













實時加SOTA一飛沖天!FastOcc:推理更快、部署友好Occ算法來啦!
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
寫在前面&筆者的個人理解
在自動駕駛系統當中,感知任務是整個自駕系統中至關重要的組成部分。感知任務的主要目標是使自動駕駛車輛能夠理解和感知周圍的環境元素,如行駛在路上的車輛、路旁的行人、行駛過程中遇到的障礙物、路上的交通標志等,從而幫助下游模塊做出正確合理的決策和行為。在一輛具備自動駕駛功能的車輛中,通常會配備不同類型的信息采集傳感器,如環視相機傳感器、激光雷達傳感器以及毫米波雷達傳感器等等,從而確保自動駕駛車輛能夠準確感知和理解周圍環境要素,使自動駕駛車輛在自主行駛的過程中能夠做出正確的決斷。
目前,基于純圖像的視覺感知方法相比于基于激光雷達的感知算法需要更低的硬件和部署成本而受到工業界和學術界的廣泛關注,并且已經有許多優秀的視覺感知算法被設計出來用于實現3D目標感知任務以及BEV場景下的語義分割任務。雖然現有的3D目標感知算法已經取得了較為不錯的檢測性能,但依舊有相關問題逐漸在使用過程中暴露了出來:
- 原有的3D目標感知算法無法很好的解決數據集中存在的長尾問題,以及真實世界中存在但是當前訓練數據集中可能沒有標注的物體(如:行駛道路上的大石塊,翻倒的車輛等等)
- 原有的3D目標感知算法通常會直接輸出一個粗糙的3D立體邊界框而無法準確描述任意形狀的目標物體,對物體形狀和幾何結構的表達還不夠細粒度。雖然這種輸出結果框可以滿足大多數的物體場景,但是像有連接的公交車或者具有很長挖鉤的建筑車輛,當前3D感知算法就無法給出準確和清楚的描述了
基于上述提到的相關問題,柵格占用網絡(Occupancy Network)感知算法被提出。本質上而言,Occupancy Network感知算法是基于3D空間場景的語義分割任務。基于純視覺的Occupancy Network感知算法會將當前的3D空間劃分成一個個的3D體素網格,通過自動駕駛車輛配備的環視相機傳感器將采集到的環視圖像送入到網絡模型中,經過算法模型的處理和預測,輸出當前空間中每個3D體素網格的占用狀態以及可能包含的目標語義類別,從而實現對于當前3D空間場景的全面感知。
近年來,基于Occupancy Network的感知算法因其更好的感知優勢而受到了研究者們的廣泛關注,目前已經涌現出了很多優秀的工作用于提升該類算法的檢測性能,這些論文的大概思路方向為:提出更加魯棒的特征提取方法、2D特征向3D特征的坐標變換方式、更加復雜的網絡結構設計以及如何更加準確的生成Occupancy真值標注幫助模型學習等等。然而許多現有的Occupancy Network感知方法在模型預測推理的過程中都存在著嚴重的計算開銷,使得這些算法很難滿足自動駕駛實時感知的要求,很難上車部署。
