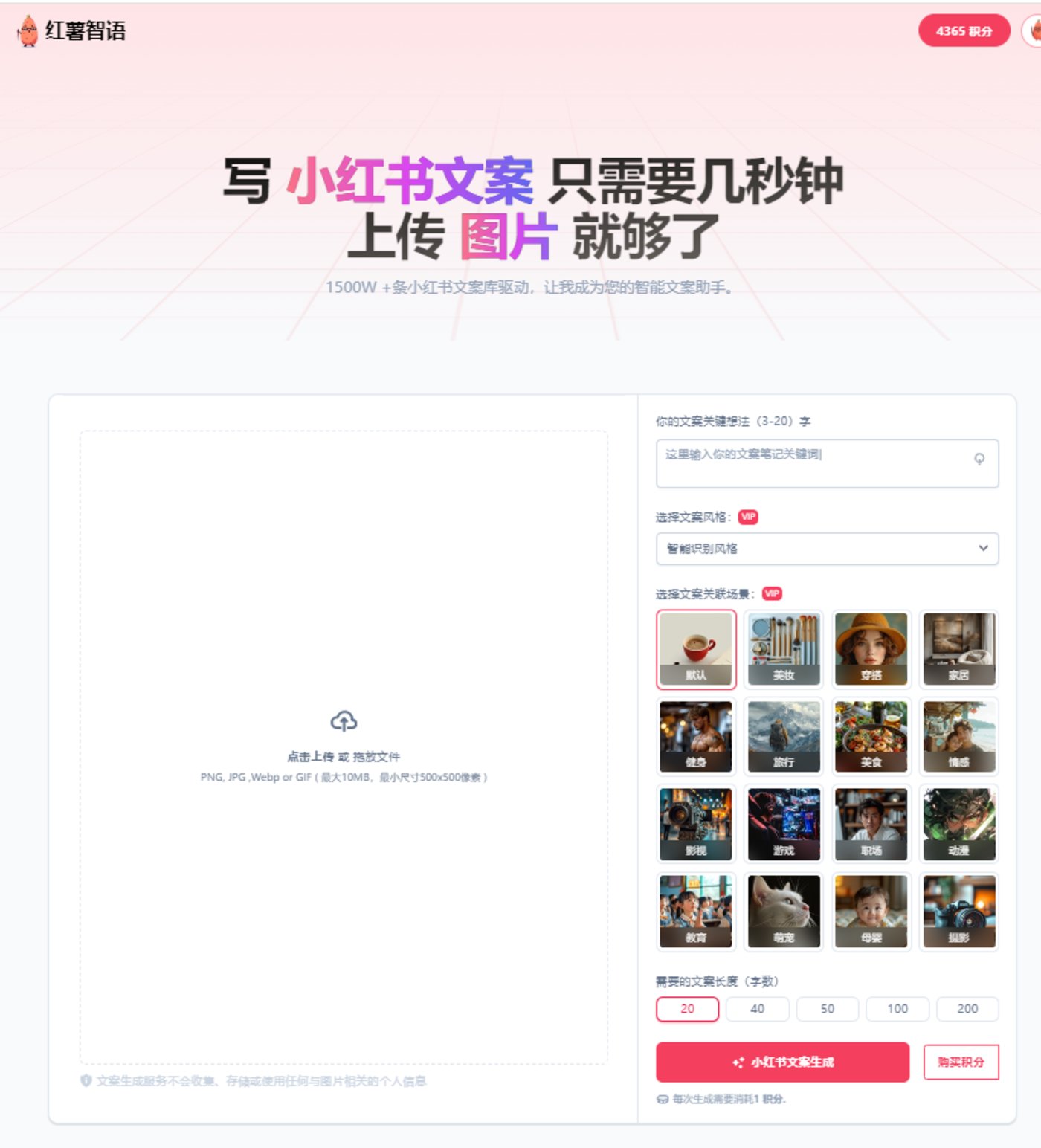
其次是擁有1500萬小紅書文案庫,這些文案都是經(jīng)過小紅書用戶驗證過的,符合小紅書平臺的風(fēng)格和用戶需求。用戶可以直接從文案庫中選擇合適的文案,無需自己編寫。
最后是自定義功能,用戶可以自定義關(guān)鍵詞、文案風(fēng)格、場景標簽,以生成符合個人需求的文案。例如,用戶可以輸入“椰香雞肉”作為關(guān)鍵詞,選擇“美食”場景,生成介紹椰香雞肉食材和制作方法的文案。
適用人群或場景:小紅書創(chuàng)作者
體驗地址: 適用人群或場景:適合所有用戶 體驗地址:內(nèi)測地址,暫無鏈接 產(chǎn)品介紹:Trik AI是小紅書推出的一款A(yù)I圖像創(chuàng)作平臺,專注于“一眼中國風(fēng)”方向的無限探索。 產(chǎn)品功能:用戶輸入文本提示,就能生成具有“中國風(fēng)”卡通或動漫圖像。用戶可以通過該平臺將設(shè)計作品融入東方文化的美學(xué)元素中,實現(xiàn)化繁為簡的效果。 適用人群或場景:適合中式美學(xué)設(shè)計師、繪畫者 產(chǎn)品介紹:美圖 AI 視覺大模型 MiracleVision(奇想智能)于 2023 年 6 月內(nèi)測,具備強大的視覺表現(xiàn)力和創(chuàng)作力,為美圖秀秀、美顏相機、Wink、美圖設(shè)計室、WHEE、美圖云修等知名影像與設(shè)計產(chǎn)品提供 AI 模型能力的同時,也幫助美圖公司搭建起由底層、中間層和應(yīng)用層構(gòu)建的人工智能產(chǎn)品生態(tài)。 產(chǎn)品功能:MiracleVision(奇想智能)的主要功能包含文生圖、圖生圖、文生視頻、圖生視頻和模型訓(xùn)練、圖片局部修改等,該模型目前已應(yīng)用于美圖旗下多個產(chǎn)品,比如美圖秀秀、WHEE等,用戶可自行前往官網(wǎng)或下載APP體驗。 據(jù)悉,MiracleVision(奇想智能)目前已升級至 4.0 版本,除全面應(yīng)用于美圖旗下產(chǎn)品,還在逐步助力電商、廣告、游戲、動漫、影視五大行業(yè)。 適用人群或場景:影視制作、動漫、游戲 體驗地址:http://www.miraclevision.com/ 產(chǎn)品介紹:WHEE 是美圖基于MiracleVision 大模型打造的AI生圖藝術(shù)創(chuàng)作平臺,旨在為用戶提供一站式 AI 視覺創(chuàng)作服務(wù),為視覺創(chuàng)作提供更多想象力和靈感。 產(chǎn)品功能:WHEE 主要功能包括文生圖、圖生圖、風(fēng)格模型訓(xùn)練、AI超清、AI生視頻和AI改圖等。文生圖不多贅述,圖生圖可以根據(jù)上傳的圖片生成一幅風(fēng)格類似的圖片;風(fēng)格模型訓(xùn)練適合設(shè)計或繪畫等專業(yè)人士,可以訓(xùn)練生成自己的繪畫模型;AI超清是最近上新的一鍵修復(fù)老照片功能,可以還原照片高清畫質(zhì);AI視頻功能目前顯示在內(nèi)測,不過經(jīng)測試,文生視頻生成速度較快,但畫面真實感欠缺,圖生視頻生成時長需幾分鐘,視頻畫面略顯僵硬,不夠自然。 值得一提的是,2023年12月,WHEE移動端App正式上線,用戶可自行下載在手機端就可實時體驗AI賦能藝術(shù)創(chuàng)作的魅力。 適用人群或場景:藝術(shù)創(chuàng)作者、設(shè)計師、插畫師 產(chǎn)品介紹:開拍是一款幫助口播視頻創(chuàng)作者從腳本靈感到高清畫質(zhì)拍攝、視頻人像精修、后期智能剪輯全鏈路的影像生產(chǎn)力工具。 產(chǎn)品功能:包含AI 腳本、數(shù)字人主播、提詞器、高清畫質(zhì)、美顏美妝等。AI腳本是用戶可以輸入關(guān)鍵詞一鍵生成口播文案或幫助生成小紅書爆款文案、潤色文案內(nèi)容;數(shù)字人主播是用戶可以自定義或創(chuàng)建數(shù)字人主播,支持更換人物形象和視頻背景;提詞器功能讓口播不用背稿,勻速模式支持自定義字幕滾動速度;高清畫質(zhì)功能,提升視頻清晰度,支持 4K 畫質(zhì)視頻錄制、濾鏡調(diào)節(jié),同時支持美顏功能,可自定義參數(shù),素顏也可以錄視頻。 適用人群或場景:視頻內(nèi)容創(chuàng)作者、主播 體驗地址: https://www.kaipai.com/home 產(chǎn)品介紹:Winkstudio是一款A(yù)I視頻人像精修工具,旨在提升攝影師、后期師、MCN機構(gòu)、自媒體博主視頻剪輯效率。 產(chǎn)品功能:WinkStudio提供配方批量出片、智能畫質(zhì)修復(fù)、智能發(fā)絲級摳像、批量色調(diào)統(tǒng)一等功能,滿足不同用戶的個性化需求。同時,WinkStudio支持高質(zhì)視頻輸出,最高支持導(dǎo)出4K超清視頻,保證高清流暢的視覺體驗。 