基于此,我們提出了一種新穎的Occupancy Network預測方法,和目前的SOTA感知算法相比,提出的FastOcc算法具有實時的推理速度以及具有競爭力的檢測性能,提出的算法和其他算法的性能和推理速度如下圖所示。
 FastOcc算法和其他SOTA算法的精度和推理速度比較
FastOcc算法和其他SOTA算法的精度和推理速度比較
論文鏈接:https://arxiv.org/pdf/2403.02710.pdf
網絡模型的整體架構&細節梳理
為了提高Occupancy Network感知算法的推理速度,我們分別從輸入圖像的分辨率、特征提取主干網絡、視角轉換的方式以及柵格預測頭結構四個部分進行了實驗,通過實驗結果發現,柵格預測頭中的三維卷積或者反卷積具有很大的耗時優化空間。基于此,我們設計了FastOcc算法的網絡結構,如下圖所示。
 FastOcc算法網絡結構圖
FastOcc算法網絡結構圖
整體而言,提出的FastOcc算法包括三個子模塊,分別是Image Feature Extraction用于多尺度特征提取、View Transformation用于視角轉換、Occupancy Prediction Head用于實現感知輸出,接下來我們會分別介紹這三個部分的細節。
圖像特征提取(Image Feature Extraction)
對于提出的FastOcc算法而言,網絡輸入依舊是采集到的環視圖像,這里我們采用了ResNet的網絡結構完成環視圖像的特征提取過程。同時,我們也利用了FPN特征金字塔結構用于聚合主干網絡輸出的多尺度圖像特征。為了后續的表達方便,這里我們將輸入圖像表示為,經過特征提取后的特征表示為。
視角轉換(View Transformation)
視角轉換模塊的主要作用就是完成2D圖像特征向3D空間特征的轉換過程,同時為了降低算法模型的開銷,通常轉換到3D空間的特征會進行粗糙的表達,這里為了方便表示,我們將轉換到3D空間的特征標記為,其中代表嵌入特征向量的維度,代表感知空間的長度、寬度和高度。在目前的感知算法當中,主流的視角轉換過程包括兩類:
- 一類是以BEVFormer為代表的Backward的坐標變換方法。該類方法通常是先在3D空間生成體素Query,然后利用Cross-view Attention的方式將3D空間的體素Query與2D圖像特征進行交互,完成最終的3D體素特征的構建。
- 一類是以LSS為代表的Forward的坐標變換方法。這類方法會利用網絡中的深度估計網絡來同時估計每個特征像素位置的語義特征信息和離散深度概率,通過外積運算構建出語義視錐特征,最終利用VoxelPooling層實現最終的3D體素特征的構建。
考慮到LSS算法具有更好的推理速度和效率,在本文中,我們采用了LSS算法作為我們的視角轉換模塊。同時,考慮到每個像素位置的離散深度都是估計出來的,其不確定性一定程度上會制約模型最終的感知性能。因此,在我們的具體實現中,我們利用點云信息來進行深度方向上的監督,以實現更好的感知結果。
柵格預測頭(Occupancy Prediction Head)