適用人群或場景:視頻內(nèi)容創(chuàng)作者、攝影師、視頻后期 體驗地址:https://wink.meitu.com/?channel=wsllbd7&bd_vid=12130296699805568259 產(chǎn)品介紹:美圖設(shè)計室是美圖推出的一款A(yù)I商業(yè)設(shè)計工具,旨在助力提升商業(yè)設(shè)計制圖效率。 產(chǎn)品功能:AI商品圖功能,上傳商品圖后,AI可自動摳出產(chǎn)品主體,支持美容、鞋帽、家居等十余種產(chǎn)品品類識別,百余種推薦場景幫你生成多種風(fēng)格,還原真實使用場景;AI LOGO功能,給出提示詞和商品slogan就能幫助自動生成商品logo;AI模特功能,用戶只需上傳衣服或假發(fā)等商品圖,選擇系統(tǒng)AI模特和場景就能生成全新商品圖,不僅可以提升制作商品圖效率,同時也降低了邀請模特拍攝成本;AI海報功能,可以幫助生成商品封面圖、活動優(yōu)惠圖以及各種活動營銷封面。 此外,還有AI消除和智能摳圖功能,可以對視頻或者圖片進行一鍵涂抹去除不要的圖像元素。 適用人群或場景:電商、帶貨 體驗地址:https://www.x-design.com/logo-design/?from=home 產(chǎn)品介紹:DreamAvatar是美圖旗下的AI數(shù)字人生成工具,專注于數(shù)字人和AIGC技術(shù)的深度融合, 為推動數(shù)字時尚、營銷推廣、企業(yè)數(shù)字化的創(chuàng)新帶來更多想象。 產(chǎn)品功能:DreamAvatar“AI演員”數(shù)字人的生成,不需要專業(yè)設(shè)備,一臺手機就能輕松搞定。用戶只需要將拍攝好的視頻素材導(dǎo)入,并指定視頻里的人物,AI會進行人體檢測、跟蹤、擦除、替換,以及背景修復(fù),自動把真人替換成數(shù)字人。利用3D人體姿態(tài)估計和驅(qū)動算法,DreamAvatar的AI演員能夠做到動作與真人完美同步。 DreamAvatar還能通過相機姿態(tài)估計和跟蹤,以及光照估計算法,讓數(shù)字人和環(huán)境自然融合,更具真實感。最后,將前面這一系列AI處理,匯總到3D渲染并輸出。 目前,DreamAvatar“AI演員”支持最長10秒視頻的轉(zhuǎn)化,共推出了機器人、獸人、類人三大題材共計11個不同風(fēng)格的數(shù)字人形象,每個題材從造型風(fēng)格、渲染風(fēng)格都做了不同方向的細化,給到用戶多樣性的體驗和選擇。 適用人群或場景:AI模特、AI主播、AI客服、AI演員 體驗地址:https://www.dreamavatar.com/ 產(chǎn)品介紹:RoboNeo是美圖推出的一款A(yù)I助手,通過與其對話可幫助用戶修圖、設(shè)計和繪畫 。 