在上圖展示的網絡結構圖中,柵格預測頭還包含三個子部分,分別是BEV特征提取、圖像特征插值采樣、特征集成。接下來,我們將逐一介紹三部分的方法的細節。
BEV特征提取
目前,大多數的Occupancy Network算法都是對視角轉換模塊得到的3D體素特征進行處理。而處理的形式一般是三維的全卷積網絡。具體而言,對于三維全卷積網絡的任意一層,其對輸入的三維體素特征進行卷積所需要的計算量如下:
其中,和分別代表輸入特征和輸出特征的通道數量,代表特征圖空間大小。相比于直接在3D空間中處理體素特征,我們采用了輕量級的2D BEV特征卷積模塊。具體而言,對于視角轉換模塊的輸出體素特征,我們首先將高度信息和語義特征進行融合得到2D的BEV特征,其次利用2D全卷積網絡進行特征提取得到BEV特征,該2D過程的特征提取過程的計算量可以表述成如下的形式
通過3D和2D處理過程的計算量對比可以看出,通過利用輕量化的2D BEV特征卷積模塊來代替原有的3D體素特征提取可以大大減少模型的計算量。同時,兩類處理過程的可視化流程圖如下圖所示:
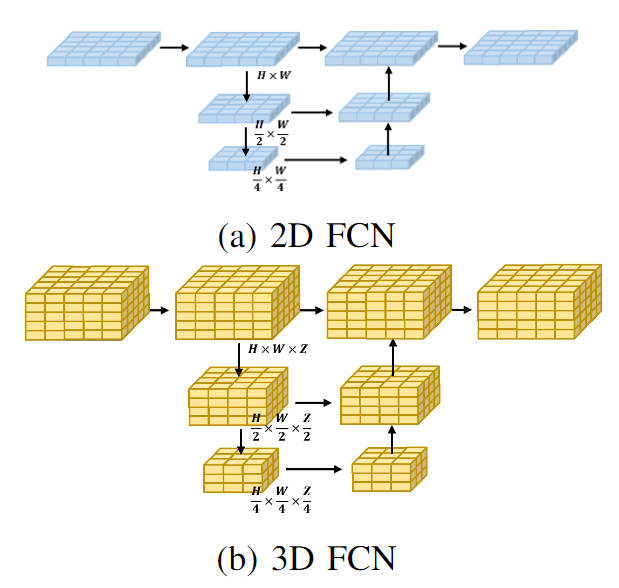
2D FCN和3D FCN網絡結構的可視化情況
圖像特征插值采樣
為了減少柵格預測頭模塊的計算量,我們將視角轉換模塊輸出的3D體素特征的高度進行壓縮,并利用2D的BEV卷積模塊進行特征提取。但為了增加缺失的Z軸高度特征信息并秉持著減少模型計算量的思想出發,我們提出了圖像特征插值采樣方法。
具體而言,我們首先根據需要感知的范圍設定對應的三維體素空間,并將其分配到ego坐標系下,記作。其次,利用相機的外參和內參坐標變換矩陣,將ego坐標系下的坐標點投影到圖像坐標系,用于提取對應位置的圖像特征。
其中,和分別代表相機的內參和外參坐標變換矩陣,代表ego坐標系下的空間點投影到圖像坐標系下的位置。在得到對應的圖像坐標后,我們將超過圖像范圍或者具有負深度的坐標點過濾掉。然后,我們采用雙線性插值運算根據投影后的坐標位置獲取對應的圖像語義特征,并對所有相機圖像收集到的特征取平均值,得到最終的插值采樣結果。
特征集成
為了將得到的平面BEV特征與插值采樣得到的3D體素特征進行集成,我們首先利用上采樣操作將BEV特征的空間尺寸和3D體素特征的空間尺寸進行對齊,并且沿著Z軸方向執行repeat操作,操作后得到的特征我們記作。然后我們將以及圖像特征插值采樣得到的特征進行Concat并通過一個卷積層進行集成得到最終的體素特征。
上述提到的圖像特征插值采樣和特征集成過程整體可以用下圖進行表示:
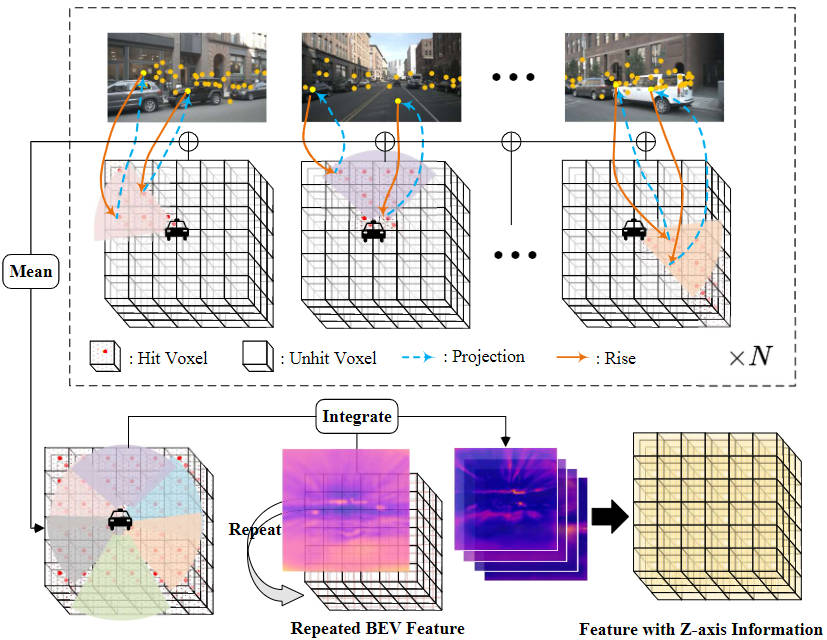
圖像特征插值采樣以及特征集成過程
除此之外,為了進一步確保經過BEV特征提取模塊輸出的BEV特征包含有足夠的特征信息用于完成后續的感知過程,我們采用了一個額外的監督方法,即利用一個語義分割頭來首先語義分割任務,并利用Occupancy的真值來構建語義分割的真值標簽完成整個的監督過程。