產(chǎn)品功能:RoboNeo的特色在于能將自然語言轉(zhuǎn)化為修圖指令。通過與RoboNeo對話,用戶能夠輕松完成以往需要手動操作的影像創(chuàng)作任務(wù)。比如告訴RoboNeo “幫我消除路人甲”、“幫我制作視頻宣傳片”、“幫我設(shè)計海報”, RoboNeo都能一一實現(xiàn)。 由于修圖過程通過對話進行,用戶擁有更高的自由度。RoboNeo的創(chuàng)作效果也不會受限于本地客戶端的功能或素材約束,能激發(fā)無限的創(chuàng)意。 此外,RoboNeo還能根據(jù)語言指令對圖片進行效果改進,提升創(chuàng)作者的生產(chǎn)效率。 適用人群或場景:設(shè)計師、插畫師、美術(shù)創(chuàng)作者 產(chǎn)品介紹:星火語音大模型是一款A(yù)I語音模型,該模型能將識別、翻譯和多語種分類等多種功能統(tǒng)一交換并進行訓(xùn)練,實現(xiàn)多種任務(wù)信息的共通,使語音識別效果大幅提升。 產(chǎn)品功能:主要是大模型語音識別和超擬人語音合成,前者能將短音頻(≤60秒)精準識別成文字,除中文普通話和英文外,支持37個語種自動判別,說話過程中可以無縫切換語種,并實時返回對應(yīng)語種的文字結(jié)果。 超擬人語音合成功能,通過對口語化及副語言現(xiàn)象進行建模,還原真人口語表達和語流變化等韻律特點,實現(xiàn)生動自然更接近真人的語音合成能力,滿足不同場景個性化需求。 適用人群或場景:語音搜索、智能客服、人機交互、聊天輸入、語音助手等 體驗地址:https://xinghuo.xfyun.cn/speechllm 產(chǎn)品介紹:星火內(nèi)容運營大師是一個集選題,寫作,配圖,排版,潤色,發(fā)布,數(shù)據(jù)分析等一體的內(nèi)容運營工作平臺。該平臺基于訊飛星火大模型打造,致力于為內(nèi)容運營、品牌內(nèi)容等崗位提供易用的生產(chǎn)力工具。 產(chǎn)品功能:AI選題推薦,AI智能生成標題,緊跟熱點,激發(fā)創(chuàng)作靈感;AI文章創(chuàng)作,輸入主體,AI一鍵寫稿,還支持模仿生成和選擇風(fēng)格生成;AI審查校對,提供校對文本、審查糾錯、合規(guī)風(fēng)險提示等功能,讓創(chuàng)作者能夠更加專注于內(nèi)容創(chuàng)作;AI配圖排版,AI可以根據(jù)關(guān)鍵詞生成圖片,一鍵排版,圖文并茂;支持多平臺內(nèi)容分發(fā),支持分發(fā)到今日頭條和微信公眾號,并可監(jiān)測數(shù)據(jù)。 適用人群或場景:自媒體創(chuàng)作者、媒體作者、文案策劃等 體驗地址:https://turbodesk.xfyun.cn/home?channelid=bd6&bd_vid=11782091658338351641 產(chǎn)品介紹:訊飛智文是科大訊飛基于星火認知大模型推出的一款人工智能PPT生成工具,只需輸入一句話或者添加要演示的文稿即可一鍵生成PPT。 產(chǎn)品功能:主題創(chuàng)建模式,一句話式主題輸入,快速把你的想法變?yōu)?nbsp;PPT 文檔,可根據(jù)需求進行 AI改寫,完善文檔內(nèi)容;文本創(chuàng)建模式,添加一段話或者一篇文章,AI 幫你總結(jié)、拆分、提煉,最終生成高度相關(guān)的PPT文檔;PPT文案優(yōu)化,內(nèi)置SPARK AI助手,可以進行文案的潤色、擴寫、翻譯、縮寫、拆分、總結(jié)、提煉、糾錯、改寫等;演講備注功能,可以秒速生成備注內(nèi)容,幫你將演講內(nèi)容梳理清晰,避免PPT演講中途卡頓;此外,平臺內(nèi)置多種模板可一鍵為PPT切換主題和模板,讓你的創(chuàng)作更出色更高效。 適用人群及場景:會議演講、工作匯報 產(chǎn)品介紹:訊飛星火是科大訊飛推出的新一代認知智能大模型,擁有跨領(lǐng)域的知識和語言理解能力,能夠基于自然對話方式理解與執(zhí)行任務(wù)。 產(chǎn)品功能:內(nèi)容生成能力,可以進行多風(fēng)格多任務(wù)長文本生成,例如郵件、文案、公文、作文、對話等;語言理解能力,可以進行多層次跨語種語言理解,實現(xiàn)語法檢查、要素抽取、語篇歸整、文本摘要、情感分析、多語言翻譯等;知識問答能力,可以回答各種各樣的問題,包括生活知識、工作技能、醫(yī)學(xué)知識等;推理能力,擁有基于思維鏈的推理能力,能夠進行科學(xué)推理、常識推理等;多題型步驟級數(shù)學(xué)能力,具備數(shù)學(xué)思維,能理解數(shù)學(xué)問題,覆蓋多種題型,并能給出解題步驟; 代碼理解與生成能力,可以進行代碼理解、代碼修改以及代碼生成等工作。 2024年1月,星火認知大模型V3.5發(fā)布,實現(xiàn)了在文本生成、語言理解、知識問答、邏輯推理、數(shù)學(xué)能力、代碼能力以及多模態(tài)能力等方面的全面提升。具體來看,文本生成提升7.3%,語言理解提升7.6%,知識問答提升4.7%,邏輯推理提升9.5%,數(shù)學(xué)能力提升9.8%,代碼能力提升8.0%,多模態(tài)能力提升6.6%。 