實驗結果&評價指標
定量分析部分
首先展示一下我們提出的FastOcc算法在Occ3D-nuScenes數據集上和其他SOTA算法的對比情況,各個算法的具體指標見下表所示
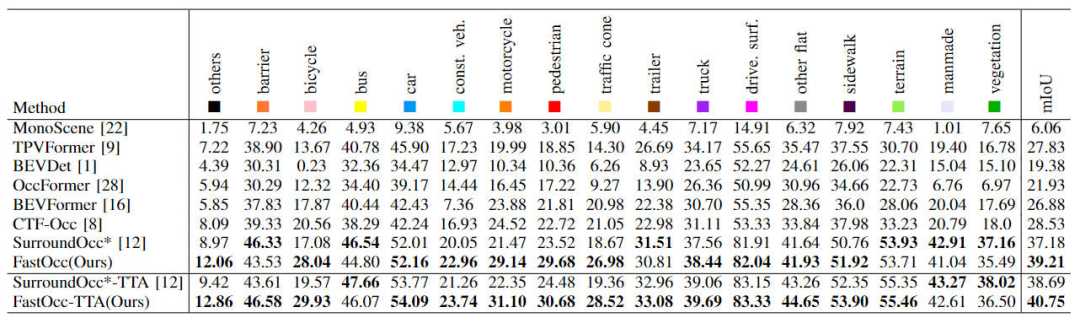
各個算法指標的在Occ3D-nuScenes數據集上的對比
通過表格上的結果可以看出,我們提出的FastOcc算法相比于其他的算法而言,在大多數的類別上都更加的具有優勢,同時總的mIoU指標也實現了SOTA的效果。
除此之外,我們也比較了不同的視角轉換方式以及柵格預測頭當中所使用的解碼特征的模塊對于感知性能以及推理耗時的影響(實驗數據均是基于輸入圖像分辨率為640×1600,主干網絡采用的是ResNet-101網絡),相關的實驗結果對比如下表所示
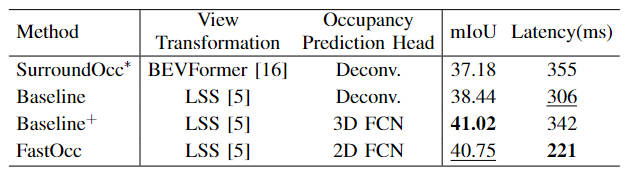
不同視角轉換以及柵格預測頭的精度和推理耗時對比
SurroundOcc算法采用了多尺度的Cross-view Attention視角轉換方式以及3D卷積來實現3D體素特征的提取,具有最高的推理耗時。我們將原有的Cross-view Attention視角轉換方式換成LSS的轉換方式之后,mIoU精度有所提升,同時耗時也得到了降低。在此基礎上,通過將原有的3D卷積換成3D FCN結構,可以進一步的增加精度,但是推理耗時也明顯增加。最后我們選擇采樣LSS的坐標轉換方式以及2D FCN結構實現檢測性能和推理耗時之間的平衡。
此外,我們也驗證了我們提出的基于BEV特征的語義分割監督任務以及圖像特征插值采樣的有效性,具體的消融實驗結果見下表所示:
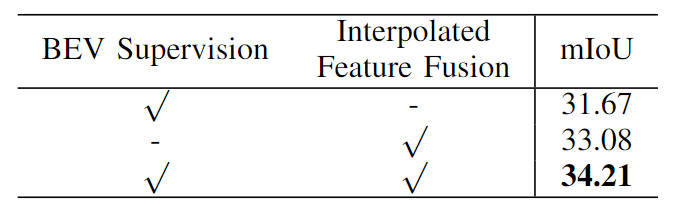
不同模塊的消融實驗對比情況
此外,我們還做了模型上的scale實驗,通過控制主干網絡的大小以及輸入圖像的分辨率,從而構建了一組Occupancy Network感知算法模型(FastOcc、FastOcc-Small、FastOcc-Tiny),具體配置見下表:
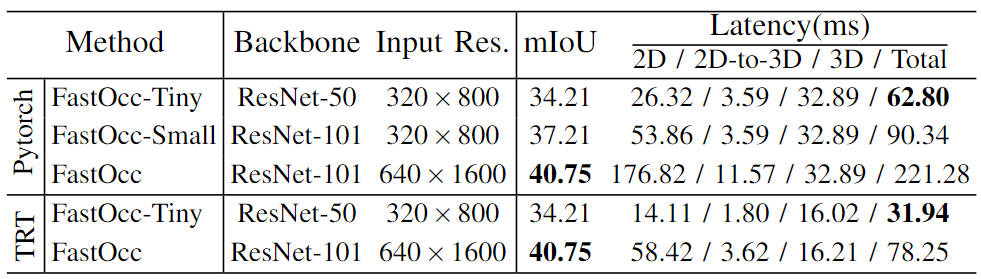
不同主干網絡和分辨率配置下的模型能力對比
定性分析部分
下圖展示了我們提出的FastOcc算法模型與SurroundOcc算法模型的可視化結果對比情況,可以明顯的看到,提出的FastOcc算法模型以更加合理的方式填補了周圍的環境元素,并且實現了更加準確的行駛車輛以及樹木的感知。

FastOcc算法與SurroundOcc算法的可視化結果對比情況
結論
在本文中,針對現有的Occupancy Network算法模型檢測耗時長,難以上車部署的問題,我們提出了FastOcc算法模型。通過將原有的處理3D體素的3D卷積模塊用2D卷積進行替代,極大縮短了推理耗時,并且和其他算法相比實現了SOTA的感知結果。