與同類競品相比,據(jù)稱星火認知大模型V3.5在語言理解和數(shù)學(xué)方面的能力已經(jīng)超過了GPT-4 Turbo,代碼能力達到了GPT-4 Turbo的96%,而多模態(tài)理解能力則達到了GPT-4V的91%。 適用人群或場景:適合所有用戶 體驗地址:https://xinghuo.xfyun.cn/&wd=&eqid=addca757000746550000000664993589 產(chǎn)品介紹:星火開源 -13B是科大訊飛發(fā)布的全棧國產(chǎn)化開源大模型,它是首個基于全國產(chǎn)化算力平臺”飛星一號”的開源大模型。擁有 130 億參數(shù),包含基礎(chǔ)模型iFlytekSpark-13B-base、精調(diào)模型iFlytekSpark-13B-chat,開源了微調(diào)工具iFlytekSpark-13B-Lora、人設(shè)定制工具iFlytekSpark-13B-Charater。學(xué)術(shù)企業(yè)研究可以基于全棧自主可控的星火優(yōu)化套件,更便利地訓(xùn)練自己的專用大模型。 產(chǎn)品功能:具備通用任務(wù)處理能力和生產(chǎn)力功能,如聊天、問答、文本提取、分類、數(shù)據(jù)分析和代碼生成等,同時基于強大的 AI能力,支持企業(yè)和學(xué)術(shù)研究訓(xùn)練專用大模型,優(yōu)化學(xué)習(xí)輔助、數(shù)學(xué)推理等領(lǐng)域的應(yīng)用。 適用人群或場景:適合需要進行 AI模型訓(xùn)練和應(yīng)用開發(fā)B端企業(yè) 體驗地址:https://xihe.mindspore.cn/modelzoo/iflytekspark/introduce 產(chǎn)品介紹:訊飛寫作是一款全能在線AI寫作工具,旨在為用戶提供高效、準確的文本生成服務(wù)。 產(chǎn)品功能:對話寫作,訊飛寫作采用對話式交互設(shè)計,用戶只需輸入關(guān)鍵詞指令,系統(tǒng)就會根據(jù)用戶需求生成相應(yīng)的文本內(nèi)容;AI模板寫作,訊飛寫作具備豐富的模板庫,涵蓋了各種類型的文本,如會議紀要、演講稿、財經(jīng)新聞、實踐報告等。用戶可以根據(jù)自己的需求選擇合適的模板,然后進行信息填寫,就可以完成文本創(chuàng)作;AI素材寫作,訊飛寫作內(nèi)置了多種AI工具,如擴寫、縮寫、改寫、續(xù)寫、文本校對等。這些工具可以幫助用戶優(yōu)化文本結(jié)構(gòu),提高表達效果。此外,為提升寫作效率,訊飛寫作還支持導(dǎo)音頻、視頻、文本等多種格式的素材,方便用戶在文本中插入和使用。用戶可以將這些素材直接拖拽到編輯器中,輕松實現(xiàn)基于素材內(nèi)容的文本創(chuàng)作。 適用群體或場景:內(nèi)容創(chuàng)作者、演講、匯報工作 體驗地址:https://huixie.iflyrec.com/?from=xfxzpz 2024年1月 產(chǎn)品介紹:360 AI搜索是新一代智能搜索產(chǎn)品,主要為最復(fù)雜的搜索查詢提供更相關(guān)、更全面的答案。 產(chǎn)品功能:該產(chǎn)品主要包括AI搜索和增強模式兩個新功能。其中,AI 搜索是用戶提出問題后,AI將通過搜索引擎進行檢索,讀取并分析多個網(wǎng)頁的內(nèi)容,最后輸出精準的結(jié)論;增強模式是在用戶提問后,AI將進行語義分析并追問以補充更多信息,然后AI將問題拆分為多組關(guān)鍵詞進行搜索引擎檢索,深度閱讀更多的網(wǎng)頁內(nèi)容,最終生成邏輯清晰、準確無誤的答案。 體驗地址:https://so.360.com/?ref=aihub.cn 2023年11月 產(chǎn)品介紹及功能:11月4日,360大模型“奇元大模型”通過備案落地。從大模型定位和應(yīng)用角度來看,奇元大模型具備充足的靈活性和可擴展性,商業(yè)化和產(chǎn)品定位以B端用戶為主,后期將會聚焦更多的商業(yè)化應(yīng)用和垂直領(lǐng)域,幫助用戶提升工作效率。 2023年9月 產(chǎn)品介紹: BDM是360 人工智能研究院發(fā)布的中文原生 AI繪畫模型,該模型能夠精確生成中文語義圖像,兼容英文社區(qū)插件,實現(xiàn)中英雙語繪畫。 產(chǎn)品功能:高質(zhì)量圖像生成,BDM 使用先進的擴散模型技術(shù),可以生成具有高度細節(jié)和真實感的圖像;多模態(tài)輸入,BDM 支持輸入,如文本、圖像和音頻等多類型,可以處理各種創(chuàng)意任務(wù); 強大的風(fēng)格遷移能力,BDM 可以將一種藝術(shù)風(fēng)格應(yīng)用到任何圖像上,從而創(chuàng)造出獨特的視覺效果;實時預(yù)覽和編輯,提供實時圖像預(yù)覽和編輯功能,用戶可以在生成過程中進行調(diào)整和優(yōu)化;個性化定制,BDM 允許用戶根據(jù)自己的需求和喜好進行個性化設(shè)置,例如調(diào)整參數(shù)、添加自定義元素等。跨平臺兼容,BDM 適用于各種操作系統(tǒng)和設(shè)備,如 Windows、macOS、Linux、Android 和 iOS。 論文地址:https://arxiv.org/pdf/2309.00952.pdf 2023年3月 產(chǎn)品介紹:360智腦是360自研認知型通用大模型,依托360多年積累的大算力、大數(shù)據(jù)、工程化等關(guān)鍵優(yōu)勢,集成了360GPT大模型、360CV大模型、360多模態(tài)大模型技術(shù)能力。 產(chǎn)品功能:360智腦大模型具備生成創(chuàng)作、多輪對話、代碼能力、邏輯推理、知識問答、閱讀理解、文本分類、翻譯、改寫、多模態(tài)十大核心能力、數(shù)百項細分功能,重塑人機協(xié)作新范式,全面升級生產(chǎn)效率。 使用人群或場景:內(nèi)容創(chuàng)作、文檔處理 體驗地址:https://ai.360.com/ 總結(jié):上述8家中國互聯(lián)網(wǎng)大廠的50款大模型及應(yīng)用,能否超越GPT-4?這似乎需要用時間來證明一切。
2023年8月
AI繪畫平臺——TrikAI

美圖秀秀
2023年6月
AI 視覺大模型——MiracleVision 奇想智能

AI藝術(shù)創(chuàng)作平臺——WHEE

AI口播視頻工具——WHEE
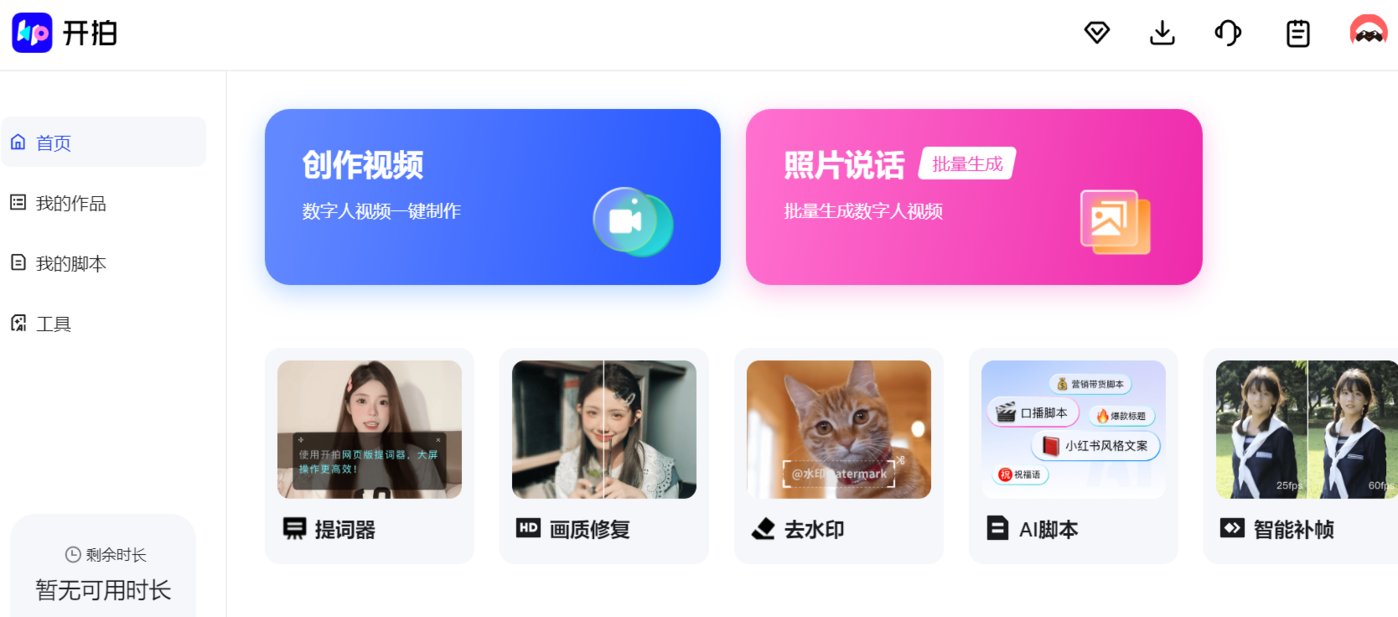
AI視頻剪輯工具——Winkstudio
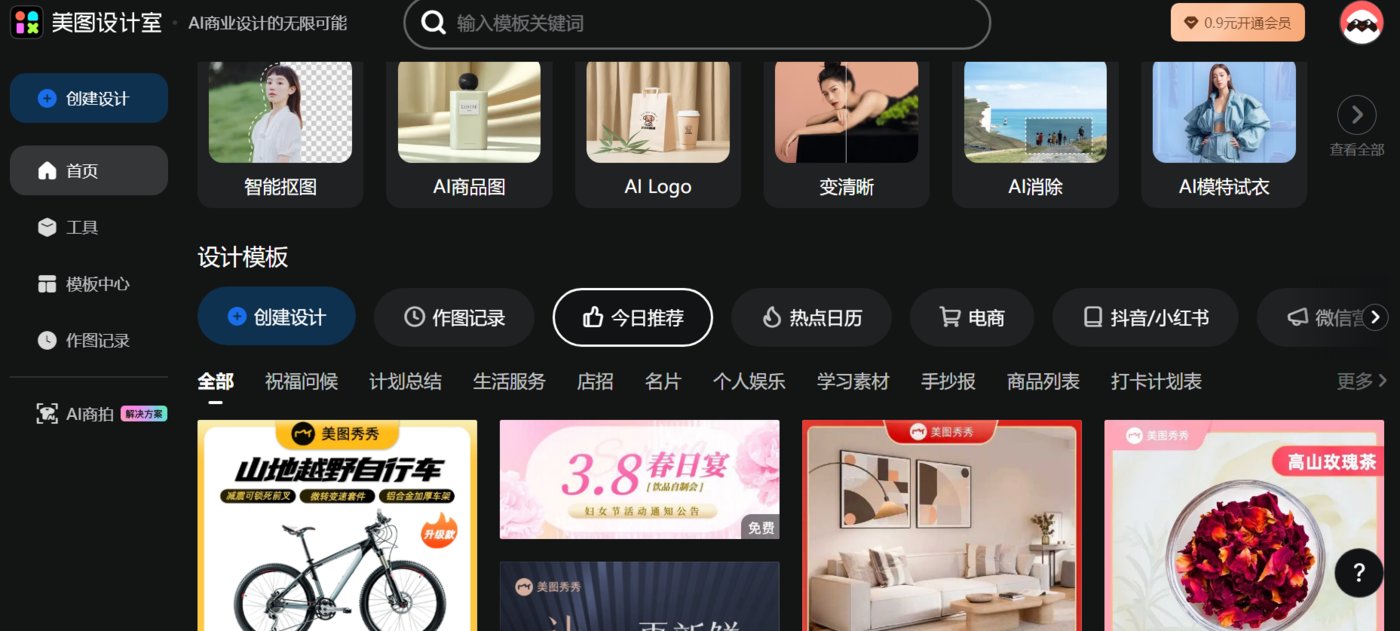
商業(yè)設(shè)計工具——美圖設(shè)計室
AI數(shù)字人生成工具——DreamAvatar

美圖AI助手——RoboNeo

科大訊飛
2024年1月
AI語音模型——星火語音大模型

2023年12月
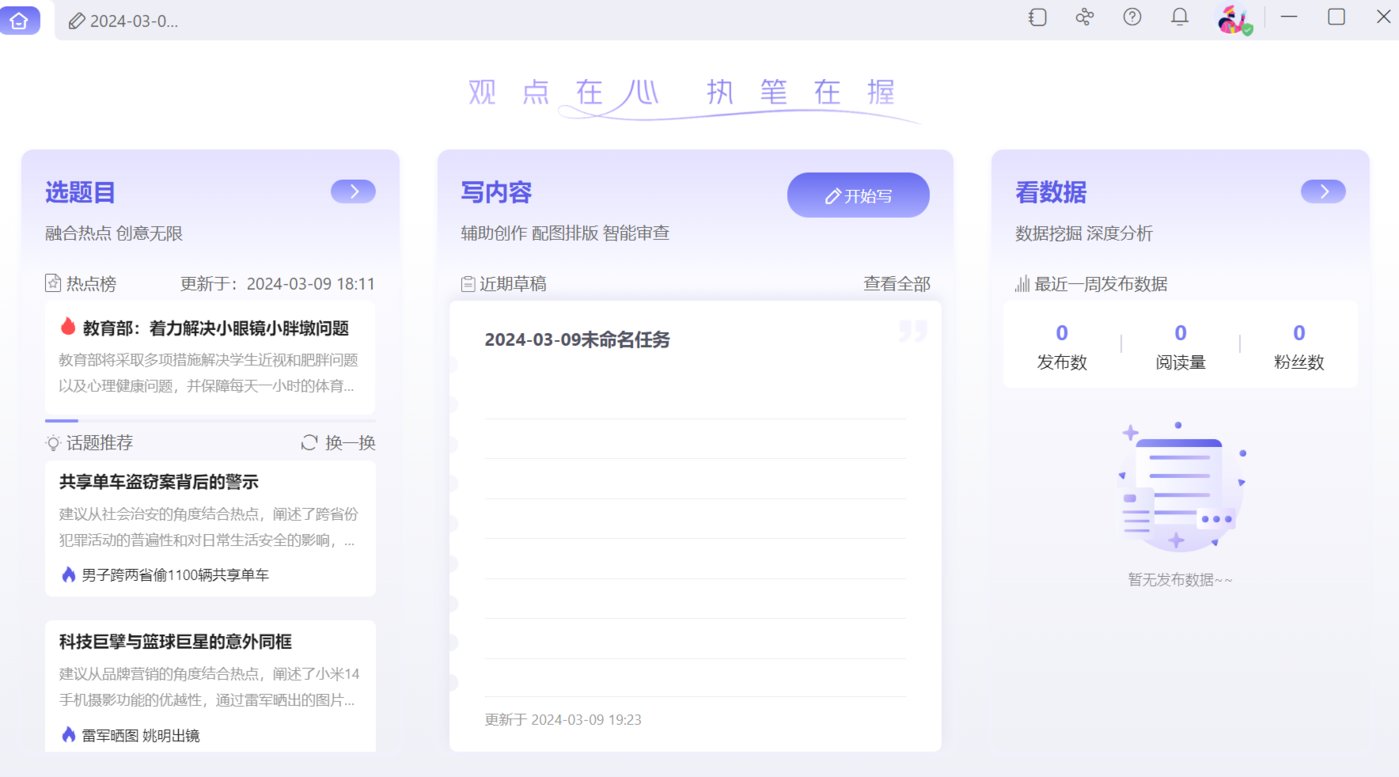
一站式AIGC內(nèi)容創(chuàng)作平臺——星火內(nèi)容運營大師
2023年11月
AI文檔平臺——訊飛智文

2023年8月
認知智能大模型——訊飛星火

全棧國產(chǎn)化開源大模型——星火開源 -13B
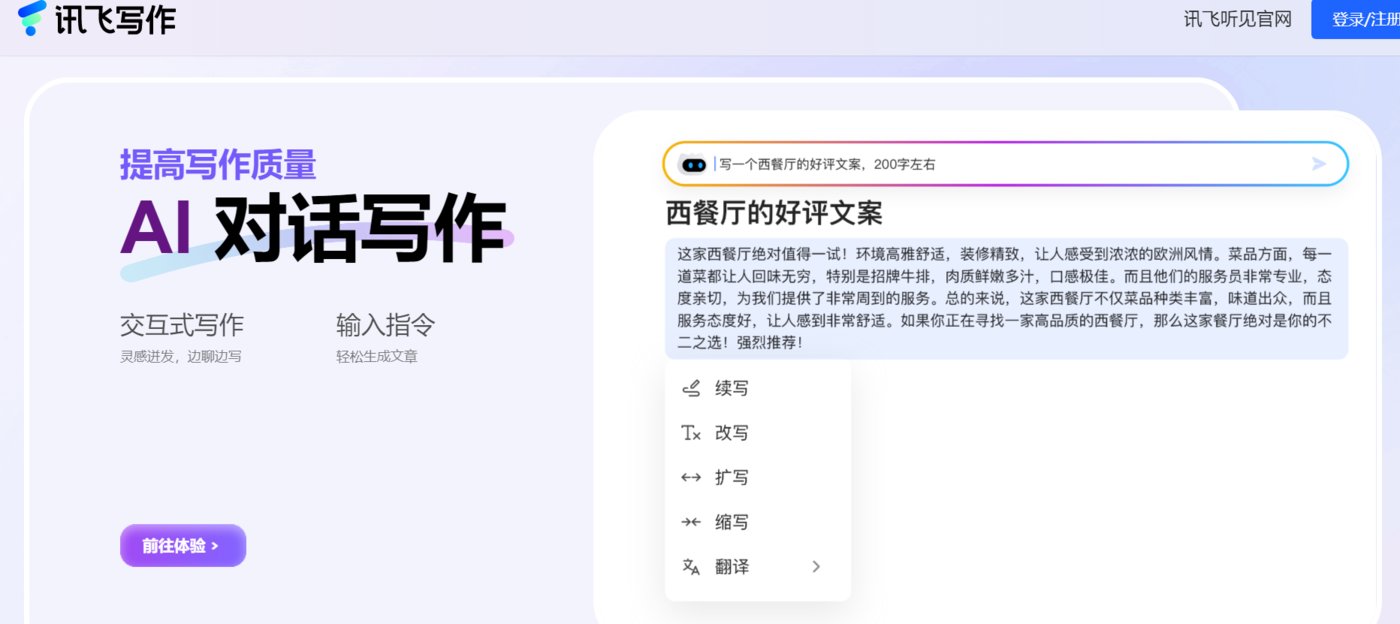
AI寫作工具——訊飛寫作
360
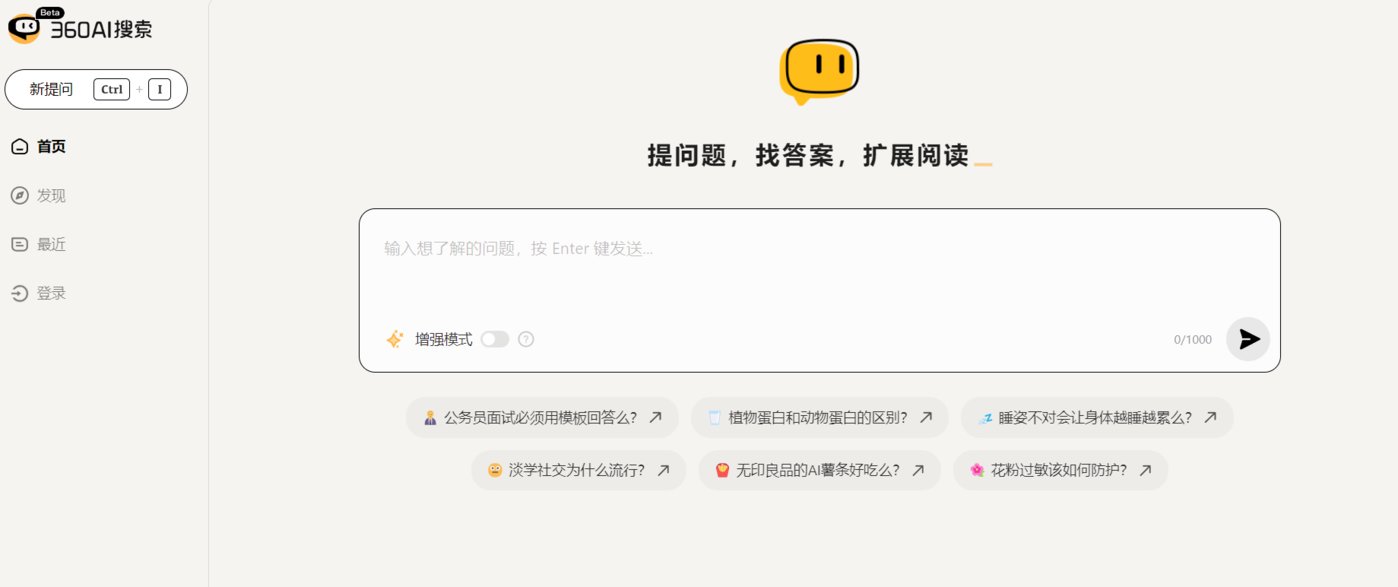
智能搜索——360AI搜索
奇元大模型
中文原生AI繪畫模型——BDM

認知型通用大模型——360智腦